

Explication détaillée du flux de travail du pilote USB Linux

Le pilote du noyau Linux est l'un des composants les plus importants du système Linux. Ils sont chargés de communiquer avec les périphériques matériels afin que le système d'exploitation puisse identifier et utiliser correctement le matériel. Cependant, développer des pilotes pour le noyau Linux n’est pas une tâche facile. Dans cet article, nous approfondirons la méthode d'implémentation du pilote du noyau Linux et fournirons aux lecteurs une compréhension et des conseils complets.
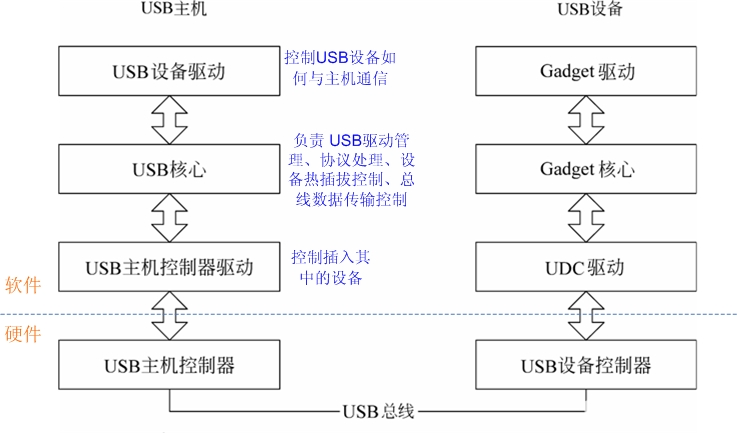
1. Hôte USB
Dans les pilotes Linux, la couche inférieure du pilote USB est le matériel du contrôleur hôte USB. Au-dessus se trouve le pilote du contrôleur hôte USB. Au-dessus du contrôleur hôte se trouve la couche principale USB et la couche supérieure est le pilote du périphérique USB. Couche (insérez le disque U, la souris, l'USB vers le port série et d'autres pilotes de périphériques sur l'hôte).
Par conséquent, dans la hiérarchie côté hôte, le pilote USB à implémenter comprend deux catégories : le pilote de contrôleur hôte USB et le pilote de périphérique USB. Le premier contrôle le périphérique USB qui y est inséré, et le second contrôle la manière dont le périphérique USB communique avec le périphérique USB. hôte. Le noyau USB du noyau Linux est responsable du travail principal de gestion des pilotes USB et de traitement des protocoles. Le noyau USB entre le pilote du contrôleur hôte et le pilote de périphérique est très important. Ses fonctions incluent : en définissant certaines structures de données, macros et fonctions, il fournit une interface de programmation pour le pilote de périphérique vers le haut et fournit une interface de programmation pour le contrôleur hôte USB. pilote vers le bas ; les variables globales conservent les informations sur le périphérique USB de l'ensemble du système ; contrôle complet de la connexion à chaud du périphérique, contrôle de la transmission des données du bus, etc.
2. Périphérique USB
Le pilote côté périphérique USB dans le noyau Linux est divisé en trois niveaux : pilote UDC, API Gadget et pilote Gadget. Le pilote UDC accède directement au matériel, contrôle la communication sous-jacente entre le périphérique USB et l'hôte et fournit des fonctions de rappel pour les opérations liées au matériel vers la couche supérieure. L'API Gadget actuelle est un simple wrapper autour des fonctions de rappel du pilote UDC. Le pilote Gadget contrôle spécifiquement l'implémentation des fonctions du périphérique USB, permettant à l'appareil d'afficher des fonctionnalités telles que « connexion réseau », « imprimante » ou « stockage de masse USB ». Il utilise l'API Gadget pour contrôler l'UDC afin d'implémenter les fonctions ci-dessus. L'API Gadget isole le pilote UDC de couche inférieure du pilote Gadget de couche supérieure, permettant ainsi de séparer l'implémentation des fonctions de la communication sous-jacente lors de l'écriture d'un pilote côté périphérique USB dans un système Linux.
3. Dans la structure organisationnelle du périphérique USB, il est divisé en quatre niveaux de haut en bas : périphérique (device), configuration (config), interface (interface) et point final (endpoint). Le programme du périphérique USB est lié à l'interface.
Une brève description de ces quatre niveaux est la suivante :
Les appareils ont généralement une ou plusieurs configurations
Les configurations ont souvent une ou plusieurs interfaces
L'interface n'a pas ou plus d'un point de terminaison
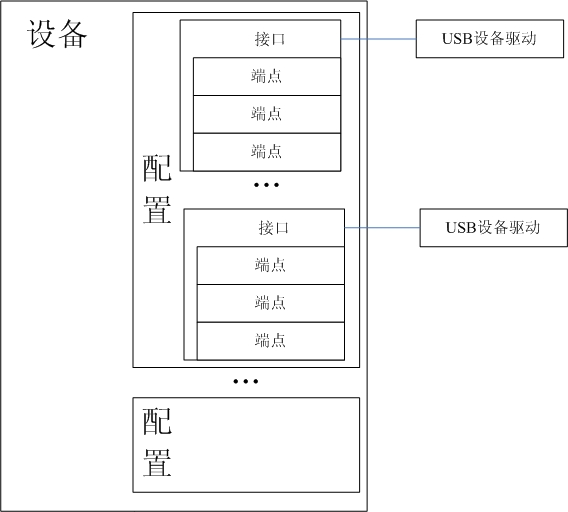
4. La forme de communication USB la plus élémentaire passe par les points de terminaison (les points de terminaison USB sont divisés en quatre types : interruption, masse, ISO et contrôle, chacun avec des utilisations différentes), les points de terminaison USB ne peuvent transmettre des données que dans une seule direction, à partir du de l'hôte vers l'appareil ou de l'appareil vers l'hôte. Le point de terminaison peut être considéré comme un canal unidirectionnel. Le pilote enregistre l'objet pilote auprès du sous-système USB et utilise ensuite l'identification du fabricant et du périphérique pour déterminer si le matériel est installé. Le noyau USB utilise une liste (une structure contenant l'ID du fabricant et l'ID du périphérique) pour déterminer quel pilote utiliser pour un périphérique, et le script de connexion à chaud l'utilise pour déterminer quand un périphérique spécifique est branché sur le système, quelle sonde de pilote doit être. automatiquement exécuté.
5. Structure des données
1) Périphérique USB : structure de données correspondante struct usb_device
2) Configuration : struct usb_host_config (Une seule configuration peut prendre effet à tout moment)
3) Interface USB : struct usb_interface (Le noyau USB le transmet au pilote de périphérique USB, et le pilote de périphérique USB est responsable du contrôle ultérieur. Une interface USB représente une fonction de base, et chaque pilote USB contrôle une interface. Donc un physique Les périphériques matériels peuvent nécessiter plusieurs pilotes)
.4) Endpoint : struct usb_host_endpoint, les véritables informations sur le point final qu'il contient se trouvent dans une autre structure : struct usb_endpoint_descriptor (descripteur de point final, contient toutes les données spécifiques à l'USB).
6. Classification des points de terminaison USB
La forme la plus élémentaire de communication USB passe par ce qu'on appelle un point de terminaison. Un point de terminaison USB ne peut transférer des données que dans une seule direction (de l'hôte vers le périphérique (appelé point de terminaison de sortie) ou du périphérique vers l'hôte (appelé point de terminaison d'entrée)). Un point final peut être considéré comme un canal unidirectionnel.
Il existe 4 types différents de points de terminaison USB, chacun avec des méthodes de transmission de données différentes :
1) CONTRÔLE
Les points de terminaison de contrôle sont utilisés pour contrôler l'accès à différentes parties d'un périphérique USB. Ils sont généralement utilisés pour configurer le périphérique, obtenir des informations sur le périphérique, envoyer des commandes au périphérique ou obtenir des rapports sur l'état du périphérique. Ces points finaux sont généralement plus petits. Chaque périphérique USB possède un point final de contrôle appelé « Endpoint 0 », qui est utilisé par le noyau USB pour configurer le périphérique lorsqu'il est branché. Le protocole USB garantit qu'il reste toujours suffisamment de bande passante pour que le point final de contrôle transmette les données à l'appareil.
2) INTERRUPTION
Chaque fois que l'hôte USB demande des données au périphérique, le point de terminaison d'interruption transmet une petite quantité de données à un débit fixe. Il s’agit de la principale méthode de transfert de données pour les claviers et souris USB. Il est également utilisé pour transférer des données vers des périphériques USB afin de contrôler l'appareil. Généralement non utilisé pour transférer de grandes quantités de données. Le protocole USB garantit qu'il reste toujours suffisamment de bande passante pour que le point final de l'interruption transmette les données à l'appareil.
3) Lot EN VRAC
Les points de terminaison en masse sont utilisés pour transférer de grandes quantités de données. Ces points de terminaison sont généralement beaucoup plus grands que les points de terminaison d’interruption. Ils sont couramment utilisés dans des situations où il ne peut y avoir de perte de données. Le protocole USB ne garantit pas que le transfert sera effectué dans un délai précis. S'il n'y a pas assez d'espace sur le bus pour envoyer l'intégralité du paquet BULK, celui-ci est divisé en plusieurs paquets pour la transmission. Ces points de terminaison sont couramment utilisés sur les imprimantes, le stockage de masse USB et les périphériques réseau USB.
4) ISOCHRONE
Les points de terminaison isochrones transfèrent également de grandes quantités de données par lots, mais leur livraison n'est pas garantie. Ces points de terminaison sont utilisés dans des appareils capables de gérer la perte de données et s'appuient davantage sur le maintien d'un flux continu de données. Tels que les équipements audio et vidéo, etc.
Les points de terminaison de contrôle et de lot sont utilisés pour le transfert de données asynchrone, tandis que les points de terminaison d'interruption et isochrones sont périodiques. Cela signifie que ces points de terminaison sont configurés pour transmettre des données en continu à une heure fixe et que le cœur USB leur réserve la bande passante correspondante.
7. point final
struct usb_host_endpoint{ struct usb_endpoint_descriptor desc;//端点描述符 struct list_head urb_list;//此端点的URB对列,由USB核心维护 void *hcpriv; struct ep_device *ep_dev; /* For sysfs info */ unsigned char*extra;/* Extra descriptors */ int extralen; int enabled;};
Lorsque le pilote de périphérique USB appelle usb_submit_urb pour soumettre une requête urb, int usb_hcd_link_urb_to_ep(struct usb_hcd *hcd, struct urb *urb) sera appelé pour ajouter cette urb à la queue de urb_list. (hcd : pilote de contrôleur hôte, structure de données correspondante struct usb_hcd)
8.urb
Toutes les communications USB sont en mode requête->réponse et les périphériques USB n'enverront pas activement de données à l'hôte. Écrire des données : le pilote de périphérique USB envoie une requête urb au périphérique USB, et le périphérique USB n'a pas besoin de renvoyer de données. Lire les données : le pilote du périphérique USB envoie une requête urb au périphérique USB et le périphérique USB doit renvoyer des données.
Le pilote de périphérique USB communique avec tous les périphériques USB via urb. urb est décrit avec la structure struct urb (include/linux/usb.h).
urb envoie ou reçoit des données de manière asynchrone vers un point de terminaison spécifique d'un périphérique USB spécifique. Un pilote de périphérique USB peut attribuer plusieurs urb à un seul point de terminaison ou réutiliser un seul urb pour plusieurs points de terminaison différents, en fonction des besoins du pilote. Chaque point de terminaison de l'appareil gère une file d'attente Urb, de sorte que plusieurs Urbs peuvent être envoyés au même point de terminaison avant que la file d'attente ne soit vidée.
Le cycle de vie typique d'une urb est le suivant :
(1) Créé ;
(2) Un point de terminaison spécifique attribué à un périphérique USB spécifique ;
(3) Soumis au noyau USB ;
(4) Soumis par le noyau USB à un pilote de contrôleur hôte USB spécifique pour un périphérique spécifique ;
(5) Traité par le pilote du contrôleur hôte USB et transmis à l'appareil
;
(6) Une fois les opérations ci-dessus terminées, le pilote du contrôleur hôte USB informe le pilote du périphérique USB.
urb peut également être annulé à tout moment par le pilote qui l'a soumis ; si le périphérique est supprimé, urb peut être annulé par le noyau USB. Les urbs sont créés dynamiquement et contiennent un décompte de références interne afin qu'ils puissent être automatiquement libérés lorsque le dernier utilisateur les libère.
8.1 Soumettre urb
Une fois l'urb correctement créé et initialisé, il peut être soumis au noyau USB pour être envoyé au périphérique USB. Ceci est réalisé en appelant la fonction sb_submit_urb.
.int usb_submit_urb(struct urb *urb, gfp_t mem_flags);
Paramètres :
struct urb *urb : pointeur vers l'urb soumis
gfp_t mem_flags : utilise les mêmes paramètres transmis à l'appel kmalloc pour indiquer au cœur USB comment allouer les tampons de mémoire en temps opportun
Comme la fonction usb_submit_urb peut être appelée à tout moment (y compris depuis un contexte d'interruption), la variable mem_flags doit être définie correctement. Selon le moment où usb_submit_urb est appelé, seules 3 valeurs valides sont disponibles :
GFP_ATOMIC
Cette valeur doit être utilisée tant que les conditions suivantes sont remplies :
1) L'appelant se trouve dans un gestionnaire de fin d'urb, un gestionnaire d'interruption, une moitié inférieure, une tasklet ou une fonction de rappel de minuterie.
2) L'appelant détient un verrou tournant ou un verrou en lecture-écriture. Notez que si un sémaphore est détenu, cette valeur n'est pas nécessaire.
.
3) l'état actuel n'est pas TASK_RUNNING. À moins que le pilote n'ait modifié l'état actuel par lui-même, l'état devrait toujours être TASK_RUNNING.
GFP_NOIO
Le pilote est utilisé lors du traitement des E/S des blocs. Il doit également être utilisé lors de la gestion des erreurs pour tous les types de stockage.
GFP_KERNEL
Toutes autres situations qui n'entrent pas dans les situations mentionnées précédemment
Une fois l'urb soumis avec succès au noyau USB, aucun membre de la structure urb n'est accessible jusqu'à ce que la fonction de routine de traitement final soit appelée
8.2 Routine de traitement de fin d'urb
Si usb_submit_urb est appelé avec succès et transfère le contrôle de l'urb au noyau USB, la fonction renvoie 0 ; sinon, un code d'erreur négatif est renvoyé. Si la fonction est appelée avec succès, la routine du gestionnaire de fin sera appelée une fois à la fin de l'urb. .Lorsque cette fonction est appelée, le noyau USB complète l'urb et rend son contrôle au pilote de périphérique.
Il n'y a que 3 situations pour terminer urb et appeler la routine de traitement de fin :
(1) urb est envoyé avec succès à l'appareil et l'appareil renvoie la confirmation correcte. Si tel est le cas, la variable d'état dans urb est définie sur 0.
.
(2) Une erreur se produit et la valeur de l'erreur est enregistrée dans la variable d'état de la structure urbaine.
(3) Dissociation de l'URB du noyau USB. Cela se produit soit lorsque le pilote demande au noyau USB d'annuler un urb soumis en appelant usb_unlink_urb ou usb_kill_urb, soit lorsqu'un urb lui a été soumis et que le périphérique est supprimé du système.
9. Détection et déconnexion
Dans la structure struct usb_driver, il y a 2 fonctions que le noyau USB appelle au moment opportun :
(1) Lorsque le périphérique est branché, si le cœur USB pense que le pilote peut le gérer (le cœur USB utilise une liste (une structure contenant l'ID du fabricant et l'ID du numéro de périphérique) pour déterminer quel pilote utiliser pour un périphérique) , la fonction de sonde est appelée. La fonction de sonde vérifie les informations sur l'appareil qui lui sont transmises et détermine si le pilote est réellement adapté à cet appareil.
(2) Pour certaines raisons, lorsque l'appareil est retiré ou que le pilote ne contrôle plus l'appareil, appelez la fonction de déconnexion et effectuez le nettoyage approprié.
Les fonctions de rappel de détection et de déconnexion sont appelées dans le contexte du thread du noyau du hub USB, il est donc légal de les mettre en veille. Afin de réduire le temps de détection USB, la plupart du travail est effectué lorsque l'appareil est allumé. L'ajout et la suppression de périphériques USB sont gérés dans le thread, de sorte que tout pilote de périphérique lent peut allonger le temps de détection du périphérique USB.
9.1 Analyse de la fonction de détection
Dans la fonction de rappel de sonde, le pilote de périphérique USB doit initialiser toutes les structures locales qu'il peut utiliser pour gérer le périphérique USB et enregistrer toutes les informations requises sur le périphérique dans les structures locales, car il est généralement plus facile de le faire à ce moment-là pour communiquer. avec l'appareil, le pilote USB sonde généralement l'adresse du point de terminaison et la taille du tampon de l'appareil.
Dans cet article, nous présentons en détail la méthode d'implémentation du pilote du noyau Linux, y compris le cadre du pilote du noyau, l'écriture du module du noyau, l'enregistrement et la désinscription du pilote de périphérique, etc. Nous pensons qu'en étudiant cet article, les lecteurs pourront mieux comprendre les principes d'implémentation du pilote du noyau Linux et fournir davantage de références et d'aide pour leur propre travail de développement.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
CentOS a été interrompu, les alternatives comprennent: 1. Rocky Linux (meilleure compatibilité); 2. Almalinux (compatible avec CentOS); 3. Serveur Ubuntu (configuration requise); 4. Red Hat Enterprise Linux (version commerciale, licence payante); 5. Oracle Linux (compatible avec Centos et Rhel). Lors de la migration, les considérations sont: la compatibilité, la disponibilité, le soutien, le coût et le soutien communautaire.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Une fois CentOS arrêté, les utilisateurs peuvent prendre les mesures suivantes pour y faire face: sélectionnez une distribution compatible: comme Almalinux, Rocky Linux et CentOS Stream. Migrez vers les distributions commerciales: telles que Red Hat Enterprise Linux, Oracle Linux. Passez à Centos 9 Stream: Rolling Distribution, fournissant les dernières technologies. Sélectionnez d'autres distributions Linux: comme Ubuntu, Debian. Évaluez d'autres options telles que les conteneurs, les machines virtuelles ou les plates-formes cloud.
 Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Vs Code Système Exigences: Système d'exploitation: Windows 10 et supérieur, MacOS 10.12 et supérieur, processeur de distribution Linux: minimum 1,6 GHz, recommandé 2,0 GHz et au-dessus de la mémoire: minimum 512 Mo, recommandée 4 Go et plus d'espace de stockage: Minimum 250 Mo, recommandée 1 Go et plus d'autres exigences: connexion du réseau stable, xorg / wayland (Linux) recommandé et recommandée et plus
 Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Dépannage des étapes pour la construction d'image Docker échouée: cochez la syntaxe Dockerfile et la version de dépendance. Vérifiez si le contexte de construction contient le code source et les dépendances requis. Affichez le journal de construction pour les détails d'erreur. Utilisez l'option - cibler pour créer une phase hiérarchique pour identifier les points de défaillance. Assurez-vous d'utiliser la dernière version de Docker Engine. Créez l'image avec --t [Image-Name]: Debug Mode pour déboguer le problème. Vérifiez l'espace disque et assurez-vous qu'il est suffisant. Désactivez SELINUX pour éviter les interférences avec le processus de construction. Demandez de l'aide aux plateformes communautaires, fournissez Dockerfiles et créez des descriptions de journaux pour des suggestions plus spécifiques.
