
 Périphériques technologiques
IA
Le premier grand modèle 100% open source de l'histoire est là ! Divulgation record du code/poids/ensembles de données/processus de formation complet, AMD peut le former
Périphériques technologiques
IA
Le premier grand modèle 100% open source de l'histoire est là ! Divulgation record du code/poids/ensembles de données/processus de formation complet, AMD peut le former
Le premier grand modèle 100% open source de l'histoire est là ! Divulgation record du code/poids/ensembles de données/processus de formation complet, AMD peut le former

Les modèles linguistiques sont au cœur de la technologie de traitement du langage naturel (NLP) depuis de nombreuses années. Compte tenu de l’énorme valeur commerciale de ce modèle, les détails techniques du modèle le plus avancé n’ont pas été rendus publics.
Maintenant, le grand modèle véritablement entièrement open source est là !
Des chercheurs de l'Allen Institute for Artificial Intelligence, de l'Université de Washington, de l'Université de Yale, de l'Université de New York et de l'Université Carnegie Mellon ont récemment collaboré pour publier un ouvrage important qui deviendra important pour l'étape importante de la communauté open source de l'IA.
Ils ont rendu presque toutes les données et informations en cours de formation d'un grand modèle à partir de zéro en open source !
Papier : https://allenai.org/olmo/olmo-paper.pdf
Poids : https://huggingface.co/allenai/OLMo-7B
Code : https ://github.com/allenai/OLMo
Données : https://huggingface.co/datasets/allenai/dolma
Évaluation : https://github.com/allenai/OLMo-Eval
Adaptation : https://github.com/allenai/open-instruct

Plus précisément, cette expérience Open Language Model (OLMo) lancée par Allen Artificial Intelligence Institute et plateforme de formation, qui fournit une source entièrement open source grand modèle, ainsi que toutes les données et détails techniques liés à la formation et au développement de ce modèle -
Formation et modélisation : Il comprend les poids complets du modèle, le code d'entraînement, les journaux d'entraînement, les études d'ablation, les métriques d'entraînement, et code d'inférence.
Corpus de pré-entraînement : Un corpus open source pré-entraîné contenant jusqu'à 3T tokens, ainsi que le code pour générer ces données d'entraînement.
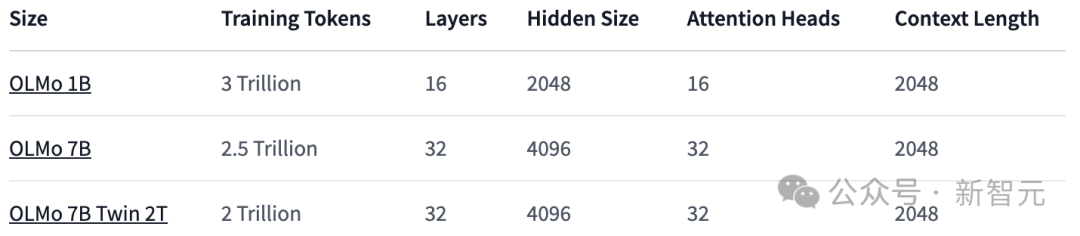
Paramètres du modèle : Le framework OLMo fournit quatre modèles de taille 7B sous différentes architectures, optimiseurs et systèmes matériels de formation, ainsi qu'un modèle de taille 1B, tous les modèles sont au moins des jetons 2T. La formation a été menée sur .
Dans le même temps, le code utilisé pour l'inférence du modèle, divers indicateurs du processus de formation et les journaux de formation sont également fournis.
7B : OLMo 7B, OLMo 7B (non recuit), OLMo 7B-2T, OLMo-7B-Twin-2T
Outils d'évaluation : a divulgué les outils d'évaluation au cours du processus de développement La suite comprend plus de 500 points de contrôle et codes d'évaluation pour 1 000 étapes de chaque processus de formation de modèle.
Toutes les données sont sous licence pour une utilisation sous Apache 2.0 (gratuit pour un usage commercial).

Un open source aussi approfondi semble établir un modèle pour la communauté open source - à l'avenir, si vous n'êtes pas open source comme moi, ne dites pas que vous êtes un modèle open source.
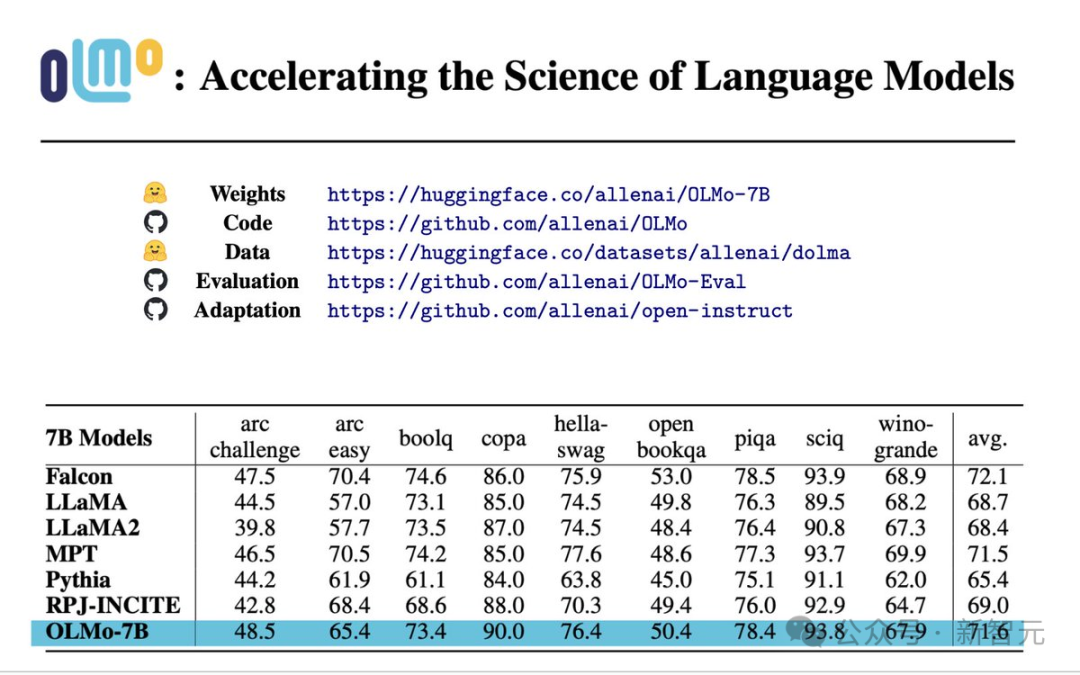
Évaluation des performances
D'après les résultats de l'évaluation de base, OLMo-7B est légèrement meilleur que les modèles open source similaires.
Parmi les 9 premières évaluations, OLMo-7B s'est classé parmi les trois premiers dans 8 d'entre elles, et 2 d'entre elles ont surpassé tous les autres modèles.
OLMo-7B surpasse Llama 2 sur de nombreuses tâches de génération ou de compréhension en lecture (telles que TruthfulQA), mais est moins performant sur certaines tâches de questions et réponses populaires (telles que MMLU ou Big-bench Hard).
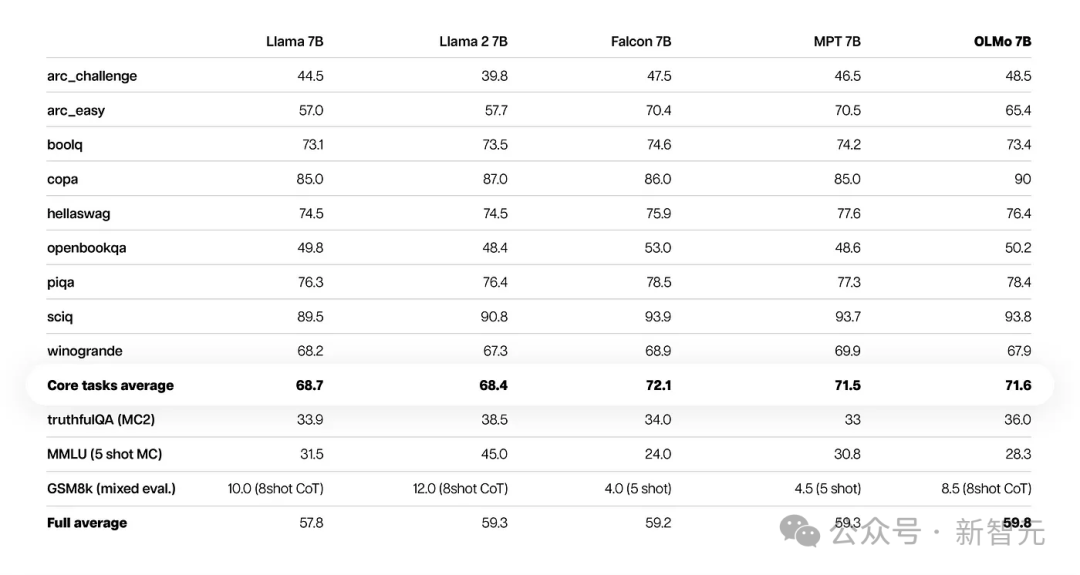
Les 9 premières tâches sont les critères d'évaluation internes des chercheurs pour le modèle pré-entraîné, tandis que les trois tâches suivantes ont été ajoutées pour améliorer le classement HuggingFace Open LLM
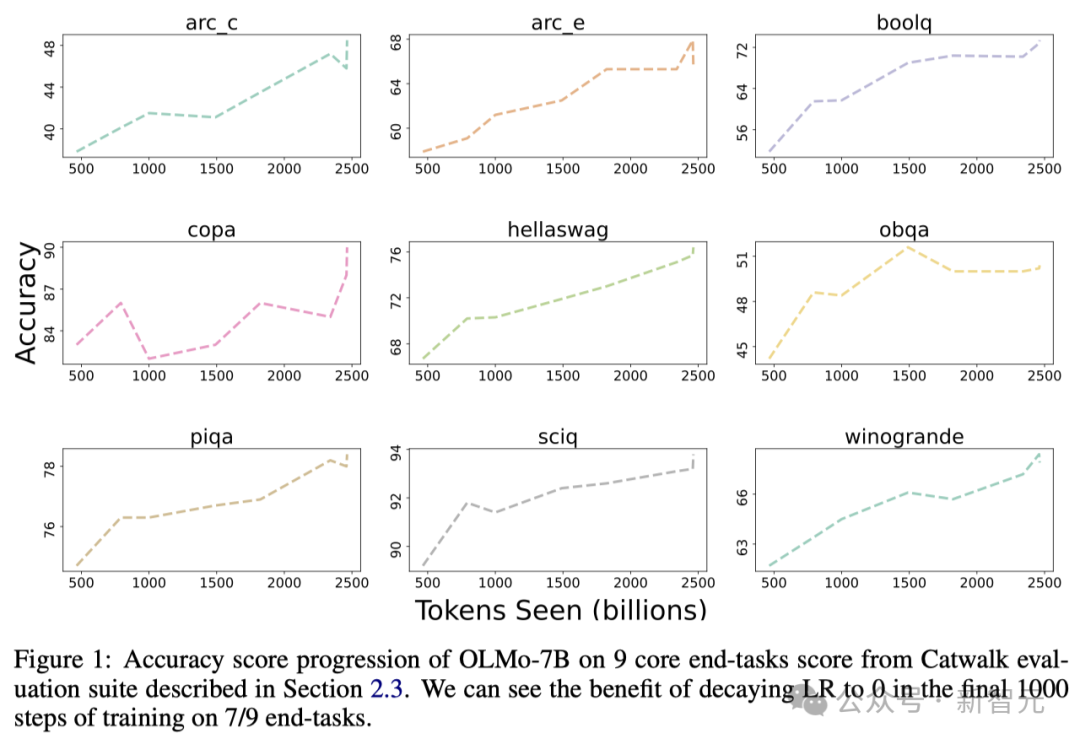
La figure ci-dessous montre la précision des 9 tâches principales. .
À l'exception de l'OBQA, à mesure que l'OLMo-7B reçoit plus de données pour l'entraînement, la précision de presque toutes les tâches montre une tendance à la hausse.
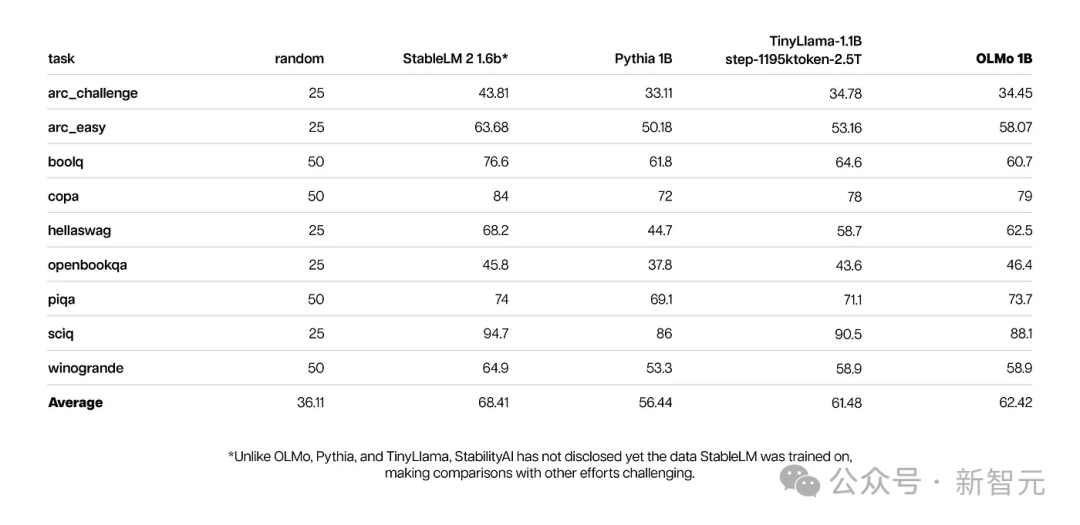
Dans le même temps, les principaux résultats de l'évaluation d'OLMo 1B et de ses modèles similaires montrent qu'OLMo est au même niveau qu'eux.
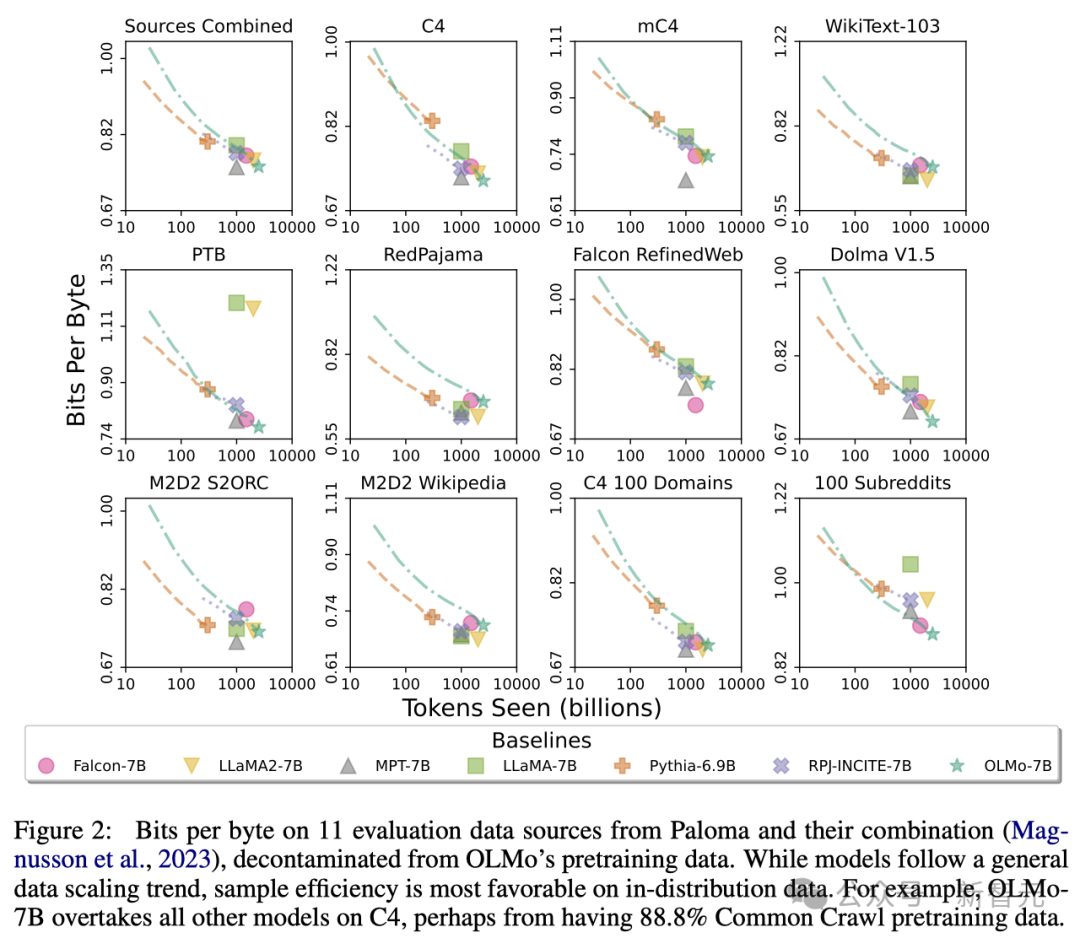
En utilisant Paloma de l'Allen AI Institute (une référence) et les points de contrôle disponibles, les chercheurs ont analysé la relation entre la capacité du modèle à prédire le langage et les facteurs de taille du modèle (tels que le nombre de jetons formés).
On peut voir que l'OLMo-7B est à égalité avec les modèles grand public en termes de performances. Parmi eux, plus le nombre de bits par octet (Bits per Byte) est faible, mieux c'est.
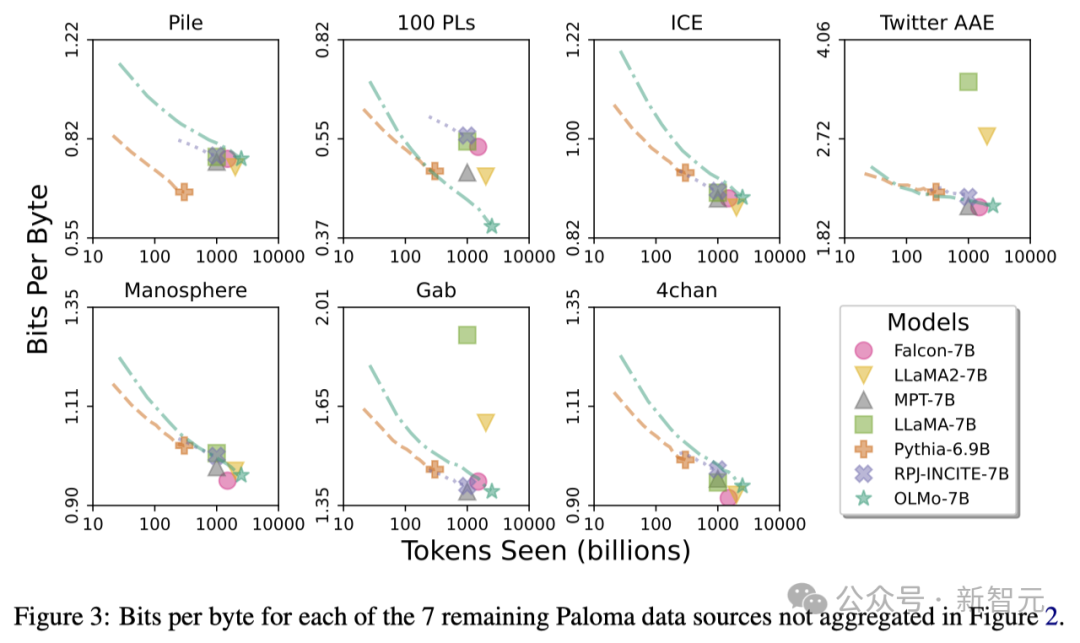
Grâce à ces analyses, les chercheurs ont constaté que l'efficacité du modèle dans le traitement de différentes sources de données varie considérablement, ce qui dépend principalement de la similarité entre les données d'entraînement du modèle et les données d'évaluation.
En particulier, OLMo-7B fonctionne bien sur les sources de données principalement basées sur Common Crawl (telles que C4).
Cependant, OLMo-7B est moins efficace que d'autres modèles sur des sources de données qui ont peu à voir avec le texte de web scraping, telles que WikiText-103, M2D2 S2ORC et M2D2 Wikipedia. L'évaluation de
RedPajama reflète également une tendance similaire, peut-être parce que seuls 2 de ses 7 champs sont dérivés de Common Crawl et que Paloma accorde un poids égal à chaque champ dans chaque source de données.
Étant donné que les sources de données organisées telles que Wikipédia et les articles arXiv fournissent des données beaucoup moins hétérogènes que les textes récupérés sur le Web, il sera plus efficace de maintenir une efficacité élevée sur ces distributions linguistiques à mesure que les ensembles de données de pré-formation continuent de croître en difficulté.
Architecture OLMo
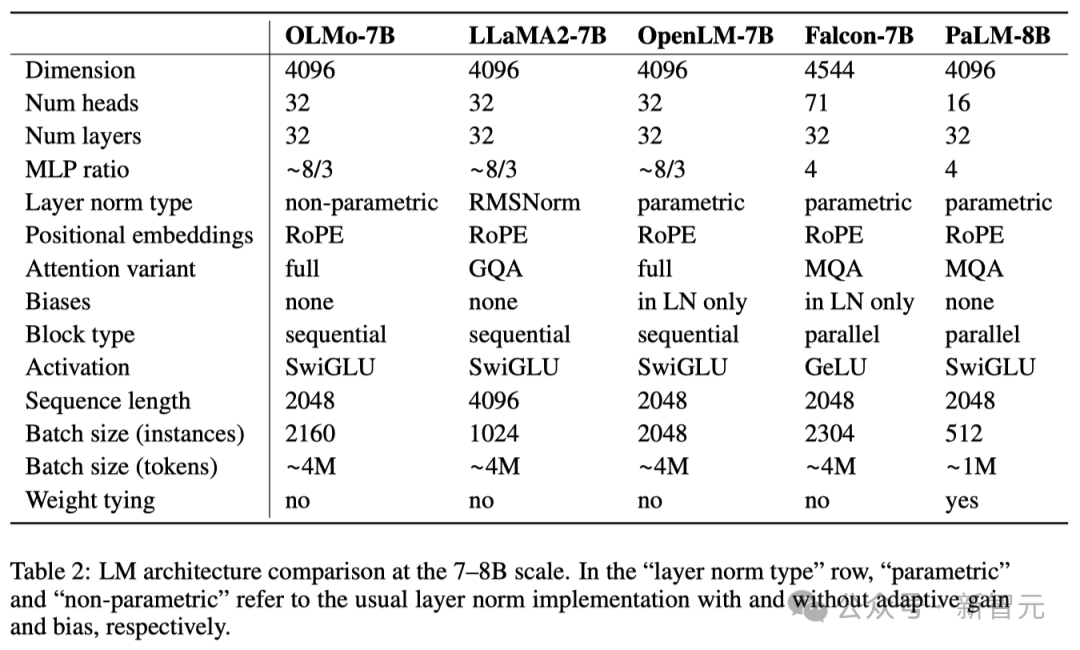
En termes d'architecture de modèle, l'équipe est basée sur l'architecture Transformer uniquement décodeur, adopte la fonction d'activation SwiGLU utilisée par PaLM et Llama et introduit la technologie d'intégration de position de rotation (RoPE). et un tokenizer amélioré basé sur le codage par paires d'octets (BPE) de GPT-NeoX-20B pour réduire les informations personnellement identifiables dans la sortie du modèle.
De plus, afin d'assurer la stabilité du modèle, les chercheurs n'ont pas utilisé de termes de biais (c'est la même chose que PaLM).
Comme le montre le tableau ci-dessous, les chercheurs ont publié deux versions, 1B et 7B, et prévoient également de lancer prochainement une version 65B.
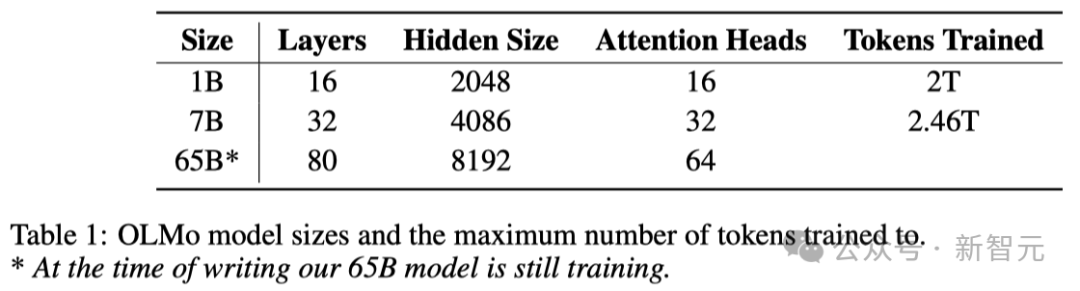
Le tableau ci-dessous fournit une comparaison détaillée des performances de l'architecture 7B avec ces autres modèles à des échelles similaires.
Ensemble de données de pré-formation : Dolma
Bien que les chercheurs aient fait quelques progrès dans l'obtention des paramètres du modèle, le niveau actuel d'ouverture des ensembles de données de pré-formation dans la communauté open source est loin d'être suffisant.
Les données de pré-formation précédentes ne sont souvent pas rendues publiques avec l'open source du modèle (sans parler du modèle fermé).
Et la documentation sur ces données manque souvent de détails suffisants, mais ces détails sont cruciaux pour reproduire la recherche ou comprendre pleinement le travail associé.
Cette situation rend la recherche sur les modèles de langage plus difficile - par exemple, comprendre comment les données de formation affectent les capacités du modèle et ses limites.
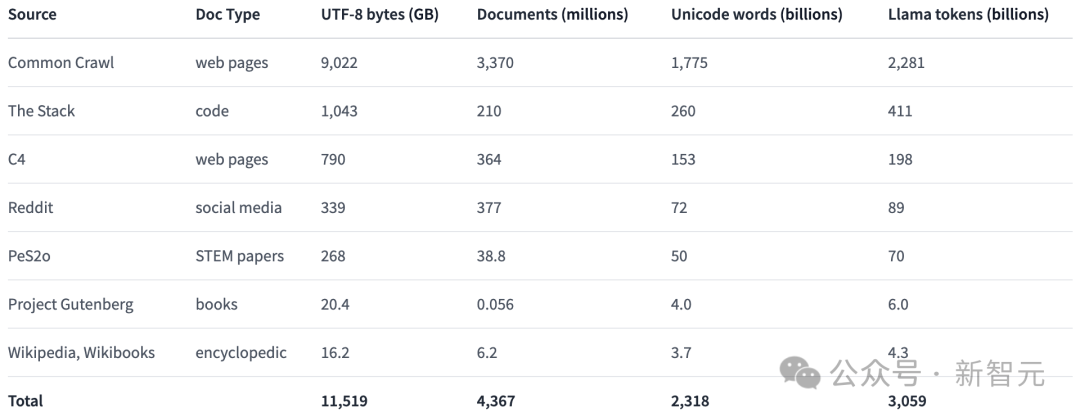
Afin de promouvoir la recherche ouverte dans le domaine de la pré-formation des modèles linguistiques, les chercheurs ont construit et rendu public l'ensemble de données de pré-formation Dolma.
Il s'agit d'un corpus diversifié et multi-sources contenant 3 000 milliards de jetons obtenus à partir de 7 sources de données différentes.
D'une part, ces sources de données sont courantes dans la pré-formation de modèles de langage à grande échelle, et d'autre part, elles sont également accessibles au grand public.
Le tableau ci-dessous donne un aperçu du volume de données provenant de diverses sources de données.
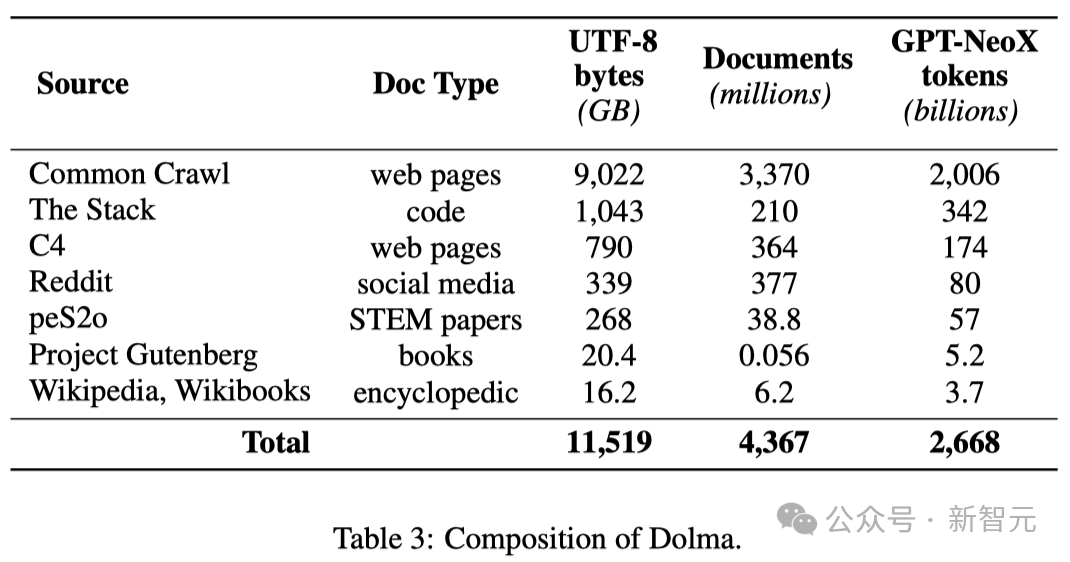
Le processus de construction de Dolma comprend six étapes : filtrage de langue, filtrage de qualité, filtrage de contenu, déduplication, mixage multi-sources et tokenisation.
Pendant le processus de collecte et de publication finale de Dolma, les chercheurs ont veillé à ce que les documents de chaque source de données restent indépendants.
Ils ont également open source un ensemble d'outils efficaces d'organisation des données, qui peuvent aider à approfondir l'étude de Dolma, à reproduire les résultats et à simplifier l'organisation du corpus de pré-formation.
De plus, les chercheurs ont également open source l'outil WIMBD pour faciliter l'analyse des ensembles de données.

Processus de traitement des données réseau

Processus de traitement du code
Formation OLMo
Cadre de formation distribué
Les chercheurs utilisent PyTorch Le cadre FS DP de et les stratégies d'optimisation ZeRO viennent former le modèle . Cette approche réduit efficacement l'utilisation de la mémoire en répartissant les pondérations du modèle et leurs états d'optimisation correspondants sur plusieurs GPU.
Lors du traitement de modèles d'une taille allant jusqu'à 7B, cette technologie permet aux chercheurs de traiter des tailles de micro-lots de 4096 jetons par GPU pour une formation plus efficace.
Pour les modèles OLMo-1B et 7B, les chercheurs ont fixé une taille de lot globale d'environ 4 millions de jetons (2048 instances de données, chaque instance contenant une séquence de 2048 jetons).
Pour le modèle OLMo-65B actuellement en cours de formation, les chercheurs ont adopté une stratégie d'échauffement de la taille du lot, en commençant à environ 2 millions de jetons (1 024 instances de données) et en doublant la taille du lot pour chaque 100 milliards de jetons supplémentaires, jusqu'à ce qu'il soit atteint. atteint finalement une taille d'environ 16 millions de jetons (8192 instances de données).
Afin d'accélérer la formation des modèles, les chercheurs ont utilisé une technologie de formation de précision mixte, qui est implémentée via la configuration interne de FSDP et le module amp de PyTorch.
Cette méthode est spécialement conçue pour garantir que certaines étapes de calcul clés (telles que la fonction softmax) sont toujours effectuées avec la plus grande précision afin de garantir la stabilité du processus d'entraînement.
Pendant ce temps, la plupart des autres calculs utilisent un format demi-précision appelé bfloat16 pour réduire l'utilisation de la mémoire et augmenter l'efficacité des calculs.
Dans des configurations spécifiques, les poids des modèles et l'état de l'optimiseur sont enregistrés avec une précision maximale sur chaque GPU.
Uniquement lors de la propagation avant et arrière du modèle, c'est-à-dire le calcul de la sortie du modèle et la mise à jour des poids, les poids dans chaque module Transformer seront temporairement convertis au format bfloat16.
De plus, lorsque les mises à jour de dégradé seront synchronisées entre les GPU, elles seront également effectuées avec la plus grande précision pour garantir la qualité de l'entraînement.
Optimiseur
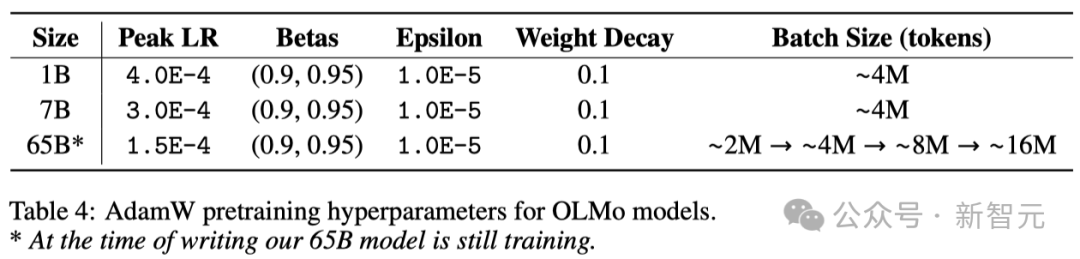
Les chercheurs ont utilisé l'optimiseur AdamW pour ajuster les paramètres du modèle.
Quelle que soit la taille du modèle, les chercheurs augmenteront progressivement le taux d'apprentissage au cours des 5 000 premières étapes de la formation (traitant environ 21 milliards de jetons). Ce processus est appelé échauffement du taux d'apprentissage.
Une fois l'échauffement terminé, le taux d'apprentissage diminuera progressivement de manière linéaire jusqu'à ce qu'il tombe à un dixième du taux d'apprentissage maximum.
De plus, les chercheurs découperont également les gradients des paramètres du modèle pour s'assurer que leur norme L1 totale ne dépasse pas 1,0.
Dans le tableau ci-dessous, les chercheurs comparent la configuration de leur optimiseur à l'échelle du modèle 7B à d'autres grands modèles de langage récents utilisant l'optimiseur AdamW.
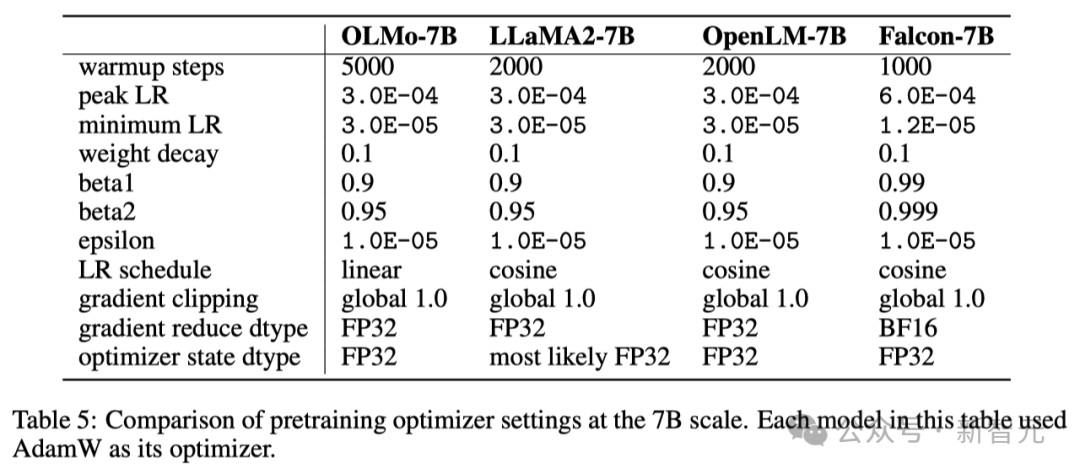
Ensemble de données
Les chercheurs ont utilisé un échantillon de jeton 2T dans l'ensemble de données ouvertes Dolma pour construire leur ensemble de données de formation.
Les chercheurs ont connecté les jetons de chaque document, ont ajouté un jeton EOS spécial à la fin de chaque document, puis ont divisé ces jetons en groupes de 2048 pour former des échantillons de formation.
Ces échantillons d'entraînement seront mélangés aléatoirement de la même manière lors de chaque entraînement. Les chercheurs fournissent également des outils qui permettent à quiconque de récupérer l’ordre exact des données et la composition de chaque lot d’entraînement.
Tous les modèles que les chercheurs ont publiés ont été entraînés pendant au moins un tour (jetons 2T). Certains de ces modèles ont également été entraînés en exécutant une deuxième série d'entraînement sur les données, mais avec un ordre de brassage aléatoire différent.
Selon des recherches antérieures, l'impact de la réutilisation d'une petite quantité de données est minime.
NVIDIA et AMD veulent OUI !
Afin de garantir que la base de code peut fonctionner efficacement sur les GPU NVIDIA et AMD, les chercheurs ont sélectionné deux clusters différents pour les tests de formation de modèles :
À l'aide du supercalculateur LUMI, les chercheurs ont déployé jusqu'à 256 nœuds, chaque nœud est équipé de 4 GPU AMD MI250X, chaque GPU dispose de 128 Go de mémoire et d'un taux de transfert de données de 800 Gbps.
Avec le support de MosaicML (Databricks), les chercheurs ont utilisé 27 nœuds, chaque nœud est équipé de 8 GPU NVIDIA A100, chaque GPU dispose de 40 Go de mémoire et d'un taux de transfert de données de 800 Gbps.
Bien que les chercheurs aient affiné la taille du lot pour améliorer l'efficacité de la formation, après avoir terminé l'évaluation des jetons 2T, il n'y avait presque aucune différence dans les performances des deux clusters.
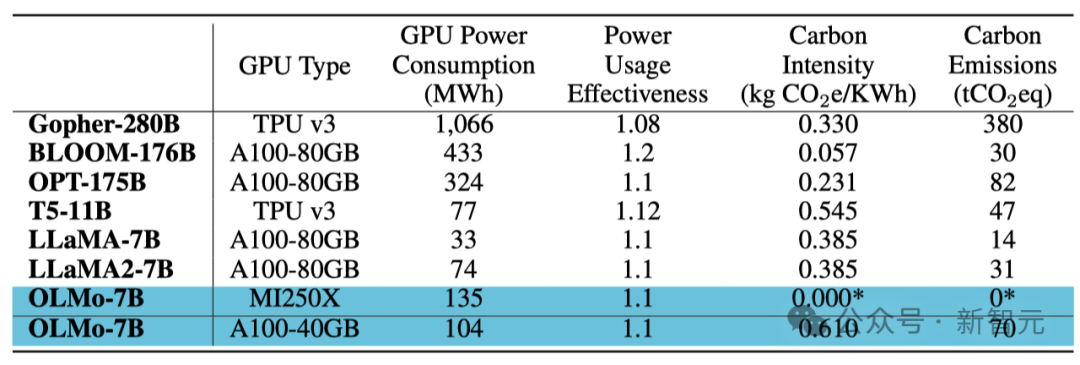
Consommation d'énergie de l'entraînement
Résumé
Différent de la plupart des modèles précédents qui ne fournissent que des poids de modèle et un code d'inférence, les chercheurs ont open source l'intégralité du contenu d'OLMo, y compris les données d'entraînement, le code d'entraînement et d'évaluation, Ainsi que les journaux de formation, les résultats expérimentaux, les résultats importants, les enregistrements de poids et de biais, etc.
De plus, l'équipe étudie comment améliorer l'OLMo grâce à l'optimisation des instructions et à différents types d'apprentissage par renforcement (RLHF). Ces codes, données et modèles affinés seront également open source.
Les chercheurs s'engagent à continuer de soutenir et de développer OLMo et son cadre, à promouvoir le développement de modèles de langage ouverts (LM) et à aider au développement de la communauté de recherche ouverte. À cette fin, les chercheurs prévoient d’introduire davantage de modèles à différentes échelles, de multiples modalités, ensembles de données, mesures de sécurité et méthodes d’évaluation pour enrichir la famille OLMo.
Ils espèrent renforcer le pouvoir de la communauté de recherche open source et déclencher une nouvelle vague d'innovation grâce à la poursuite d'un travail approfondi sur l'open source à l'avenir.
Présentation de l'équipe
Yizhong Wang (王义中)

Yizhong Wang est doctorant à la Paul G. Allen School of Computer Science and Engineering de l'Université de Washington, encadré par Hannaneh Hajishirzi et Noah. Forgeron. Parallèlement, il est également stagiaire de recherche à temps partiel à l'Allen Institute for Artificial Intelligence.
Auparavant, il avait effectué un stage chez Meta AI, Microsoft Research et Baidu NLP. Auparavant, il a obtenu une maîtrise de l'Université de Pékin et une licence de l'Université Jiao Tong de Shanghai.
Ses axes de recherche sont le traitement du langage naturel, l'apprentissage automatique et le grand modèle linguistique (LLM).
- Adaptabilité du LLM : Comment construire et évaluer plus efficacement des modèles capables de suivre des instructions ? Quels facteurs devrions-nous prendre en compte lors du réglage fin de ces modèles, et comment affectent-ils la généralisabilité du modèle ? Quels types de supervision sont à la fois efficaces et évolutifs ?
- Formation Continue pour LLM : Où est la frontière entre la pré-formation et la mise au point ? Quelles architectures et stratégies d’apprentissage peuvent permettre au LLM de continuer à évoluer après la pré-formation ? Comment les connaissances existantes dans le modèle interagissent-elles avec les connaissances nouvellement acquises ?
- Application de données synthétiques à grande échelle : Aujourd'hui, alors que les modèles génératifs génèrent rapidement des données, quel impact ces données ont-elles sur le développement de nos modèles et même sur l'ensemble d'Internet et de la société ? Comment pouvons-nous garantir que nous pouvons générer des données diversifiées et de haute qualité à grande échelle ? Pouvons-nous distinguer ces données des données générées par l’homme ?
Yuling Gu

Yuling Gu est chercheur au sein de l'équipe Aristo de l'Allen Institute for Artificial Intelligence (AI2).
En 2020, elle a obtenu son baccalauréat de l'Université de New York (NYU). En plus de sa spécialisation en informatique, elle a également suivi une spécialisation interdisciplinaire, Language and Mind, qui combine linguistique, psychologie et philosophie. Elle a ensuite obtenu une maîtrise de l'Université de Washington (UW).
Elle est pleine d'enthousiasme pour l'intégration et l'application de la technologie d'apprentissage automatique et de la théorie des sciences cognitives.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
