
 Périphériques technologiques
IA
Tongyi Qianwen est à nouveau open source, Qwen1.5 propose six modèles de volume et ses performances dépassent GPT3.5
Périphériques technologiques
IA
Tongyi Qianwen est à nouveau open source, Qwen1.5 propose six modèles de volume et ses performances dépassent GPT3.5
Tongyi Qianwen est à nouveau open source, Qwen1.5 propose six modèles de volume et ses performances dépassent GPT3.5

Avant la Fête du Printemps, la version 1.5 de Tongyi Qianwen Large Model (Qwen) est en ligne. Ce matin, la nouvelle de la nouvelle version a suscité l'inquiétude de la communauté IA.
La nouvelle version du grand modèle comprend six tailles de modèle : 0,5B, 1,8B, 4B, 7B, 14B et 72B. Parmi eux, les performances de la version la plus puissante surpassent GPT 3.5 et Mistral-Medium. Cette version inclut le modèle de base et le modèle Chat et fournit une prise en charge multilingue.
L'équipe d'Alibaba Tongyi Qianwen a déclaré que la technologie correspondante a également été lancée sur le site officiel de Tongyi Qianwen et sur l'application Tongyi Qianwen.
De plus, la version actuelle de Qwen 1.5 présente également les points forts suivants :
- prend en charge une longueur de contexte de 32 Ko
- ouvre le point de contrôle du modèle Base + Chat
- peut être utilisé avec ; Transformers fonctionne localement ;
- Les poids GPTQ Int-4/Int8, AWQ et GGUF sont publiés simultanément.
En utilisant des modèles à grande échelle plus avancés comme juges, l'équipe Tongyi Qianwen a mené une évaluation préliminaire de Qwen1.5 sur deux benchmarks largement utilisés, MT-Bench et Alpaca-Eval. Les résultats de l'évaluation sont les suivants :
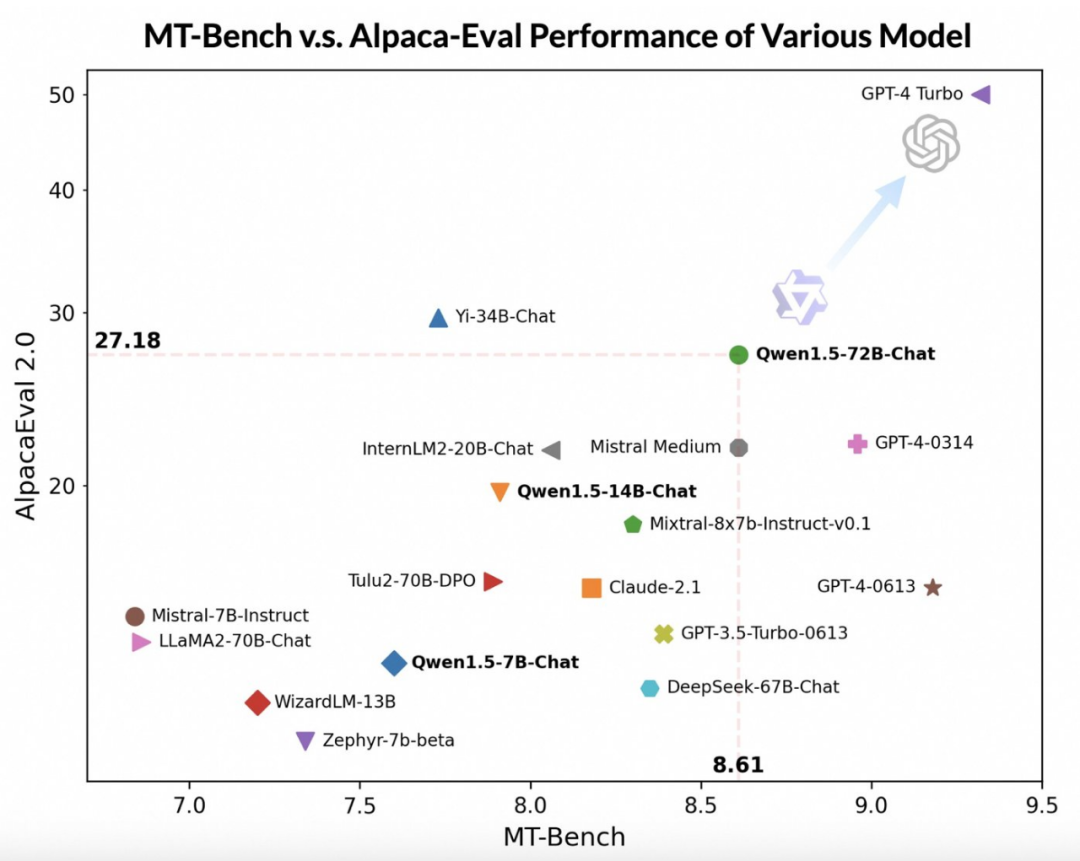
Bien que le modèle Qwen1.5-72B-Chat soit en retard sur GPT-4-Turbo, lors des tests sur MT-Bench et Alpaca-Eval v2, il a montré des performances impressionnantes Eye- attraper des performances. En fait, Qwen1.5-72B-Chat surpasse Claude-2.1, GPT-3.5-Turbo-0613, Mixtral-8x7b-instruct et TULU 2 DPO 70B en termes de performances, et est comparable au modèle Mistral Medium qui a récemment attiré beaucoup d'attention. .Comparable. Cela montre que le modèle Qwen1.5-72B-Chat possède une force considérable dans le traitement du langage naturel.
L'équipe de Tongyi Qianwen a souligné que même si les scores des grands modèles peuvent être liés à la longueur des réponses, les observations humaines montrent que Qwen1.5 n'affecte pas les scores en produisant des réponses excessivement longues. Selon les données d'AlpacaEval 2.0, la longueur moyenne de Qwen1.5-Chat est de 1618, ce qui est la même longueur que GPT-4 et plus courte que GPT-4-Turbo.
Les développeurs de Tongyi Qianwen ont déclaré qu'au cours des derniers mois, ils ont travaillé dur pour construire un excellent modèle et améliorer continuellement l'expérience des développeurs.

Par rapport aux versions précédentes, cette mise à jour se concentre sur l'amélioration de l'alignement du modèle Chat avec les préférences humaines et améliore considérablement les capacités de traitement multilingue du modèle. En termes de longueur de séquence, tous les modèles réduits ont implémenté une prise en charge de la plage de longueur de contexte de 32 768 jetons. Dans le même temps, la qualité du modèle de base pré-entraîné a également été considérablement optimisée, ce qui devrait offrir aux utilisateurs une meilleure expérience pendant le processus de réglage fin.
Capacités de base
Concernant l'évaluation des capacités de base du modèle, l'équipe Tongyi Qianwen a réalisé Qwen1.5 sur des ensembles de données de référence tels que MMLU (5-shot), C-Eval, Humaneval, GS8K et BBH. . Évaluer.
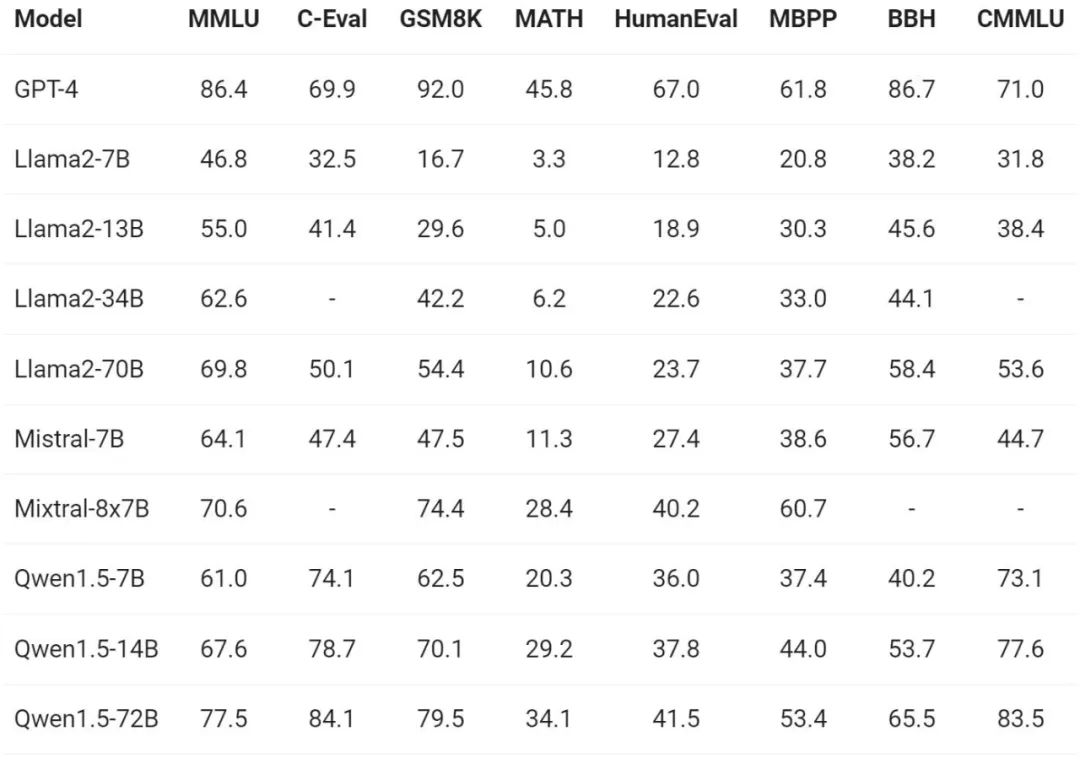
Sous différentes tailles de modèle, Qwen1.5 a montré de solides performances dans les tests d'évaluation. La version 72B a surpassé Llama2-70B dans tous les tests de référence, démontrant ses performances en matière de compréhension et de raisonnement du langage et de capacités mathématiques.
Ces derniers temps, la construction de petits modèles a été l'un des points chauds de l'industrie. L'équipe de Tongyi Qianwen a comparé le modèle Qwen1.5 avec des paramètres de modèle inférieurs à 7 milliards avec des petits modèles importants de la communauté :
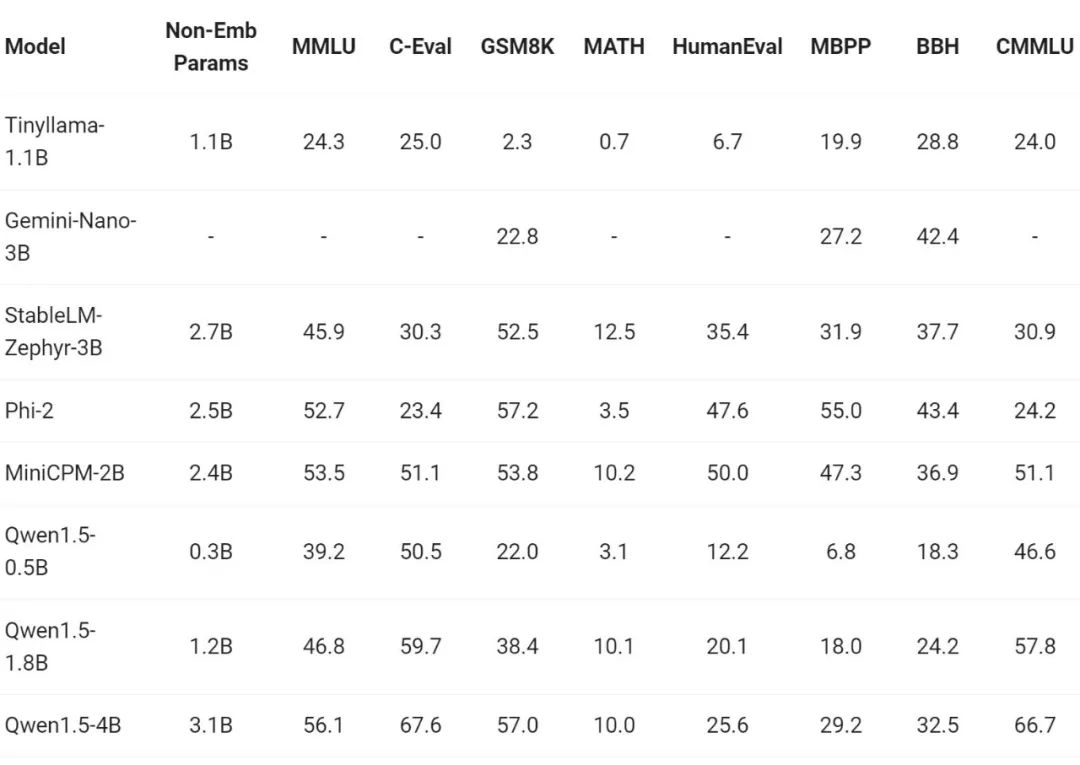
Qwen1.5 est très compétitif avec les petits modèles leaders de l'industrie dans la plage de taille de paramètres inférieure à 7 milliards.
Capacités multilingues
L'équipe Tongyi Qianwen a évalué les capacités multilingues du modèle de base sur 12 langues différentes d'Europe, d'Asie de l'Est et d'Asie du Sud-Est. À partir de l'ensemble de données publiques de la communauté open source, les chercheurs d'Alibaba ont construit l'ensemble d'évaluation présenté dans le tableau suivant, couvrant quatre dimensions différentes : examen, compréhension, traduction et mathématiques. Le tableau ci-dessous fournit des détails sur chaque ensemble de tests, y compris sa configuration d'évaluation, ses métriques d'évaluation et les langages spécifiques impliqués.
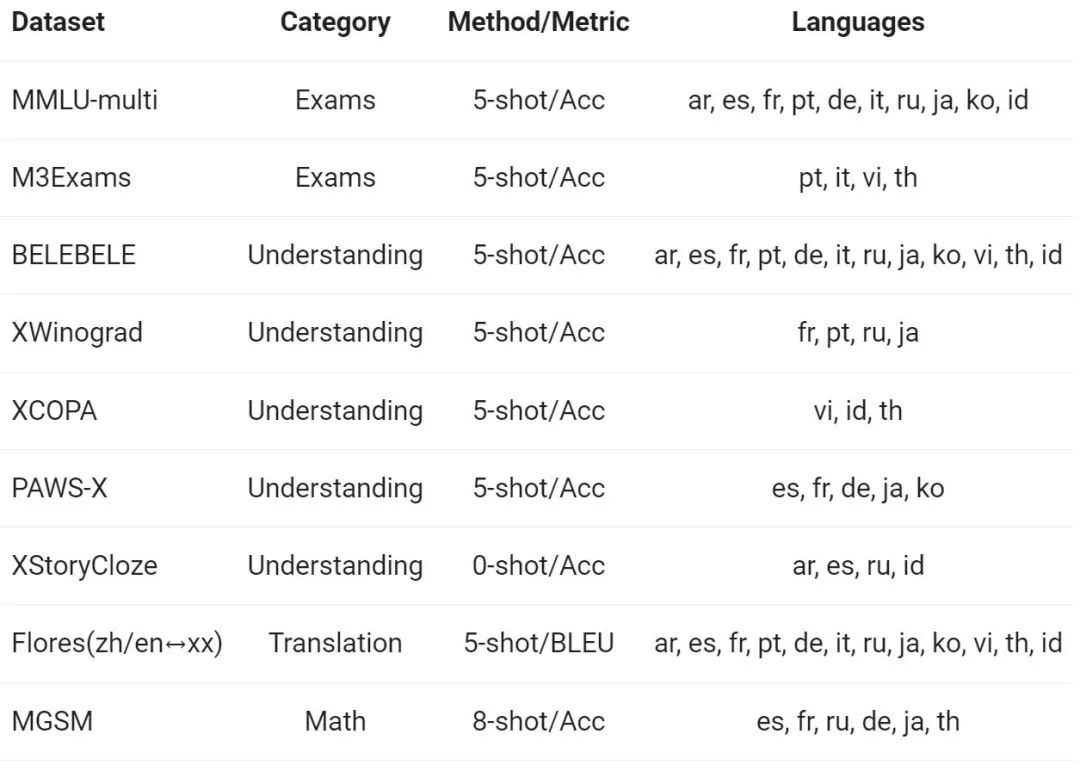
Les résultats détaillés sont les suivants :
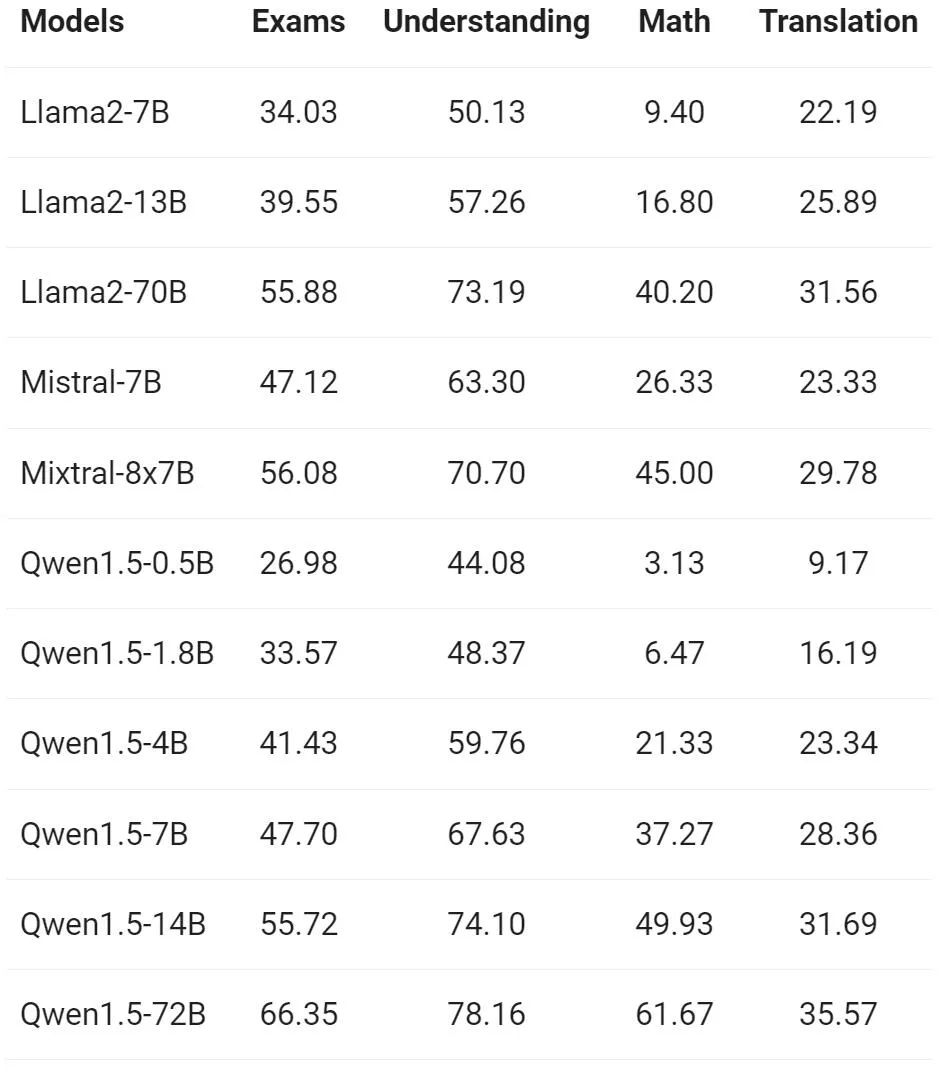
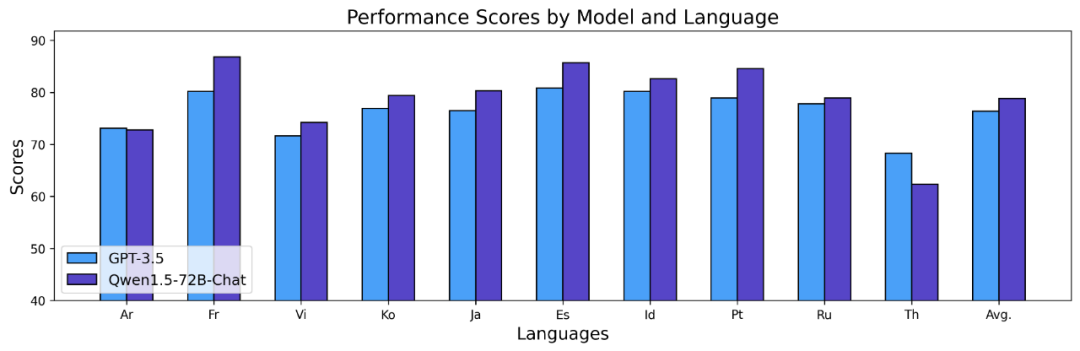
Les résultats ci-dessus montrent que le modèle de base Qwen1.5 fonctionne bien en termes de capacités multilingues dans 12 langues différentes et montre de bons résultats dans l'évaluation de diverses dimensions telles que la connaissance du sujet, la compréhension de la langue, la traduction et les mathématiques. De plus, en termes de capacités multilingues du modèle Chat, les résultats suivants peuvent être observés :
Séquences longues
Alors que la demande de compréhension de séquences longues continue d'augmenter, Alibaba s'est amélioré de des milliers dans la nouvelle version Interrogé sur les capacités correspondantes du modèle, la série complète de modèles Qwen1.5 prend en charge le contexte de 32 000 jetons. L'équipe Tongyi Qianwen a évalué les performances du modèle Qwen1.5 sur le benchmark L-Eval, qui mesure la capacité d'un modèle à générer des réponses basées sur un contexte long. Les résultats sont les suivants :
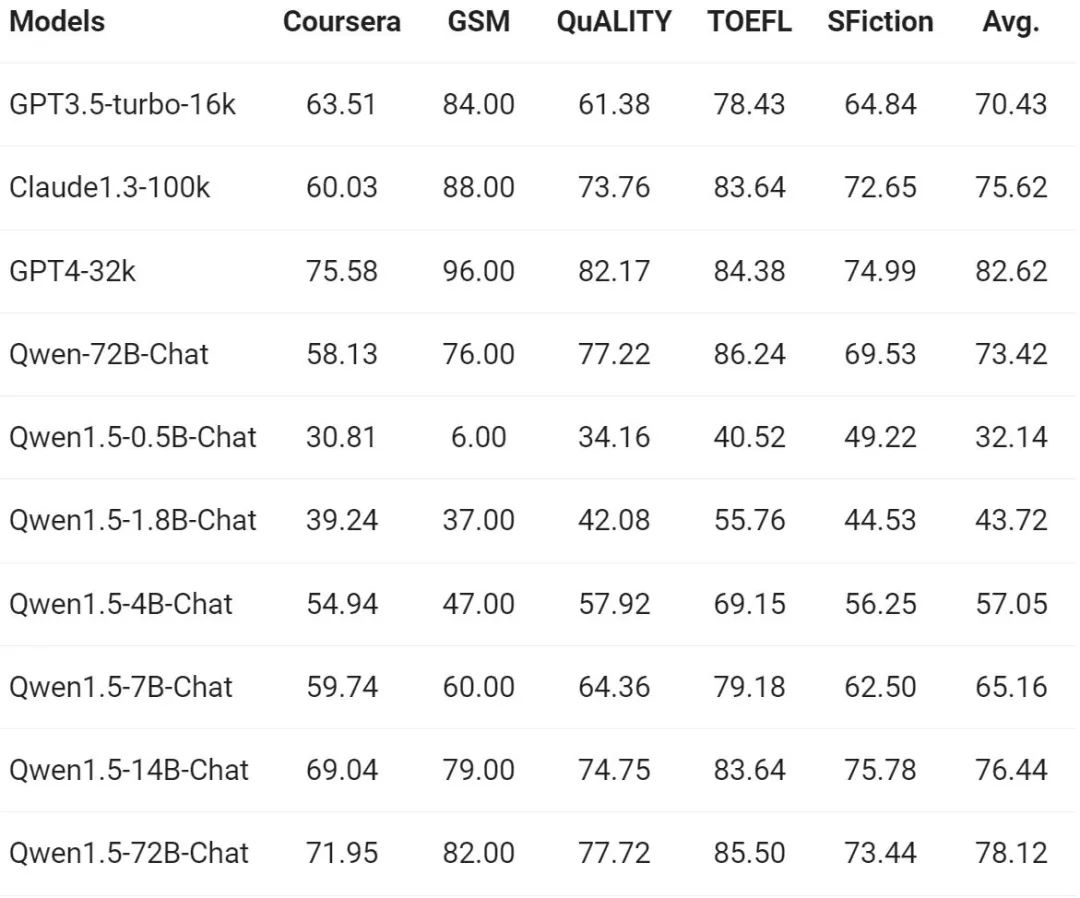
D'après les résultats, même un modèle à petite échelle comme Qwen1.5-7B-Chat peut montrer des performances comparables à celles de GPT-3.5, tandis que le plus grand modèle Qwen1.5 -72B- Le chat n'est que légèrement derrière GPT4-32k.
Il convient de mentionner que les résultats ci-dessus ne montrent l'effet de Qwen 1.5 que sous une longueur de 32 000 jetons, et cela ne signifie pas que le modèle ne peut prendre en charge qu'une longueur maximale de 32 000 jetons. Les développeurs peuvent essayer de modifier max_position_embedding à une valeur plus grande dans config.json pour observer si le modèle peut obtenir des résultats satisfaisants dans des scénarios de compréhension de contexte plus longs.
Lien vers des systèmes externes
De nos jours, l'un des charmes des modèles de langage généraux réside dans leur capacité potentielle à s'interfacer avec des systèmes externes. En tant que tâche émergente rapidement dans la communauté, RAG répond efficacement à certains des défis typiques auxquels sont confrontés les grands modèles de langage, tels que les hallucinations et l'incapacité d'obtenir des mises à jour en temps réel ou des données privées. De plus, les modèles de langage démontrent de puissantes capacités d’utilisation d’API et d’écriture de code basé sur des instructions et des exemples. Les grands modèles peuvent utiliser des interpréteurs de code ou agir en tant qu'agents d'IA pour obtenir une valeur plus large.
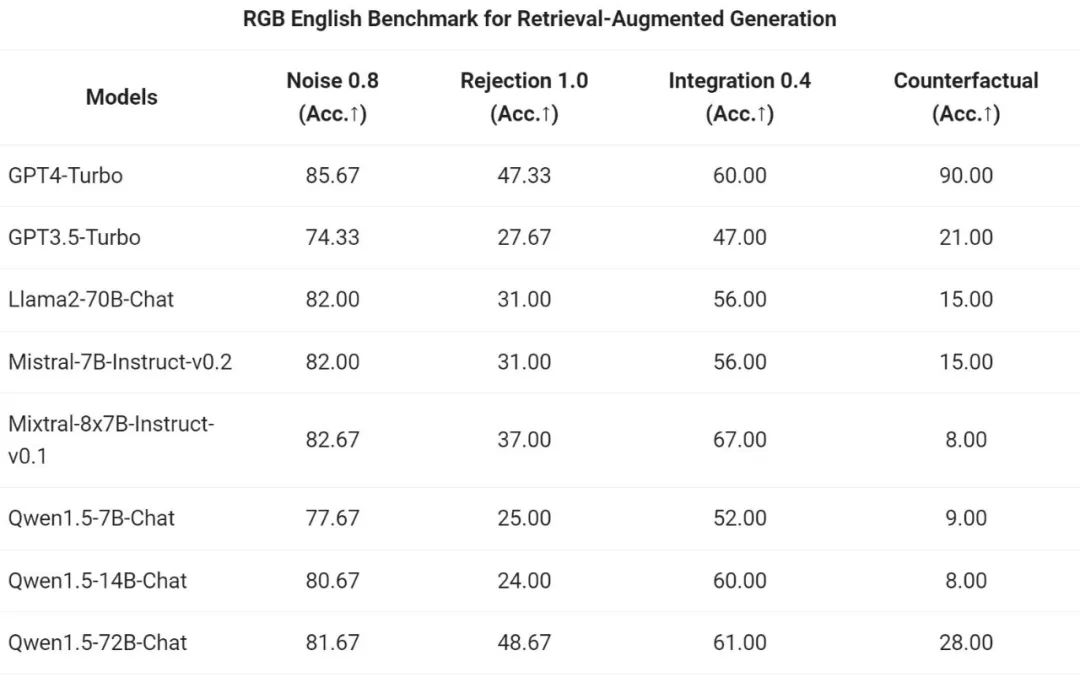
L'équipe Tongyi Qianwen a évalué l'effet de bout en bout du modèle Chat de la série Qwen1.5 sur la tâche RAG. L'évaluation est basée sur l'ensemble de tests RGB, qui est un ensemble utilisé pour l'évaluation RAG en chinois et en anglais :
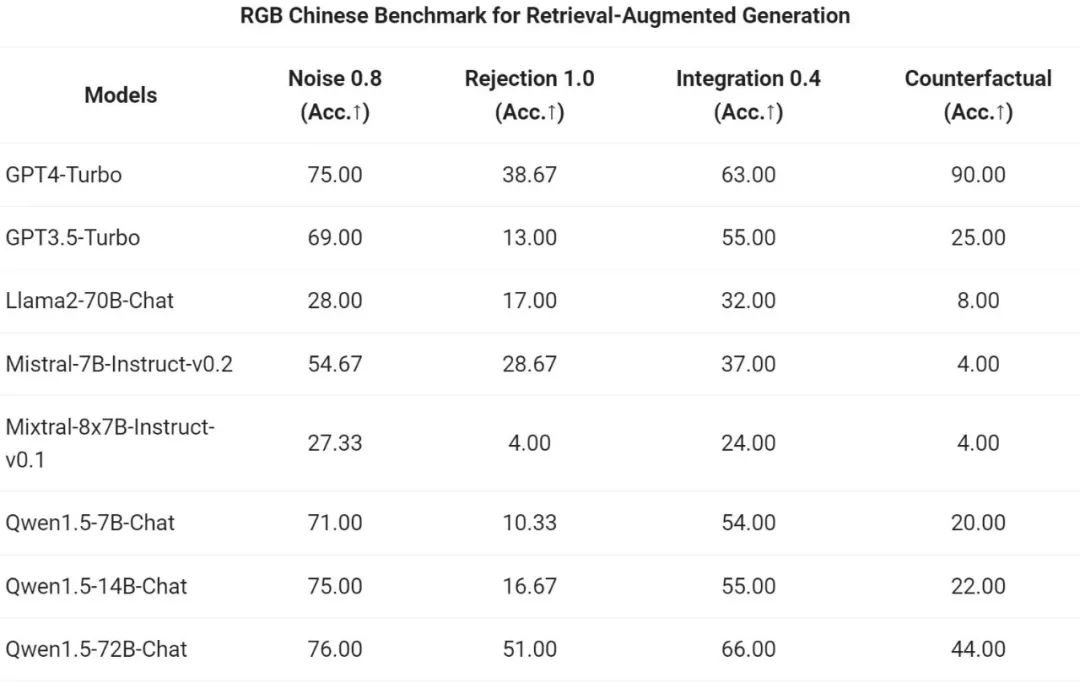
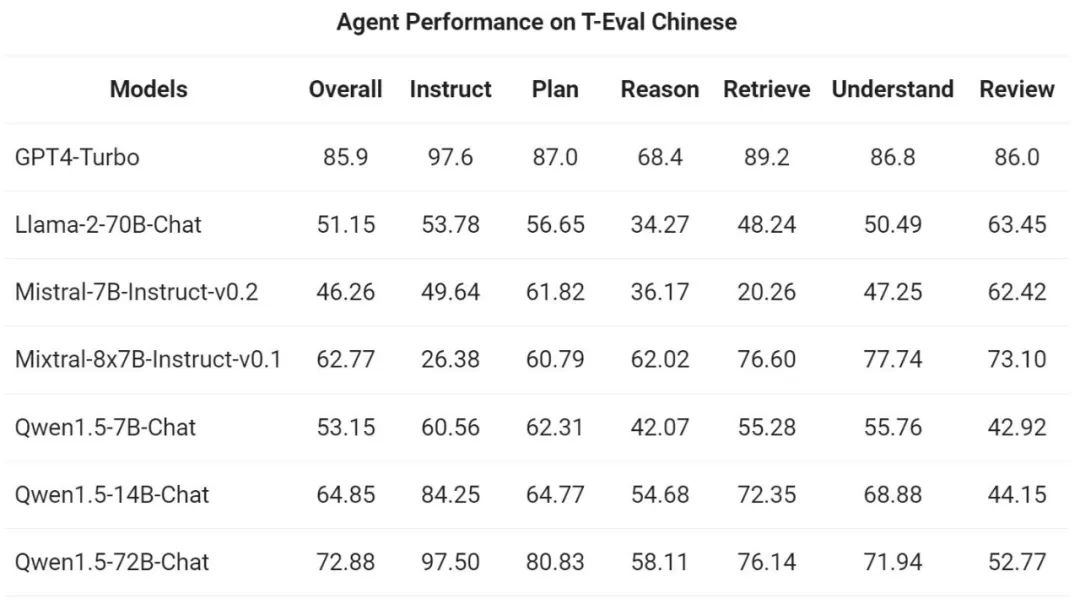
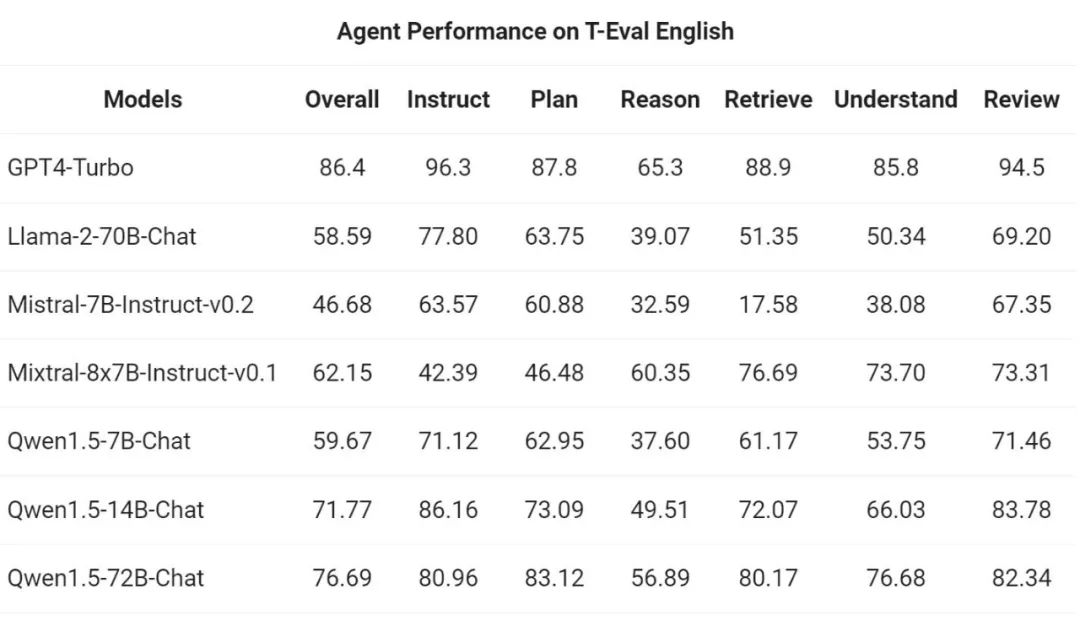
Ensuite, l'équipe Tongyi Qianwen a évalué Qwen1.5 en tant qu'agent général dans le T- Test de référence d'évaluation La capacité d'exécuter. Tous les modèles Qwen1.5 ne sont pas optimisés spécifiquement pour les benchmarks :
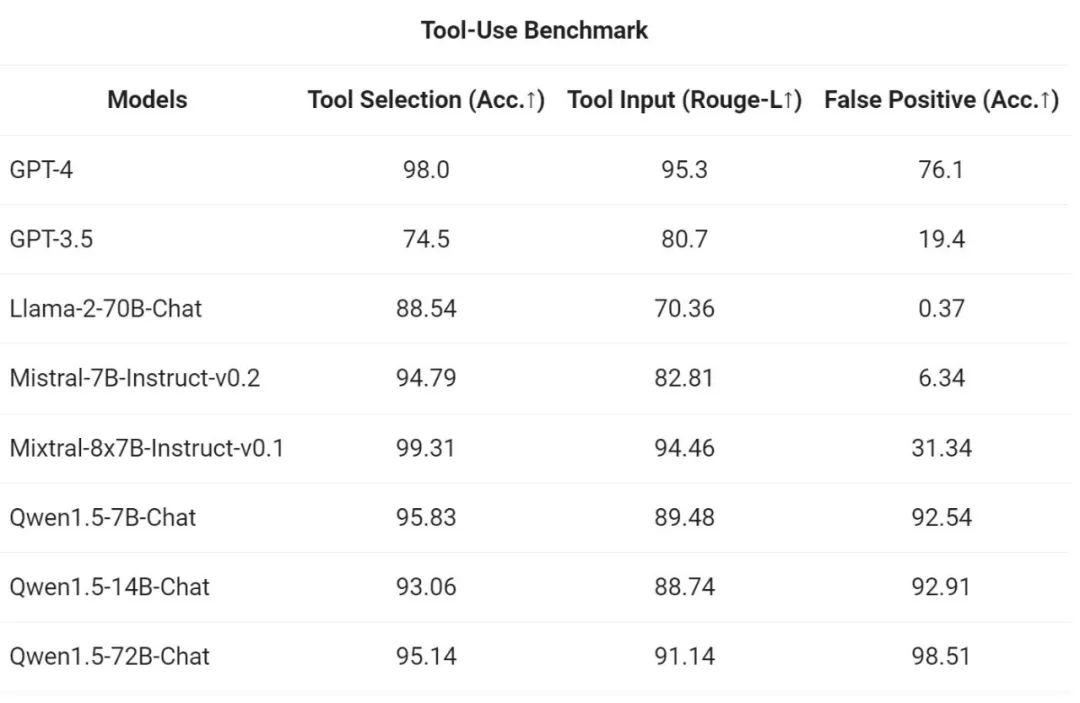
Afin de tester la capacité d'appel des outils, Alibaba a utilisé son propre benchmark d'évaluation open source pour tester la capacité du modèle à sélectionner et appeler correctement les outils. . Les résultats sont les suivants :
Enfin, comme l'interpréteur de code Python est devenu un outil de plus en plus puissant pour le LLM avancé, l'équipe Tongyi Qianwen a également évalué la capacité du nouveau modèle à utiliser cet outil sur la base de l'open source précédent. critères d'évaluation :
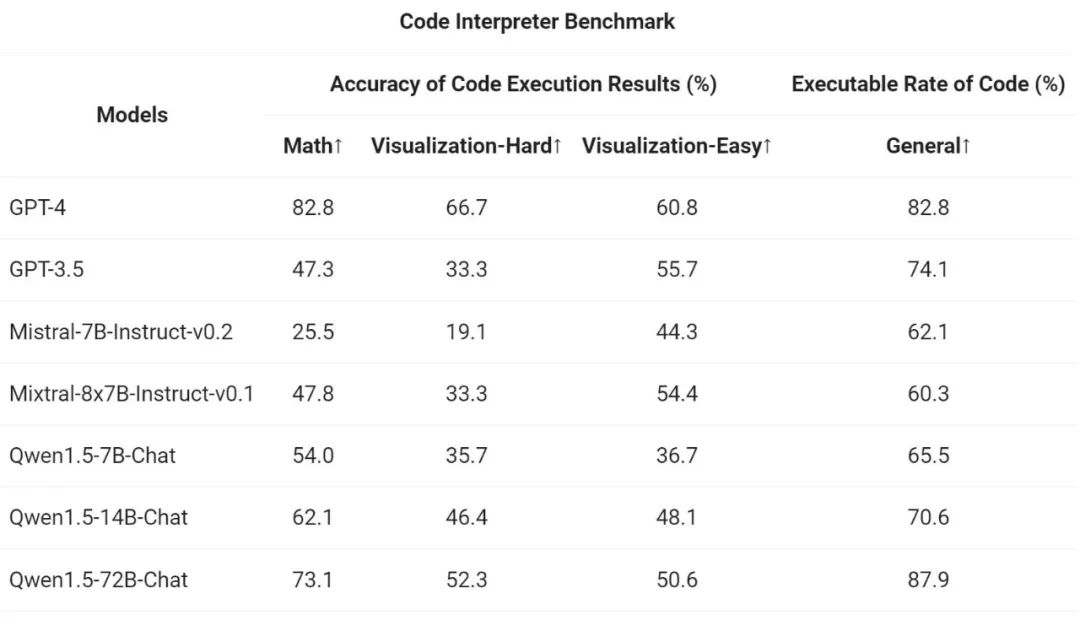
Les résultats montrent que le plus grand modèle Qwen1.5-Chat surpasse généralement le plus petit modèle, Qwen1.5-72B-Chat se rapprochant des performances d'utilisation des outils de GPT-4. Cependant, dans les tâches d'interprétation de code telles que la résolution de problèmes mathématiques et la visualisation, même le plus grand modèle Qwen1.5-72B-Chat est nettement en retard sur GPT-4 en termes de capacité de codage. Ali a déclaré que cela améliorerait les capacités de codage de tous les modèles Qwen pendant le processus de pré-formation et d'alignement dans les versions futures.
Qwen1.5 est intégré à la base de code des transformateurs HuggingFace. À partir de la version 4.37.0, les développeurs peuvent utiliser directement le code natif de la bibliothèque Transformers sans charger de code personnalisé (en spécifiant l'option trust_remote_code) pour utiliser Qwen1.5.
Dans l'écosystème open source, Alibaba a coopéré avec vLLM, SGLang (pour le déploiement), AutoAWQ, AutoGPTQ (pour la quantification), Axolotl, LLaMA-Factory (pour le réglage fin) et lama.cpp (pour l'inférence LLM locale), etc. Cadre de coopération, tous ces frameworks prennent désormais en charge Qwen1.5. La série Qwen1.5 est également actuellement disponible sur des plateformes telles que Ollama et LMStudio.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
