

Il y a une semaine, OpenAI a offert des avantages aux utilisateurs. Ils ont résolu le problème de la paresse de GPT-4 et ont introduit 5 nouveaux modèles, y compris le modèle d'intégration text-embedding-3-small, qui est plus petit et plus efficace.
Les intégrations sont des séquences de nombres utilisées pour représenter des concepts en langage naturel, en code, etc. Ils aident les modèles d'apprentissage automatique et d'autres algorithmes à mieux comprendre comment le contenu est lié et facilitent l'exécution de tâches telles que le clustering ou la récupération. Dans le domaine de la PNL, l’intégration joue un rôle très important.
Cependant, le modèle d'intégration d'OpenAI n'est pas gratuit pour tout le monde. Par exemple, text-embedding-3-small facture 0,00002 $ pour 1 000 jetons.
Maintenant, un meilleur modèle d'intégration que text-embedding-3-small est ici, et il est gratuit.
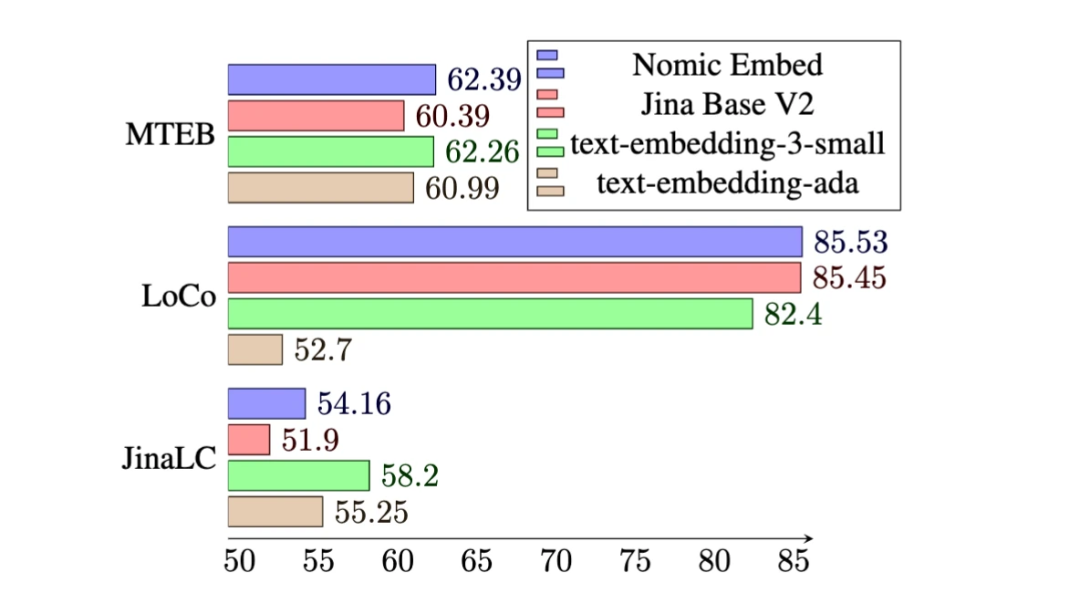
Nomic AI, une startup d'IA, a récemment publié le premier modèle d'intégration open source, données ouvertes, poids ouverts et code de formation ouvert - Nomic Embed. Le modèle est entièrement reproductible et auditable, avec une longueur de contexte de 8 192. Nomic Embed a battu les modèles text-embedding-3-small et text-embedding-ada-002 d'OpenAI dans les benchmarks à contexte court et long. Cette réalisation marque une avancée importante de Nomic AI dans le domaine des modèles embarqués.

L'intégration de texte est un composant clé des applications PNL modernes, offrant des capacités de génération d'augmentation de récupération (RAG) pour alimenter le LLM et la recherche sémantique. Cette technologie permet un traitement plus efficace en codant les informations sémantiques d'une phrase ou d'un document dans un vecteur de faible dimension et en l'appliquant à des applications en aval telles que le clustering pour la visualisation, la classification et la récupération d'informations de données. Actuellement, le text-embedding-ada-002 d'OpenAI est l'un des modèles d'intégration de texte à contexte long les plus populaires, prenant en charge jusqu'à 8 192 longueurs de contexte. Malheureusement, Ada est une source fermée et ses données de formation ne peuvent pas être auditées, ce qui limite sa crédibilité. Malgré cela, le modèle est toujours largement utilisé et fonctionne bien dans de nombreuses tâches de PNL. À l’avenir, nous espérons développer des modèles d’intégration de texte plus transparents et vérifiables pour améliorer leur crédibilité et leur fiabilité. Cela contribuera à promouvoir le développement du domaine de la PNL et à fournir des capacités de traitement de texte plus efficaces et plus précises pour diverses applications.
Les modèles d'intégration de texte à contexte long open source les plus performants, tels que E5-Mistral et jina-embeddings-v2-base-en, peuvent avoir certaines limitations. D’une part, en raison de la grande taille du modèle, il peut ne pas convenir à un usage général. D’un autre côté, ces modèles pourraient ne pas être en mesure de surpasser les niveaux de performances de leurs homologues OpenAI. Par conséquent, ces facteurs doivent être pris en compte lors du choix d’un modèle adapté à une tâche spécifique. La sortie de
Nomic-embed change cela. Le modèle ne comporte que 137 millions de paramètres, ce qui est très simple à déployer et peut être formé en 5 jours.

Adresse de l'article : https://static.nomic.ai/reports/2024_Nomic_Embed_Text_Technical_Report.pdf
Titre de l'article : Nomic Embed : Formation d'un intégrateur de texte à contexte long reproductible
Projet Adresse : https://github.com/nomic-ai/contrastors
L'un des principaux inconvénients des encodeurs de texte existants est qu'ils sont limités à la longueur de la séquence, qui est limité à 512 jetons. Pour entraîner un modèle pour des séquences plus longues, la première chose à faire est d'ajuster BERT afin qu'il puisse prendre en charge de longues longueurs de séquence. La longueur de séquence cible pour cette étude était de 8 192.
Formation BERT avec une durée de contexte de 2048
Cette étude suit un pipeline d'apprentissage contrastif en plusieurs étapes pour former l'intégration nomique. Tout d'abord, l'étude a effectué l'initialisation BERT étant donné que bert-base ne peut gérer qu'une longueur de contexte allant jusqu'à 512 jetons, l'étude a décidé de former son propre BERT avec une longueur de contexte de 2 048 jetons - nomic-bert-2048.
Inspirée par MosaicBERT, l'équipe de recherche a apporté quelques modifications au processus de formation de BERT, notamment :
et a effectué les optimisations de formation suivantes :
Lors de l'entraînement, cette étude entraîne toutes les étapes avec une longueur de séquence maximale de 2048 et utilise l'interpolation dynamique NTK pour s'étendre à 8192 longueurs de séquence pendant l'inférence.
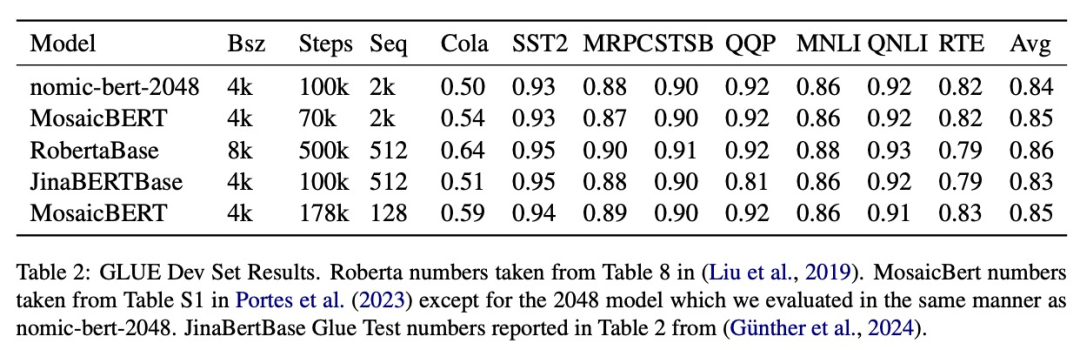
L'étude a évalué la qualité de nomic-bert-2048 sur le benchmark standard GLUE et a constaté que ses performances étaient comparables à celles d'autres modèles BERT, mais avec l'avantage de longueurs de contexte significativement plus longues.
Formation comparative de nomic-embed
Cette étude utilise nomic-bert-2048 pour initialiser la formation de nomic-embed. L'ensemble de données de comparaison comprend environ 235 millions de paires de textes et sa qualité a été largement vérifiée à l'aide de Nomic Atlas lors de la collecte.
Sur le benchmark MTEB, nomic-embed surpasse text-embedding-ada-002 et jina-embeddings-v2-base-en.
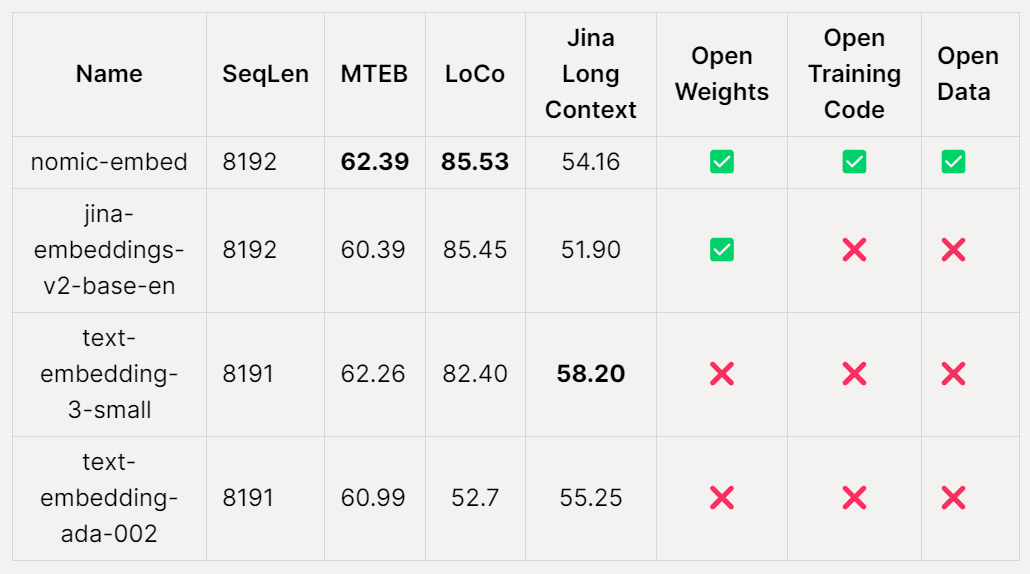
Cependant, MTEB ne peut pas évaluer les tâches contextuelles longues. Par conséquent, cette étude évalue l'intégration nomique sur le benchmark LoCo récemment publié ainsi que sur le benchmark Jina Long Context.
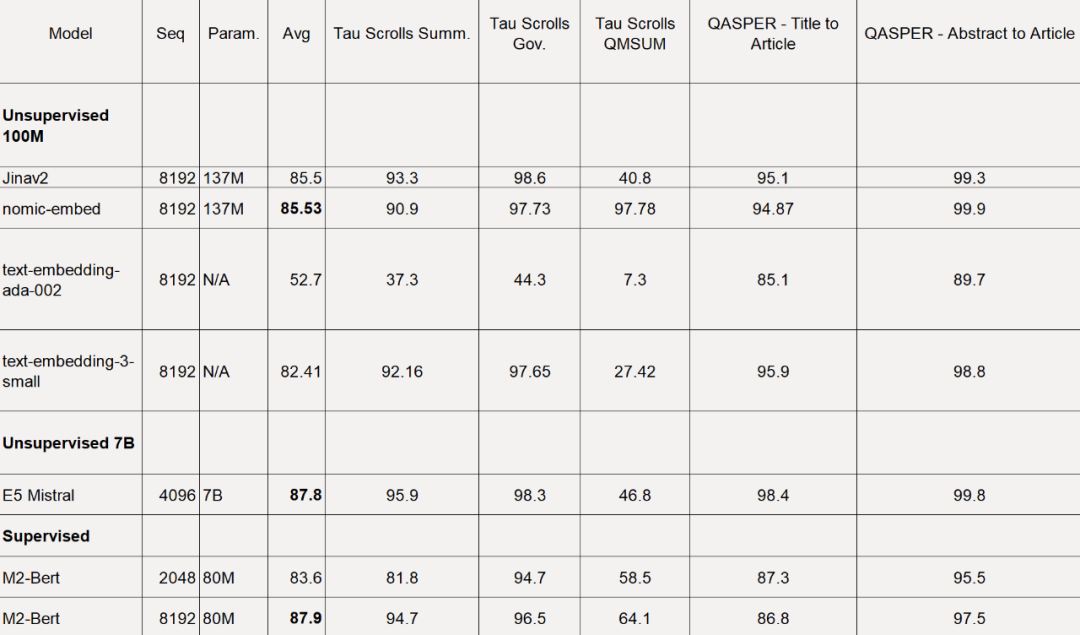
Pour le benchmark LoCo, l'étude est évaluée séparément par catégorie de paramètres et selon que l'évaluation est réalisée dans un cadre supervisé ou non supervisé.
Comme le montre le tableau ci-dessous, Nomic Embed est le modèle non supervisé à 100 millions de paramètres le plus performant. Notamment, Nomic Embed est comparable aux modèles les plus performants de la catégorie de paramètres 7B ainsi qu'aux modèles formés dans un environnement supervisé spécifiquement pour le benchmark LoCo :
Performance globale de Nomic Embed sur le benchmark Jina Long Context Effectue également mieux que jina-embeddings-v2-base-en, mais Nomic Embed ne fonctionne pas mieux que OpenAI ada-002 ou text-embedding-3-small sur ce benchmark :
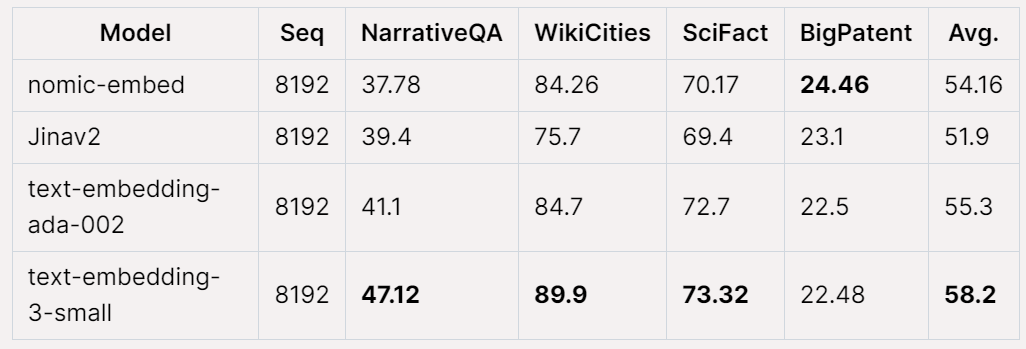
Dans l'ensemble, en d'autres termes, Nomic Embed surpasse OpenAI Ada-002 et text-embedding-3-small sur le benchmark 2/3.
L'étude indique que la meilleure option pour utiliser Nomic Embed est l'API Nomic Embedding, et la façon d'obtenir l'API est la suivante :

Enfin, l'accès aux données : Afin d'accéder aux données complètes, l'étude a fourni aux utilisateurs des clés d'accès Cloudflare R2 (un service de stockage d'objets similaire à AWS S3). Pour y accéder, les utilisateurs doivent d'abord créer un compte Nomic Atlas et suivre les instructions dans le référentiel des contrasteurs.
adresse des contrasteurs : https://github.com/nomic-ai/contrastors?tab=readme-ov-file#data-access
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que signifie l'intervalle ?
Que signifie l'intervalle ?
 Que comprend le stockage par cryptage des données ?
Que comprend le stockage par cryptage des données ?
 Utilisation de setInterval dans JS
Utilisation de setInterval dans JS
 Quels sont les attributs du javabean ?
Quels sont les attributs du javabean ?
 Quels sont les paramètres du chapiteau ?
Quels sont les paramètres du chapiteau ?
 Où regarder les rediffusions en direct de Douyin
Où regarder les rediffusions en direct de Douyin
 Solution au problème selon lequel les fichiers exe ne peuvent pas être ouverts dans le système win10
Solution au problème selon lequel les fichiers exe ne peuvent pas être ouverts dans le système win10
 équipebition
équipebition
 Tutoriel de configuration des variables d'environnement Java
Tutoriel de configuration des variables d'environnement Java








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



