

Explication détaillée du processus de compilation du programme Linux

Les langages de programmation informatique sont généralement divisés en trois catégories : le langage machine, le langage assembleur et le langage de haut niveau. Les langages de haut niveau doivent être traduits en langage machine avant de pouvoir être exécutés. Il existe deux méthodes de traduction, l'une est compilée et l'autre est interprétée.
Nous divisons donc essentiellement les langages de haut niveau en deux catégories, l'une est un langage compilé, tel que C, C++, Java, et l'autre est un langage interprété, tel que Python, Ruby, MATLAB et JavaScript.
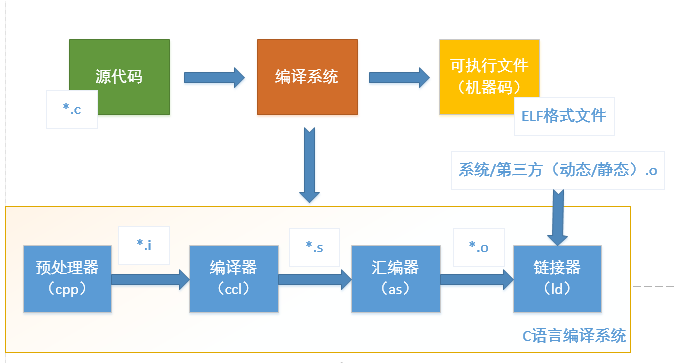
Cet article présentera le processus de conversion de programmes de haut niveau écrits en langage C/C++ en codes binaires pouvant être exécutés par le processeur, comprenant quatre étapes :
- Prétraitement
- Compilation
- Assemblée
- Lien
Présentation de la chaîne d'outils GCC
Le communément appelé GCC est l'abréviation de GUN Compiler Collection, qui est un outil de compilation couramment utilisé sur les systèmes Linux. Le logiciel de chaîne d'outils GCC comprend GCC, Binutils, la bibliothèque d'exécution C, etc.
CCG
GCC (GNU C Compiler) est un outil de compilation. Cet article présentera le processus de conversion d'un programme écrit en langage C/C++ en un code binaire exécutable par le processeur, qui est complété par le compilateur.
Binutils
Un ensemble d'outils de traitement de programmes binaires, notamment : addr2line, ar, objcopy, objdump, as, ld, ldd, readelf, size, etc. Cet ensemble d'outils est un outil indispensable au développement et au débogage. Leurs introductions respectives sont les suivantes :
.- addr2line : utilisé pour convertir l'adresse du programme en son fichier source de programme correspondant et la ligne de code correspondante, et également obtenir la fonction correspondante. Cet outil aidera le débogueur à localiser l'emplacement du code source correspondant pendant le débogage.
- comme : Principalement utilisé pour l'assemblage, veuillez vous référer à l'article suivant pour une introduction détaillée à l'assemblage.
- ld : principalement utilisé pour les liens. Pour plus de détails sur les liens, veuillez consulter l'article suivant.
- ar : Principalement utilisé pour créer des bibliothèques statiques. Afin de faciliter la compréhension des débutants, les notions de bibliothèques dynamiques et de bibliothèques statiques sont introduites ici :
- Si vous souhaitez générer plusieurs fichiers objets .o dans un fichier de bibliothèque, il existe deux types de bibliothèques, l'une est une bibliothèque statique et l'autre est une bibliothèque dynamique.
- Sous Windows, les bibliothèques statiques sont des fichiers portant le suffixe .lib et les bibliothèques partagées sont des fichiers portant le suffixe .dll. Sous Linux, les bibliothèques statiques sont des fichiers avec le suffixe .a et les bibliothèques partagées sont des fichiers avec le suffixe .so.
- La différence entre les bibliothèques statiques et les bibliothèques dynamiques réside dans le moment où le code est chargé. Le code de la bibliothèque statique a été chargé dans le programme exécutable pendant le processus de compilation, sa taille est donc plus grande. Le code de la bibliothèque partagée est chargé en mémoire lors de l'exécution du programme exécutable et n'est simplement référencé que lors du processus de compilation, la taille du code est donc plus petite. Sur les systèmes Linux, vous pouvez utiliser la commande ldd pour afficher les bibliothèques partagées dont dépend un programme exécutable.
- S'il existe plusieurs programmes dans un système qui doivent s'exécuter en même temps et qu'il existe des bibliothèques partagées entre ces programmes, l'utilisation d'une bibliothèque dynamique permettra d'économiser plus de mémoire.
- ldd : peut être utilisé pour afficher les bibliothèques partagées dont dépend un programme exécutable.
- objcopy : Traduisez un fichier objet dans un autre format, par exemple en convertissant .bin en .elf ou en convertissant .elf en .bin, etc.
- objdump : Sa fonction principale est le démontage. Pour une introduction détaillée au démontage, consultez l'article suivant.
- readelf : affiche des informations sur les fichiers ELF, voir plus tard pour plus d'informations.
- size : répertoriez la taille et la taille totale de chaque partie du fichier exécutable, du segment de code, du segment de données, de la taille totale, etc. Veuillez consulter l'article suivant pour des exemples d'utilisation spécifiques de l'utilisation de la taille.
Bibliothèque d'exécution C
Le standard du langage C se compose principalement de deux parties : une partie décrit la syntaxe du C et l'autre partie décrit la bibliothèque standard C. La bibliothèque standard C définit un ensemble de fichiers d'en-tête standard. Chaque fichier d'en-tête contient des fonctions, variables, déclarations de type et définitions de macro associées. Par exemple, la fonction printf commune est une fonction de bibliothèque standard C et son prototype est défini dans le fichier stdio. En tête de fichier.
C语言标准仅仅定义了C标准库函数原型,并没有提供实现。因此,C语言编译器通常需要一个C运行时库(C Run Time Libray,CRT)的支持。C运行时库又常简称为C运行库。与C语言类似,C++也定义了自己的标准,同时提供相关支持库,称为C++运行时库。
准备工作
由于GCC工具链主要是在Linux环境中进行使用,因此本文也将以Linux系统作为工作环境。为了能够演示编译的整个过程,本节先准备一个C语言编写的简单Hello程序作为示例,其源代码如下所示:
#include
//此程序很简单,仅仅打印一个Hello World的字符串。
int main(void)
{
printf("Hello World! \n");
return 0;
}
“
编译过程
1.预处理
预处理的过程主要包括以下过程:
- 将所有的#define删除,并且展开所有的宏定义,并且处理所有的条件预编译指令,比如#if #ifdef #elif #else #endif等。
- 处理#include预编译指令,将被包含的文件插入到该预编译指令的位置。
- 删除所有注释“//”和“/* */”。
- 添加行号和文件标识,以便编译时产生调试用的行号及编译错误警告行号。
- 保留所有的#pragma编译器指令,后续编译过程需要使用它们。
使用gcc进行预处理的命令如下:
$ gcc -E hello.c -o hello.i // 将源文件hello.c文件预处理生成hello.i // GCC的选项-E使GCC在进行完预处理后即停止
hello.i文件可以作为普通文本文件打开进行查看,其代码片段如下所示:
// hello.i代码片段
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__));
# 942 "/usr/include/stdio.h" 3 4
# 2 "hello.c" 2
# 3 "hello.c"
int
main(void)
{
printf("Hello World!" "\n");
return 0;
}
2.编译
编译过程就是对预处理完的文件进行一系列的词法分析,语法分析,语义分析及优化后生成相应的汇编代码。
使用gcc进行编译的命令如下:
$ gcc -S hello.i -o hello.s // 将预处理生成的hello.i文件编译生成汇编程序hello.s // GCC的选项-S使GCC在执行完编译后停止,生成汇编程序
上述命令生成的汇编程序hello.s的代码片段如下所示,其全部为汇编代码。
// hello.s代码片段 main: .LFB0: .cfi_startproc pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset 6, -16 movq %rsp, %rbp .cfi_def_cfa_register 6 movl $.LC0, %edi call puts movl $0, %eax popq %rbp .cfi_def_cfa 7, 8 ret .cfi_endproc
3.汇编
汇编过程调用对汇编代码进行处理,生成处理器能识别的指令,保存在后缀为.o的目标文件中。由于每一个汇编语句几乎都对应一条处理器指令,因此,汇编相对于编译过程比较简单,通过调用Binutils中的汇编器as根据汇编指令和处理器指令的对照表一一翻译即可。
当程序由多个源代码文件构成时,每个文件都要先完成汇编工作,生成.o目标文件后,才能进入下一步的链接工作。注意:目标文件已经是最终程序的某一部分了,但是在链接之前还不能执行。
使用gcc进行汇编的命令如下:
$ gcc -c hello.s -o hello.o // 将编译生成的hello.s文件汇编生成目标文件hello.o // GCC的选项-c使GCC在执行完汇编后停止,生成目标文件 //或者直接调用as进行汇编 $ as -c hello.s -o hello.o //使用Binutils中的as将hello.s文件汇编生成目标文件
注意:hello.o目标文件为ELF(Executable and Linkable Format)格式的可重定向文件。
4.链接
链接也分为静态链接和动态链接,其要点如下:
- 静态链接是指在编译阶段直接把静态库加入到可执行文件中去,这样可执行文件会比较大。链接器将函数的代码从其所在地(不同的目标文件或静态链接库中)拷贝到最终的可执行程序中。为创建可执行文件,链接器必须要完成的主要任务是:符号解析(把目标文件中符号的定义和引用联系起来)和重定位(把符号定义和内存地址对应起来然后修改所有对符号的引用)。
- 动态链接则是指链接阶段仅仅只加入一些描述信息,而程序执行时再从系统中把相应动态库加载到内存中去。
- 在Linux系统中,gcc编译链接时的动态库搜索路径的顺序通常为:首先从gcc命令的参数-L指定的路径寻找;再从环境变量LIBRARY_PATH指定的路径寻址;再从默认路径/lib、/usr/lib、/usr/local/lib寻找。
- 在Linux系统中,执行二进制文件时的动态库搜索路径的顺序通常为:首先搜索编译目标代码时指定的动态库搜索路径;再从环境变量LD_LIBRARY_PATH指定的路径寻址;再从配置文件/etc/ld.so.conf中指定的动态库搜索路径;再从默认路径/lib、/usr/lib寻找。
- 在Linux系统中,可以用ldd命令查看一个可执行程序依赖的共享库。
由于链接动态库和静态库的路径可能有重合,所以如果在路径中有同名的静态库文件和动态库文件,比如libtest.a和libtest.so,gcc链接时默认优先选择动态库,会链接libtest.so,如果要让gcc选择链接libtest.a则可以指定gcc选项-static,该选项会强制使用静态库进行链接。以Hello World为例:
- 如果使用命令“gcc hello.c -o hello”则会使用动态库进行链接,生成的ELF可执行文件的大小(使用Binutils的size命令查看)和链接的动态库(使用Binutils的ldd命令查看)如下所示:
$ gcc hello.c -o hello $ size hello //使用size查看大小 text data bss dec hex filename 1183 552 8 1743 6cf hello $ ldd hello //可以看出该可执行文件链接了很多其他动态库,主要是Linux的glibc动态库 linux-vdso.so.1 => (0x00007fffefd7c000) libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007fadcdd82000) /lib64/ld-linux-x86-64.so.2 (0x00007fadce14c000)
如果使用命令“gcc -static hello.c -o hello”则会使用静态库进行链接,生成的ELF可执行文件的大小(使用Binutils的size命令查看)和链接的动态库(使用Binutils的ldd命令查看)如下所示:
$ gcc -static hello.c -o hello $ size hello //使用size查看大小 text data bss dec hex filename 823726 7284 6360 837370 cc6fa hello //可以看出text的代码尺寸变得极大 $ ldd hello not a dynamic executable //说明没有链接动态库
链接器链接后生成的最终文件为ELF格式可执行文件,一个ELF可执行文件通常被链接为不同的段,常见的段譬如.text、.data、.rodata、.bss等段。
分析ELF文件
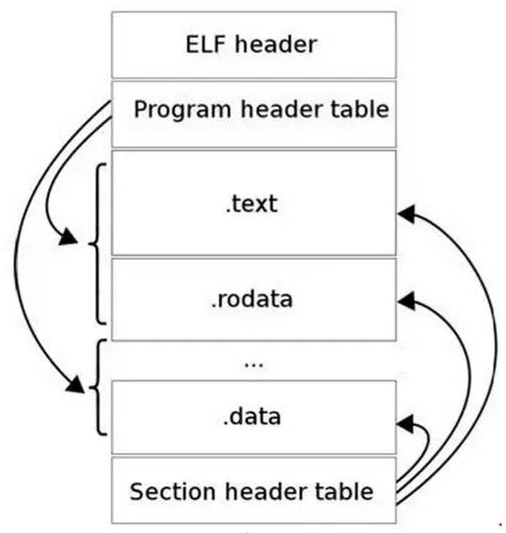
1.ELF文件的段
ELF文件格式如下图所示,位于ELF Header和Section Header Table之间的都是段(Section)。一个典型的ELF文件包含下面几个段:
- .text:已编译程序的指令代码段。
- .rodata:ro代表read only,即只读数据(譬如常数const)。
- .data:已初始化的C程序全局变量和静态局部变量。
- .bss:未初始化的C程序全局变量和静态局部变量。
- .debug:调试符号表,调试器用此段的信息帮助调试。
可以使用readelf -S查看其各个section的信息如下
$ readelf -S hello There are 31 section headers, starting at offset 0x19d8: Section Headers: [Nr] Name Type Address Offset Size EntSize Flags Link Info Align [ 0] NULL 0000000000000000 00000000 0000000000000000 0000000000000000 0 0 0 …… [11] .init PROGBITS 00000000004003c8 000003c8 000000000000001a 0000000000000000 AX 0 0 4 …… [14] .text PROGBITS 0000000000400430 00000430 0000000000000182 0000000000000000 AX 0 0 16 [15] .fini PROGBITS 00000000004005b4 000005b4 ……
2.反汇编ELF
由于ELF文件无法被当做普通文本文件打开,如果希望直接查看一个ELF文件包含的指令和数据,需要使用反汇编的方法。
使用objdump -D对其进行反汇编如下:
$ objdump -D hello …… 0000000000400526 : // main标签的PC地址 //PC地址:指令编码 指令的汇编格式 400526: 55 push %rbp 400527: 48 89 e5 mov %rsp,%rbp 40052a: bf c4 05 40 00 mov $0x4005c4,%edi 40052f: e8 cc fe ff ff callq 400400 400534: b8 00 00 00 00 mov $0x0,%eax 400539: 5d pop %rbp 40053a: c3 retq 40053b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
使用objdump -S将其反汇编并且将其C语言源代码混合显示出来:
$ gcc -o hello -g hello.c //要加上-g选项
$ objdump -S hello
……
0000000000400526 :
#include
int
main(void)
{
400526: 55 push %rbp
400527: 48 89 e5 mov %rsp,%rbp
printf("Hello World!" "\n");
40052a: bf c4 05 40 00 mov $0x4005c4,%edi
40052f: e8 cc fe ff ff callq 400400
return 0;
400534: b8 00 00 00 00 mov $0x0,%eax
}
400539: 5d pop %rbp
40053a: c3 retq
40053b: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
……
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Comment résoudre le problème des autorisations rencontré lors de la visualisation de la version Python dans le terminal Linux?
Apr 01, 2025 pm 05:09 PM
Solution aux problèmes d'autorisation Lors de la visualisation de la version Python dans Linux Terminal Lorsque vous essayez d'afficher la version Python dans Linux Terminal, entrez Python ...
 Comment définir automatiquement les autorisations d'UnixSocket après le redémarrage du système?
Mar 31, 2025 pm 11:54 PM
Comment définir automatiquement les autorisations d'UnixSocket après le redémarrage du système?
Mar 31, 2025 pm 11:54 PM
Comment définir automatiquement les autorisations d'UnixSocket après le redémarrage du système. Chaque fois que le système redémarre, nous devons exécuter la commande suivante pour modifier les autorisations d'UnixSocket: sudo ...
 Pourquoi une erreur se produit-elle lors de l'installation d'une extension à l'aide de PECL dans un environnement Docker? Comment le résoudre?
Apr 01, 2025 pm 03:06 PM
Pourquoi une erreur se produit-elle lors de l'installation d'une extension à l'aide de PECL dans un environnement Docker? Comment le résoudre?
Apr 01, 2025 pm 03:06 PM
Causes et solutions pour les erreurs Lors de l'utilisation de PECL pour installer des extensions dans un environnement Docker Lorsque nous utilisons un environnement Docker, nous rencontrons souvent des maux de tête ...
 Comment intégrer efficacement les services Node.js ou Python sous l'architecture LAMP?
Apr 01, 2025 pm 02:48 PM
Comment intégrer efficacement les services Node.js ou Python sous l'architecture LAMP?
Apr 01, 2025 pm 02:48 PM
De nombreux développeurs de sites Web sont confrontés au problème de l'intégration de Node.js ou des services Python sous l'architecture de lampe: la lampe existante (Linux Apache MySQL PHP) a besoin d'un site Web ...
 Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Utilisation de Python dans Linux Terminal ...
 Que dois-je faire si Beyond Compare échoue à la sensibilité à la synchronisation des Windows et des fichiers Linux?
Apr 01, 2025 am 08:06 AM
Que dois-je faire si Beyond Compare échoue à la sensibilité à la synchronisation des Windows et des fichiers Linux?
Apr 01, 2025 am 08:06 AM
Le problème de la comparaison et de la synchronisation des fichiers au-delà de la compare: défaillance de la sensibilité à la casse lors de l'utilisation de Beyond ...
 Comment configurer la tâche de synchronisation APScheduler en tant que service sur macOS?
Apr 01, 2025 pm 06:09 PM
Comment configurer la tâche de synchronisation APScheduler en tant que service sur macOS?
Apr 01, 2025 pm 06:09 PM
Configurez la tâche de synchronisation APScheduler en tant que service sur la plate-forme MacOS, si vous souhaitez configurer la tâche de synchronisation APScheduler en tant que service, similaire à Ngin ...
 L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
En ce qui concerne le problème de la suppression de l'interpréteur Python qui est livré avec des systèmes Linux, de nombreuses distributions Linux préinstalleront l'interpréteur Python lors de l'installation, et il n'utilise pas le gestionnaire de packages ...
