
 Périphériques technologiques
IA
Améliorant considérablement les performances de GPT-4/Llama2 sans RLHF, l'équipe de l'Université de Pékin propose un nouveau paradigme d'alignement des aligneurs
Périphériques technologiques
IA
Améliorant considérablement les performances de GPT-4/Llama2 sans RLHF, l'équipe de l'Université de Pékin propose un nouveau paradigme d'alignement des aligneurs
Améliorant considérablement les performances de GPT-4/Llama2 sans RLHF, l'équipe de l'Université de Pékin propose un nouveau paradigme d'alignement des aligneurs

Contexte
Bien que les grands modèles de langage (LLM) aient démontré de puissantes capacités, ils peuvent également produire des résultats imprévisibles et nuisibles, tels que des réponses offensantes, de fausses informations et des fuites de données privées, causant du tort aux utilisateurs et à la société. . Garantir que le comportement de ces modèles s'aligne sur les intentions et les valeurs humaines est un défi urgent.
Bien que l'apprentissage par renforcement basé sur le feedback humain (RLHF) fournisse une solution, il est confronté à une architecture de formation complexe, à une sensibilité élevée aux paramètres et à l'instabilité du modèle de récompense sur différents ensembles de données. Ces facteurs rendent la technologie RLHF difficile à mettre en œuvre, efficace et reproductible. Afin de surmonter ces défis, l'équipe de l'Université de Pékin a proposé un nouveau paradigme d'alignement efficace -
Aligner, dont le cœur réside dans l'apprentissage du résidu modifié entre l'alignement et le désalignement des réponses, contournant ainsi la lourdeur Processus RLHF. S'appuyant sur les idées d'apprentissage résiduel et de supervision évolutive, Aligner simplifie le processus d'alignement. Il utilise un modèle Seq2Seq pour apprendre les résidus implicites et optimiser l'alignement grâce à des étapes de réplication et de correction des résidus.
Par rapport à la complexité du RLHF, qui nécessite la formation de plusieurs modèles, l'avantage d'Aligner est que l'alignement peut être réalisé simplement en ajoutant un module après le modèle à aligner. De plus, les ressources informatiques requises dépendent principalement de l’effet d’alignement souhaité plutôt que de la taille du modèle en amont. Des expériences ont prouvé que l'utilisation d'Aligner-7B peut améliorer considérablement l'utilité et la sécurité de GPT-4, l'utilité augmentant de 17,5 % et la sécurité augmentant de 26,9 %. Ces résultats montrent qu'Aligner est une méthode d'alignement efficace et efficiente, fournissant une solution réalisable pour l'amélioration des performances du modèle.De plus, en utilisant le framework Aligner, l'auteur améliore les performances du modèle fort (Llama-70B) grâce au signal de supervision du modèle faible (Aligner-13B), réalisant une généralisation
faible à forte et fournissant une solution pratique pour un super alignement.
Adresse papier : https://arxiv.org/abs/2402.02416
- Page d'accueil du projet et adresse open source : https://aligner2024.github.io
- Titre : Aligner : Réaliser un alignement efficace grâce à une correction FAIBLE-Forte
- Qu'est-ce que GNED Answers ? Il est plus facile de corriger des réponses mal alignées que de générer des réponses alignées.
En tant que méthode d'alignement efficace, Aligner possède les excellentes fonctionnalités suivantes :

En tant que modèle Seq2Seq autorégressif, Aligner fonctionne sur les données de requête-réponse-correction (Q-A-C). Entraînez-vous sur l'ensemble pour apprendre la différence entre les données alignées. et des réponses non alignées, obtenant ainsi un alignement plus précis du modèle. Par exemple, lors de l'alignement du 70B LLM, Aligner-7B réduit considérablement la quantité de paramètres d'entraînement, qui est 16,67 fois plus petite que DPO et 30,7 fois plus petite que RLHF.
Le paradigme Aligner réalise une généralisation de faible à fort et utilise des modèles Aligner avec des quantités de paramètres élevées et petites pour superviser les signaux afin d'affiner les LLM avec de grandes quantités de paramètres, améliorant considérablement les performances des modèles forts. Par exemple, le réglage fin de Llama2-70B sous la supervision de l'Aligner-13B a amélioré son utilité et sa sécurité de 8,2 % et 61,6 %, respectivement.
En raison de la nature plug-and-play d'Aligner et de son insensibilité aux paramètres du modèle, il peut aligner des modèles tels que GPT3.5, GPT4 et Claude2 qui ne peuvent pas obtenir de paramètres. Avec une seule session de formation, Aligner-7B aligne et améliore l'utilité et la sécurité de 11 modèles, y compris les modèles alignés fermés, open source et sécurisés/non sécurisés. Parmi eux, Aligner-7B améliore considérablement l’utilité et la sécurité de GPT-4 de 17,5 % et 26,9 % respectivement.
Performances globales de l'Aligner
- L'auteur montre que des aligneurs de différentes tailles (7B, 13B, 70B) peuvent être utilisés dans des modèles basés sur API et des modèles open source (y compris l'alignement sûr et l'alignement non sécurisé ) Améliorer les performances. En général, à mesure que le modèle s'agrandit, les performances d'Aligner s'améliorent progressivement et la densité des informations qu'il peut fournir lors de la correction augmente progressivement, ce qui rend également la réponse corrigée plus sûre et plus utile.
-

Comment entraîner un modèle Aligner ?
1. Collecte de données Requête-Réponse (Q-A)
L'auteur obtient des requêtes à partir de divers ensembles de données open source, notamment Stanford Alpaca, ShareGPT, HH-RLHF et d'autres conversations partagées par les utilisateurs. Ces questions subissent un processus de suppression des modèles en double et de filtrage de qualité pour la génération de réponses ultérieures et de réponses corrigées. Des réponses non corrigées ont été générées à l'aide de divers modèles open source tels que Alpaca-7B, Vicuna-(7B,13B,33B), Llama2-(7B,13B)-Chat et Alpaca2-(7B,13B).
2. Correction de réponse
L'auteur utilise GPT-4, Llama2-70B-Chat et l'annotation manuelle pour corriger les données Q-A selon les critères 3H des grands modèles de langage (utilité, sécurité, honnêteté) Des réponses concentrées.
Pour les réponses qui répondent déjà aux critères, laissez-les telles quelles. Le processus de modification est basé sur un ensemble de principes bien définis qui établissent des contraintes pour la formation des modèles Seq2Seq, en mettant l'accent sur la création de réponses plus utiles et plus sûres. La distribution des réponses a considérablement changé avant et après la correction. La figure suivante montre clairement l'impact de la modification sur l'ensemble de données :
3. Formation du modèle
Sur la base du processus ci-dessus, l'auteur a construit un nouvel ensemble de données corrigées
, où représente la question de l'utilisateur, est la réponse originale à la question et est la réponse corrigée basée sur des principes établis. Le processus de formation du modèle est relativement simple. Les auteurs entraînent un modèle Seq2Seq conditionnel
paramétré par , tel que les réponses originales soient redistribuées aux réponses alignées. Le processus de génération de réponse d'alignement basé sur le grand modèle de langage en amont est :
La perte d'entraînement est la suivante :
Le deuxième élément n'a rien à voir avec les paramètres de l'Aligner , et les objectifs de formation de l'Aligner peuvent être dérivés pour :
La figure suivante montre dynamiquement le processus intermédiaire de l'Aligner :
Il est à noter que l'Aligner n'a pas besoin d'accéder aux paramètres de le modèle en amont pendant les phases de formation et d’inférence. Le processus de raisonnement d'Aligner n'a besoin que d'obtenir les questions de l'utilisateur et les réponses initiales générées par le grand modèle de langage en amont, puis de générer des réponses plus cohérentes avec les valeurs humaines.
Corriger les réponses existantes plutôt que de répondre directement permet à Aligner de s'aligner facilement sur les valeurs humaines, réduisant considérablement les exigences en matière de capacités du modèle.
Aligner comparé aux paradigmes d'alignement existants
Aligner vs SFT
Contrairement à Aligner, SFT crée directement un mappage inter-domaines de l'espace sémantique de requête à l'espace sémantique de réponse. Ce processus d'apprentissage dépend. sur les modèles en amont pour déduire et simuler divers contextes dans l'espace sémantique est beaucoup plus difficile que d'apprendre à corriger les signaux.
Le paradigme d'entraînement Aligner peut être considéré comme une forme d'apprentissage résiduel (correction résiduelle). L'auteur a créé un paradigme d'apprentissage "copier + corriger" dans Aligner. Ainsi, Aligner crée essentiellement un mappage résiduel de l'espace sémantique de réponse à l'espace sémantique de réponse révisé, où les deux espaces sémantiques sont plus proches sur le plan de la distribution.
À cette fin, l'auteur a construit des données Q-A-A dans différentes proportions à partir de l'ensemble de données de formation Q-A-C, et a formé Aligner à effectuer un apprentissage de cartographie d'identité (également appelé cartographie de copie) (appelé l'étape échauffement). Sur cette base, l'ensemble des données de formation QAC est utilisé pour la formation. Ce paradigme d'apprentissage résiduel est également utilisé dans ResNet pour résoudre le problème de la disparition du gradient causée par l'empilement trop profond d'un réseau neuronal. Les résultats expérimentaux montrent que le modèle peut atteindre les meilleures performances lorsque le taux de préchauffage est de 20 %.
Aligner vs RLHF
RLHF entraîne un modèle de récompense (RM) sur l'ensemble de données de préférences humaines et utilise ce modèle de récompense pour affiner les LLM de l'algorithme PPO afin de rendre les LLM cohérents avec le comportement des préférences humaines.
Plus précisément, le modèle de récompense doit mapper les données de préférences humaines d'un espace numérique discret à un espace numérique continu pour l'optimisation, mais comparé au modèle Seq2Seq avec une forte capacité de généralisation dans l'espace texte, ce type de modèle de récompense numérique a la capacité de généralisation du texte l'espace est faible, ce qui conduit à l'effet instable du RLHF sur différents modèles.
Aligner apprend la différence (résiduelle) entre les réponses alignées et non alignées en entraînant un modèle Seq2Seq, évitant ainsi efficacement le processus RLHF et obtenant de meilleures performances de généralisation que RLHF.
Aligner vs. Prompt Engineering
Prompt Engineering est une méthode courante pour stimuler les capacités des LLM. Cependant, cette méthode présente certains problèmes clés, tels que : il est difficile de concevoir des invites et elle en a besoin. être ciblé sur différents Le modèle est conçu différemment et l'effet final dépend de la capacité du modèle. Lorsque la capacité du modèle n'est pas suffisante pour résoudre la tâche, plusieurs itérations peuvent être nécessaires, ce qui gaspille la fenêtre contextuelle limitée de. le petit modèle affectera l'effet du projet de mot d'invite, et pour les grands modèles, prendre trop de temps dans un contexte augmente considérablement le coût de la formation.
Aligner lui-même peut prendre en charge l'alignement de n'importe quel modèle. Après une formation, il peut aligner 11 types de modèles différents sans occuper la fenêtre contextuelle du modèle d'origine. Il convient de noter qu'Aligner peut être combiné de manière transparente avec les méthodes d'ingénierie de mots rapides existantes pour obtenir un effet 1+1>2.
En général : Aligner présente les avantages significatifs suivants :
1. Par rapport au processus de réglage fin du modèle de récompense complexe d'apprentissage et d'apprentissage par renforcement (RL) de RLHF basé sur ce modèle, le processus de mise en œuvre d'Aligner est plus direct et plus facile à utiliser. En repensant aux multiples détails d’ajustement des paramètres d’ingénierie impliqués dans RLHF ainsi qu’à l’instabilité inhérente et à la sensibilité des hyperparamètres de l’algorithme RL, Aligner simplifie considérablement la complexité de l’ingénierie.
2.Aligner a moins de données d'entraînement et un effet d'alignement évident. La formation d'un modèle Aligner-7B basé sur des données 20K peut améliorer l'utilité de GPT-4 de 12 % et la sécurité de 26 %, et améliorer l'utilité du modèle Vicuna 33B de 29 % et la sécurité de 45,3 %. ajustements raffinés des paramètres pour obtenir cet effet.
3.L'aligneur n'a pas besoin de toucher les poids du modèle. Bien que le RLHF se soit avéré efficace dans l'alignement du modèle, il repose sur un entraînement direct du modèle. L'applicabilité de RLHF est limitée face aux modèles basés sur des API non open source tels que GPT-4 et à leurs exigences de réglage fin dans les tâches en aval. En revanche, Aligner ne nécessite pas de manipulation directe des paramètres d'origine du modèle et permet un alignement flexible en externalisant les exigences d'alignement dans un module d'alignement indépendant.
4.L'alignement est indifférent aux types de modèles. Dans le cadre RLHF, le réglage fin de différents modèles (tels que Llama2, Alpaca) nécessite non seulement de collecter à nouveau les données de préférence, mais nécessite également d'ajuster les paramètres d'entraînement dans les étapes d'entraînement du modèle de récompense et RL. Aligner peut prendre en charge l’alignement de n’importe quel modèle grâce à une formation unique. Par exemple, en s'entraînant une seule fois sur un ensemble de données rectifiés, Aligner-7B peut aligner 11 modèles différents (y compris des modèles open source, des modèles API tels que GPT) et améliorer les performances de 21,9 % et 23,8 % respectivement en termes d'utilité et de sécurité.
5.La demande d’Aligner en ressources de formation est plus flexible. RLHF La mise au point d'un modèle 70B reste très exigeante en ressources informatiques, nécessitant des centaines de cartes GPU pour fonctionner. Parce que la méthode RLHF nécessite également un chargement supplémentaire de modèles de récompense, de modèles d'acteurs et de modèles critiques équivalents au nombre de paramètres du modèle. Par conséquent, en termes de consommation de ressources de formation par unité de temps, le RLHF nécessite en réalité plus de ressources informatiques que la pré-formation.
En comparaison, Aligner propose une stratégie de formation plus flexible, permettant aux utilisateurs de choisir de manière flexible l'échelle de formation d'Aligner en fonction de leurs ressources informatiques réelles. Par exemple, pour les exigences d'alignement d'un modèle 70B, les utilisateurs peuvent choisir des modèles d'alignement de différentes tailles (7B, 13B, 70B, etc.) en fonction des ressources réellement disponibles pour obtenir un alignement efficace du modèle cible.
Cette flexibilité réduit non seulement la demande absolue en ressources informatiques, mais offre également aux utilisateurs la possibilité d'un alignement efficace avec des ressources limitées.
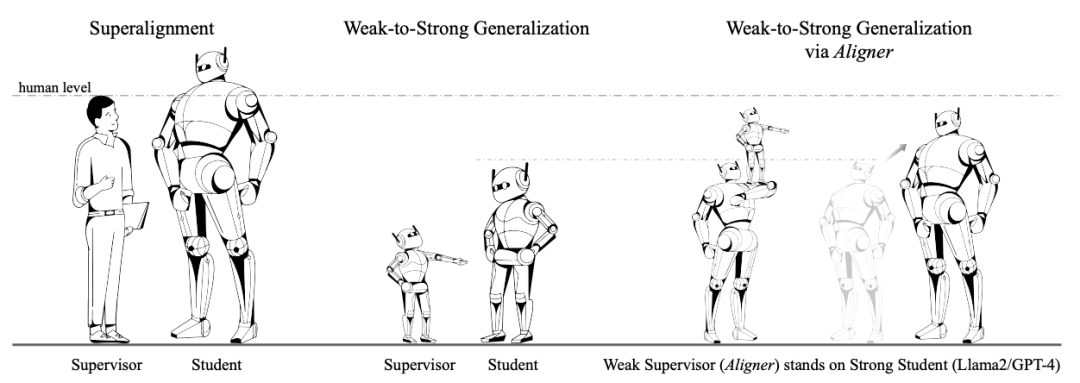
Généralisation de faible à fort
Généralisation de faible à fort La question discutée est de savoir si les étiquettes du modèle faible peuvent être utilisées pour entraîner le modèle fort, de sorte que le un modèle fort peut améliorer ses performances. OpenAI utilise cette analogie pour résoudre le problème du SuperAlignment. Plus précisément, ils utilisent des étiquettes de vérité terrain pour former des modèles faibles.
Les chercheurs d'OpenAI ont mené des expériences préliminaires. Par exemple, sur la tâche de classification de texte, l'ensemble de données de formation a été divisé en deux parties. Les étiquettes d'entrée et de vérité terrain de la première moitié ont été utilisées pour former des modèles faibles. la moitié des données d'entraînement ne conserve que l'entrée et les étiquettes sont générées par le modèle faible. Seules les étiquettes faibles produites par le modèle faible sont utilisées pour fournir des signaux de supervision pour le modèle fort lors de la formation du modèle fort.
Le but de la formation d'un modèle faible à l'aide de véritables étiquettes de valeur est de permettre au modèle faible d'acquérir la capacité de résoudre la tâche correspondante, mais l'entrée utilisée pour générer des étiquettes faibles et l'entrée utilisée pour entraîner le modèle faible ne le sont pas. le même. Ce paradigme s'apparente au concept d'« enseignement », c'est-à-dire l'utilisation de modèles faibles pour guider des modèles forts.
L'auteur propose un nouveau paradigme de généralisation faible à fort basé sur les propriétés d'Aligner.
L’objectif principal de l’auteur est de laisser Aligner agir comme un « superviseur debout sur les épaules de géants ». Contrairement à la méthode d'OpenAI consistant à superviser directement le « géant », Aligner modifiera les modèles plus forts via des corrections faibles à fortes pour fournir des étiquettes plus précises dans le processus.
Plus précisément, pendant le processus de formation d'Aligner, les données corrigées contiennent GPT-4, des annotateurs humains et des annotations de modèle plus grandes. Par la suite, l'auteur utilise Aligner pour générer des étiquettes faibles (c'est-à-dire des corrections) sur le nouvel ensemble de données Q-A, puis utilise les étiquettes faibles pour affiner le modèle d'origine ;
Les résultats expérimentaux montrent que ce paradigme peut encore améliorer les performances d'alignement du modèle.
Résultats expérimentaux
Aligner vs SFT/RLHF/DPO
L'auteur a utilisé l'ensemble de données d'entraînement Query-Answer-Correction d'Aligner pour affiner Alpaca-7B via la méthode SFT/RLHF/DPO respectivement.
Lors de l'évaluation des performances, utilisez l'ensemble de données d'invite de test de BeaverTails et HarmfulQA open source, et comparez les réponses générées par le modèle affiné avec les réponses générées par le modèle Alpaca-7B original en utilisant Aligner pour corriger les réponses.
Les résultats expérimentaux montrent qu'Aligner présente des avantages évidents par rapport aux paradigmes d'alignement LLM matures tels que SFT/RLHF/DPO, en termes d'utilité et de comparaison en termes de sécurité. la serviabilité et la sécurité sont nettement en avance.
En analysant des cas expérimentaux spécifiques, on peut constater que le modèle d'alignement affiné à l'aide du paradigme RLHF/DPO est peut-être plus susceptible de produire des réponses conservatrices afin d'améliorer la sécurité, mais dans le processus d'amélioration de l'utilité, la sécurité ne peut pas être prise en compte. en compte, ce qui entraîne des réponses. Les informations dangereuses augmentent.
Aligner vs Prompt Engineering
Comparez l'amélioration des performances des méthodes Aligner-13B et CAI / Self-Critique sur le même modèle en amont. Les résultats expérimentaux sont présentés dans la figure ci-dessous : Aligner-13B est utile. à GPT-4 L'amélioration de la sûreté et de la sécurité est supérieure à celle de la méthode CAI/Auto-Critique, ce qui montre que le paradigme Aligner présente des avantages évidents par rapport à la méthode d'ingénierie rapide couramment utilisée.
Il convient de noter que les invites CAI ne sont utilisées que pendant le raisonnement de l'expérience pour les encourager à auto-modifier leurs réponses, ce qui est également l'une des formes d'auto-raffinement.
De plus, l'auteur a également mené une exploration plus approfondie. Ils ont corrigé les réponses en utilisant la méthode CAI via Aligner et ont comparé directement les réponses avant et après Aligner. Les résultats expérimentaux sont présentés dans la figure ci-dessous. .
Méthode A : CAI + Aligner Méthode B : CAI uniquement
Après avoir utilisé Aligner pour corriger deux fois la réponse corrigée CAI, la réponse est plus utile sans perdre en sécurité. Une amélioration très significative a été obtenue. Cela montre qu'Aligner est non seulement très compétitif lorsqu'il est utilisé seul, mais qu'il peut également être combiné avec d'autres méthodes d'alignement existantes pour améliorer encore ses performances.
Généralisation de faible à fort
Méthode : faible à fort L'ensemble de données d'entraînement se compose de (q, a, a′) triples, où q représente les données d'entraînement d'Aligner Ensemble - 50 000 questions, a représente la réponse générée par le modèle Alpaca-7B et a′ représente la réponse alignée (q, a) donnée par Aligner-7B. Contrairement à SFT, qui utilise uniquement a′ comme étiquette de vérité terrain, dans les formations RLHF et DPO, a′ est considéré comme meilleur que a.
L'auteur a utilisé Aligner pour corriger la réponse originale sur le nouvel ensemble de données Q-A, a utilisé la réponse corrigée comme étiquette faible et a utilisé ces étiquettes faibles comme signaux de supervision pour former un modèle plus grand. Ce processus est similaire au paradigme de formation d’OpenAI.
L'auteur forme des modèles forts basés sur des étiquettes faibles à travers trois méthodes : SFT, RLHF et DPO. Les résultats expérimentaux du tableau ci-dessus montrent que lorsque le modèle en amont est affiné via SFT, les étiquettes faibles d'Aligner-7B et d'Aligner-13B améliorent les performances de la série Llama2 de modèles forts dans tous les scénarios.
Perspectives : Orientations de recherche potentielles d'Aligner
Aligner, en tant que méthode d'alignement innovante, présente un énorme potentiel de recherche. Dans l'article, l'auteur a proposé plusieurs scénarios d'application d'Aligner, notamment :
1 Application de scénarios de dialogue multi-tours. Dans les conversations à plusieurs tours, le défi de faire face à des récompenses rares est particulièrement important. Dans les conversations questions-réponses (QA), les signaux de supervision sous forme scalaire ne sont généralement disponibles qu'à la fin de la conversation.
Ce problème de rareté sera encore amplifié au cours de plusieurs cycles de dialogue (tels que des scénarios d'assurance qualité continue), ce qui rendra difficile l'efficacité du feedback humain basé sur l'apprentissage par renforcement (RLHF). L’étude du potentiel d’Aligner à améliorer l’alignement du dialogue sur plusieurs tours est un domaine qui mérite une exploration plus approfondie.
2.Alignement de la valeur humaine sur le modèle de récompense. Dans le processus en plusieurs étapes consistant à créer des modèles de récompense basés sur les préférences humaines et à affiner les grands modèles de langage (LLM), il existe d'énormes défis pour garantir que les LLM sont alignés sur des valeurs humaines spécifiques (par exemple, l'équité, l'empathie, etc.).
En confiant la tâche d'alignement des valeurs au module d'alignement Aligner en dehors du modèle et en utilisant un corpus spécifique pour former Aligner, il fournit non seulement de nouvelles idées pour l'alignement des valeurs, mais permet également à Aligner de modifier la sortie du front- modèle final pour refléter des valeurs spécifiques.
3. Streaming et traitement parallèle de MoE-Aligner. En spécialisant et en intégrant les aligneurs, vous pouvez créer un aligneur hybride expert (MoE) plus puissant et complet qui peut répondre à plusieurs besoins hybrides de sécurité et d'alignement de valeur. Dans le même temps, améliorer davantage les capacités de traitement parallèle d’Aligner afin de réduire la perte de temps d’inférence est une direction de développement réalisable.
4. Fusion lors de l'entraînement du modèle. En intégrant la couche Aligner après une couche de poids spécifique, une intervention en temps réel sur la sortie pendant l'entraînement du modèle peut être obtenue. Cette méthode améliore non seulement l'efficacité de l'alignement, mais contribue également à optimiser le processus de formation du modèle et à obtenir un alignement plus efficace du modèle.
Présentation de l'équipe
Ce travail a été réalisé de manière indépendante par l'équipe de recherche de Yang Yaodong au Centre de sécurité et de gouvernance de l'IA de l'Institut d'intelligence artificielle de l'Université de Pékin. L'équipe est profondément impliquée dans la technologie d'alignement des grands modèles de langage, y compris l'ensemble de données open source de préférences d'alignement sécurisé au niveau d'un million BeaverTails (NeurIPS 2023) et l'algorithme d'alignement sécurisé SafeRLHF (ICLR 2024 Spotlight) pour les grands modèles de langage. été adopté par plusieurs modèles open source. A rédigé la première étude complète du secteur sur l'alignement de l'intelligence artificielle et l'a associé au site Web de ressources www.alignmentsurvey.com (cliquez sur le texte original pour accéder directement), exposant systématiquement les quatre perspectives : apprendre à partir des commentaires, apprendre sous changement de distribution, assurance. , et problème d’alignement de l’IA ci-dessous. Les points de vue de l’équipe sur l’alignement et le super-alignement ont été présentés sur la couverture du numéro 5 de 2024 de Sanlian Life Weekly.


 représente la question de l'utilisateur,
représente la question de l'utilisateur, 



 soient redistribuées aux réponses alignées.
soient redistribuées aux réponses alignées. 







Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
