
 Périphériques technologiques
IA
Terence Tao l'a traité d'expert après l'avoir vu ! Google et d'autres ont utilisé LLM pour prouver automatiquement des théorèmes et ont remporté les meilleurs articles de la conférence. Plus le contexte est complet, meilleure est la preuve.
Périphériques technologiques
IA
Terence Tao l'a traité d'expert après l'avoir vu ! Google et d'autres ont utilisé LLM pour prouver automatiquement des théorèmes et ont remporté les meilleurs articles de la conférence. Plus le contexte est complet, meilleure est la preuve.
Terence Tao l'a traité d'expert après l'avoir vu ! Google et d'autres ont utilisé LLM pour prouver automatiquement des théorèmes et ont remporté les meilleurs articles de la conférence. Plus le contexte est complet, meilleure est la preuve.

L'arbre de compétences de Transformer devient de plus en plus puissant.
Des chercheurs de l'Université du Massachusetts, de Google et de l'Université de l'Illinois à Urbana-Champaign (UIUC) ont récemment publié un article dans lequel ils ont réussi à générer automatiquement des preuves complètes de théorèmes en utilisant de grands modèles de langage.

Adresse papier : https://arxiv.org/pdf/2303.04910.pdf
Cette œuvre porte le nom de Baldur (le frère de Thor dans la mythologie nordique), et c'est la première fois que Transformer peut générer une preuve complète, montre également que les preuves précédentes du modèle peuvent être améliorées en fournissant au modèle un contexte supplémentaire.
Cet article a été publié à l'ESEC/FSE (ACM European Joint Conference on Software Engineering and Symposium on Fundamentals of Software Engineering) en décembre 2023 et a remporté le Outstanding Paper Award.
Comme nous le savons tous, les bugs sont inévitables dans les logiciels, ce qui peut ne pas poser trop de problèmes pour les applications générales ou les sites Web. Cependant, pour les logiciels derrière les systèmes critiques, tels que les protocoles de cryptage, les dispositifs médicaux et les navettes spatiales, nous devons nous assurer qu'il n'y a pas de bugs.
- La révision et les tests généraux du code ne peuvent pas donner cette garantie, qui nécessite une vérification formelle.
Pour la vérification formelle, l'explication donnée par ScienceDirect est :
le processus de vérification mathématique que le comportement d'un système, décrit à l'aide d'un modèle formel, satisfait une propriété donnée, également décrite à l'aide d'un modèle formel
fait référence au processus de vérification mathématique si le comportement d'un système décrit à l'aide d'un modèle formel satisfait des propriétés données.
Pour faire simple, il utilise des méthodes d'analyse mathématique pour construire un modèle via un moteur d'algorithme pour effectuer une analyse et une vérification exhaustives de l'espace d'état de la conception à tester.
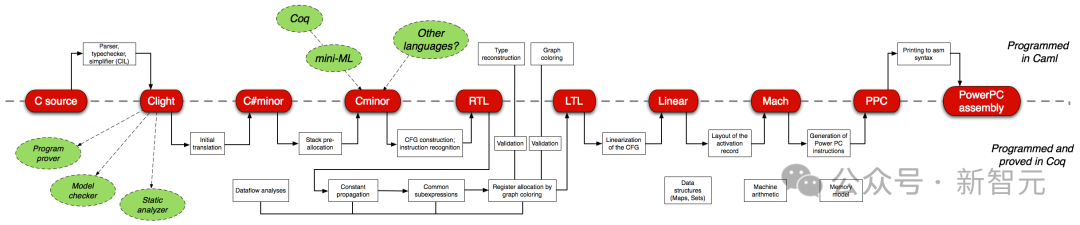
La vérification formelle des logiciels est l'une des tâches les plus difficiles pour les ingénieurs logiciels. Par exemple, CompCert, un compilateur C vérifié avec le prouveur de théorème interactif Coq, est le seul compilateur utilisé par les omniprésents GCC et LLVM, entre autres.
Cependant, le coût de la vérification formelle manuelle (écriture de preuves) est assez énorme - la preuve d'un compilateur C est plus de trois fois supérieure au code du compilateur lui-même.
Ainsi, la vérification formelle en elle-même est une tâche « à forte intensité de main-d'œuvre », et les chercheurs explorent également des méthodes automatisées.
Les assistants de preuve tels que Coq et Isabelle entraînent un modèle pour prédire une étape de preuve à la fois et utilisent le modèle pour rechercher l'espace de preuve possible.
Le Baldur dans cet article a introduit pour la première fois la capacité des grands modèles de langage dans ce domaine, une formation sur le texte et le code en langage naturel et un réglage fin de la preuve
Baldur peut générer une preuve complète. du théorème en une seule fois, plutôt que de le faire étape par étape.
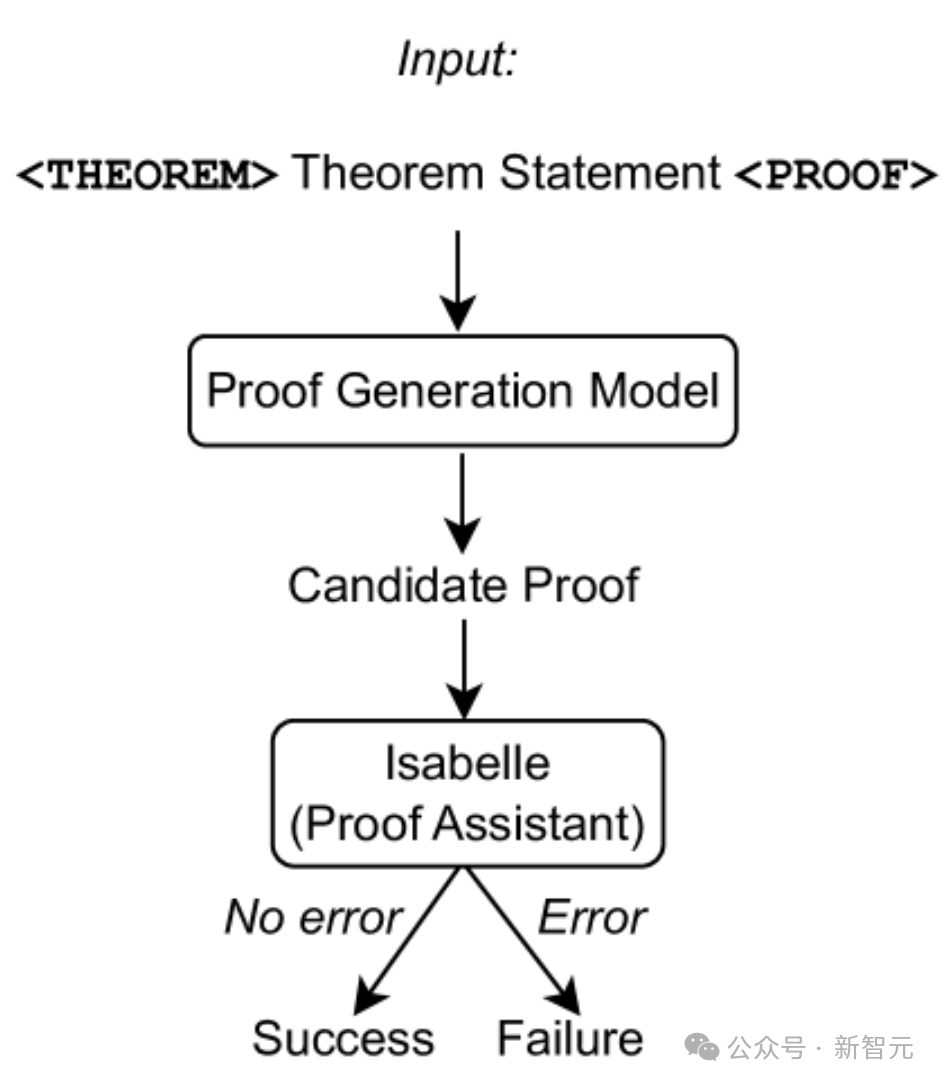
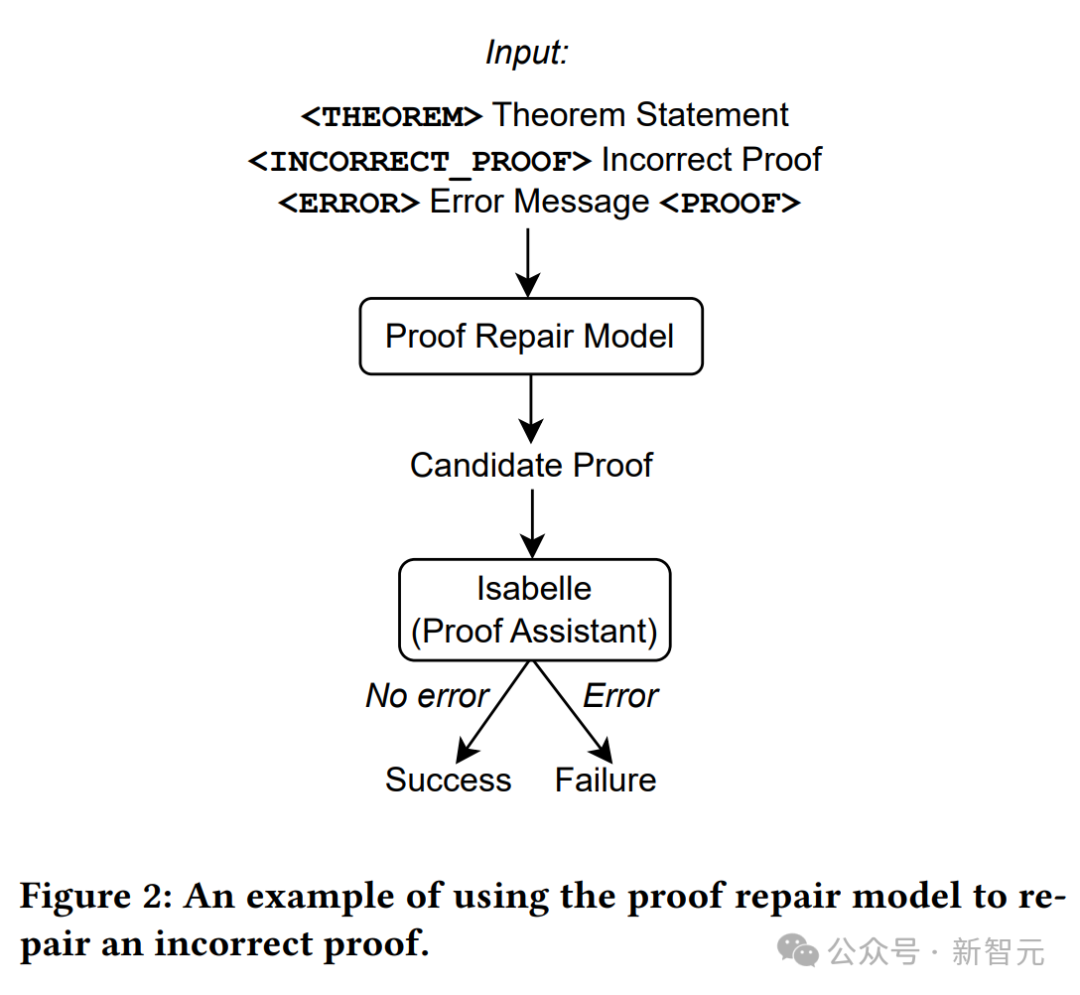
Comme le montre la figure ci-dessus, seules les déclarations de théorème sont utilisées comme entrée dans le modèle de génération de preuves, puis les tentatives de preuve sont extraites du modèle et Isabelle est utilisée pour effectuer la vérification des preuves.
Si Isabelle accepte la tentative de preuve sans erreurs, la preuve est réussie ; sinon, une autre tentative de preuve est extraite du modèle de génération de preuve.
Baldur est évalué sur un benchmark de 6336 théorèmes Isabelle/HOL et leurs preuves, démontrant empiriquement l'efficacité de la génération de preuves complètes, de la réparation et de l'ajout de contexte.
De plus, la raison pour laquelle cet outil s'appelle Baldur est peut-être parce que le meilleur outil de génération automatique de preuves actuellement s'appelle Thor.
Thor a un taux de preuve plus élevé (57 %). Il utilise un modèle de langage plus petit combiné à une méthode de recherche dans l'espace de preuve possible pour prédire la prochaine étape de la preuve, tandis que l'avantage de Baldur est sa capacité à générer des preuves complètes.

Mais les deux frères Thor et Baldur peuvent également travailler ensemble, ce qui pourrait augmenter le taux de preuve à près de 66%.
Générer automatiquement des preuves complètes
Baldur est alimenté par Minerva, le grand modèle de langage de Google, qui est formé sur des articles scientifiques et des pages Web contenant des expressions mathématiques et affiné sur des données sur les preuves et les théorèmes.
Baldur peut travailler avec Isabelle, l'assistante de démonstration du théorème, qui vérifie les résultats de la preuve. Lorsqu'on lui a donné un théorème, Baldur était capable de générer une preuve complète dans près de 41 % du temps.
Pour améliorer encore les performances de Baldur, les chercheurs ont fourni des informations contextuelles supplémentaires au modèle (telles que d'autres définitions ou des énoncés de théorèmes dans des documents théoriques), ce qui a augmenté le taux de preuve à 47,5 %.
Cela signifie que Baldur est capable de prendre le contexte et de l'utiliser pour prédire de nouvelles preuves correctes - tout comme les programmeurs qui sont plus susceptibles de corriger les bogues dans leurs programmes lorsqu'ils comprennent les méthodes et le code pertinents.
Voici un exemple (théorème fun_sum_commute) :

Ce théorème vient d'un projet appelé Polynomials dans les archives de preuves formelles.
Lors de l'écriture manuelle d'une preuve, deux cas sont distingués : l'ensemble est fini ou non fini :

Donc, pour le modèle, l'entrée est l'énoncé du théorème, et la sortie cible est cet Humain -des preuves écrites.
Baldur a reconnu la nécessité de l'induction ici et a appliqué une règle d'induction spéciale appelée infinite_finite_induct, qui suit la même approche générale que les preuves écrites humaines, mais est plus concise.
Et comme l'induction est requise, le Sledgehammer utilisé par Isabelle ne peut pas prouver ce théorème par défaut.
Formation
Pour entraîner le modèle de génération de preuves, les chercheurs ont construit un nouvel ensemble de données de génération de preuves.
L'ensemble de données existant contient des exemples d'une seule étape de preuve, et chaque exemple de formation comprend l'état de preuve (entrée) et la prochaine étape de preuve à appliquer (objectif).
Étant donné un ensemble de données contenant une seule étape de preuve, vous devez ici créer un nouvel ensemble de données afin d'entraîner le modèle à prédire l'intégralité de la preuve en même temps.
Les chercheurs ont extrait les étapes de preuve de chaque théorème de l'ensemble de données et les ont concaténées pour reconstruire la preuve originale.
Proof fix
Toujours en prenant le fun_sum_commute ci-dessus comme exemple,

La première tentative de preuve générée par Baldur a échoué dans le vérificateur de preuves.
Baldur a essayé d'appliquer l'induction mais n'a pas réussi à décomposer d'abord la preuve en deux cas (ensemble fini contre ensemble infini). Isabelle renvoie le message d'erreur suivant :

Pour dériver un exemple de formation à la réparation de preuves à partir de ces chaînes, ici les déclarations de théorème, les tentatives de preuve échouées et les messages d'erreur sont concaténés en entrée, et une preuve écrite par l'homme correcte est utilisée comme cible.
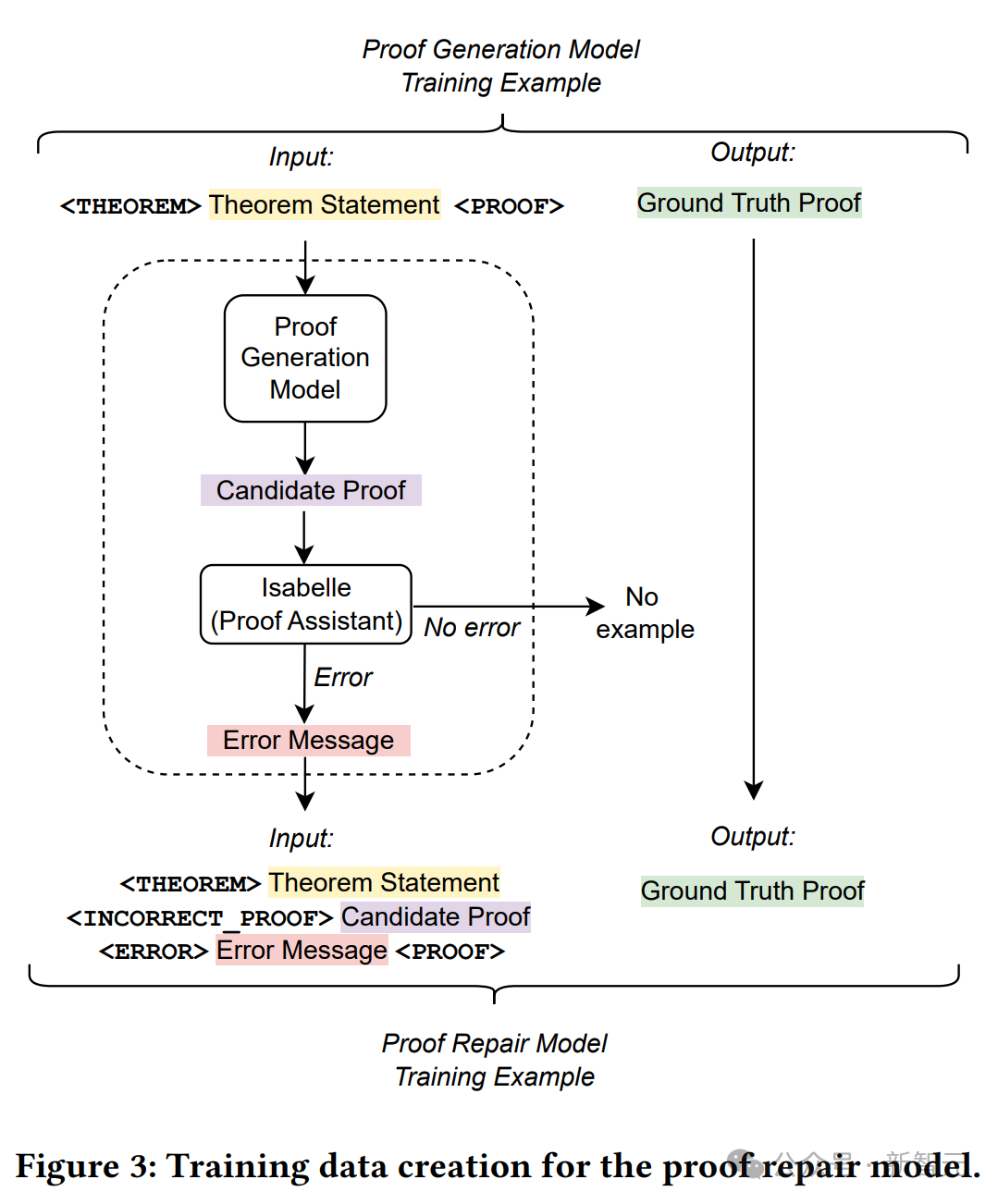
La figure ci-dessus détaille le processus de création des données d'entraînement.
Utilisez un modèle de génération de preuves pour échantillonner des preuves avec une température de 0 pour chaque question de l'ensemble de formation d'origine.
Utilisez l'assistant de vérification linguistique pour enregistrer toutes les preuves ayant échoué et leurs messages d'erreur, puis procédez à la création d'un nouvel ensemble de formation de correction de preuves.
Pour chaque exemple de formation original, concaténez l'énoncé du théorème, la preuve candidate (incorrecte) générée par le modèle de génération de preuve et le message d'erreur correspondant pour obtenir la séquence d'entrée du nouvel exemple de formation.
Ajouter un contexte
Ajoutez des lignes du fichier théorique avant les énoncés du théorème comme contexte supplémentaire. Par exemple, l'image ci-dessous ressemble à ceci : Le modèle de génération de preuves avec contexte dans Baldur peut utiliser ces informations supplémentaires. Les chaînes qui apparaissent dans les déclarations du théorème fun_sum_commute apparaissent à nouveau dans ce contexte, de sorte que les informations supplémentaires qui les entourent peuvent aider le modèle à faire de meilleures prédictions.
 Le contexte peut être un énoncé (théorème, définition, preuve) ou une annotation en langage naturel.
Le contexte peut être un énoncé (théorème, définition, preuve) ou une annotation en langage naturel.
Pour exploiter la longueur d'entrée disponible de LLM, les chercheurs ont d'abord ajouté jusqu'à 50 énoncés du même fichier théorique.
Pendant la formation, toutes ces instructions sont d'abord tokenisées, puis le côté gauche de la séquence est tronqué pour s'adapter à la longueur d'entrée.
La figure ci-dessus montre la relation entre le taux de réussite de la preuve et le nombre de tentatives de preuve pour les modèles génératifs contextuels et sans contexte. Nous pouvons voir que les modèles génératifs de preuve avec contexte surpassent systématiquement les modèles génératifs simples.
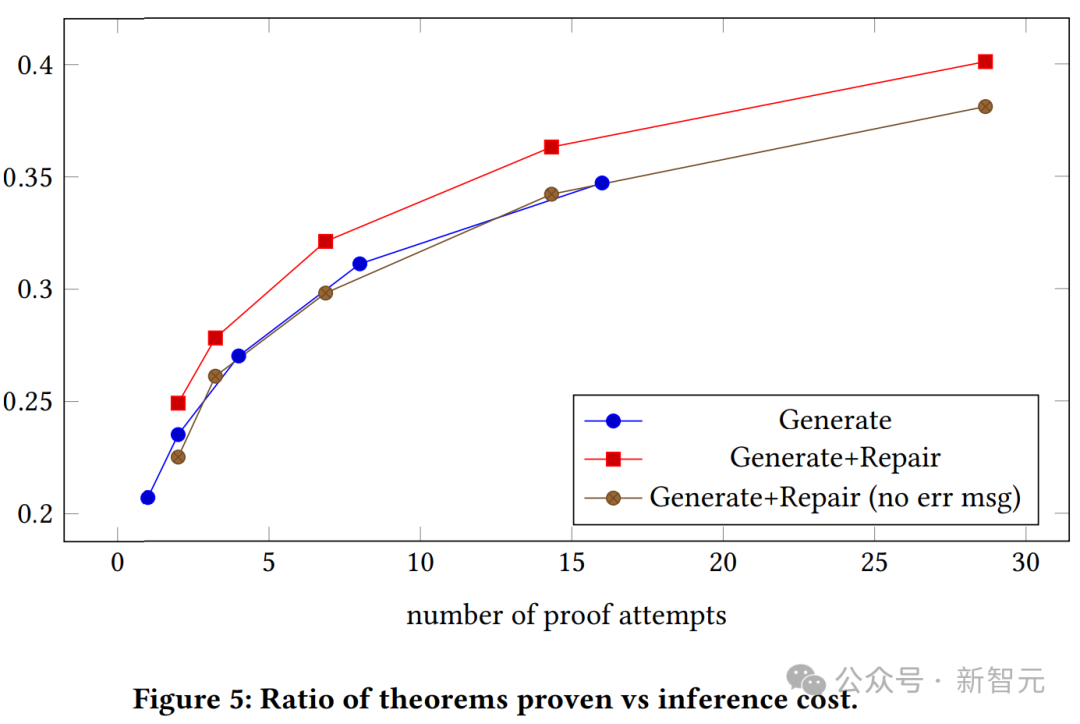
Le graphique ci-dessus montre le rapport entre les théorèmes vérifiés et les coûts d'inférence pour des modèles de différentes tailles et températures.
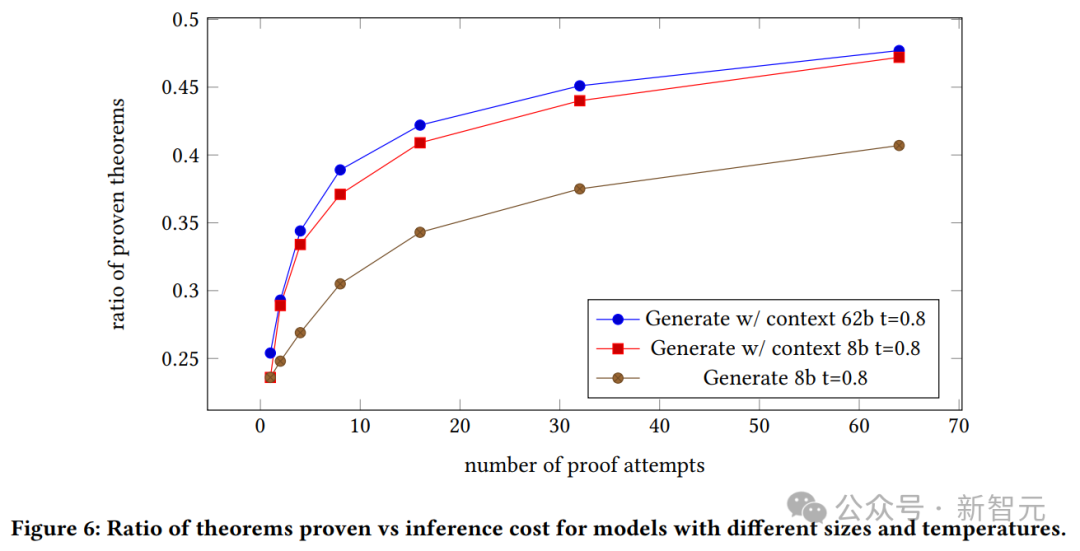 Nous pouvons voir le taux de réussite de la preuve du modèle généré, et la relation entre le contexte du modèle 8B et du modèle 62B et le nombre de tentatives de preuve.
Nous pouvons voir le taux de réussite de la preuve du modèle généré, et la relation entre le contexte du modèle 8B et du modèle 62B et le nombre de tentatives de preuve.
Le modèle 62B avec contexte prouve que le modèle génératif surpasse le modèle 8B avec contexte.
Cependant, les auteurs soulignent ici qu'en raison du coût élevé de ces expériences et de leur incapacité à ajuster les hyperparamètres, le modèle 62B peut être plus performant s'il est optimisé.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravelelognent Model Retrieval: Faconttement l'obtention de données de base de données Eloquentorm fournit un moyen concis et facile à comprendre pour faire fonctionner la base de données. Cet article présentera en détail diverses techniques de recherche de modèles éloquentes pour vous aider à obtenir efficacement les données de la base de données. 1. Obtenez tous les enregistrements. Utilisez la méthode All () pour obtenir tous les enregistrements dans la table de base de données: usApp \ Modèles \ Post; $ poters = post :: all (); Cela rendra une collection. Vous pouvez accéder aux données à l'aide de Foreach Loop ou d'autres méthodes de collecte: ForEach ($ PostsAs $ POST) {echo $ post->
