
 Périphériques technologiques
IA
Les Chinois de l'UCLA proposent un nouveau mécanisme de jeu automatique ! LLM s'entraîne tout seul et l'effet est meilleur que celui des conseils d'experts GPT-4.
Périphériques technologiques
IA
Les Chinois de l'UCLA proposent un nouveau mécanisme de jeu automatique ! LLM s'entraîne tout seul et l'effet est meilleur que celui des conseils d'experts GPT-4.
Les Chinois de l'UCLA proposent un nouveau mécanisme de jeu automatique ! LLM s'entraîne tout seul et l'effet est meilleur que celui des conseils d'experts GPT-4.

Les données synthétiques sont devenues la pierre angulaire la plus importante dans l'évolution des grands modèles de langage.
À la fin de l'année dernière, certains internautes ont révélé qu'Ilya, ancien scientifique en chef d'OpenAI, avait déclaré à plusieurs reprises qu'il n'y avait pas de goulots d'étranglement en matière de données dans le développement de LLM et que les données synthétiques pouvaient résoudre la plupart des problèmes.
 Photos
Photos
Après avoir étudié le dernier lot d'articles, Jim Fan, scientifique principal chez NVIDIA, a conclu que la combinaison de données synthétiques avec la technologie traditionnelle de génération de jeux et d'images peut permettre à LLM de réaliser une énorme auto-évolution.
 Photos
Photos
L'article qui proposait formellement cette méthode a été rédigé par une équipe chinoise de l'UCLA.
 Pictures
Pictures
Adresse papier : https://www.php.cn/link/236522d75c8164f90a85448456e1d1aa
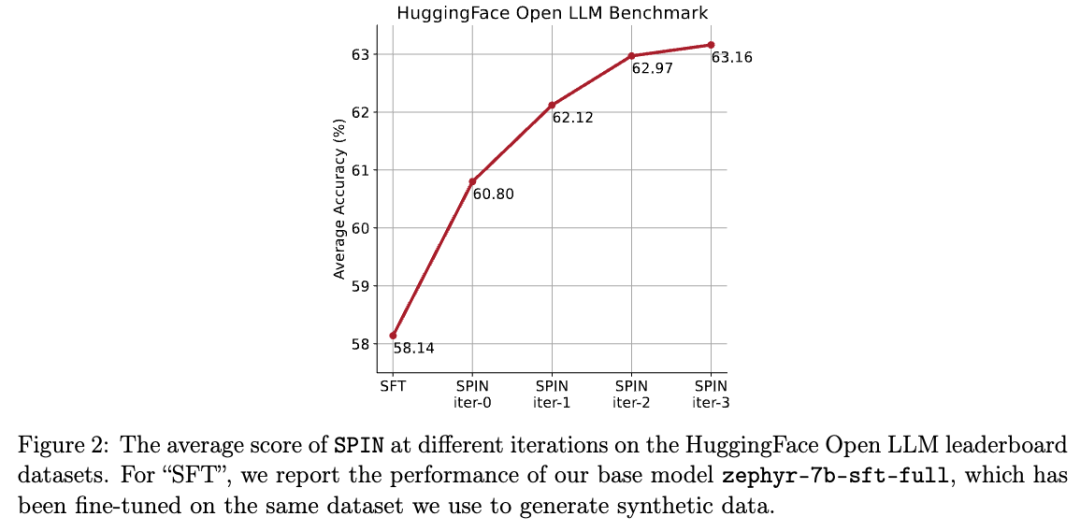
Ils utilisent le mécanisme de lecture automatique (SPIN) pour générer des données synthétiques, et grâce au soi- méthode de réglage fin, non En s'appuyant sur le nouvel ensemble de données, le score moyen du LLM le plus faible sur l'Open LLM Leaderboard Benchmark est amélioré de 58,14 à 63,16.
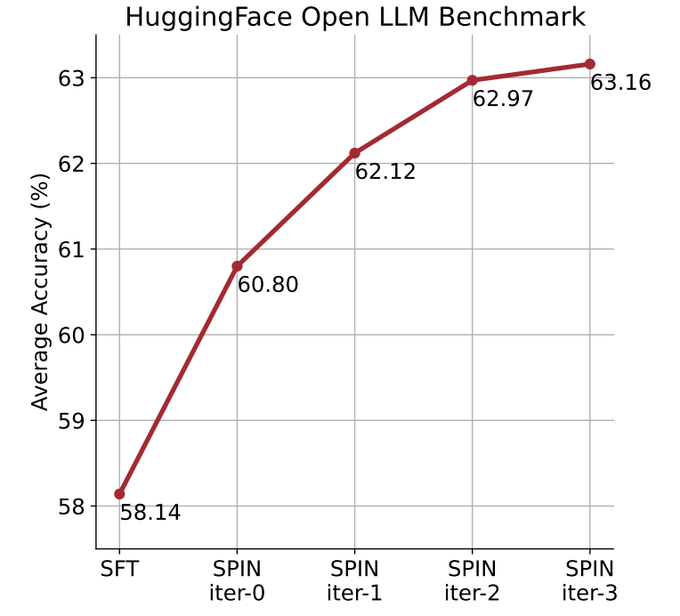
Les chercheurs ont proposé une méthode d'auto-ajustement appelée SPIN, qui améliore progressivement les performances du modèle de langage grâce à l'auto-jeu - LLM rivalise avec sa version itérative précédente.
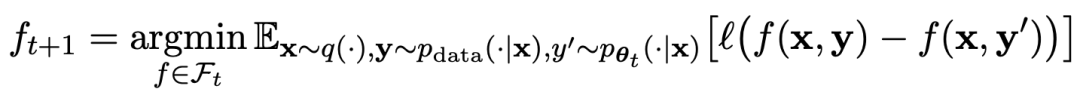 Photos
Photos
De cette façon, l'auto-évolution du modèle peut être complétée sans avoir besoin de données annotées humaines supplémentaires ou de commentaires de modèles de langage de niveau supérieur.
Les paramètres du modèle principal et du modèle adverse sont exactement les mêmes. Jouez contre vous-même avec deux versions différentes.
Le processus de jeu peut être résumé par la formule :
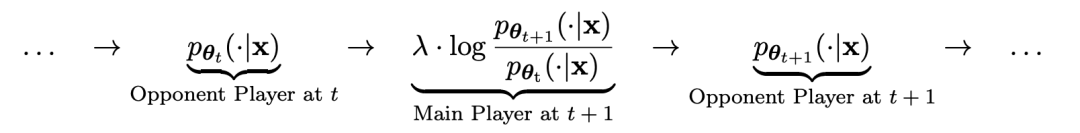 Images
Images
La méthode d'entraînement du self-play Pour résumer, l'idée est à peu près la suivante :
Distinguer les réponses. généré par le modèle de l'adversaire en entraînant le modèle principal et les réponses de la cible humaine, le modèle de l'adversaire est un modèle de langage obtenu de manière itérative en tours, dans le but de générer des réponses aussi indiscernables que possible.
Supposons que les paramètres du modèle de langage obtenus lors de la t-ème itération sont θt, puis dans l'itération t+1, utilisez θt comme joueur adverse et utilisez θt pour générer la réponse y' pour chaque invite x dans le ensemble de données de réglage fin supervisé.
Optimisez ensuite les nouveaux paramètres du modèle de langage θt+1 afin qu'il puisse distinguer y' de la réponse humaine y dans l'ensemble de données de réglage fin supervisé. Cela peut former un processus graduel et se rapprocher progressivement de la distribution de réponse cible.
Ici, la fonction de perte du modèle principal utilise une perte logarithmique, en tenant compte de la différence de valeurs de fonction entre y et y'.
Ajoutez la régularisation de divergence KL au modèle adverse pour éviter que les paramètres du modèle ne s'écartent trop.
Les objectifs spécifiques de l'entraînement au jeu antagoniste sont présentés dans la Formule 4.7. L'analyse théorique montre que lorsque la distribution des réponses du modèle de langage est égale à la distribution des réponses cible, le processus d'optimisation converge.
Si vous utilisez les données synthétiques générées après le jeu pour l'entraînement, puis utilisez SPIN pour l'auto-réglage, les performances de LLM peuvent être efficacement améliorées.
 Images
Images
Mais ensuite, le simple réglage à nouveau des données de réglage initial entraînera une dégradation des performances.
SPIN ne nécessite que le modèle initial lui-même et l'ensemble de données affinées existantes, afin que LLM puisse s'améliorer grâce à SPIN.
En particulier, SPIN surpasse même les modèles entraînés avec des données de préférences GPT-4 supplémentaires via DPO.
 Photos
Photos
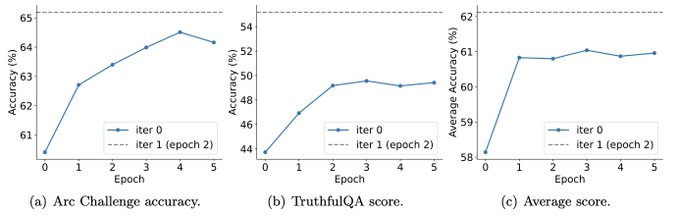
Et les expériences montrent également que l'entraînement itératif peut améliorer les performances du modèle plus efficacement qu'un entraînement avec plus d'époques.
 Photos
Photos
Prolonger la durée d'entraînement d'une seule itération ne réduira pas les performances de SPIN, mais il atteindra sa limite.
Plus il y a d'itérations, plus l'effet de SPIN est évident.
Après avoir lu cet article, les internautes ont soupiré :
Les données synthétiques domineront le développement de grands modèles de langage, ce qui sera une très bonne nouvelle pour les chercheurs de grands modèles de langage !
 Pictures
Pictures
Le jeu automatique permet à LLM de s'améliorer continuellement
Plus précisément, le système SPIN développé par les chercheurs est un système dans lequel deux modèles qui s'influencent mutuellement se promeuvent.
désigné par 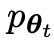 le LLM de l'itération précédente t, que les chercheurs ont utilisé pour générer la réponse y au signal x dans l'ensemble de données SFT annoté par l'homme.
le LLM de l'itération précédente t, que les chercheurs ont utilisé pour générer la réponse y au signal x dans l'ensemble de données SFT annoté par l'homme.
Le prochain objectif est de trouver un nouveau LLM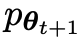 capable de faire la distinction entre la
capable de faire la distinction entre la 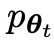 réponse générée y et la réponse générée par l'homme y'.
réponse générée y et la réponse générée par l'homme y'.
Ce processus peut être vu comme un jeu à deux joueurs :
Le joueur principal ou le nouveau LLM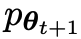 essaie de discerner la réponse du joueur adverse et la réponse générée par l'humain, tandis que l'adversaire ou l'ancien LLM
essaie de discerner la réponse du joueur adverse et la réponse générée par l'humain, tandis que l'adversaire ou l'ancien LLM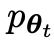 génère des réponses aussi similaires que possible aux données de l'ensemble de données SFT annoté manuellement.
génère des réponses aussi similaires que possible aux données de l'ensemble de données SFT annoté manuellement.
Le nouveau LLM 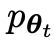 obtenu en affinant l'ancien
obtenu en affinant l'ancien 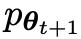 préfère la réponse de
préfère la réponse de 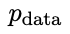 , ce qui entraîne une répartition plus cohérente
, ce qui entraîne une répartition plus cohérente 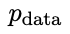 avec
avec 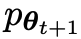 .
.
Dans la prochaine itération, le LLM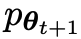 nouvellement acquis devient l'adversaire de génération de réponse, et le but du processus d'auto-jeu est que le LLM finisse par converger vers
nouvellement acquis devient l'adversaire de génération de réponse, et le but du processus d'auto-jeu est que le LLM finisse par converger vers  , de telle sorte que le LLM le plus fort ne soit plus capable de faire la distinction entre sa version de réponse générée précédemment et la version générée par l'homme.
, de telle sorte que le LLM le plus fort ne soit plus capable de faire la distinction entre sa version de réponse générée précédemment et la version générée par l'homme.
Comment utiliser SPIN pour améliorer les performances du modèle
Les chercheurs ont conçu un jeu à deux joueurs, dans lequel l'objectif principal du modèle est de faire la distinction entre les réponses générées par LLM et les réponses générées par l'homme. Dans le même temps, le rôle de l’adversaire est de produire des réponses qui ne se distinguent pas de celles des humains. La formation du modèle principal est au cœur de l’approche des chercheurs.
Expliquez d'abord comment entraîner le modèle principal pour distinguer les réponses de LLM des réponses humaines.
Au cœur de l'approche des chercheurs se trouve un mécanisme de jeu de soi, dans lequel le joueur principal et l'adversaire sont le même LLM, mais issus d'itérations différentes.
Plus précisément, l'adversaire est l'ancien LLM de l'itération précédente, et l'acteur principal est le nouveau LLM à apprendre dans l'itération actuelle. L'itération t+1 comprend les deux étapes suivantes : (1) entraîner le modèle principal, (2) mettre à jour le modèle adverse.
Formation du maître modèle
Tout d'abord, les chercheurs expliqueront comment former le maître joueur à faire la distinction entre les réponses LLM et les réponses humaines. Inspirés par la mesure de probabilité intégrale (IPM), les chercheurs ont formulé la fonction objectif :
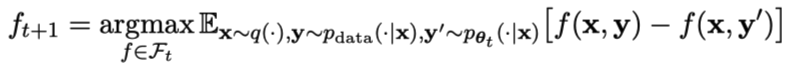 Image
Image
Mettre à jour le modèle de l'adversaire
Le but du modèle de l'adversaire est de trouver un meilleur LLM qui produit La réponse de n'est pas différente des données p du modèle principal.
Expériences
SPIN améliore efficacement les performances de référence
Les chercheurs ont utilisé HuggingFace Open LLM Leaderboard comme évaluation approfondie pour prouver l'efficacité de SPIN.
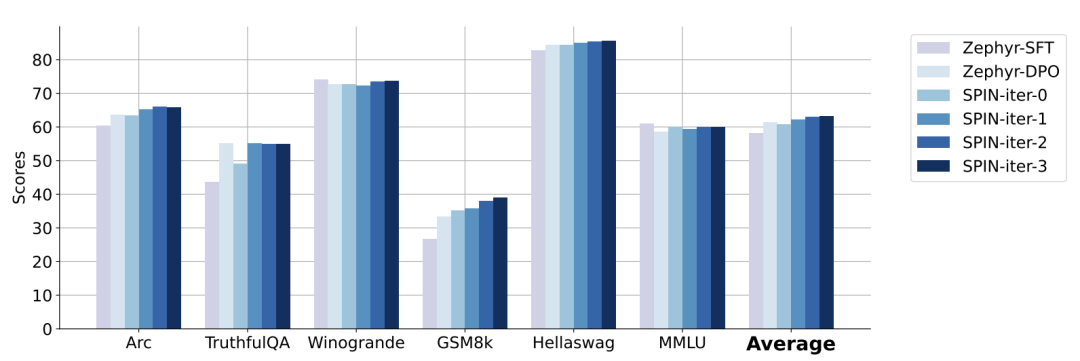
Dans la figure ci-dessous, les chercheurs ont comparé les performances du modèle affiné par SPIN après 0 à 3 itérations avec le modèle de base zephyr-7b-sft-full.
Les chercheurs peuvent observer que SPIN montre des résultats significatifs dans l'amélioration des performances du modèle en exploitant davantage l'ensemble de données SFT, sur lequel le modèle de base a été entièrement affiné.
Dans l'itération 0, la réponse du modèle a été générée à partir de zephyr-7b-sft-full, et les chercheurs ont observé une amélioration globale de 2,66 % du score moyen.
Cette amélioration est particulièrement visible sur les benchmarks TruthfulQA et GSM8k, avec des augmentations de plus de 5% et 10% respectivement.
Dans l'itération 1, les chercheurs ont utilisé le modèle LLM de l'itération 0 pour générer une nouvelle réponse pour SPIN, en suivant le processus décrit dans l'algorithme 1.
Cette itération produit une amélioration supplémentaire de 1,32% en moyenne, ce qui est particulièrement significatif sur les benchmarks Arc Challenge et TruthfulQA.
Les itérations suivantes ont poursuivi la tendance aux améliorations progressives pour diverses tâches. Dans le même temps, l'amélioration à l'itération t+1 est naturellement plus petite
 picture
picture
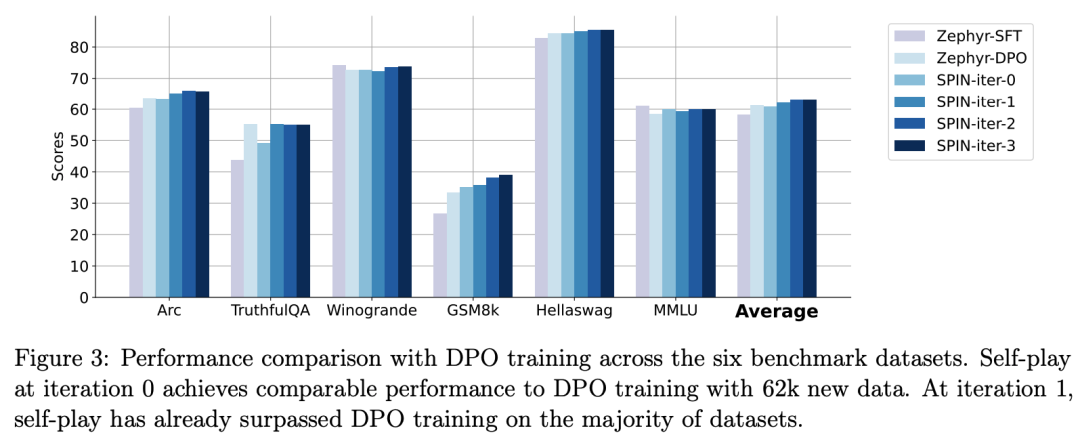
zephyr-7b-beta est un modèle dérivé de zephyr-7b-sft-full, utilisant DPO sur environ 62 000 données de préférences qualifié.
Les chercheurs notent que DPO nécessite une contribution humaine ou un retour d'information de haut niveau sur un modèle de langage pour déterminer les préférences, la génération de données est donc un processus plutôt coûteux.
En revanche, le SPIN des chercheurs ne nécessite que le modèle initial lui-même.
De plus, contrairement au DPO qui nécessite de nouvelles sources de données, l’approche des chercheurs exploite pleinement les ensembles de données SFT existants.
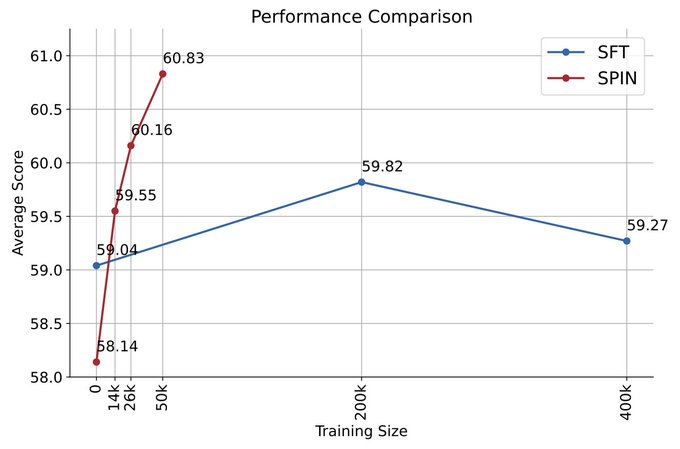
La figure ci-dessous montre la comparaison des performances de SPIN avec la formation DPO aux itérations 0 et 1 (en utilisant 50 000 données SFT).
 Photos
Photos
Les chercheurs peuvent observer que bien que DPO utilise davantage de données provenant de nouvelles sources, SPIN basé sur les données SFT existantes démarre à partir de l'itération 1. SPIN dépasse même les performances de DPO et SPIN se classe dans le classement. les tests de référence dépassent même ceux du DPO.
Référence :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Traducteur | Bugatti Review | Chonglou Cet article décrit comment utiliser le moteur d'inférence GroqLPU pour générer des réponses ultra-rapides dans JanAI et VSCode. Tout le monde travaille à la création de meilleurs grands modèles de langage (LLM), tels que Groq, qui se concentre sur le côté infrastructure de l'IA. Une réponse rapide de ces grands modèles est essentielle pour garantir que ces grands modèles réagissent plus rapidement. Ce didacticiel présentera le moteur d'analyse GroqLPU et comment y accéder localement sur votre ordinateur portable à l'aide de l'API et de JanAI. Cet article l'intégrera également dans VSCode pour nous aider à générer du code, à refactoriser le code, à saisir la documentation et à générer des unités de test. Cet article créera gratuitement notre propre assistant de programmation d’intelligence artificielle. Introduction au moteur d'inférence GroqLPU Groq
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 Les Chinois de Caltech utilisent l'IA pour renverser les preuves mathématiques ! Accélérer 5 fois a choqué Tao Zhexuan, 80% des étapes mathématiques sont entièrement automatisées
Apr 23, 2024 pm 03:01 PM
Les Chinois de Caltech utilisent l'IA pour renverser les preuves mathématiques ! Accélérer 5 fois a choqué Tao Zhexuan, 80% des étapes mathématiques sont entièrement automatisées
Apr 23, 2024 pm 03:01 PM
LeanCopilot, cet outil mathématique formel vanté par de nombreux mathématiciens comme Terence Tao, a encore évolué ? Tout à l'heure, Anima Anandkumar, professeur à Caltech, a annoncé que l'équipe avait publié une version étendue de l'article LeanCopilot et mis à jour la base de code. Adresse de l'article image : https://arxiv.org/pdf/2404.12534.pdf Les dernières expériences montrent que cet outil Copilot peut automatiser plus de 80 % des étapes de preuve mathématique ! Ce record est 2,3 fois meilleur que le précédent record d’Esope. Et, comme auparavant, il est open source sous licence MIT. Sur la photo, il s'agit de Song Peiyang, un garçon chinois.
 De « humain + RPA » à « humain + IA générative + RPA », comment le LLM affecte-t-il l'interaction homme-machine RPA ?
Jun 05, 2023 pm 12:30 PM
De « humain + RPA » à « humain + IA générative + RPA », comment le LLM affecte-t-il l'interaction homme-machine RPA ?
Jun 05, 2023 pm 12:30 PM
Source de l'image@visualchinesewen|Wang Jiwei De « humain + RPA » à « humain + IA générative + RPA », comment le LLM affecte-t-il l'interaction homme-machine RPA ? D'un autre point de vue, comment le LLM affecte-t-il la RPA du point de vue de l'interaction homme-machine ? La RPA, qui affecte l'interaction homme-machine dans le développement de programmes et l'automatisation des processus, sera désormais également modifiée par le LLM ? Comment le LLM affecte-t-il l’interaction homme-machine ? Comment l’IA générative modifie-t-elle l’interaction homme-machine de la RPA ? Apprenez-en davantage dans un article : L'ère des grands modèles arrive, et l'IA générative basée sur LLM transforme rapidement l'interaction homme-machine RPA ; l'IA générative redéfinit l'interaction homme-machine, et LLM affecte les changements dans l'architecture logicielle RPA. Si vous demandez quelle est la contribution de la RPA au développement et à l’automatisation des programmes, l’une des réponses est qu’elle a modifié l’interaction homme-machine (HCI, h).
 Plaud lance l'enregistreur portable NotePin AI pour 169 $
Aug 29, 2024 pm 02:37 PM
Plaud lance l'enregistreur portable NotePin AI pour 169 $
Aug 29, 2024 pm 02:37 PM
Plaud, la société derrière le Plaud Note AI Voice Recorder (disponible sur Amazon pour 159 $), a annoncé un nouveau produit. Surnommé NotePin, l’appareil est décrit comme une capsule mémoire AI, et comme le Humane AI Pin, il est portable. Le NotePin est
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
L'Ameca deuxième génération est là ! Il peut communiquer couramment avec le public, ses expressions faciales sont plus réalistes et il peut parler des dizaines de langues.
Mar 04, 2024 am 09:10 AM
Le robot humanoïde Ameca est passé à la deuxième génération ! Récemment, lors de la Conférence mondiale sur les communications mobiles MWC2024, le robot le plus avancé au monde, Ameca, est à nouveau apparu. Autour du site, Ameca a attiré un grand nombre de spectateurs. Avec la bénédiction de GPT-4, Ameca peut répondre à divers problèmes en temps réel. "Allons danser." Lorsqu'on lui a demandé si elle avait des émotions, Ameca a répondu avec une série d'expressions faciales très réalistes. Il y a quelques jours à peine, EngineeredArts, la société britannique de robotique derrière Ameca, vient de présenter les derniers résultats de développement de l'équipe. Dans la vidéo, le robot Ameca a des capacités visuelles et peut voir et décrire toute la pièce et des objets spécifiques. Le plus étonnant, c'est qu'elle peut aussi
 GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
La génération améliorée de récupération de graphiques (GraphRAG) devient progressivement populaire et est devenue un complément puissant aux méthodes de recherche vectorielles traditionnelles. Cette méthode tire parti des caractéristiques structurelles des bases de données graphiques pour organiser les données sous forme de nœuds et de relations, améliorant ainsi la profondeur et la pertinence contextuelle des informations récupérées. Les graphiques présentent un avantage naturel dans la représentation et le stockage d’informations diverses et interdépendantes, et peuvent facilement capturer des relations et des propriétés complexes entre différents types de données. Les bases de données vectorielles sont incapables de gérer ce type d'informations structurées et se concentrent davantage sur le traitement de données non structurées représentées par des vecteurs de grande dimension. Dans les applications RAG, la combinaison de données graphiques structurées et de recherche de vecteurs de texte non structuré nous permet de profiter des avantages des deux en même temps, ce dont discutera cet article. structure
