

Note d'application sur les tuyaux Linux et FIFO

Aperçu
L'endroit le plus courant pour les tuyaux est dans la coque, comme :
$ ls | wc -l
Afin d'exécuter la commande ci-dessus, le shell crée deux processus à exécuter respectivement ls 和 wc (通过 fork() 和 exec() Complete), comme suit :
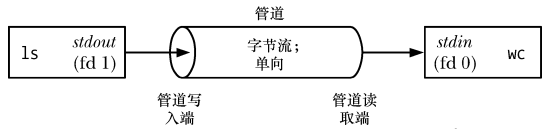
Comme vous pouvez le voir sur l'image ci-dessus, un pipeline peut être considéré comme un ensemble de conduites d'eau qui permettent aux données de circuler d'un processus à un autre, d'où le nom tuyau.
Comme vous pouvez le voir sur l'image ci-dessus, deux processus sont connectés au tube, de sorte que le processus d'écriture ls 就将其标准输出(文件描述符为1)连接到来管道的写入段,读取进程 wc connecte son entrée standard (descripteur de fichier 0) à l'extrémité lecture du tube. En fait, ces deux processus ne connaissent pas l’existence du tube, ils se contentent de lire et d’écrire les données du descripteur de fichier standard. C'est la coque qui doit faire le travail.
Un tube est un flux d'octets
Un tube est un flux d'octets, c'est-à-dire qu'il n'y a aucune notion de messages ou de limites de messages lors de l'utilisation d'un tube :
- Un processus lisant des données à partir d'un tube peut lire des blocs de données de n'importe quelle taille, quelle que soit la taille des blocs de données écrits dans le tube par le processus d'écriture
-
Les données transmises via le tube sont séquentielles. L'ordre des octets lus dans le tube est exactement le même que l'ordre dans lequel ils ont été écrits dans le tube. Vous ne pouvez pas utiliser
lseek()pour accéder de manière aléatoire aux données dans le tube .
Si vous devez implémenter le concept de messages discrets dans un pipeline, vous devez alors effectuer ce travail dans l'application. Bien que cela soit possible, si vous rencontrez ce besoin, il est préférable d'utiliser d'autres mécanismes IPC, tels que les files d'attente de messages et les sockets de datagramme.
Lire les données du tuyau
Tenter de lire à partir d'un tube actuellement vide bloquera jusqu'à ce qu'au moins un octet ait été écrit dans le tube.
Si l'extrémité d'écriture du tube est fermée, le processus lisant les données du tube verra la fin du fichier (c'est-à-dire read() renvoie 0) après avoir lu toutes les données restantes dans le tube.
Le tuyau est à sens unique
Le sens de transmission des données dans le pipeline est à sens unique. Une extrémité du tuyau est utilisée pour l’écriture et l’autre extrémité est utilisée pour la lecture.
Sur certaines autres implémentations UNIX, en particulier celles évoluées à partir de System V Release 4, les canaux sont bidirectionnels (appelés canaux de flux). Les canaux bidirectionnels ne sont spécifiés dans aucune norme UNIX, il est donc préférable d'éviter de s'appuyer sur cette sémantique, même sur les implémentations qui fournissent des canaux bidirectionnels. Comme alternative, une paire de sockets de flux de domaine UNIX (créée via l'appel système socketpair()) peut être utilisée, qui fournit un mécanisme de communication bidirectionnel standard et dont la sémantique est équivalente aux canaux de flux.
Garantit que l'écriture de pas plus de PIPE_BUF octets est atomique
Si plusieurs processus écrivent dans le même canal, si la quantité de données qu'ils écrivent en même temps ne dépasse pas PIPE_BUF octets, alors on peut être assuré que les données écrites ne seront pas mélangées les unes aux autres.
SUSv3 nécessite que PIPE_BUF soit au moins _POSIX_PIPE_BUF(512)。一个实现应该定义 PIPE_BUF(在 <limits.h></limits.h> 中)并/或允许调用 fpathconf(fd,_PC_PIPE_BUF) pour renvoyer une limite supérieure pratique pour les opérations d'écriture atomique. PIPE_BUF varie selon les différentes implémentations UNIX. Par exemple, sur FreeBSD 6.0, sa valeur est de 512 octets, sur Tru64 5.1, sa valeur est de 4 096 octets et sur Solaris 8, sa valeur est de 5 120 octets. Sous Linux, la valeur de PIPE_BUF est 4096.
-
Lorsque la taille du bloc de données écrit dans le canal dépasse PIPE_BUF octets, le noyau peut diviser les données en plusieurs fragments plus petits pour la transmission et ajouter les données suivantes lorsque le lecteur consomme les données du canal (
write()L'appel bloquera jusqu'à ce que toutes les données est écrit dans le tuyau) - Lorsqu'un seul processus écrit des données dans le tube (cas habituel), la valeur de PIPE_BUF n'a pas d'importance
- Mais s'il existe plusieurs processus d'écriture, l'écriture de gros blocs de données peut être divisée en segments de taille arbitraire (qui peuvent être plus petites que les octets PIPE_BUF) et peuvent chevaucher les données écrites par d'autres processus
La limite PIPE_BUF ne prend effet que lorsque les données sont transférées vers le canal. Lorsque les données écrites atteignent PIPE_BUF octets, write() 会在必要的时候阻塞知道管道中的可用空间足以原子的完成此操作。如果写入的数据大于 PIPE_BUF 字节,那么 write() 会尽可能的多传输数据以充满整个管道,然后阻塞直到一些读取进程从管道中移除了数据。如果此类阻塞的 write() bloquera si nécessaire jusqu'à ce qu'il y ait suffisamment d'espace libre dans le tube pour terminer l'opération de manière atomique. Si les données écrites sont supérieures à PIPE_BUF octets, alors
est interrompu par un gestionnaire de signal, alors l'appel sera débloqué et renverra le nombre d'octets transférés avec succès vers le tube, qui sera inférieur au nombre d'octets dont l'écriture est demandée (ce qu'on appelle Partiellement écrit) .
La capacité du pipeline est limitéeUn tube est en fait un tampon conservé dans la mémoire du noyau. La capacité de stockage de ce tampon est limitée. Une fois le canal rempli, les écritures ultérieures dans le canal sont bloquées jusqu'à ce que le lecteur supprime certaines données du canal.
🎜SUSv3 ne précise pas la capacité de stockage du pipeline. Dans les noyaux Linux antérieurs à 2.6.11, la capacité de stockage du canal est cohérente avec la taille de la page système (par exemple, 4 096 octets sur x86-32), et à partir de Linux 2.6.11, la capacité de stockage du canal est de 65 536 octet. Les capacités de stockage des canaux sur d'autres implémentations UNIX peuvent varier. 🎜一般来讲,一个应用程序无需知道管道的实际存储能力。如果需要防止写者进程阻塞,那么从管道中读取数据的进程应该被设计成以尽可能快的速度从管道中读取数据。
创建和使用管道
#include int pipe(int fd[2]);
-
pipe()创建一个新管道 -
成功的调用在数组
fd中返回两个打开的文件描述符,一个表示管道的读取端fd[0],一个表示管道的写入端fd[1]
调用 pipe() 函数时,首先在内核中开辟一块缓冲区用于通信,它有一个读端和一个写端,然后通过 fd 参数传出给用户进程两个文件描述符,fd[0] 指向管道的读端,fd[1] 指向管道的写段。
不要用 fd[0] 写数据,也不要用 fd[1] 读数据,其行为未定义的,但在有些系统上可能会返回 -1 表示调用失败。数据只能从 fd[0] 中读取,数据也只能写入到fd[1],不能倒过来。
与所有文件描述符一样,可以使用 read() 和 write() 系统调用来在管道上执行 IO,一旦向管道的写入端写入数据之后立即就能从管道的读取端读取数据。管道上的 read() 调用会读取的数据量为所请求的字节数与管道中当前存在的字节数两者之间的较小值。当管道为空时,读取操作阻塞。
Vous pouvez également utiliser les fonctions stdio sur les tuyaux (printf()、scanf() 等),只需要首先使用 fdopen() 获取一个与 filedes 中的某个描述符对应的文件流即可。但在这样做的时候需要解决 stdio Problèmes de mise en mémoire tampon.
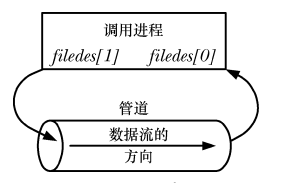
Les tuyaux peuvent être utilisés pour la communication interne au sein d'un processus :
Les tuyaux peuvent être utilisés pour la communication en cours dans les relations de parenté (les processus enfants héritent d'une copie du descripteur de fichier dans le processus parent) :
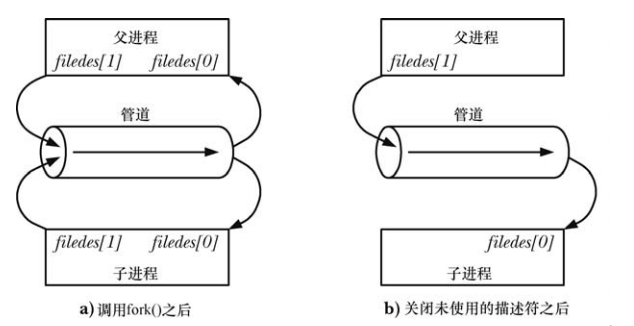
Il n'est pas recommandé d'utiliser un seul tube en full-duplex, ou de l'utiliser en semi-duplex sans fermer l'extrémité de lecture/écriture correspondante. Cela est susceptible de conduire à un blocage : si deux processus tentent de lire à partir du tube. en même temps Si les données sont récupérées, il est alors impossible de déterminer quel processus réussira à les lire en premier, ce qui entraînera deux processus en compétition pour les données. Pour éviter que cette situation de concurrence critique ne se produise, vous devez utiliser une sorte de mécanisme de synchronisation. À ce stade, vous devez considérer le problème de blocage, car un blocage peut se produire si les deux processus tentent de lire des données à partir d'un canal vide ou d'écrire des données dans un canal plein.
Si nous voulons un flux de données bidirectionnel, nous pouvons créer deux tuyaux, un dans chaque direction.
Les tuyaux permettent la communication entre les processus liés
En fait, les tubes peuvent être utilisés pour la communication entre deux ou plusieurs processus liés, à condition que le tube soit créé via un processus ancêtre commun avant la série d'appels fork() qui créent le processus enfant.
Fermer les descripteurs de fichiers de tuyaux inutilisés
Fermez les descripteurs de fichiers de canal inutilisés non seulement pour garantir qu'un processus n'épuise pas sa limite de descripteurs de fichiers.
Le processus lisant les données du tube ferme le descripteur d'écriture du tube qu'il contient, afin que le lecteur puisse voir la fin du fichier une fois que l'autre processus a terminé la sortie et fermé son descripteur d'écriture. D'un autre côté, si le processus de lecture ne ferme pas l'extrémité d'écriture du tube, alors après que d'autres processus ferment le descripteur d'écriture, le lecteur ne verra pas la fin du fichier même s'il a lu toutes les données du tube. Parce qu'à ce moment-là, le noyau sait qu'au moins un descripteur d'écriture de tube est ouvert, provoquant un blocage read().
当一个进程视图向一个管道中写入数据但没有任何进程拥有该管道的打开着的读取描述符时,内核会向写入进程发送一个 SIGPIPE 信号,默认情况下,这个信号将会杀死进程,但进程可以选择忽略或者设置信号处理器,这样 write() 将因为 EPIPE 错误而失败。收到 SIGPIPE 信号和得到 EPIPE 错误对于标识管道的状态是有意义的,这就是为什么需要关闭管道的未使用读取描述符的原因。如果写入进程没有关闭管道的读取端,那么即使在其他进程已经关闭了管道的读取端之后,写入进程仍然能够向管道写入数据,最后写入进程会将数据充满整个管道,后续的写入请求会将永远阻塞。
使用管道连接过滤器
当管道被创建之后,为管道的两端分配的文件描述符是可用描述符中数值最小的两个,由于通常情况下,进程已经使用了描述符 0,1,2,因此会为管道分配一些数值更大的描述符。如果需要使用管道连接两个过滤器(即从 stdin 读取和写入到 stdout),使得一个程序的标准输出被重定向到管道中,就需要采用复制文件描述符技术。
int pfd[2]; pipe(pfd); close(STDOUT_FILENO); dup2(pfd[1],STDOUT_FILENO);
上面这些调用的最终结果是进程的标准输出被绑定到管道的写入端,而对应的一组调用可以用来将进程的标准的输入绑定到管道的读取端上。
通过管道与 shell 命令进行通信: popen()
#include FILE *popen (const char *command, const char *mode);
-
pipe()和close()是最底层的系统调用,它的进一步封装是popen()和pclose() -
popen()函数创建了一个管道,然后创建了一个子进程来执行 shell,而 shell 又创建了一个子进程来执行command字符串 -
mode参数是一个字符串: -
-
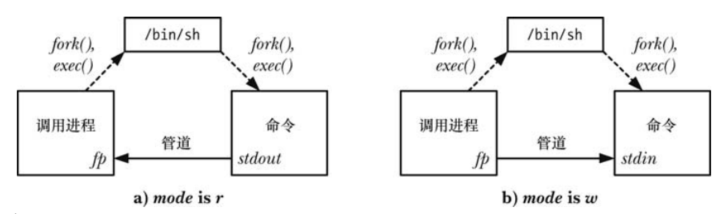
它确定调用进程是从管道中读取数据(
mode是r)还是将数据写入到管道中(mode是w) -
由于管道是向的,因此无法在执行的
command中进行双向通信 -
mode的取值确定了所执行的命令的标准输出是连接到管道的写入端还是将其标准输入连接到管道的读取端
-
它确定调用进程是从管道中读取数据(
-
popen()在成功时会返回可供stdio库函数使用的文件流指针。当发生错误时,popen()会返回NULL并设置errno以标示出发生错误的原因 -
在
popen()调用之后,调用进程使用管道来读取command的输出或使用管道向其发送输入。与使用pipe()创建的管道一样,当从管道中读取数据时,调用进程在command关闭管道的写入端之后会看到文件结束;当向管道写入数据时,如果command已经关闭了管道的读取端,那么调用进程就会收到SIGPIPE信号并得到EPIPE错误
#include int pclose ( FILE * stream);
-
一旦IO结束之后可以使用
pclose()函数关闭管道并等待子进程中的 shell 终止(不应该使用fclose()函数,因为它不会等待子进程。) -
pclose()En cas de succès, l'état de fin du shell dans le processus enfant sera renvoyé (c'est-à-dire l'état de fin de la dernière commande exécutée par le shell, à moins que le shell n'ait été tué par un signal) -
et
système (), si le shell ne peut pas être exécuté, alorssystem()一样,如果无法执行shell,那么pclose()会返回一个值就像子进程中的 shell 通过调用_exit(127)renverra une valeur tout comme le shell dans le processus enfant en appelant_exit(127)pour terminer le même -
Si une autre erreur se produit, alors
pclose()renvoie −1. L'une des erreurs qui peuvent survenir est que le statut de résiliation ne peut pas être obtenu
Lors de l'attente pour obtenir l'état du shell dans un processus enfant, SUSv3 nécessite que pclose() 与 system() 一样,即在内部的 waitpid() corresponde à system() est le même, c'est-à-dire en interne waitpid() Redémarre automatiquement un appel une fois qu'il est terminé interrompu par un gestionnaire de signal.
et system() 一样,在特权进程中永远都不应该使用 popen().
popenAvantages et inconvénients :
-
Avantages : Toutes les extensions de paramètres sous Linux sont effectuées par le shell. Donc au démarrage
command命令之前程序先启动 shell 来分析command字符串,就可以使用各种 shell 扩展(比如通配符),这样我们可以通过popen()appelez une commande shell très complexe -
Inconvénient : Pour chaque
popen()调用,不仅要启动一个被请求的程序,还需要启动一个 shell。即每一个popen(), deux processus seront lancés.从效率和资源的角度看,popen()函数的调用比正常方式要慢一些
pipe()` VS `popen()
-
pipe()是一个底层调用,popen()是一个高级的函数 -
pipe()单纯的创建管道,而popen()创建管道的同时fork()子进程 -
popen()在两个进程中传递数据时需要调用 shell 来解释请求命令;pipe()在两个进程中传递数据不需要启动 shell 来解释请求命令,同时提供了对读写数据的更多控制(popen()必须时 shell 命令,pipe()则无硬性要求) -
popen()函数是基于文件流(FILE)工作的,而pipe()是基于文件描述符工作的,所以在使用pipe()后,数据必须要用底层的read()和write()调用来读取和发送
管道和 stdio 缓冲
由于 popen() 调用返回的文件流指针没有引用一个终端,因此 stdio 库会对这种流应用块缓冲。这意味着当 mode 的值为 w 来调用 popen() 时,默认情况下只有当 stdio 缓冲区被充满或者使用 pclose() 关闭了管道之后才会被发送到管道的另一端的子进程。在很多情况下,这种处理方式是不存在问题的。Mais si vous devez vous assurer que le processus enfant peut recevoir immédiatement les données du tube, vous devez appeler fflush() 或使用 setbuf(fp, NULL) 调用禁用 stdio 缓冲。当使用 pipe() 系统调用创建管道,然后使用 fdopen() régulièrement. Cette technique peut également être utilisée lors de l'obtention d'un flux stdio correspondant à la fin d'écriture du tube
Si appelé popen() 的进程正在从管道中读取数据(即 mode 是 r),那么事情就不是那么简单了。在这样情况下如果子进程正在使用 stdio 库,那么——除非它显式地调用了 fflush() 或 setbuf() ,其输出只有在子进程填满 stdio 缓冲器或调用了 fclose() 之后才会对调用进程可用。(如果正在从使用 pipe() 创建的管道中读取数据并且向另一端写入数据的进程正在使用 stdio 库,那么同样的规则也是适用的。)如果这是一个问题,那么能采取的措施就比较有限的,除非能够修改在子进程中运行的程序的源代码使之包含对 setbuf() 或 fflush() est appelé.
Si vous ne pouvez pas modifier le code source, vous pouvez utiliser un pseudo terminal pour remplacer le tube. Un pseudo-terminal est un canal IPC qui apparaît à un processus comme un terminal. Le résultat est que la bibliothèque stdio affiche les données dans le tampon ligne par ligne.
Tuyau nommé (FIFO)
Bien que le pipeline ci-dessus implémente la communication inter-processus, il présente certaines limites :
- Les tuyaux anonymes ne peuvent communiquer qu'entre des processus liés par le sang
- Il ne peut permettre qu'à un processus d'écrire et à un autre processus de lire. Si vous devez faire les deux en même temps, vous devez rouvrir un tube .
Afin de permettre la communication entre deux processus quelconques, des tubes nommés (named pipe ou FIFO) ont été proposés :
- FIFO 与管道的区别:FIFO 在文件系统中拥有一个名称,并且其打开方式与打开一个普通文件一样,能够实现任何两个进程之间通信。而匿名管道对于文件系统是不可见的,它仅限于在父子进程之间的通信
-
一旦打开了 FIFO,就能在它上面使用与操作管道和其他文件的系统调用一样的 IO 系统调用
read(),write(),close()。与管道一样,FIFO 也有一个写入端和读取端,并且总是遵循先进先出的原则,即第一个进来的数据会第一个被读走 - 与管道一样,当所有引用 FIFO 的描述符都关闭之后,所有未被读取的数据都将被丢弃
-
使用
mkfifo命令可以在 shell 中创建一个 FIFO:
mkfifo [-m mode] pathname
-
pathname是创建的 FIFO 的名称,-m选项指定权限mode,其工作方式与chmod命令一样 -
fstat()和stat()函数会在stat结构的st_mode字段返回S_IFIFO,使用ls -l列出文件时,FIFO 文件在第一列的类型为p,ls -F会在 FIFO 路径名后面附加管道符|
#include #include int mkfifo(const char *pathname,mode_t mode);
-
mode参数指定了新 FIFO 的权限,这些权限会按照进程的umask值来取掩码 - 一旦创建了 FIFO,任何进程都能够打开它,只要它通过常规的文件权限检测
-
使用 FIFO 时唯一明智的做法是在两端分别设置一个读取进程和一个写入进程。这样在默认情况下,打开一个 FIFO 以便读取数据(
open() O_RDONLY标记)将会阻塞直到另一个进程打开 FIFO 以写入数(open() O_WRONLY标记)为止。相应地,打开一个 FIFO 以写入数据将会阻塞直到另一个进程打开 FIFO 以读取数据为止。换句话说,打开一个 FIFO 会同步读取进程和写入进程。如果一个 FIFO 的另一端已经打开(可能是因为一对进程已经打开了 FIFO 的两端),那么open()调用会立即成功。
在大多数 Unix 实现上(包含 Linux),当打开一个 FIFO 时可以通过指定 O_RDWR 标记来绕过打开 FIFO 时的阻塞行为。这样,open() 会立即返回,但无法使用返回的文件描述符在 FIFO 上读取和写入数据。这种做法破坏了 FIFO 的 IO 模型,SUSv3 明确指出以 O_RDWR 标记打开一个 FIFO 的结果是未知的,因此出于可移植性的原因,开发人员不应该使用这项技术。对于那些需要避免在打开 FIFO 时发生阻塞的需求,open() 的 O_NONBLOCK 标记提供了一种标准化的方法来完成这个任务:
open(const char *path, O_RDONLY | O_NONBLOCK); open(const char *path, O_WRONLY | O_NONBLOCK);
在打开一个 FIFO 时避免使用 O_RDWR 标记还有另外一个原因,当采用那种方式调用 open() 之后,调用进程在从返回的文件描述符中读取数据时永远都不会看到文件结束,因为永远都至少存在一个文件描述符被打开着以等待数据被写入 FIFO,即进程从中读取数据的那个描述符。
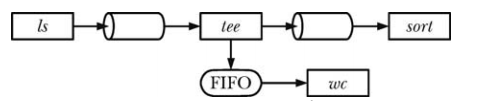
使用 FIFO 和 tee 创建双重管道线
shell 管道线的其中一个特征是它们是线性的,管道线中的每个进程都能读取前一个进程产生的数据并将数据发送到其后一个进程中,使用 FIFO 就能够在管道线中创建子进程,这样除了将一个进程的输出发送给管道线中的后面一个进程之外,还可以复制进程的输出并将数据发送到另一个进程中,要完成这个任务就需要使用 tee 命令,它将其从标准输入中读取到的数据复制两份并输出:一份写入标准输出,另一份写入到通过命令行参数指定的文件中。
mkfifo myfifo wc -l
非阻塞 IO
当一个进程打开一个 FIFO 的一端时,如果 FIFO 的另一端还没有被打开,那么该进程会被阻塞。但有些时候阻塞并不是期望的行为,而这可以通过在调用 open() 时指定 O_NONBLOCK 标记来实现。
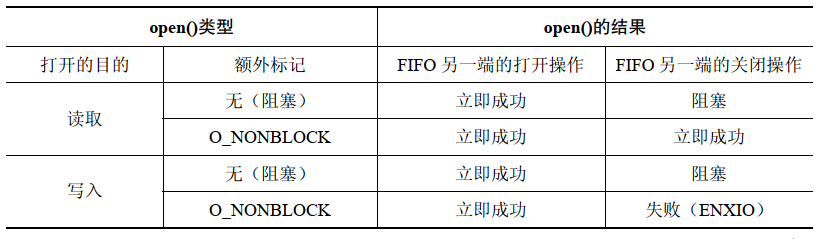
如果 FIFO 的另一端已经被打开,那么 O_NONBLOCK 对 open() 调用不会产生任何影响,它会像往常一样立即成功地打开 FIFO。只有当 FIFO 的另一端还没有被打开的时候 O_NONBLOCK 标记才会起作用,而具体产生的影响则依赖于打开 FIFO 是用于读取还是用于写入的:
-
如果打开 FIFO 是为了读取,并且 FIFO 的写入端当前已经被打开,那么
open()调用会立即成功(就像 FIFO 的另一端已经被打开一样) -
如果打开 FIFO 是为了写入,并且还没有打开 FIFO 的另一端来读取数据,那么
open()调用会失败,并将errno设置为ENXIO
为读取而打开 FIFO 和为写入而打开 FIFO 时 O_NONBLOCK 标记所起的作用不同是有原因的。当 FIFO 的另一个端没有写者时打开一个 FIFO 以便读取数据是没有问题的,因为任何试图从 FIFO 读取数据的操作都不会返回任何数据。但当试图向没有读者的 FIFO 中写入数据时将会导致 SIGPIPE 信号的产生以及 write() 返回 EPIPE 错误。
在 FIFO 上调用 open() 的语义总结如下:
在打开一个 FIFO 时,使用 O_NOBLOCK 标记存在两个目的:
-
它允许单个进程打开一个 FIFO 的两端,这个进程首先会在打开 FIFO 时指定
O_NOBLOCK标记以便读取数据,接着打开 FIFO 以便写入数据 - 它防止打开两个 FIFO 的进程之间产生死锁
例如,下面的情况将会发生死锁:

非阻塞 read() 和 write()
O_NONBLOCK 标记不仅会影响 open() 的语义,而且还会影响——因为在打开的文件描述中这个标记仍然被设置着——后续的 read() 和 write() 调用的语义。
有些时候需要修改一个已经打开的 FIFO(或另一种类型的文件)的 O_NONBLOCK 标记的状态,具体存在这个需求的场景包括以下几种:
-
使用
O_NONBLOCK打开了一个 FIFO 但需要后续的read()和write()在阻塞模式下运行 -
需要启用从
pipe()返回的一个文件描述符的非阻塞模式。更一般地,可能需要更改从除open()调用之外的其他调用中,如每个由 shell 运行的新程序中自动被打开的三个标准描述符的其中一个或socket()返回的文件描述符,取得的任意文件描述符的非阻塞状态 -
出于一些应用程序的特殊需求,需要切换一个文件描述符的
O_NONBLOCK设置的开启和关闭状态
当碰到上面的需求时可以使用 fcntl() 启用或禁用打开着的文件的 O_NONBLOCK 状态标记。通过下面的代码(忽略的错误检查)可以启用这个标记:
int flags; flags = fcntl(fd, F_GETFL); flags != O_NONBLOCK; fcntl(fd, F_SETFL, flags);
通过下面的代码可以禁用这个标记:
flags = fcntl(fd, F_GETFL); flags &= ~O_NONBLOCK; fcntl(fd, F_SETFL, flags);
管道和 FIFO 中 read() 和 write() 的语义
FIFO 上的 read() 操作:
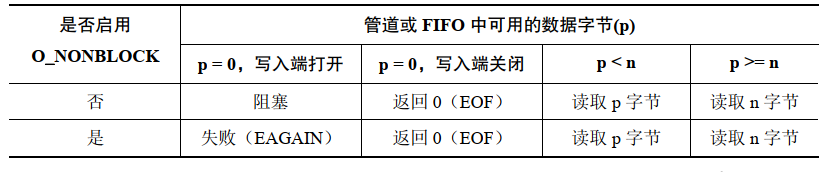
只有当没有数据并且写入端没有被打开时阻塞和非阻塞读取之间才存在差别。在这种情况下,普通的 read() 会被阻塞,而非阻塞 read() 会失败并返回 EAGAIN 错误。
当 O_NONBLOCK 标记与 PIPE_BUF 限制共同起作用时 O_NONBLOCK 标记对象管道或 FIFO 写入数据的影响会变得复杂。
FIFO 上的 write() 操作:
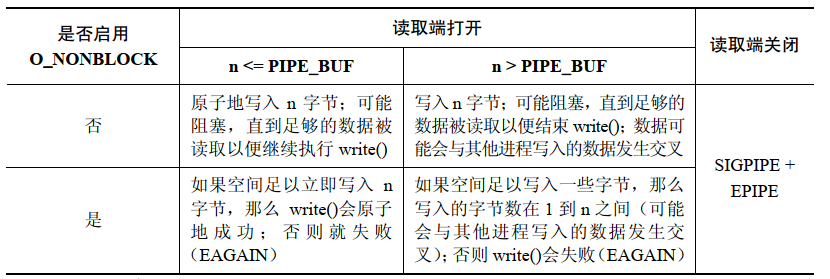
-
Lorsque les données ne peuvent pas être transférées immédiatement
O_NONBLOCK标记会导致在一个管道或 FIFO 上的write()失败(错误是EAGAIN)。这意味着当写入了PIPE_BUF字节之后,如果在管道或 FIFO 中没有足够的空间了,那么write()会失败,因为内核无法立即完成这个操作并且无法执行部分写入,否则就会破坏不超过PIPE_BUFExigences relatives à l'atomicité des opérations d'écriture d'octets -
Lorsque la quantité de données écrites en une seule fois dépasse
PIPE_BUF字节时,该写入操作无需是原子的。因此,write()会尽可能多地传输字节(部分写)以充满管道或 FIFO。在这种情况下,从write()返回的值是实际传输的字节数,并且调用者随后必须要进行重试以写入剩余的字节。但如果管道或 FIFO 已经满了,从而导致哪怕连一个字节都无法传输了,那么write()会失败并返回EAGAINerreur
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Entrée de la version Web Deepseek Entrée du site officiel Deepseek
Feb 19, 2025 pm 04:54 PM
Entrée de la version Web Deepseek Entrée du site officiel Deepseek
Feb 19, 2025 pm 04:54 PM
Deepseek est un puissant outil de recherche et d'analyse intelligent qui fournit deux méthodes d'accès: la version Web et le site officiel. La version Web est pratique et efficace et peut être utilisée sans installation; Que ce soit des individus ou des utilisateurs d'entreprise, ils peuvent facilement obtenir et analyser des données massives via Deepseek pour améliorer l'efficacité du travail, aider la prise de décision et promouvoir l'innovation.
 Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Il existe de nombreuses façons d'installer Deepseek, notamment: Compiler à partir de Source (pour les développeurs expérimentés) en utilisant des packages précompilés (pour les utilisateurs de Windows) à l'aide de conteneurs Docker (pour le plus pratique, pas besoin de s'inquiéter de la compatibilité), quelle que soit la méthode que vous choisissez, veuillez lire Les documents officiels documentent soigneusement et les préparent pleinement à éviter des problèmes inutiles.
 Installation officielle du site officiel de Bitget (Guide du débutant 2025)
Feb 21, 2025 pm 08:42 PM
Installation officielle du site officiel de Bitget (Guide du débutant 2025)
Feb 21, 2025 pm 08:42 PM
Bitget est un échange de crypto-monnaie qui fournit une variété de services de trading, notamment le trading au comptant, le trading de contrats et les dérivés. Fondée en 2018, l'échange est basée à Singapour et s'engage à fournir aux utilisateurs une plate-forme de trading sûre et fiable. Bitget propose une variété de paires de trading, notamment BTC / USDT, ETH / USDT et XRP / USDT. De plus, l'échange a une réputation de sécurité et de liquidité et offre une variété de fonctionnalités telles que les types de commandes premium, le trading à effet de levier et le support client 24/7.
 Le package d'installation OUYI OKX est directement inclus
Feb 21, 2025 pm 08:00 PM
Le package d'installation OUYI OKX est directement inclus
Feb 21, 2025 pm 08:00 PM
OUYI OKX, le premier échange mondial d'actifs numériques, a maintenant lancé un package d'installation officiel pour offrir une expérience de trading sûre et pratique. Le package d'installation OKX de OUYI n'a pas besoin d'être accessible via un navigateur. Le processus d'installation est simple et facile à comprendre.
 Obtenez le package d'installation Gate.io gratuitement
Feb 21, 2025 pm 08:21 PM
Obtenez le package d'installation Gate.io gratuitement
Feb 21, 2025 pm 08:21 PM
Gate.io est un échange de crypto-monnaie populaire que les utilisateurs peuvent utiliser en téléchargeant son package d'installation et en l'installant sur leurs appareils. Les étapes pour obtenir le package d'installation sont les suivantes: Visitez le site officiel de Gate.io, cliquez sur "Télécharger", sélectionnez le système d'exploitation correspondant (Windows, Mac ou Linux) et téléchargez le package d'installation sur votre ordinateur. Il est recommandé de désactiver temporairement les logiciels antivirus ou le pare-feu pendant l'installation pour assurer une installation fluide. Une fois terminé, l'utilisateur doit créer un compte Gate.io pour commencer à l'utiliser.
 OUYI Exchange Télécharger le portail officiel
Feb 21, 2025 pm 07:51 PM
OUYI Exchange Télécharger le portail officiel
Feb 21, 2025 pm 07:51 PM
Ouyi, également connu sous le nom d'OKX, est une plate-forme de trading de crypto-monnaie de pointe. L'article fournit un portail de téléchargement pour le package d'installation officiel d'Ouyi, qui facilite les utilisateurs pour installer le client Ouyi sur différents appareils. Ce package d'installation prend en charge les systèmes Windows, Mac, Android et iOS. Une fois l'installation terminée, les utilisateurs peuvent s'inscrire ou se connecter au compte OUYI, commencer à négocier des crypto-monnaies et profiter d'autres services fournis par la plate-forme.
 GATE.IO Lien du package d'installation d'enregistrement du site Web officiel
Feb 21, 2025 pm 08:15 PM
GATE.IO Lien du package d'installation d'enregistrement du site Web officiel
Feb 21, 2025 pm 08:15 PM
Gate.io est une plate-forme de trading de crypto-monnaie très acclamée connue pour sa sélection de jetons étendue, ses frais de transaction faibles et une interface conviviale. Avec ses fonctionnalités de sécurité avancées et son excellent service client, Gate.io offre aux traders un environnement de trading de crypto-monnaie fiable et pratique. Si vous souhaitez rejoindre Gate.io, veuillez cliquer sur le lien fourni pour télécharger le package d'installation d'enregistrement officiel pour démarrer votre parcours de trading de crypto-monnaie.
 Comment installer phpmyadmin avec nginx sur Ubuntu?
Feb 07, 2025 am 11:12 AM
Comment installer phpmyadmin avec nginx sur Ubuntu?
Feb 07, 2025 am 11:12 AM
Ce tutoriel vous guide à travers l'installation et la configuration de Nginx et PhpMyAdmin sur un système Ubuntu, potentiellement aux côtés d'un serveur Apache existant. Nous couvrirons la configuration de Nginx, résolvant les conflits de port potentiels avec Apache, l'installation de MariaDB (
