
 Périphériques technologiques
IA
Pratique de l'inférence causale dans la courte recommandation vidéo de Kuaishou
Périphériques technologiques
IA
Pratique de l'inférence causale dans la courte recommandation vidéo de Kuaishou
Pratique de l'inférence causale dans la courte recommandation vidéo de Kuaishou


1. Scène de recommandation vidéo courte sur une seule colonne de Kuaishou
1. À propos de Kuaishou
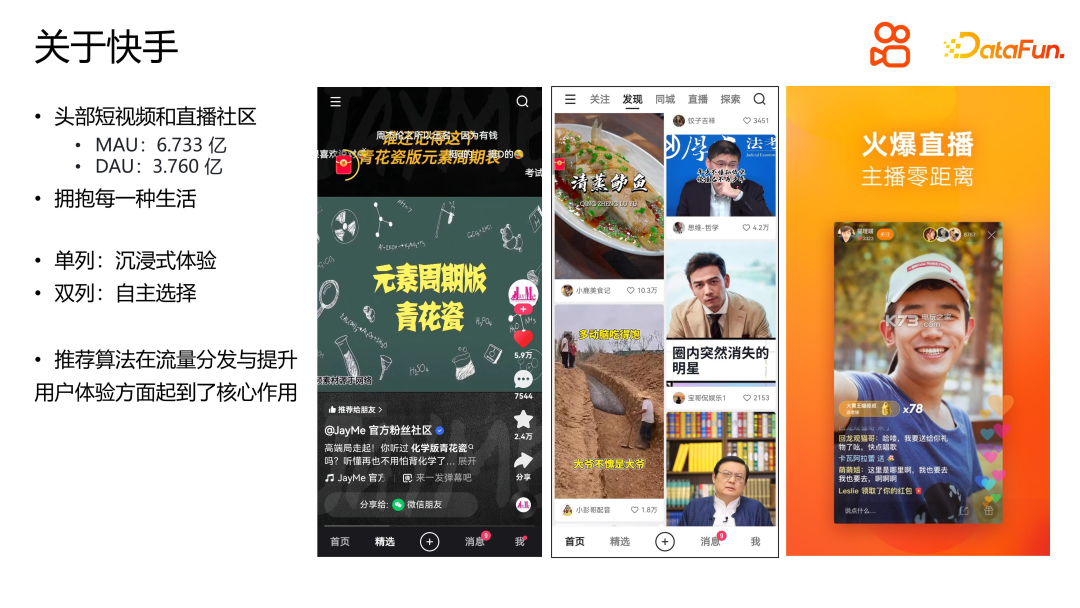
*Les données sont tirées du deuxième trimestre 2023
Kuaishou est un A populaire Application communautaire de courte vidéo et de streaming en direct, elle a atteint de nouveaux records MAU et DAU impressionnants au deuxième trimestre de cette année. Le concept central de Kuaishou est de permettre à chacun de devenir créateur et diffuseur de contenu en observant et en partageant la vie des gens ordinaires. Dans les applications Kuaishou, les scènes vidéo courtes sont principalement divisées en deux formes : simple colonne et double colonne. À l'heure actuelle, le trafic d'une seule colonne est relativement important et les utilisateurs peuvent parcourir le contenu vidéo de manière immersive en glissant de haut en bas. La présentation en double colonne est similaire à un flux d'informations. Les utilisateurs doivent sélectionner ceux qui les intéressent parmi les différents contenus apparaissant à l'écran et cliquer pour regarder. L'algorithme de recommandation est au cœur de l'écosystème commercial de Kuaishou et joue un rôle important dans la répartition du trafic et l'amélioration de l'expérience utilisateur. En analysant les intérêts des utilisateurs et les données comportementales, Kuaishou peut proposer avec précision un contenu qui répond aux goûts des utilisateurs, améliorant ainsi la fidélité et la satisfaction des utilisateurs. En général, Kuaishou, en tant qu'application communautaire de courte vidéo et de diffusion en direct au niveau national, continue d'attirer de plus en plus d'utilisateurs à la rejoindre grâce à son concept unique d'observation et de partage de la vie des gens ordinaires, ainsi qu'à son excellent algorithme de recommandation, et parmi les utilisateurs Remarquable des résultats ont été obtenus en termes d'expérience et de répartition du trafic.
2. Scénario de recommandation de vidéo courte à colonne unique Kuaishou

Dans le scénario de recommandation de vidéo courte Kuaishou, une seule colonne est le formulaire principal. Les utilisateurs parcourent les vidéos via le mode de comportement consistant à glisser de haut en bas, une fois la vidéo glissée, elle sera automatiquement lue sans que l'utilisateur ait à sélectionner puis à cliquer pour déclencher la lecture. De plus, il existe de nombreuses formes de commentaires des utilisateurs, notamment le suivi, les likes, le partage de commentaires, le déplacement de la barre de progression, etc. Avec le développement des entreprises, les formulaires interactifs se diversifient de plus en plus. Les objectifs d'optimisation incluent les objectifs à long terme et les objectifs à court terme, notamment l'optimisation de l'expérience utilisateur et la conservation des DAU, tandis que les indicateurs à court terme couvrent divers commentaires positifs des utilisateurs.
Le système de recommandation est basé sur le machine learning et le deep learning, et les logs proviennent principalement des caractéristiques et des retours générés par les comportements réels des utilisateurs. Cependant, les journaux ont des limites et ne peuvent refléter que des informations limitées sur les intérêts actuels de l'utilisateur, et les informations privées telles que son vrai nom, sa taille et son poids ne peuvent pas être obtenues. Dans le même temps, l'algorithme de recommandation est basé sur l'apprentissage et la formation antérieurs des journaux, puis le recommande aux utilisateurs, ce qui présente les caractéristiques d'une boucle automatique. De plus, en raison de l'audience large et variée, du grand nombre de vidéos et des mises à jour fréquentes, le système de recommandation est sujet à divers biais, tels que le biais de popularité, le biais d'exposition de vidéos longues et courtes, etc. Dans le cadre d'une courte recommandation vidéo, la modélisation des biais à l'aide de la technologie d'inférence causale peut aider à corriger les biais et à améliorer les effets des recommandations.
2. Technologie d'inférence causale et représentation de modèle
Ensuite, nous partagerons notre travail avec notre équipe fraternelle sur l'inférence causale et la représentation de modèle.
1.Contexte

Les systèmes recommandés effectuent généralement l'apprentissage de modèles en analysant les journaux d'interaction. Les commentaires des utilisateurs ne proviennent pas seulement de leurs préférences pour le contenu, mais sont également affectés par la mentalité de troupeau. En prenant comme exemple la sélection de films, les utilisateurs peuvent prendre en compte le statut primé de l'œuvre ou les opinions de leur entourage lorsqu'ils prennent des décisions. Il existe des différences dans la mentalité de troupeau entre les différents utilisateurs. Certains utilisateurs sont plus subjectifs et indépendants, tandis que d’autres sont plus sensibles à l’influence des autres ou à la popularité. Par conséquent, lors de l'attribution des interactions des utilisateurs, en plus de prendre en compte les intérêts de l'utilisateur, il est également nécessaire de prendre en compte les facteurs de psychologie du troupeau.
La plupart des travaux existants traitent la popularité comme un écart statique. Par exemple, la popularité d'un film est uniquement liée à un élément et l'écart entre les utilisateurs n'est pas pris en compte lors de la modélisation des évaluations des utilisateurs et des éléments. La popularité est généralement utilisée comme élément de notation distinct, qui est lié au nombre d'expositions de l'élément, et il y a moins de biais pour les éléments moins populaires. Cette façon de modéliser est statique et relative aux éléments. Avec l'application de la technologie d'inférence causale dans le domaine de la recommandation, certaines recherches tentent de résoudre ce problème par le biais d'une représentation découplée et de considérer la différence de psychologie du troupeau lorsque les utilisateurs sélectionnent des éléments. Par rapport aux méthodes existantes, notre méthode peut modéliser avec plus de précision les différences de mentalité de troupeau des utilisateurs, corrigeant ainsi plus efficacement les écarts et améliorant les effets des recommandations.
2. Travaux connexes
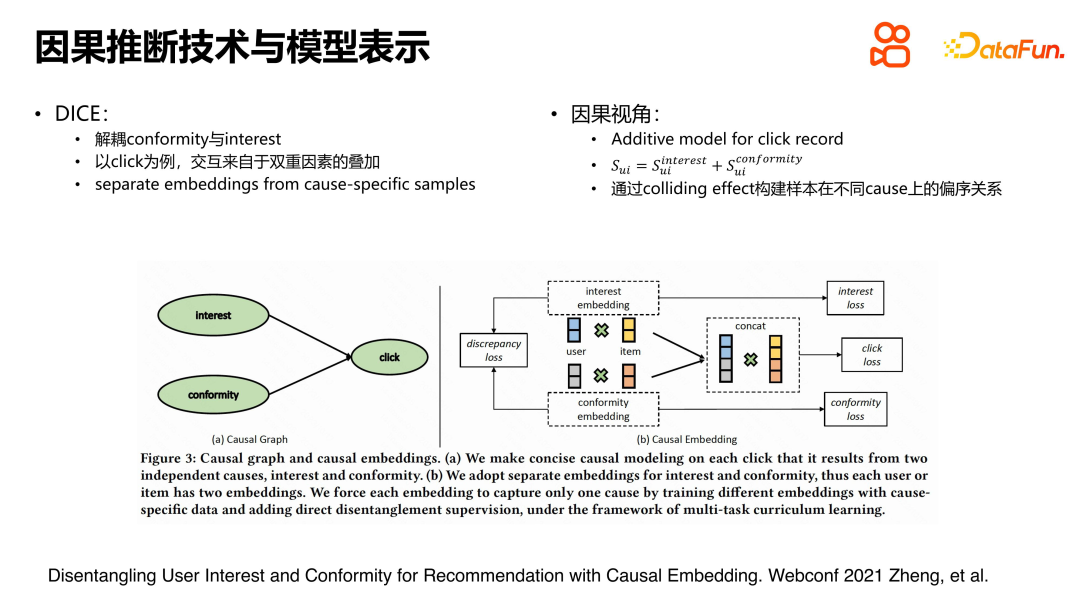
Dans un article de Webconf2021, l'interaction de l'utilisateur est modélisée comme étant affectée à la fois par l'intérêt de l'utilisateur pour l'article et par le degré de mentalité de troupeau que l'article a sur l'utilisateur lors du choix de l'article. article. . Le diagramme de la relation causale est présenté à gauche et la relation est relativement simple. Dans une modélisation spécifique, les représentations de l'utilisateur et de l'élément sont divisées en représentation d'intérêt et représentation de conformité. Pour l'expression d'intérêt, une perte d'intérêt est construite ; pour l'expression de conformité, une perte de confirmation est construite pour un comportement de rétroaction, une perte de clic est construite ; En raison de la division de la structure de représentation, la perte d'intérêt est utilisée comme signal de supervision pour apprendre la représentation des intérêts, tandis que la perte de confirmation est utilisée pour modéliser la représentation de la mentalité de troupeau. La perte de clics est liée à deux facteurs et se construit donc par concaténation et intersection. L’ensemble de l’approche est clair et simple.
Lors de la construction de la perte d'intérêts et de la perte de confirmation, cette recherche utilise également certains concepts et techniques d'inférence causale. Par exemple, si une vidéo ou un élément impopulaire suscite des interactions positives, c'est probablement parce que les utilisateurs l'ont réellement aimé. Cela peut être confirmé par vérification inverse : si un article n’est pas populaire et que les utilisateurs ne s’y intéressent pas, il est peu probable qu’il y ait une interaction positive. Quant à la perte de clics, une méthode de traitement courante est adoptée, à savoir la perte par paire. Concernant l’effet de collision, les lecteurs intéressés peuvent se référer à l’article pour une méthode de construction plus détaillée.
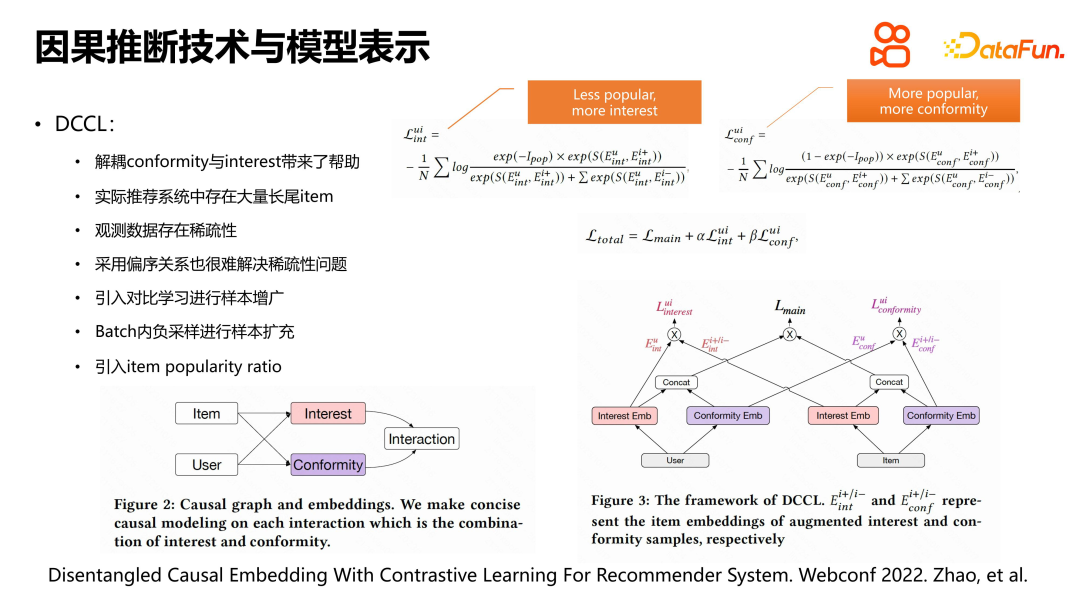
Lors de la résolution de problèmes complexes dans les systèmes de recommandation, certaines recherches partent de la représentation du modèle, visant à distinguer l'intérêt des utilisateurs pour les articles et la mentalité de troupeau. Toutefois, certains problèmes se posent au niveau de l’application pratique. Il existe un grand nombre de vidéos dans le système de recommandation et les expositions sont inégalement réparties. Les vidéos principales ont plus d'expositions et les vidéos longue traîne ont moins d'expositions, ce qui entraîne des données clairsemées. La parcimonie entraîne des difficultés d'apprentissage dans les modèles d'apprentissage automatique.
Pour résoudre ce problème, nous avons introduit l'apprentissage contrastif pour l'augmentation des échantillons. Plus précisément, en plus de l'interaction positive entre l'utilisateur et l'élément, nous avons également sélectionné d'autres vidéos appartenant à la plage de comportement de l'utilisateur comme échantillons négatifs à développer. Dans le même temps, nous avons utilisé le diagramme de cause à effet pour concevoir le modèle et diviser les représentations d'intérêt et de conformité du côté de l'utilisateur et de l'élément. La principale différence entre ce modèle et le DICE traditionnel est qu'il adopte la méthode d'apprentissage contrastif et d'augmentation d'échantillon lors de l'apprentissage des pertes d'intérêt et de confirmation, et construit des termes d'indice normalisés du rapport de popularité des articles pour la perte d'intérêt et la perte de confirmation respectivement. De cette façon, le problème de rareté des données peut être mieux géré et l'intérêt des utilisateurs et leur mentalité de troupeau pour des éléments de popularité différente peuvent être modélisés avec plus de précision.
3. Résumé
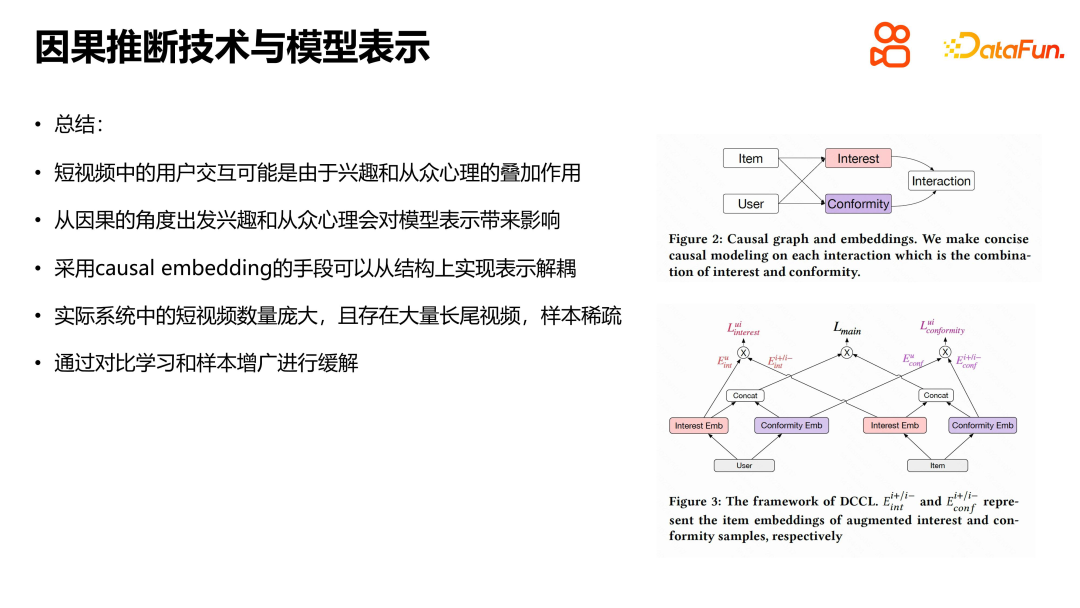
Ce travail est basé sur la superposition de l'intérêt et de la psychologie du troupeau dans de courtes interactions vidéo, et utilise la technologie d'inférence causale et les méthodes d'intégration causale pour réaliser le découplage de la représentation structurelle. Dans le même temps, compte tenu du problème de la rareté des échantillons vidéo à longue traîne dans les systèmes réels, des méthodes d'apprentissage contrastif et d'augmentation d'échantillons sont utilisées pour atténuer la rareté. Ce travail combine des modèles de représentation en ligne et une inférence causale pour obtenir un certain effet de découplage de conformité. Cette méthode a donné de bons résultats dans les expériences hors ligne et en ligne et a été utilisée avec succès dans les expériences LTR de recommandation de Kuaishou, apportant certaines améliorations d'effet.
3. Estimation de la durée de visionnage et technologie d'inférence causale
1. Importance de la durée de visionnage
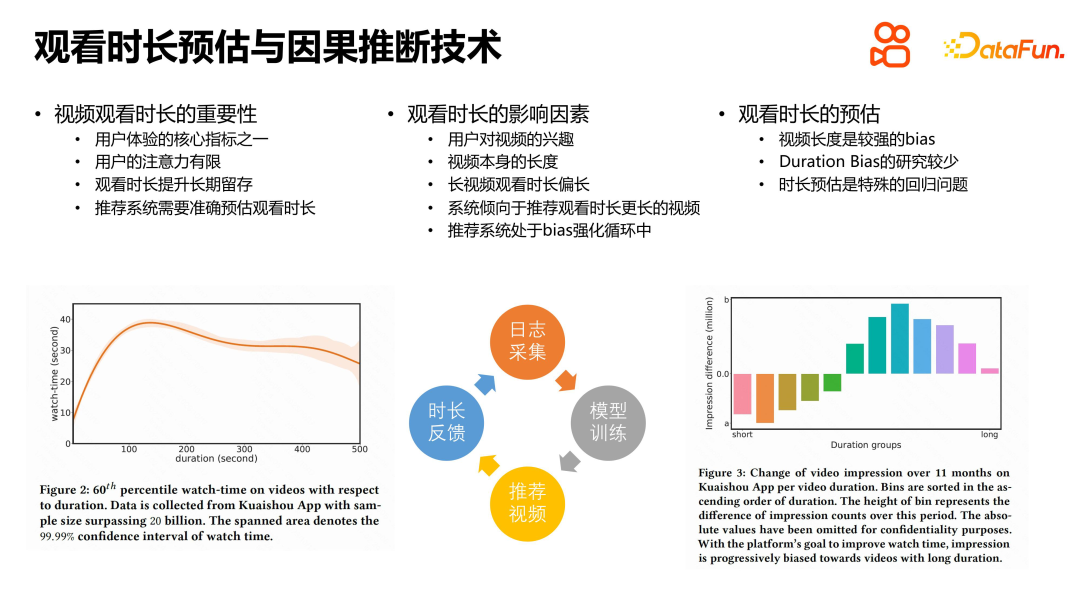
Dans le secteur de la recommandation de vidéos courtes, la durée de visionnage est un objectif d'optimisation important, qui est étroitement lié à les utilisateurs Les mesures à long terme telles que la rétention, la DAU et les visites répétées sont étroitement liées. Afin d'améliorer l'expérience utilisateur, nous devons nous concentrer sur des indicateurs comportementaux intermédiaires lors de la recommandation de vidéos aux utilisateurs. L'expérience montre que la durée de visionnage est une mesure très précieuse, car les utilisateurs ont une capacité d'attention limitée. En observant les changements dans la durée de visionnage des utilisateurs, nous pouvons mieux comprendre quels facteurs affectent l’expérience visuelle des utilisateurs.
La longueur de la vidéo est l'un des facteurs importants qui affectent la durée de visionnage. À mesure que la durée de la vidéo augmente, la durée de visionnage de l'utilisateur augmentera également en conséquence, mais les vidéos trop longues peuvent entraîner une diminution des effets marginaux, voire une légère diminution de la durée de visionnage. Par conséquent, le système de recommandation doit trouver un point d’équilibre pour recommander une durée de vidéo adaptée aux besoins de l’utilisateur.
Afin d'optimiser le temps de visionnage, le système de recommandation doit prédire le temps de visionnage de l'utilisateur. Cela implique un problème de régression car la durée est une valeur continue. Cependant, il y a moins de travaux liés à la durée, probablement parce que le secteur de la recommandation de vidéos courtes est relativement nouveau, alors que la recherche sur les systèmes de recommandation a une longue histoire.
Lors de la résolution du problème de l'estimation du temps de visionnage, d'autres facteurs que la durée de la vidéo peuvent être pris en compte, tels que l'intérêt de l'utilisateur, la qualité du contenu vidéo, etc. En prenant ces facteurs en considération, la précision des prédictions est améliorée et les utilisateurs bénéficient d'une meilleure expérience de recommandation. Dans le même temps, nous devons également itérer et optimiser en permanence l’algorithme de recommandation pour nous adapter aux changements du marché et aux changements des besoins des utilisateurs.
2, D2Q
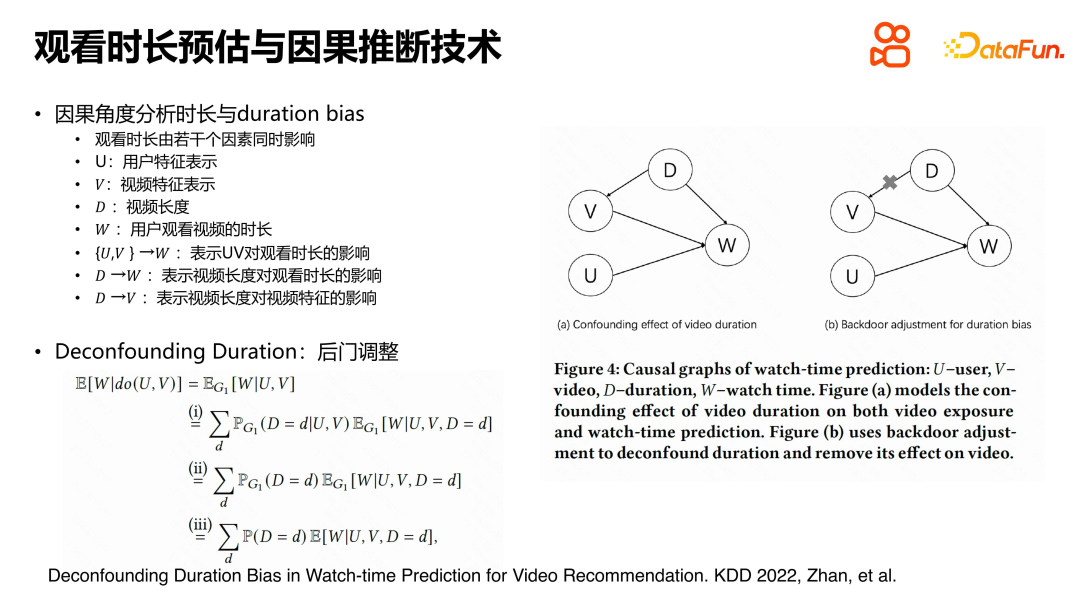
Lors de la conférence KDD212, nous avons proposé une nouvelle méthode pour résoudre le problème de l'estimation de la durée dans la recommandation de vidéos courtes. Ce problème découle principalement du phénomène d’auto-renforcement du biais de durée dans l’inférence causale. Pour résoudre ce problème, nous introduisons un diagramme de cause à effet pour décrire la relation entre les utilisateurs, les vidéos et la durée de visionnage.
Dans le diagramme de cause à effet, U et V représentent respectivement la représentation caractéristique de l'utilisateur et de la vidéo, W représente la durée pendant laquelle l'utilisateur regarde la vidéo et D représente la durée de la vidéo. Nous avons constaté qu'en raison du processus de génération autocyclique du système de recommandation, la durée n'est pas seulement directement liée à la durée de visionnage, mais affecte également l'apprentissage de la représentation vidéo.
Afin d'éliminer l'impact de la durée sur la représentation vidéo, nous avons utilisé le calcul pour la dérivation. La conclusion finale montre que pour résoudre ce problème par ajustement détourné, la méthode la plus simple et la plus directe consiste à estimer la durée de visionnage séparément pour les échantillons correspondant à chaque durée vidéo. Cela peut éliminer l'effet d'amplification de la durée sur la durée de visionnage, résolvant ainsi efficacement le problème du biais de durée dans l'inférence causale. L'idée principale de cette méthode est d'éliminer l'erreur de d à v, atténuant ainsi l'amplification du biais.

Lors de la résolution du problème de l'estimation de la durée dans la recommandation de vidéos courtes, nous avons adopté une méthode basée sur l'inférence causale pour éliminer l'erreur de d à v et obtenir une atténuation de l'amplification du biais. Afin de traiter le problème de la durée en tant que variable continue et de la répartition du nombre de vidéos, nous regroupons les vidéos dans le pool de recommandations en fonction de la durée et utilisons des quantiles pour le calcul. Les données au sein de chaque groupe sont divisées et utilisées pour entraîner le modèle au sein du groupe. Pendant le processus de formation, le quantile correspondant à la durée de la vidéo dans chaque groupe de durée est régressé au lieu de régresser directement la durée. Cela réduit la rareté des données et évite le surajustement du modèle. Lors de l'inférence en ligne, pour chaque vidéo, recherchez d'abord son groupe correspondant, puis calculez le quantile de durée correspondant. En consultant le tableau, vous pouvez trouver la durée de visionnage réelle en fonction des quantiles. Cette méthode simplifie le processus de raisonnement en ligne et améliore la précision de l'estimation de la durée. En résumé, notre méthode résout efficacement le problème d'estimation de la durée dans la recommandation vidéo courte en éliminant l'erreur de d à v, et fournit un support solide pour optimiser l'expérience utilisateur.
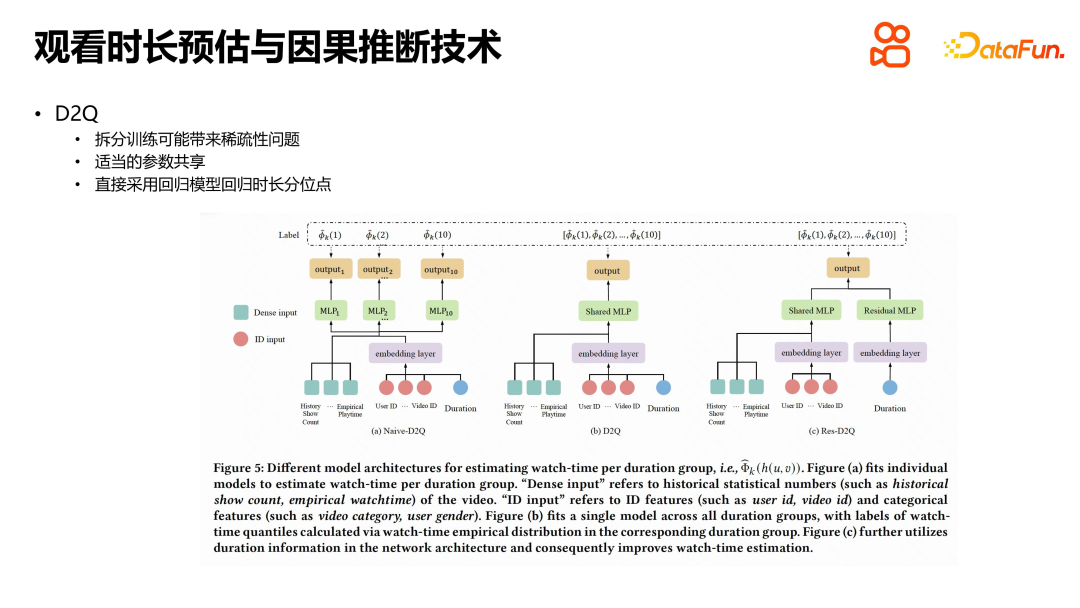
Lors de la résolution du problème de l'estimation de la durée dans la recommandation de vidéos courtes, nous avons également introduit une méthode de partage de paramètres pour réduire les difficultés techniques. Dans le processus de formation fractionnée, une approche idéale consiste à parvenir à une séparation complète des données, des fonctionnalités et des modèles, mais cela augmentera les coûts de déploiement. Par conséquent, nous avons choisi une méthode plus simple, qui consiste à partager l'intégration des fonctionnalités sous-jacentes et des paramètres de modèle de la couche intermédiaire, et à la diviser uniquement dans la couche de sortie. Afin d'étendre davantage l'impact de la durée sur la durée de visionnage réelle, nous introduisons une connexion résiduelle pour connecter directement la durée à la partie qui génère le quantile de la durée estimée, renforçant ainsi l'influence de la durée. Cette méthode réduit la difficulté technique et résout efficacement le problème de l’estimation de la durée dans la recommandation vidéo courte.
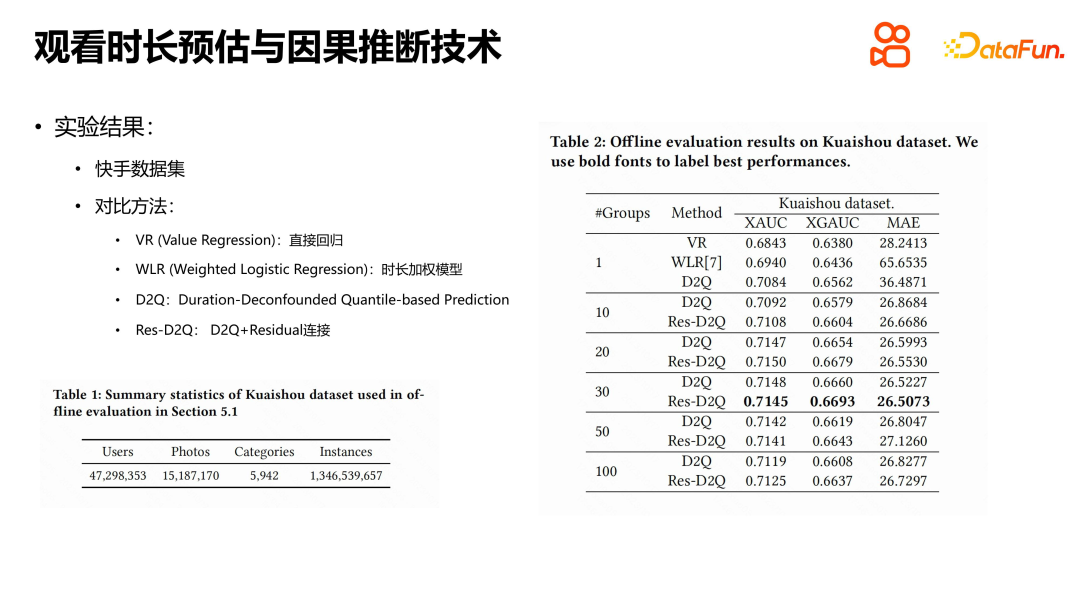
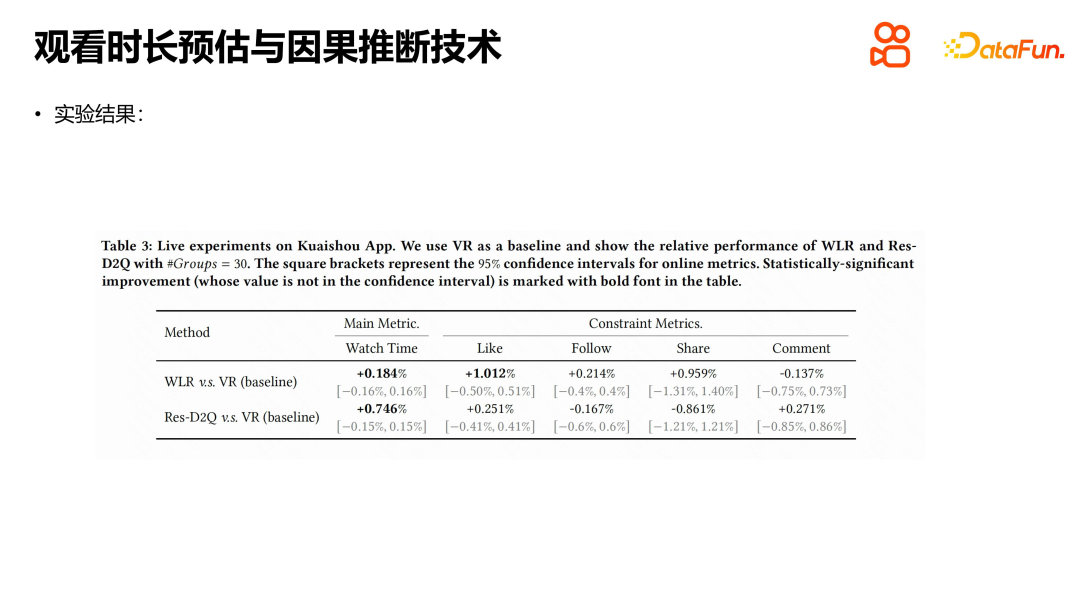
Dans l'expérience, l'ensemble de données publiques publié par Kuaishou a été principalement utilisé. En comparant plusieurs méthodes, nous pouvons constater que les performances des modèles de régression directe et pondérés en fonction de la durée ont leurs propres avantages. Le modèle pondéré en fonction de la durée n'est pas étranger aux systèmes de recommandation. Son idée principale est d'inclure la durée de visualisation comme poids des échantillons positifs dans le modèle. D2Q et Res-D2Q sont deux structures modèles basées sur l'inférence causale, parmi lesquelles Res-D2Q introduit des connexions résiduelles. Grâce à des expériences, nous avons constaté que les meilleurs résultats peuvent être obtenus lorsque les vidéos sont regroupées en 30 groupes en fonction de leur durée. Par rapport au modèle de régression naïf, la méthode D2Q présente des améliorations significatives et peut atténuer dans une certaine mesure le problème d'amplification en boucle automatique du biais de durée. Cependant, du point de vue du problème d’estimation de la durée, le défi n’est pas encore entièrement résolu.
3. TPM
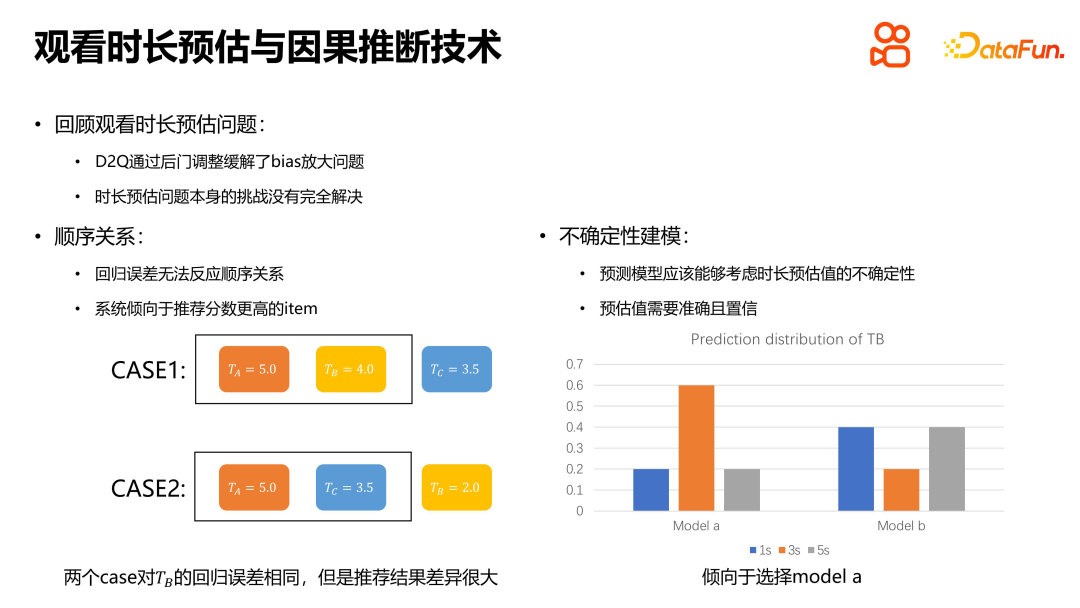
En tant que problème central du système de recommandation, le problème de l'estimation de la durée a ses propres caractéristiques et défis. Premièrement, le modèle de régression ne peut pas refléter la relation séquentielle entre les résultats des recommandations. Ainsi, même lorsque l’erreur de régression est la même, les résultats réels des recommandations peuvent être très différents. De plus, en plus de garantir l'exactitude de l'estimation, le modèle de prédiction doit également prendre en compte la confiance de l'estimation donnée par le modèle. Un modèle fiable doit non seulement donner des estimations précises, mais également donner cette estimation avec une probabilité élevée. Par conséquent, lors de la résolution du problème de l'estimation de la durée, nous devons non seulement prêter attention à l'exactitude de la régression, mais également tenir compte de la confiance du modèle et de la relation d'ordre des valeurs estimées.
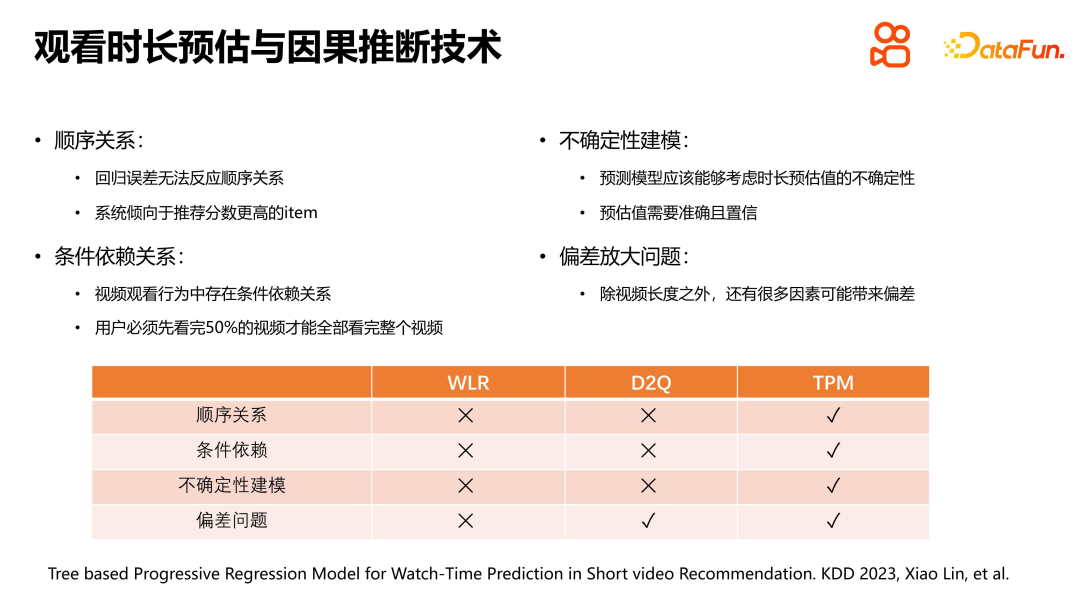
Dans le comportement de visionnage, il existe une dépendance conditionnelle à l'égard du visionnage continu des vidéos par l'utilisateur. Plus précisément, si regarder la vidéo dans son intégralité est un événement aléatoire, alors regarder d'abord 50 % de la vidéo est également un événement aléatoire, et il existe une stricte dépendance conditionnelle entre eux. La résolution du problème d’amplification du biais est très importante dans l’estimation du temps de visualisation, et la méthode D2Q résout bien ce problème. En revanche, notre approche TPM proposée vise à couvrir de manière exhaustive tous les problèmes d’estimation de durée.
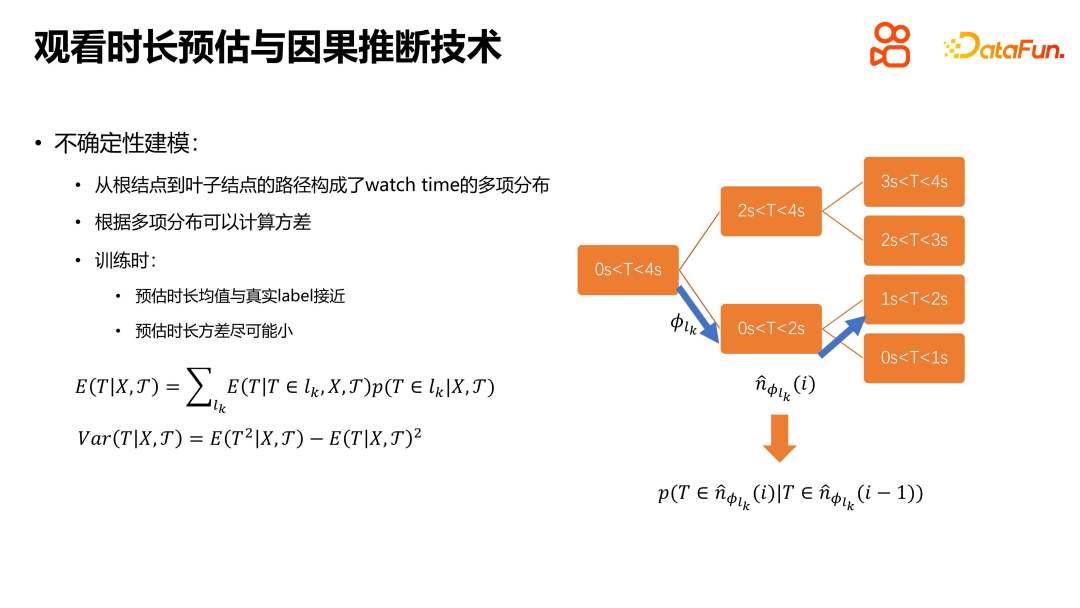
L'idée principale de la méthode TPM est de transformer le problème d'estimation de durée en un problème de recherche discrète. En construisant un arbre binaire complet, le problème d'estimation de durée est transformé en plusieurs problèmes de classification conditionnellement dépendants les uns des autres, puis un classificateur binaire est utilisé pour résoudre ces problèmes de classification. En effectuant continuellement une recherche binaire vers le bas, la probabilité de durée de visionnage dans chaque intervalle ordonné est déterminée, et finalement une distribution multinomiale de durée de visionnage est formée. Cette méthode peut résoudre efficacement le problème de modélisation de l'incertitude, en rendant la moyenne de la durée estimée aussi proche que possible de la valeur réelle, tout en réduisant la variance de la durée estimée. L'ensemble du problème du temps de visionnage ou du processus d'estimation peut être progressivement résolu en résolvant continuellement des problèmes de classification binaire interdépendants. Cette méthode fournit une nouvelle idée et un nouveau cadre pour résoudre le problème d'estimation de durée, ce qui peut améliorer la précision et la confiance de l'estimation.
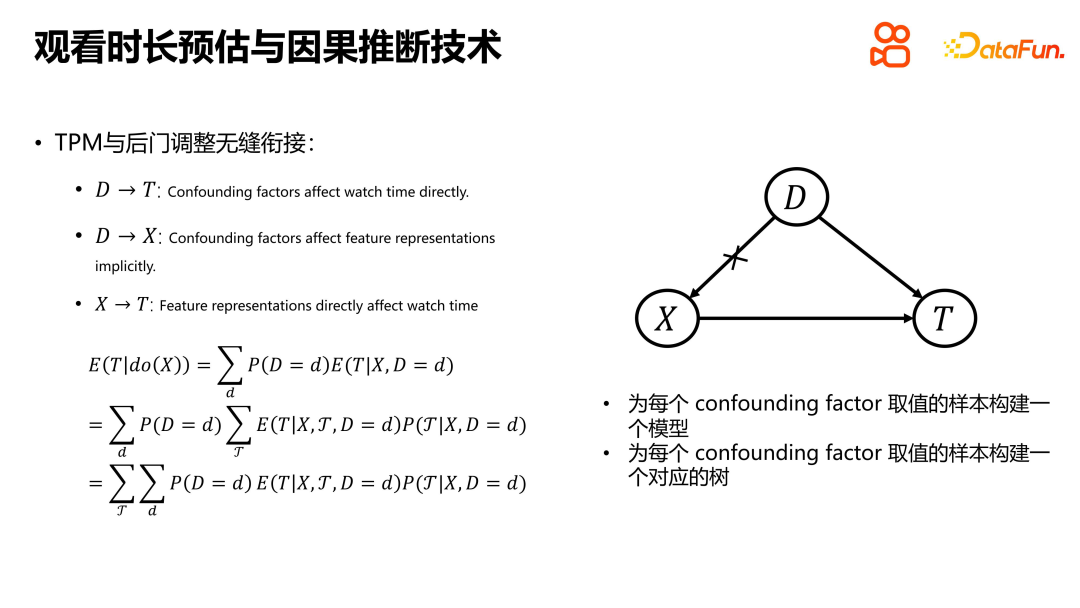
Présentant l'idée de modéliser la durée critique du TPM, il a démontré le lien transparent entre le TPM et l'ajustement de la porte dérobée de D2Q. Ici, un simple diagramme de cause à effet est utilisé pour associer les fonctionnalités côté utilisateur et élément à des facteurs de confusion. Afin de mettre en œuvre l'ajustement de porte dérobée dans TPM, il est nécessaire de créer un modèle correspondant pour chaque échantillon avec une valeur de facteur de confusion, et de créer un arbre TPM correspondant pour chaque facteur de confusion. Une fois ces deux étapes terminées, le TPM est connecté de manière transparente au réglage de la porte arrière. Ce type de connexion permet au modèle de mieux gérer les facteurs de confusion, améliorant ainsi la précision et la confiance des prédictions.
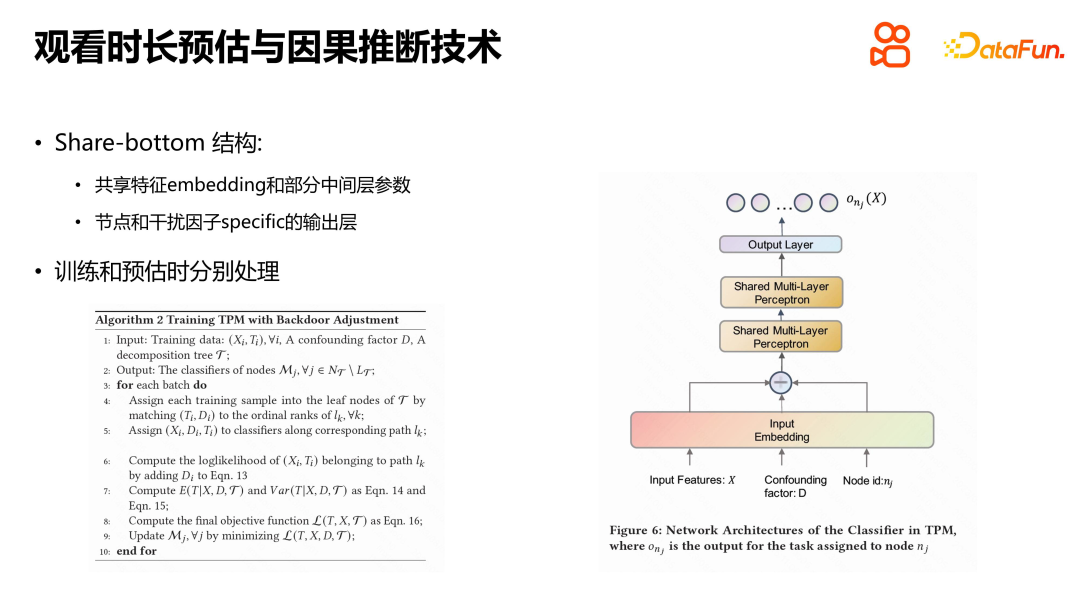
La solution spécifique consiste à créer un modèle correspondant pour chaque facteur de confusion de niveau profond, comme D2Q, cela entraînera également des problèmes de rareté des données et un traitement de fond de partage trop important est nécessaire pour convertir chaque échantillon. chaque facteur de confusion est intégré dans le même modèle, mais la représentation d'intégration sous-jacente, les paramètres intermédiaires, etc. du modèle sont tous partagés et ne sont liés qu'aux nœuds réels et aux valeurs des facteurs d'interférence dans la couche de sortie. Pendant l'entraînement, il vous suffit de trouver le véritable nœud feuille correspondant à chaque échantillon d'entraînement pour l'entraînement. Lors de l'estimation, puisque nous ne savons pas à quel nœud feuille appartient la durée de visualisation, nous devons parcourir de haut en bas et effectuer une somme pondérée de la probabilité de chaque nœud feuille où se trouve la durée de visualisation et de la durée attendue de le nœud feuille correspondant, pour obtenir l'heure de visualisation réelle. Cette méthode de traitement permet au modèle de mieux gérer les facteurs de confusion et améliore la précision et la confiance des prévisions.
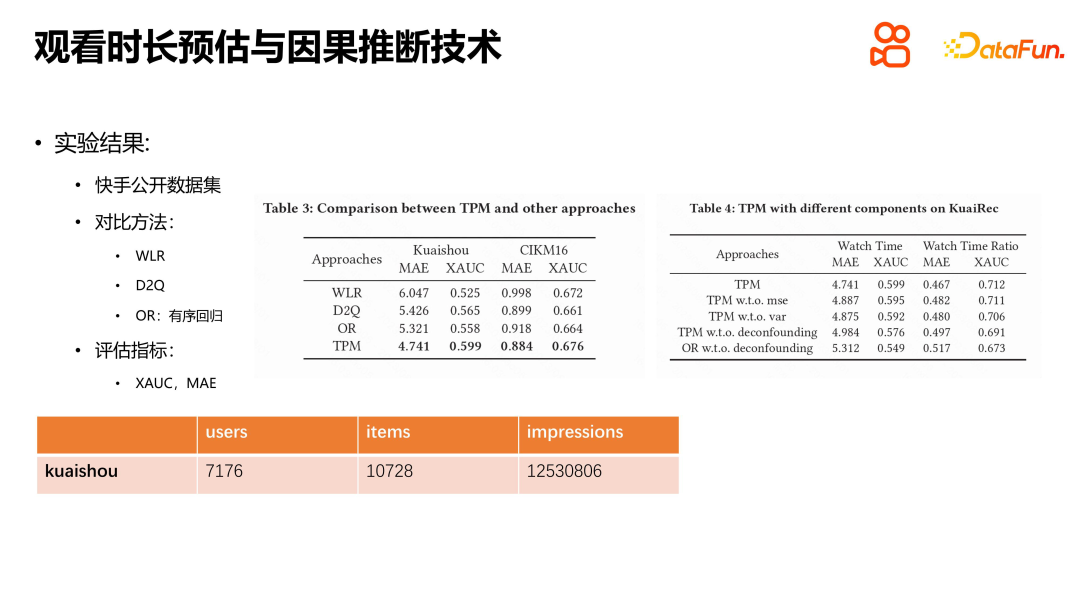
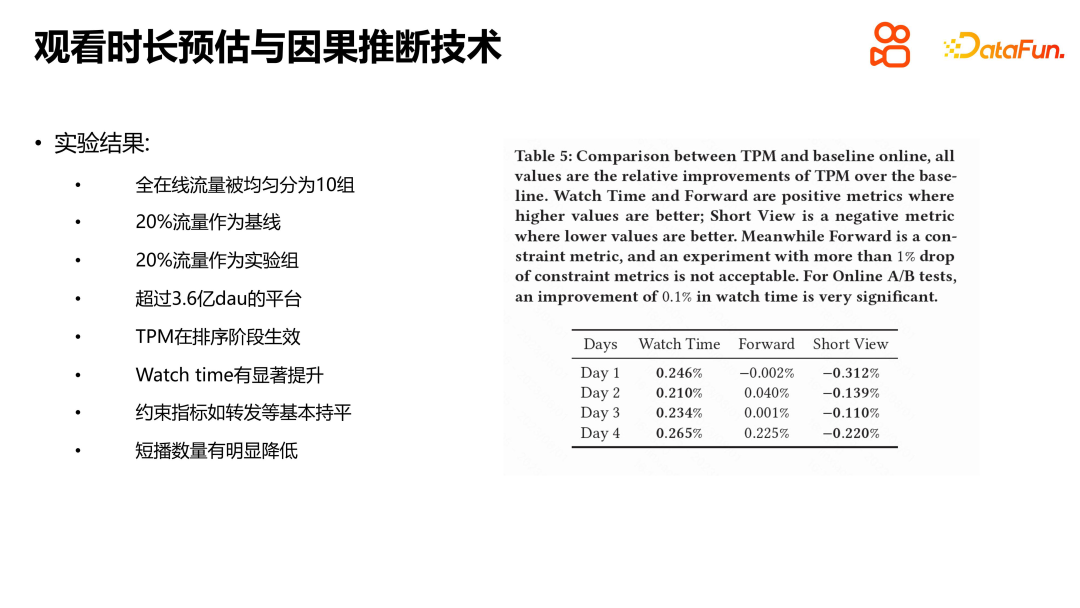
Nous avons mené des expériences sur l'ensemble de données publiques Kuaishou et l'ensemble de données CIKM16 sur le temps de séjour, en comparant des méthodes telles que WLR, D2Q et OR, et les résultats ont montré que le TPM présente des avantages significatifs. Chaque module a son rôle spécifique, et nous avons également mené des expériences par défaut. Les résultats expérimentaux montrent que chaque module joue un rôle. Nous avons également expérimenté le TPM en ligne. Les conditions expérimentales consistaient à diviser le trafic sélectionné par Kuaishou de manière égale en dix groupes, et 20 % du trafic a été utilisé comme référence pour la comparaison avec le groupe expérimental en ligne. Les résultats expérimentaux montrent que le TPM peut augmenter considérablement le temps de visionnage des utilisateurs lors de la phase de tri, tandis que les autres indicateurs restent fondamentalement les mêmes. Il convient de noter que les indicateurs négatifs tels que le nombre d’utilisateurs d’ondes courtes ont également diminué, ce qui, selon nous, a une certaine relation avec la précision des estimations de durée et la réduction de l’incertitude dans les estimations. La durée de visionnage est l'indicateur principal de la plate-forme de recommandation de vidéos courtes, et l'introduction du TPM est d'une grande importance pour améliorer l'expérience utilisateur et les indicateurs de la plate-forme.
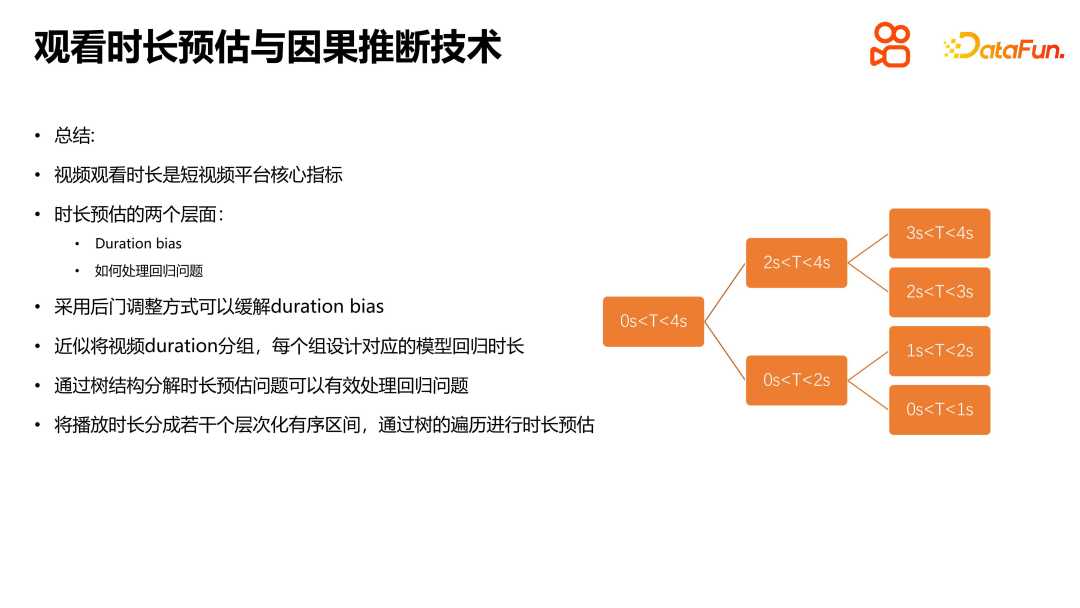
Résumons cette partie de l’introduction. Dans les plateformes de recommandation de vidéos courtes, la durée de visionnage est l’indicateur principal. Il y a deux niveaux à considérer pour résoudre ce problème : l'un est le problème de biais, y compris le biais de durée et le biais de popularité, qui doit être résolu dans l'auto-boucle de l'ensemble du journal de liaison du système à la formation, l'autre est le problème d'estimation de la durée ; , qui est lui-même un continu. Les problèmes de prédiction de valeur correspondent généralement à des problèmes de régression. Cependant, pour les problèmes particuliers de régression d’estimation de durée, des méthodes spécifiques doivent être utilisées. Tout d’abord, le problème de biais peut être atténué grâce à un ajustement détourné. La méthode spécifique consiste à regrouper la durée et à concevoir un modèle correspondant pour chaque groupe à des fins de régression. Deuxièmement, pour résoudre le problème de régression de l'estimation de la durée, une structure arborescente peut être utilisée pour décomposer l'estimation de la durée en plusieurs intervalles ordonnés hiérarchiquement. Grâce au processus de parcours de l'arbre, le problème peut être démonté le long du chemin allant du sommet aux nœuds feuilles. .et résoudre. Lors de l'estimation, la durée est estimée par traversée d'arbres. Cette méthode de traitement peut résoudre plus efficacement le problème de régression de l'estimation de la durée et améliorer la précision et la confiance des prévisions.
4. Perspectives d'avenir
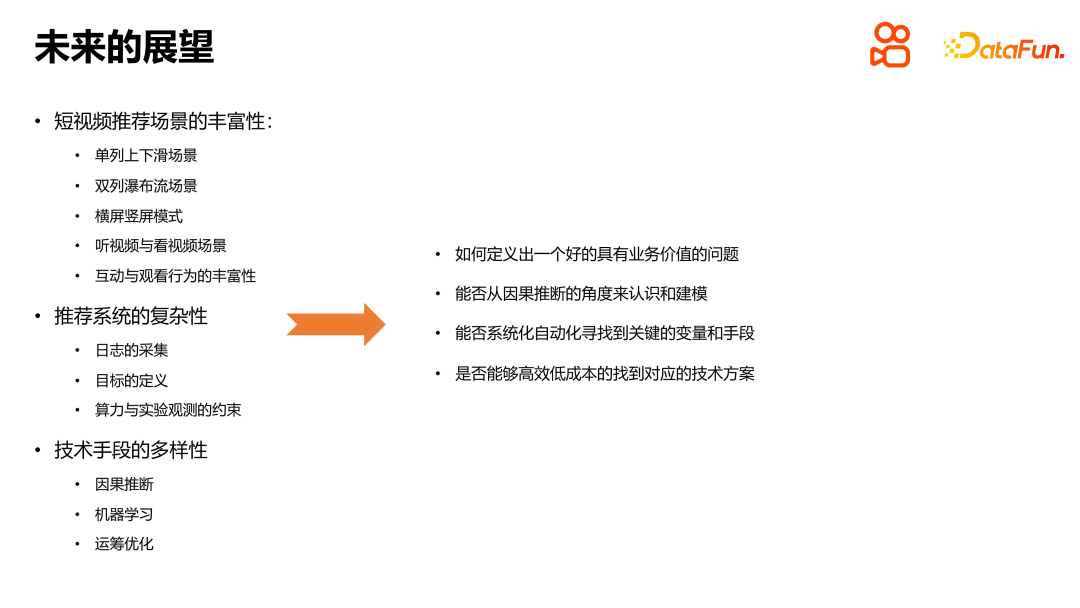
Avec l'accélération du développement technologique, le monde dans lequel nous vivons devient de plus en plus complexe. Dans le court scénario de recommandation vidéo de Kuaishou, la complexité du système de recommandation est devenue de plus en plus importante. Afin de formuler de meilleures recommandations, nous devons étudier en profondeur l’application de l’inférence causale dans les systèmes de recommandation. Tout d’abord, nous devons définir un problème lié à la valeur commerciale, tel que l’estimation de la durée de visionnage. Nous pouvons alors comprendre et modéliser ce problème dans une perspective d’inférence causale. Grâce à la méthode d'ajustement causal ou d'inférence causale, nous pouvons mieux analyser et résoudre les problèmes de biais, tels que le biais de durée et le biais de popularité. De plus, nous pouvons également utiliser des moyens techniques, tels que l'apprentissage automatique et l'optimisation des opérations, pour résoudre des problèmes tels que la complexité du système et la distribution des scènes. Afin de parvenir à des solutions efficaces, nous devons trouver un moyen systématique et automatisé de résoudre le problème. Cela améliore non seulement l’efficacité du travail, mais apporte également une valeur continue à l’entreprise. Enfin, nous devons nous concentrer sur l’évolutivité et la rentabilité de la technologie pour garantir la faisabilité et la durabilité de la solution.
En résumé, l'application de l'inférence causale dans les systèmes de recommandation est une direction de recherche difficile et potentielle. Grâce à une exploration et une pratique continues, nous pouvons continuellement améliorer l'efficacité du système de recommandation, offrir une meilleure expérience aux utilisateurs et créer une plus grande valeur pour l'entreprise.
Ce qui précède est le contenu partagé cette fois, merci à tous.
5. Session de questions-réponses
Q1 : Par rapport à D2Q, TPM a apporté quelques améliorations lors de la régression pour mieux utiliser les dépendances de durée. Je voudrais demander à quoi fait référence ici la relation de dépendance ?
A1 : Passer du nœud principal au nœud feuille peut être considéré comme un processus de prise de décision continu similaire au MDP. La dépendance conditionnelle signifie que la décision de la couche suivante est basée sur les résultats de la couche précédente. Par exemple, pour atteindre le nœud feuille, qui est l'intervalle [0,1], il faut d'abord passer par le nœud intermédiaire, qui est l'intervalle [0,2]. Cette dépendance est réalisée dans une estimation en ligne réelle par chaque classificateur qui détermine uniquement si un nœud spécifique doit passer au nœud feuille suivant. C'est comme dans l'exemple de la détermination de l'âge, on demande d'abord si l'âge est supérieur à 50 ans, puis, en fonction de la réponse, on demande s'il est supérieur à 25 ans. Il existe ici une dépendance conditionnelle implicite, c'est-à-dire qu'être âgé de moins de 50 ans est une condition préalable pour répondre à la deuxième question.
Q2 : L'utilisation du modèle d'arbre entraînera-t-elle des difficultés en termes de coût de formation du modèle et d'inférence en ligne ?
A2 : Dans la comparaison des avantages du TPM et du D2Q, le principal avantage réside dans le fractionnement des problèmes. TPM fait un meilleur usage des informations temporelles et divise le problème en plusieurs problèmes de classification binaire avec des échantillons relativement équilibrés, ce qui contribue à l'apprentissage de la formation et de l'apprentissage des modèles. En revanche, les problèmes de régression peuvent être affectés par des valeurs aberrantes et d’autres valeurs aberrantes, provoquant une plus grande instabilité d’apprentissage. Dans les applications pratiques, nous avons effectué de nombreux travaux pratiques, notamment la construction d'échantillons et le calcul d'étiquettes de nœuds de graphe TF. Lorsqu'il est déployé en ligne, nous utilisons un modèle, mais sa dimension de sortie est le nombre de classificateurs de nœuds intermédiaires. Pour chaque vidéo, nous sélectionnons un seul des groupes de durée et calculons la sortie du classificateur correspondant. Ensuite, la distribution sur les nœuds feuilles est calculée via une boucle, et enfin une somme pondérée est effectuée. Bien que la structure du modèle soit relativement simple, les classificateurs de chaque groupe de durée et de chaque nœud non-feuille peuvent partager les couches d'intégration et intermédiaires sous-jacentes, donc lors de l'inférence directe, à l'exception de la couche de sortie, ce n'est pas très différent du modèle ordinaire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment annuler la suppression de l'écran d'accueil sur iPhone
Apr 17, 2024 pm 07:37 PM
Comment annuler la suppression de l'écran d'accueil sur iPhone
Apr 17, 2024 pm 07:37 PM
Vous avez supprimé quelque chose d'important de votre écran d'accueil et vous essayez de le récupérer ? Vous pouvez remettre les icônes d’applications à l’écran de différentes manières. Nous avons discuté de toutes les méthodes que vous pouvez suivre et remettre l'icône de l'application sur l'écran d'accueil. Comment annuler la suppression de l'écran d'accueil sur iPhone Comme nous l'avons mentionné précédemment, il existe plusieurs façons de restaurer cette modification sur iPhone. Méthode 1 – Remplacer l'icône de l'application dans la bibliothèque d'applications Vous pouvez placer une icône d'application sur votre écran d'accueil directement à partir de la bibliothèque d'applications. Étape 1 – Faites glisser votre doigt sur le côté pour trouver toutes les applications de la bibliothèque d'applications. Étape 2 – Recherchez l'icône de l'application que vous avez supprimée précédemment. Étape 3 – Faites simplement glisser l'icône de l'application de la bibliothèque principale vers le bon emplacement sur l'écran d'accueil. Voici le schéma d'application
 Le rôle et l'application pratique des symboles fléchés en PHP
Mar 22, 2024 am 11:30 AM
Le rôle et l'application pratique des symboles fléchés en PHP
Mar 22, 2024 am 11:30 AM
Le rôle et l'application pratique des symboles fléchés en PHP En PHP, le symbole fléché (->) est généralement utilisé pour accéder aux propriétés et méthodes des objets. Les objets sont l'un des concepts de base de la programmation orientée objet (POO) en PHP. Dans le développement actuel, les symboles fléchés jouent un rôle important dans le fonctionnement des objets. Cet article présentera le rôle et l'application pratique des symboles fléchés et fournira des exemples de code spécifiques pour aider les lecteurs à mieux comprendre. 1. Le rôle du symbole flèche pour accéder aux propriétés d'un objet. Le symbole flèche peut être utilisé pour accéder aux propriétés d'un objet. Quand on instancie une paire
 Du débutant au compétent : explorez différents scénarios d'application de la commande Linux tee
Mar 20, 2024 am 10:00 AM
Du débutant au compétent : explorez différents scénarios d'application de la commande Linux tee
Mar 20, 2024 am 10:00 AM
La commande Linuxtee est un outil de ligne de commande très utile qui peut écrire la sortie dans un fichier ou envoyer la sortie à une autre commande sans affecter la sortie existante. Dans cet article, nous explorerons en profondeur les différents scénarios d'application de la commande Linuxtee, du débutant au compétent. 1. Utilisation de base Tout d'abord, jetons un coup d'œil à l'utilisation de base de la commande tee. La syntaxe de la commande tee est la suivante : tee[OPTION]...[FILE]...Cette commande lira les données de l'entrée standard et enregistrera les données dans
 Découvrez les avantages et les scénarios d'application du langage Go
Mar 27, 2024 pm 03:48 PM
Découvrez les avantages et les scénarios d'application du langage Go
Mar 27, 2024 pm 03:48 PM
Le langage Go est un langage de programmation open source développé par Google et lancé pour la première fois en 2007. Il est conçu pour être un langage simple, facile à apprendre, efficace et hautement simultané, et est favorisé par de plus en plus de développeurs. Cet article explorera les avantages du langage Go, présentera quelques scénarios d'application adaptés au langage Go et donnera des exemples de code spécifiques. Avantages : Forte concurrence : le langage Go prend en charge de manière intégrée les threads-goroutine légers, qui peuvent facilement implémenter une programmation simultanée. Goroutin peut être démarré en utilisant le mot-clé go
 La large application de Linux dans le domaine du cloud computing
Mar 20, 2024 pm 04:51 PM
La large application de Linux dans le domaine du cloud computing
Mar 20, 2024 pm 04:51 PM
La large application de Linux dans le domaine du cloud computing Avec le développement et la vulgarisation continus de la technologie du cloud computing, Linux, en tant que système d'exploitation open source, joue un rôle important dans le domaine du cloud computing. En raison de leur stabilité, de leur sécurité et de leur flexibilité, les systèmes Linux sont largement utilisés dans diverses plates-formes et services de cloud computing, fournissant une base solide pour le développement de la technologie du cloud computing. Cet article présentera le large éventail d'applications de Linux dans le domaine du cloud computing et donnera des exemples de code spécifiques. 1. Technologie de virtualisation d'applications de Linux dans la plate-forme de cloud computing Technologie de virtualisation
 Comprendre les horodatages MySQL : fonctions, fonctionnalités et scénarios d'application
Mar 15, 2024 pm 04:36 PM
Comprendre les horodatages MySQL : fonctions, fonctionnalités et scénarios d'application
Mar 15, 2024 pm 04:36 PM
L'horodatage MySQL est un type de données très important, qui peut stocker la date, l'heure ou la date plus l'heure. Dans le processus de développement actuel, l'utilisation rationnelle des horodatages peut améliorer l'efficacité des opérations de base de données et faciliter les requêtes et les calculs liés au temps. Cet article abordera les fonctions, les fonctionnalités et les scénarios d'application des horodatages MySQL, et les expliquera avec des exemples de code spécifiques. 1. Fonctions et caractéristiques des horodatages MySQL Il existe deux types d'horodatages dans MySQL, l'un est TIMESTAMP
 Tutoriel Apple sur la façon de fermer les applications en cours d'exécution
Mar 22, 2024 pm 10:00 PM
Tutoriel Apple sur la façon de fermer les applications en cours d'exécution
Mar 22, 2024 pm 10:00 PM
1. Nous cliquons d’abord sur le petit point blanc. 2. Cliquez sur l'appareil. 3. Cliquez sur Plus. 4. Cliquez sur Sélecteur d'applications. 5. Fermez l'arrière-plan de l'application.
 Systèmes de recommandation basés sur l'inférence causale : bilan et perspectives
Apr 12, 2024 am 09:01 AM
Systèmes de recommandation basés sur l'inférence causale : bilan et perspectives
Apr 12, 2024 am 09:01 AM
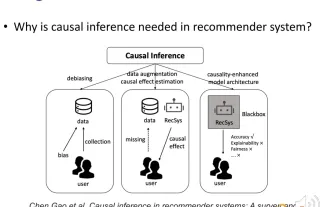
Le thème de ce partage concerne les systèmes de recommandation basés sur l'inférence causale. Nous passons en revue les travaux antérieurs connexes et proposons des perspectives futures dans cette direction. Pourquoi devons-nous utiliser des techniques d'inférence causale dans les systèmes de recommandation ? Les travaux de recherche existants utilisent l'inférence causale pour résoudre trois types de problèmes (voir l'article TOIS2023 de Gaoe et al. Causal Inference in Recommender Systems: ASurvey and Future Directions) : Premièrement, il existe divers biais (BIAS) dans les systèmes de recommandation et l'inférence causale. est un moyen efficace de supprimer ces outils de partialité. Les systèmes de recommandation peuvent être confrontés à des difficultés pour remédier à la rareté des données et à l’incapacité d’estimer avec précision les effets causals. pour résoudre
