
 Périphériques technologiques
IA
Le premier framework universel dans le domaine des graphes est là ! Sélectionné dans ICLR\'24 Spotlight, tout problème d'ensemble de données et de classification peut être résolu
Périphériques technologiques
IA
Le premier framework universel dans le domaine des graphes est là ! Sélectionné dans ICLR\'24 Spotlight, tout problème d'ensemble de données et de classification peut être résolu
Le premier framework universel dans le domaine des graphes est là ! Sélectionné dans ICLR\'24 Spotlight, tout problème d'ensemble de données et de classification peut être résolu

Peut-il exister un modèle graphique universel——
qui puisse prédire la toxicité en fonction de la structure moléculaire et recommander des amis sur les réseaux sociaux ?
Ou pouvez-vous non seulement prédire les citations des articles de différents auteurs, mais également découvrir le mécanisme du vieillissement humain dans le réseau génétique ?
Ne me dites pas, le cadre « One for All(OFA) » accepté comme Spotlight par ICLR 2024 a réalisé cette « essence ».
Cette recherche a été proposée conjointement par des chercheurs tels que l’équipe du professeur Chen Yixin de l’Université de Washington à Saint-Louis, Zhang Muhan de l’Université de Pékin et Tao Dacheng du JD Research Institute.
En tant que premier cadre général dans le domaine graphique, OFA permet de former un seul modèle GNN pour résoudre les tâches de classification de n'importe quel ensemble de données, n'importe quel type de tâche et n'importe quelle scène dans le champ graphique.

Comment le mettre en œuvre spécifiquement, ce qui suit est la contribution de l'auteur.
La conception de modèles universels dans le domaine des graphes se heurte à trois difficultés majeures
Concevoir un modèle de base universel pour résoudre une variété de tâches est un objectif à long terme dans le domaine de l'intelligence artificielle. Ces dernières années, les grands modèles de langage de base (LLM) ont bien fonctionné dans le traitement des tâches en langage naturel.
Cependant, dans le domaine des graphiques, bien que les réseaux de neurones graphiques (GNN) aient de bonnes performances dans différentes données graphiques, comment concevoir et former un modèle graphique de base capable de gérer plusieurs tâches graphiques en même temps reste un moyen en avant vaste.
Par rapport au domaine du langage naturel, la conception de modèles généraux dans le domaine des graphes se heurte à de nombreuses difficultés uniques.
Tout d'abord, à la différence du langage naturel, différentes données graphiques ont des attributs et des distributions complètement différents.
Par exemple, un diagramme moléculaire décrit comment plusieurs atomes forment différentes substances chimiques à travers différentes relations de force. Le diagramme des relations de citation décrit le réseau de citations mutuelles entre les articles.
Ces différentes données graphiques sont difficiles à unifier dans un cadre de formation.
Deuxièmement, contrairement à toutes les tâches des LLM, qui peuvent être converties en tâches de génération de contexte unifiée, les tâches de graphe incluent une variété de sous-tâches, telles que les tâches de nœuds, les tâches de liens, les tâches de graphe complet, etc.
Différentes sous-tâches nécessitent généralement différentes représentations de tâches et différents modèles graphiques.
Enfin, le succès des grands modèles de langage est indissociable de l'apprentissage contextuel (apprentissage en contexte) réalisé grâce à des paradigmes rapides.
Dans les grands modèles de langage, le paradigme d'invite est généralement une description textuelle lisible de la tâche en aval.
Mais pour les données graphiques non structurées et difficiles à décrire avec des mots, comment concevoir un paradigme d'invite graphique efficace pour réaliser un apprentissage en contexte reste un mystère non résolu.
Utilisez le concept de « diagramme de texte » pour le résoudre
La figure suivante montre le cadre global d'OFA :
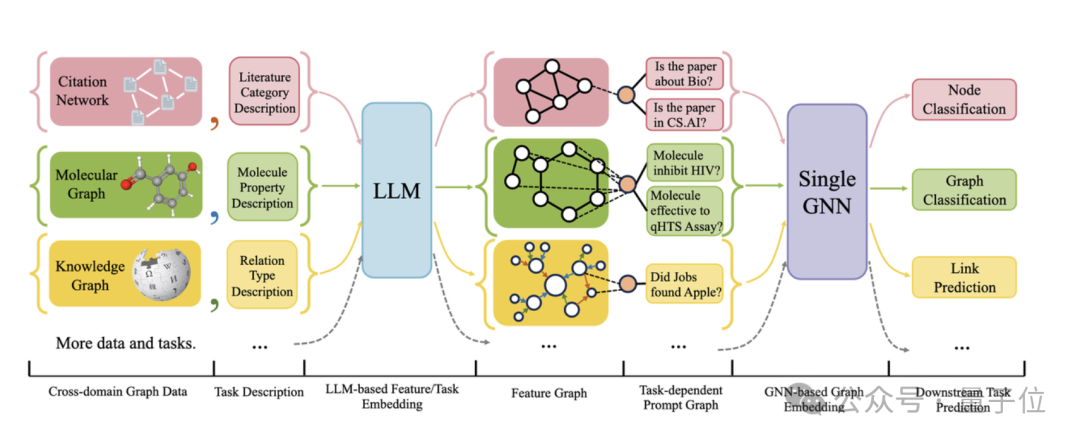
Plus précisément, l'équipe d'OFA résout les trois principaux problèmes mentionnés ci-dessus grâce à une conception intelligente .
Pour le problème des différents attributs et distributions de données graphiques, OFA unifie toutes les données graphiques en proposant le concept de Text-Attributed Graph (TAGs) . À l'aide de graphiques textuels, OFA décrit les informations de nœud et les informations de bord dans toutes les données graphiques à l'aide d'un cadre de langage naturel unifié, comme le montre la figure suivante :


(NOI) sous-graphique et nœud d'invite NOI (NOI Prompt Node) pour unifier différents types de sous-tâches dans le champ graphique. Ici, NOI représente un ensemble de nœuds cibles participant à la tâche correspondante.
Par exemple, dans la tâche de prédiction de nœuds, le NOI fait référence à un seul nœud qui doit être prédit tandis que dans la tâche de lien, le NOI comprend deux nœuds qui doivent prédire le lien ; Le sous-graphe NOI fait référence à un sous-graphe contenant des quartiers de sauts h étendus autour de ces nœuds NOI.
Ensuite, le nœud d'invite NOI est un type de nœud nouvellement introduit, directement connecté à tous les NOI.
L'important est que chaque nœud d'invite NOI contient des informations de description de la tâche en cours. Ces informations existent sous forme de langage naturel et sont représentées par le même LLM que le graphique de texte.
Étant donné que les informations contenues dans les nœuds du NOI seront collectées par le nœud d'invite NOI après avoir transmis le message des GNN, le modèle GNN n'a besoin que de faire des prédictions via le nœud d'invite NOI.
De cette façon, tous les différents types de tâches auront une représentation unifiée des tâches. L'exemple spécifique est présenté dans la figure ci-dessous :
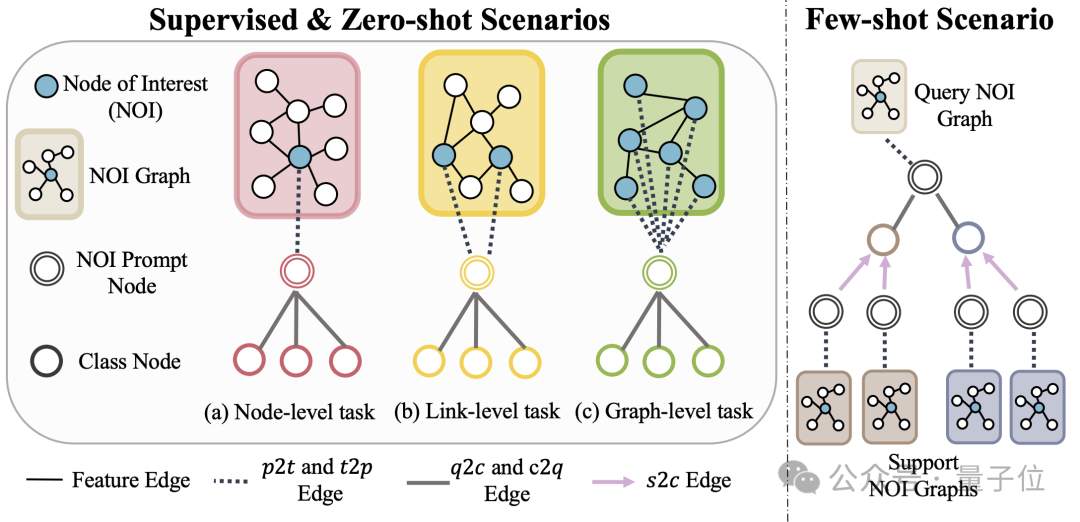
Enfin, afin de réaliser un apprentissage en contexte dans le champ du graphique, OFA introduit un sous-graphe d'invite unifié.
Dans un scénario de tâche de classification supervisée k-way, ce sous-graphe d'invite contient deux types de nœuds : l'un est le nœud d'invite NOI mentionné ci-dessus, et l'autre est constitué de nœuds de catégorie représentant k catégories différentes (nœud de classe).
Le texte de chaque nœud de catégorie décrira les informations pertinentes de cette catégorie.
Les nœuds d'invite NOI seront connectés à tous les nœuds de catégorie dans une direction. Le graphe construit de cette manière sera introduit dans le modèle de réseau neuronal graphique pour la transmission et l'apprentissage des messages.
Enfin, OFA effectuera une tâche de classification binaire sur chaque nœud de catégorie et prendra le nœud de catégorie avec la probabilité la plus élevée comme résultat de prédiction final.
Étant donné que les informations de catégorie existent dans le sous-graphe de repère, même si un problème de classification complètement nouveau est rencontré, OFA peut prédire directement sans aucun réglage fin en construisant le sous-graphe de repère correspondant, réalisant ainsi un apprentissage sans tir.
Pour les scénarios d'apprentissage en quelques étapes, une tâche de classification comprendra un graphique d'entrée de requête et plusieurs graphiques d'entrée de support. Le paradigme de graphique d'invite d'OFA connectera le nœud d'invite NOI de chaque graphique d'entrée de support à son nœud de catégorie correspondant, et en même temps. Le nœud d'invite NOI du graphique d'entrée de requête est connecté à tous les nœuds de catégorie.
Les étapes de prédiction suivantes sont cohérentes avec ce qui précède. De cette manière, chaque nœud de catégorie recevra des informations supplémentaires du graphique d'entrée de support, réalisant ainsi un apprentissage en quelques étapes sous un paradigme unifié.
Les principales contributions de l'OFA sont résumées comme suit :
Distribution unifiée des données graphiques : en proposant des graphiques textuels et en utilisant LLM pour transformer les informations textuelles, OFA réalise l'alignement de la distribution et l'unification des données graphiques.
Formulaire de tâche graphique uniforme : grâce aux sous-graphiques NOI et aux nœuds d'invite NOI, OFA obtient une représentation unifiée des sous-tâches dans divers champs graphiques.
Paradigme d'incitation graphique unifié : en proposant un nouveau paradigme d'incitation graphique, OFA réalise un apprentissage multi-scénarios en contexte dans le domaine des graphiques.
Super capacité de généralisation
L'article a testé le cadre OFA sur 9 ensembles de données collectées. Ces tests ont couvert dix tâches différentes dans des scénarios d'apprentissage supervisé, y compris la prédiction de nœuds, la prédiction de liens et la classification de figures.
Le but de l'expérience est de vérifier la capacité d'un seul modèle OFA à gérer plusieurs tâches, dans laquelle l'auteur compare l'utilisation de différents LLM (OFA-{LLM}) et la formation de modèles distincts pour chaque tâche (OFA-ind-{LLM}) Effet.
Les résultats de la comparaison sont présentés dans le tableau suivant :
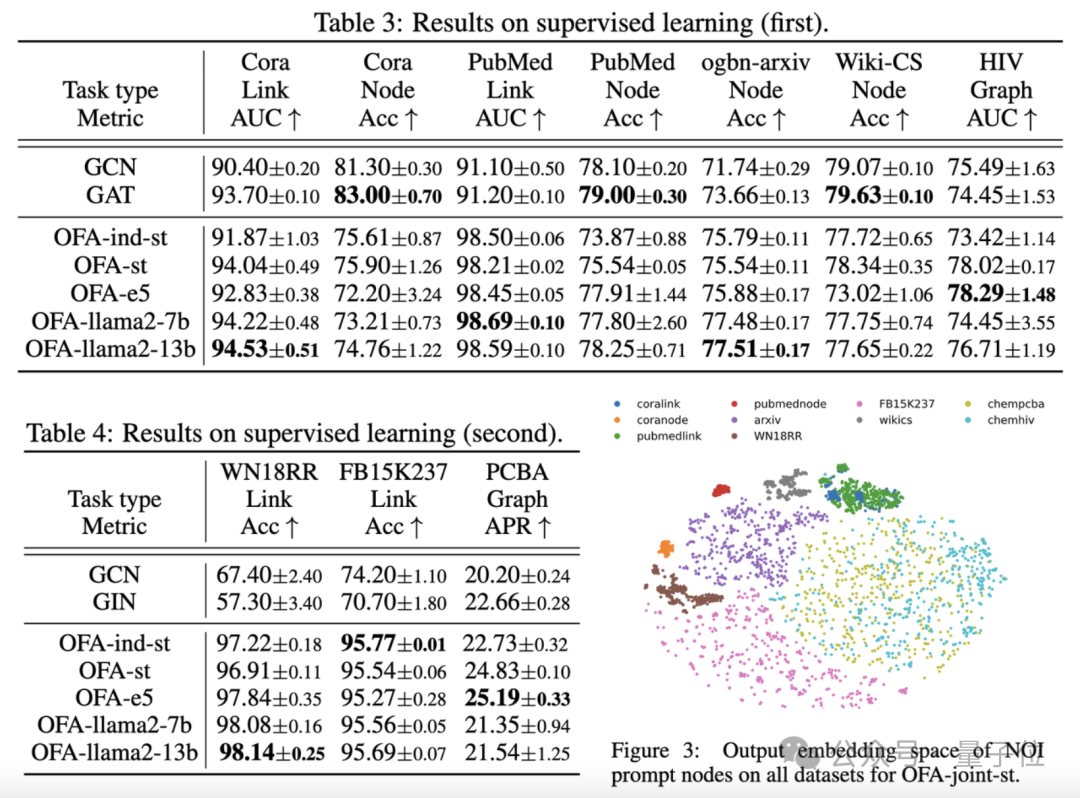
On peut voir que, sur la base de la puissante capacité de généralisation d'OFA, un modèle de graphique distinct (OFA-st, OFA-e5, OFA-llama2-7b, OFA -llama2 -13b)C'est-à-dire qu'il peut avoir des performances similaires ou meilleures que le modèle de formation séparé traditionnel(GCN, GAT, OFA-ind-st) sur toutes les tâches.
Dans le même temps, l'utilisation d'un LLM plus puissant peut apporter certaines améliorations de performances. L'article trace en outre la représentation des nœuds d'invite NOI pour différentes tâches par le modèle OFA formé.
Vous pouvez voir que différentes tâches sont intégrées dans différents sous-espaces par le modèle, de sorte qu'OFA puisse apprendre différentes tâches séparément sans s'affecter les unes les autres.
Dans le scénario de quelques échantillons et de zéro échantillon, OFA utilise un modèle unique sur ogbn-arxiv(graphe de référence), FB15K237(graphe de connaissances) et Chemble(graphe moléculaire) pour la pré-formation et les tests. performances sur différentes tâches et ensembles de données en aval. Les résultats sont les suivants :
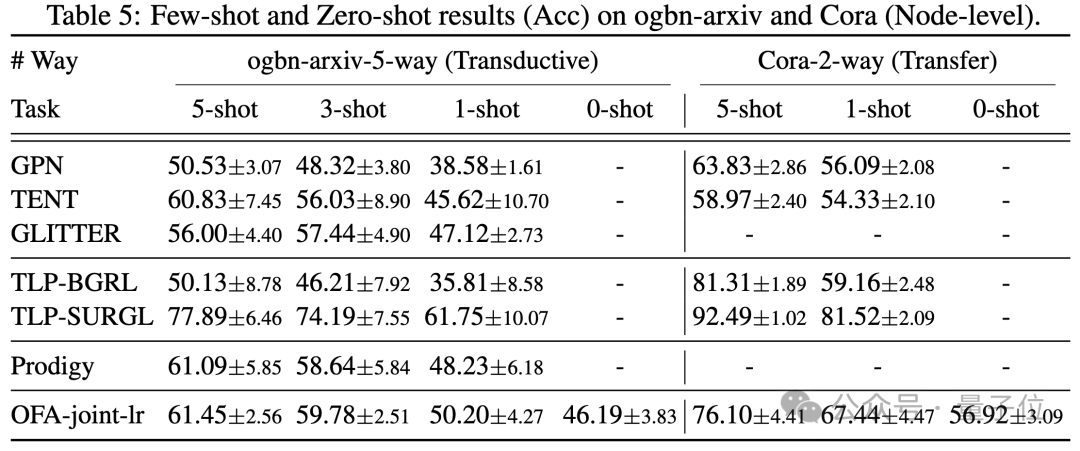
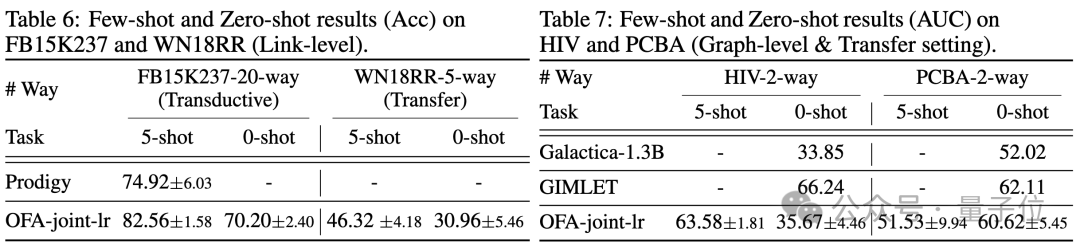
On peut voir que même dans le scénario sans échantillon, OFA peut toujours obtenir de bons résultats. Pris ensemble, les résultats expérimentaux vérifient bien les puissantes performances générales de l’OFA et son potentiel en tant que modèle de base dans le domaine des graphes.
Pour plus de détails sur la recherche, veuillez vous référer à l'article original.
Adresse : https://www.php.cn/link/dd4729902a3476b2bc9675e3530a852chttps://github.com/LechengKong/OneForAll
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
 Pour seulement 250$, le directeur technique de Hugging Face vous apprend étape par étape comment peaufiner Llama 3
May 06, 2024 pm 03:52 PM
Pour seulement 250$, le directeur technique de Hugging Face vous apprend étape par étape comment peaufiner Llama 3
May 06, 2024 pm 03:52 PM
Les grands modèles de langage open source familiers tels que Llama3 lancé par Meta, les modèles Mistral et Mixtral lancés par MistralAI et Jamba lancé par AI21 Lab sont devenus des concurrents d'OpenAI. Dans la plupart des cas, les utilisateurs doivent affiner ces modèles open source en fonction de leurs propres données pour libérer pleinement le potentiel du modèle. Il n'est pas difficile d'affiner un grand modèle de langage (comme Mistral) par rapport à un petit en utilisant Q-Learning sur un seul GPU, mais le réglage efficace d'un grand modèle comme Llama370b ou Mixtral est resté un défi jusqu'à présent. . C'est pourquoi Philipp Sch, directeur technique de HuggingFace
 Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Afin d'aligner les grands modèles de langage (LLM) sur les valeurs et les intentions humaines, il est essentiel d'apprendre les commentaires humains pour garantir qu'ils sont utiles, honnêtes et inoffensifs. En termes d'alignement du LLM, une méthode efficace est l'apprentissage par renforcement basé sur le retour humain (RLHF). Bien que les résultats de la méthode RLHF soient excellents, certains défis d’optimisation sont impliqués. Cela implique de former un modèle de récompense, puis d'optimiser un modèle politique pour maximiser cette récompense. Récemment, certains chercheurs ont exploré des algorithmes hors ligne plus simples, dont l’optimisation directe des préférences (DPO). DPO apprend le modèle politique directement sur la base des données de préférence en paramétrant la fonction de récompense dans RLHF, éliminant ainsi le besoin d'un modèle de récompense explicite. Cette méthode est simple et stable
 Les startups d'IA ont collectivement transféré leurs emplois vers OpenAI, et l'équipe de sécurité s'est regroupée après le départ d'Ilya !
Jun 08, 2024 pm 01:00 PM
Les startups d'IA ont collectivement transféré leurs emplois vers OpenAI, et l'équipe de sécurité s'est regroupée après le départ d'Ilya !
Jun 08, 2024 pm 01:00 PM
" sept péchés capitaux" » Dissiper les rumeurs : selon des informations divulguées et des documents obtenus par Vox, la haute direction d'OpenAI, y compris Altman, était bien au courant de ces dispositions de récupération de capitaux propres et les a approuvées. De plus, OpenAI est confronté à un problème grave et urgent : la sécurité de l’IA. Les récents départs de cinq employés liés à la sécurité, dont deux de ses employés les plus en vue, et la dissolution de l'équipe « Super Alignment » ont une nouvelle fois mis les enjeux de sécurité d'OpenAI sur le devant de la scène. Le magazine Fortune a rapporté qu'OpenA
