

Une brève analyse de la planification des groupes Linux

Le système Linux est un système d'exploitation qui prend en charge l'exécution simultanée de tâches multiples. Il peut exécuter plusieurs processus en même temps, améliorant ainsi l'utilisation et l'efficacité du système. Cependant, pour qu’un système Linux atteigne des performances optimales, il est nécessaire de comprendre et de maîtriser sa méthode de planification des processus. La planification des processus fait référence à la fonction du système d'exploitation qui alloue dynamiquement les ressources du processeur à différents processus en fonction de certains algorithmes et stratégies pour réaliser l'exécution simultanée de plusieurs tâches. Il existe de nombreuses méthodes de planification de processus dans les systèmes Linux, dont la planification de groupe. La planification de groupe est une méthode de planification de processus basée sur un groupe qui permet à différents groupes de processus de partager les ressources du processeur dans une certaine proportion, atteignant ainsi un équilibre entre équité et efficacité. Cet article analysera brièvement la méthode de planification de groupe Linux, y compris le principe, la mise en œuvre, la configuration, les avantages et les inconvénients de la planification de groupe.
cgroup et planification de groupe
Le noyau Linux implémente la fonction de groupe de contrôle (cgroup, depuis Linux 2.6.24), qui peut prendre en charge les processus de regroupement puis diviser diverses ressources par groupe. Par exemple : le groupe 1 a 30 % de processeur et 50 % d'E/S disque, le groupe 2 a 10 % de processeur et 20 % d'E/S disque, et ainsi de suite. Veuillez vous référer aux articles liés au cgroup pour plus de détails.
cgroup prend en charge la division de nombreux types de ressources, et les ressources CPU en font partie, ce qui conduit à la planification de groupe.
Dans le noyau Linux, le planificateur traditionnel est planifié en fonction des processus. Supposons que les utilisateurs A et B partagent une machine, qui est principalement utilisée pour compiler des programmes. Nous pouvons espérer que A et B pourront partager équitablement les ressources CPU, mais si l'utilisateur A utilise make -j8 (8 threads parallèles make) et que l'utilisateur B utilise make directement (en supposant que ses programmes make utilisent la priorité par défaut), le programme make de l'utilisateur A générera 8 fois plus de processus que l'utilisateur B, occupant ainsi (environ) 8 fois le CPU de l'utilisateur B. Étant donné que le planificateur est basé sur des processus, plus l'utilisateur A possède de processus, plus la probabilité d'être planifié est grande et plus il est compétitif par rapport au processeur.
Comment s'assurer que les utilisateurs A et B partagent équitablement le CPU ? La planification de groupe peut le faire. Les processus appartenant aux utilisateurs A et B sont divisés en un groupe chacun. Le planificateur sélectionnera d'abord un groupe parmi les deux groupes, puis sélectionnera un processus à exécuter dans le groupe sélectionné. Si les deux groupes ont la même probabilité d’être sélectionnés, alors les utilisateurs A et B occuperont chacun environ 50 % du CPU.
Structures de données associées
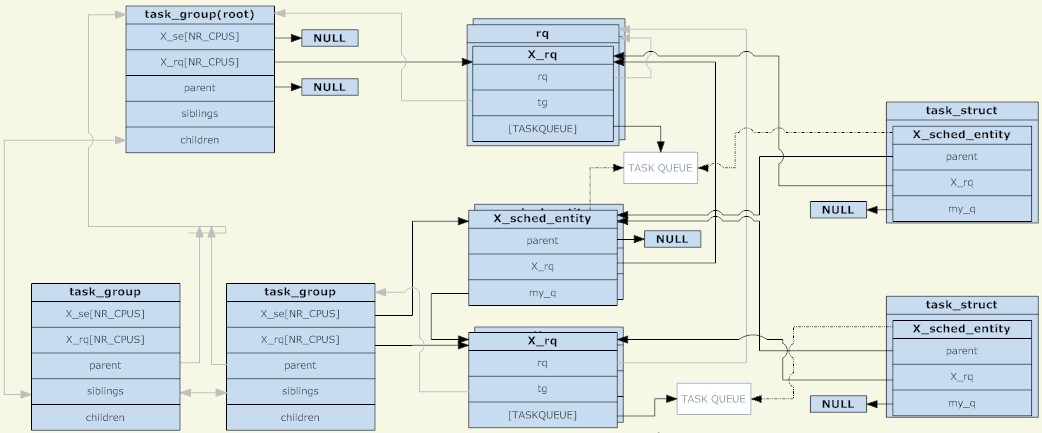
Dans le noyau Linux, la structure task_group est utilisée pour gérer les groupes pour la planification de groupe. Tous les task_groups existants forment une arborescence (correspondant à la structure de répertoires du cgroup).
Un task_group peut contenir des processus avec n'importe quelle catégorie de planification (en particulier, des processus en temps réel et des processus ordinaires), donc task_group doit fournir un ensemble de structures de planification pour chaque stratégie de planification. L'ensemble des structures de planification mentionné ici comprend principalement deux parties, l'entité de planification et la file d'attente d'exécution (les deux sont partagées par CPU). L'entité de planification sera ajoutée à la file d'attente d'exécution pour un groupe_tâches, son entité de planification sera ajoutée à la file d'attente d'exécution de son groupe_tâches parent.
Pourquoi existe-t-il une entité de planification ? Puisqu'il existe deux types d'objets planifiés : task_group et task, une structure abstraite est nécessaire pour les représenter. Si l'entité de planification représente un task_group, son champ my_q pointe vers la file d'attente d'exécution correspondant à ce groupe de planification ; sinon, le champ my_q est NULL et l'entité de planification représente une tâche. L'opposé de my_q dans l'entité de planification est La file d'attente d'exécution du nœud parent, qui est la file d'attente d'exécution dans laquelle cette entité de planification doit être placée.
Ainsi, l'entité de planification et la file d'attente d'exécution forment une autre structure arborescente. Chacun de ses nœuds non-feuilles correspond à la structure arborescente de task_group, et les nœuds feuilles correspondent à des tâches spécifiques. Tout comme les processus dans l'état non-TASK_RUNNING ne seront pas placés dans la file d'attente d'exécution, s'il n'y a aucun processus dans l'état TASK_RUNNING dans un groupe, ce groupe (l'entité de planification correspondante) ne sera pas placé dans sa file d'attente d'exécution de niveau supérieur. Pour être clair, tant que le groupe de planification est créé, son groupe de tâches correspondant existera définitivement dans la structure arborescente composée de groupe_de tâches ; et si son entité de planification correspondante existe dans la structure arborescente composée de la file d'attente d'exécution et de l'entité de planification dépend de si il existe un processus dans l'état TASK_RUNNING dans ce groupe.
Le task_group en tant que nœud racine n'a pas d'entité de planification. Le planificateur démarre toujours à partir de sa file d'attente d'exécution pour sélectionner l'entité de planification suivante (le nœud racine doit être le premier sélectionné, et il n'y a pas d'autres candidats, donc le nœud racine ne le fait pas). Des entités de planification sont requises). La file d'attente d'exécution correspondant au nœud racine task_group est regroupée dans une structure rq qui, en plus de la file d'attente d'exécution spécifique, contient également des informations statistiques globales et d'autres champs.
Lors de la planification, le planificateur sélectionne une entité de planification dans la file d'attente d'exécution du groupe de tâches racine. Si cette entité de planification représente un groupe_tâches, le planificateur doit continuer à sélectionner une entité de planification dans la file d'attente d'exécution correspondant à ce groupe. Cette récursion continue jusqu'à ce qu'un processus soit sélectionné. À moins que la file d'attente d'exécution du groupe de tâches racine ne soit vide, un processus sera définitivement trouvé par récurrence. Car si la file d'attente d'exécution correspondant à un task_group est vide, son entité de planification correspondante ne sera pas ajoutée à la file d'attente d'exécution correspondant à son nœud parent.
Enfin, pour un task_group, son entité de planification et sa file d'attente d'exécution sont partagées par CPU, et une entité de planification (correspondant à task_group) ne sera ajoutée qu'à la file d'attente d'exécution correspondant au même CPU. Pour une tâche, il n'existe qu'une seule copie de l'entité de planification (non divisée par CPU). La fonction d'équilibrage de charge du planificateur peut déplacer l'entité de planification (correspondant à la tâche) de la file d'attente d'exécution correspondant aux différentes CPU.
Stratégie planning pour le groupe
La structure principale des données de la planification de groupe a été clarifiée, mais il reste ici un problème très important. Nous savons que les tâches ont leurs priorités correspondantes (priorité statique ou priorité dynamique) et le planificateur sélectionne les processus dans la file d'attente d'exécution en fonction de la priorité. Ainsi, puisque task_group et task sont tous deux abstraits dans des entités de planification et acceptent la même planification, comment définir la priorité de task_group ? Cette question doit être répondue spécifiquement par la catégorie de planification (différentes catégories de planification ont des définitions de priorité différentes), en particulier rt (planification en temps réel) et cfs (planification totalement équitable).
Ordonnancement groupé des processus en temps réel
Comme le montre l'article « Une brève analyse de la planification des processus Linux », un processus en temps réel est un processus qui a des exigences en temps réel pour le CPU. Sa priorité est liée à des tâches spécifiques et est entièrement définie par l'utilisateur. . Le planificateur choisira toujours le processus en temps réel à exécuter ayant la priorité la plus élevée.
Avec le développement de la planification de groupe, la priorité du groupe est définie comme « la priorité du processus le plus prioritaire du groupe ». Par exemple, s'il y a trois processus dans le groupe avec les priorités 10, 20 et 30, la priorité du groupe est 10 (plus la valeur est petite, plus la priorité est grande).
La priorité du groupe est ainsi définie, ce qui conduit à un phénomène intéressant. Lorsqu'une tâche est mise ou retirée de la file d'attente, tous ses nœuds ancêtres doivent d'abord être retirés de la file d'attente, puis remis en file d'attente de bas en haut. Étant donné que la priorité d'un nœud de groupe dépend de ses nœuds enfants, la mise en file d'attente et le retrait des tâches affecteront chacun de ses nœuds ancêtres.
Ainsi, lorsque le planificateur sélectionne l'entité de planification dans le groupe de tâches du nœud racine, il peut toujours trouver la priorité la plus élevée parmi tous les processus en temps réel dans l'état TASK_RUNNING le long du chemin correct. Cette implémentation semble naturelle, mais à bien y réfléchir, à quoi sert de regrouper ainsi les processus temps réel ? Indépendamment du regroupement ou non, le planificateur doit « sélectionner celui ayant la priorité la plus élevée parmi tous les processus en temps réel dans l'état TASK_RUNNING ». Il semble qu'il manque quelque chose ici...
Nous devons maintenant introduire les deux fichiers proc dans le système Linux : /proc/sys/kernel/sched_rt_period_us et /proc/sys/kernel/sched_rt_runtime_us. Ces deux fichiers stipulent que dans une période avec sched_rt_period_us comme période, la somme des temps d'exécution de tous les processus en temps réel ne doit pas dépasser sched_rt_runtime_us. Les valeurs par défaut de ces deux fichiers sont 1 s et 0,95 s, ce qui signifie que chaque seconde est un cycle. Dans ce cycle, la durée totale d'exécution de tous les processus en temps réel ne dépasse pas 0,95 seconde et le reste au moins 0,05. les secondes seront réservées aux processus ordinaires. En d’autres termes, le processus temps réel n’occupe pas plus de 95 % du CPU. Avant l'apparition de ces deux fichiers, il n'y avait aucune limite à la durée d'exécution des processus temps réel. S'il y avait toujours des processus temps réel dans l'état TASK_RUNNING, les processus ordinaires ne pourraient jamais s'exécuter. L'équivalent de sched_rt_runtime_us est égal à sched_rt_period_us.
Pourquoi y a-t-il deux variables, sched_rt_runtime_us et sched_rt_period_us ? N'est-il pas possible d'utiliser directement une variable qui représente le pourcentage d'utilisation du CPU ? Je pense que cela est dû au fait que de nombreux processus en temps réel font quelque chose périodiquement, comme un programme vocal envoyant un paquet vocal toutes les 20 ms, un programme vidéo actualisant une image toutes les 40 ms, etc. Les périodes sont importantes et la simple utilisation d’un taux d’occupation macro du processeur ne peut pas décrire avec précision les besoins des processus en temps réel.
Le regroupement de processus en temps réel élargit les concepts de sched_rt_runtime_us et sched_rt_period_us. Chaque task_group a ses propres sched_rt_runtime_us et sched_rt_period_us, ce qui garantit que les processus de son propre groupe ne peuvent exécuter sched_rt_runtime_us que pendant une période limitée. Le taux d'occupation du processeur est sched_rt_runtime_us/sched_rt_period_us.
Pour le task_group du nœud racine, ses sched_rt_runtime_us et sched_rt_period_us sont égaux aux valeurs des deux fichiers proc ci-dessus. Pour un nœud task_group, en supposant qu'il y a n sous-groupes de planification et m processus dans l'état TASK_RUNNING, son taux d'occupation CPU est A et le taux d'occupation CPU de ces n sous-groupes est B, alors B doit être inférieur ou égal à A. , et le temps CPU restant de A-B sera alloué aux m processus dans l'état TASK_RUNNING. (Ce qui est discuté ici est le taux d'occupation du processeur, car chaque groupe de planification peut avoir des valeurs de cycle différentes.)
Afin d'implémenter la logique de sched_rt_runtime_us et sched_rt_period_us, lorsque le noyau met à jour le temps d'exécution d'un processus (comme une mise à jour de l'heure déclenchée par une interruption d'horloge périodique), le noyau ajoutera le temps d'exécution correspondant à l'entité de planification du processus en cours. et tous ses nœuds ancêtres. Si une entité de planification atteint le temps limité par sched_rt_runtime_us, elle sera supprimée de la file d'attente d'exécution correspondante et le rt_rq correspondant sera défini sur l'état limité. Dans cet état, l'entité de planification correspondant à ce rt_rq n'entrera plus dans la file d'attente d'exécution. Chaque rt_rq maintient un temporisateur périodique avec une période de synchronisation de sched_rt_period_us. Chaque fois que la minuterie est déclenchée, sa fonction de rappel correspondante soustraira une valeur unitaire sched_rt_period_us du temps d'exécution de rt_rq (mais gardera le temps d'exécution au moins égal à 0), puis restaurera rt_rq de l'état limité.
Il y a une autre question. Comme mentionné précédemment, par défaut, le temps d'exécution des processus en temps réel dans le système ne dépasse pas 0,95 seconde par seconde. Si la demande réelle du CPU par le processus temps réel est inférieure à 0,95 seconde (supérieure ou égale à 0 seconde et inférieure à 0,95 seconde), le temps restant sera alloué aux processus ordinaires. Et si la demande de CPU du processus en temps réel est supérieure à 0,95 seconde, il ne peut fonctionner que pendant 0,95 seconde, et les 0,05 secondes restantes seront allouées à d'autres processus ordinaires. Cependant, que se passe-t-il si aucun processus ordinaire n'a besoin d'utiliser le CPU pendant ces 0,05 secondes (processus ordinaires qui n'ont pas d'état TASK_RUNNING) ? Dans ce cas, puisque le processus ordinaire n’a aucune demande en CPU, le processus en temps réel peut-il s’exécuter pendant plus de 0,95 seconde ? ne peut pas. Dans les 0,05 secondes restantes, le noyau préfère garder le processeur inactif plutôt que de laisser le processus en temps réel l'utiliser. On voit que sched_rt_runtime_us et sched_rt_period_us sont très obligatoires.
Enfin, il y a le problème de plusieurs processeurs. Comme mentionné précédemment, pour chaque groupe de tâches, son entité de planification et sa file d'attente d'exécution sont conservées par processeur. sched_rt_runtime_us et sched_rt_period_us agissent sur l'entité de planification, donc s'il y a N CPU dans le système, la limite supérieure du CPU réel occupé par le processus en temps réel est N*sched_rt_runtime_us/sched_rt_period_us. Autrement dit, le processus en temps réel ne peut s'exécuter que pendant 0,95 seconde, malgré la limite par défaut d'une seconde. Mais pour un processus en temps réel, si le CPU a deux cœurs, il peut toujours répondre à sa demande d'occupation de 100 % du CPU (comme l'exécution d'une boucle infinie). Ensuite, il va de soi que 100 % du CPU occupé par ce processus temps réel devrait être composé de deux parties (chaque CPU en occupe une partie, mais pas plus de 95 %). Mais en fait, afin d'éviter une série de problèmes tels que le changement de contexte et l'invalidation du cache provoqués par la migration de processus entre les CPU, l'entité de planification sur un CPU peut emprunter du temps à l'entité de planification correspondante sur un autre CPU. Le résultat est que macroscopiquement, cela répond non seulement aux limites de sched_rt_runtime_us, mais évite également la migration des processus.
Ordonnancement groupé des processus ordinaires
Au début de l'article, il a été mentionné que deux utilisateurs A et B peuvent partager à parts égales les besoins en CPU même si le nombre de processus est différent. Cependant, la stratégie de planification de groupe pour les processus en temps réel ci-dessus ne semble pas pertinente. à cela. En fait, c'est l'exigence des processus ordinaires. Ce que le planificateur de groupe doit faire.
Par rapport aux processus en temps réel, la planification groupée des processus ordinaires n'est pas si particulière. Un groupe est traité presque comme la même entité qu'un processus. Il a sa propre priorité statique et le planificateur ajuste dynamiquement sa priorité. Pour un groupe, la priorité des processus dans le groupe n'affecte pas la priorité du groupe. La priorité de ces processus n'est prise en compte que lorsque le groupe est sélectionné par l'ordonnanceur.
Afin de définir la priorité du groupe, chaque task_group dispose d'un paramètre share (en parallèle des deux paramètres sched_rt_runtime_us et sched_rt_period_us mentionnés précédemment). Les partages ne sont pas des priorités, mais le poids de l'entité de planification (c'est ainsi que fonctionne le planificateur CFS. Il existe une correspondance biunivoque entre ce poids et cette priorité). La priorité d'un processus ordinaire sera également convertie en poids de son entité de planification correspondante, on peut donc dire que les actions représentent la priorité.
La valeur par défaut des actions est la même que le poids correspondant à la priorité par défaut des processus ordinaires. Ainsi, par défaut, le groupe et le processus partagent le processeur à parts égales.
Exemple
(Environnement : Ubuntu 10.04, noyau 2.6.32, Intel Core2 dual core)
Montez un groupe de contrôle qui divise uniquement les ressources CPU et créez deux sous-groupes grp_a et grp_b :
kouu@kouu-one:~$ sudo mkdir /dev/cgroup/cpu -p
kouu@kouu-one:~$ sudo mount -t cgroup cgroup -o cpu /dev/cgroup/cpu
kouu@kouu-one:/dev/cgroup/cpu$ cd /dev/cgroup/cpu/
kouu@kouu-one:/dev/cgroup/cpu$ mkdir grp_{a,b}
kouu@kouu-one:/dev/cgroup/cpu$ ls *
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release release_agent tasks
grp_a:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
grp_b:
cgroup.procs cpu.rt_period_us cpu.rt_runtime_us cpu.shares notify_on_release tasks
Ouvrez respectivement trois shells, ajoutez grp_a au premier et grp_b aux deux derniers :
kouu@kouu-one:~/test/rtproc$ cat ttt.sh echo $1 > /dev/cgroup/cpu/$2/tasks
(为什么要用ttt.sh来写cgroup下的tasks文件呢?因为写这个文件需要root权限,当前shell没有root权限,而sudo只能赋予被它执行的程序的root权限。其实sudo sh,然后再在新开的shell里面执行echo操作也是可以的。) kouu@kouu-one:~/test1$ echo $$ 6740 kouu@kouu-one:~/test1$ sudo sh ttt.sh $$ grp_a kouu@kouu-one:~/test2$ echo $$ 9410 kouu@kouu-one:~/test2$ sudo sh ttt.sh $$ grp_b kouu@kouu-one:~/test3$ echo $$ 9425 kouu@kouu-one:~/test3$ sudo sh ttt.sh $$ grp_b
回到cgroup目录下,确认这几个shell都被加进去了:
kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/tasks 6740 kouu@kouu-one:/dev/cgroup/cpu$ cat grp_b/tasks 9410 9425
现在准备在这三个shell下同时执行一个死循环的程序(a.out),为了避免多CPU带来的影响,将进程绑定到第二个核上:
#define _GNU_SOURCE
\#include
int main()
{
cpu_set_t set;
CPU_ZERO(&set);
CPU_SET(1, &set);
sched_setaffinity(0, sizeof(cpu_set_t), &set);
while(1);
return 0;
}
编译生成a.out,然后在前面的三个shell中分别运行。三个shell分别会fork出一个子进程来执行a.out,这些子进程都会继承其父进程的cgroup分组信息。然后top一下,可以观察到属于grp_a的a.out占了50%的CPU,而属于grp_b的两个a.out各占25%的CPU(加起来也是50%):
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 19854 kouu 20 0 1616 328 272 R 50 0.0 0:11.69 ./a.out 19857 kouu 20 0 1616 332 272 R 25 0.0 0:05.73 ./a.out 19860 kouu 20 0 1616 332 272 R 25 0.0 0:04.68 ./a.out ......
接下来再试试实时进程,把a.out程序改造如下:
#define _GNU_SOURCE
\#include
int main()
{
int prio = 50;
sched_setscheduler(0, SCHED_FIFO, (struct sched_param*)&prio);
while(1);
return 0;
}
然后设置grp_a的rt_runtime值:
kouu@kouu-one:/dev/cgroup/cpu$ sudo sh \# echo 300000 > grp_a/cpu.rt_runtime_us \# exit kouu@kouu-one:/dev/cgroup/cpu$ cat grp_a/cpu.rt_* 1000000 300000
现在的配置是每秒为一个周期,属于grp_a的实时进程每秒种只能执行300毫秒。运行a.out(设置实时进程需要root权限),然后top看看:
kouu@kouu-one:/dev/cgroup/cpu$ top -c ...... Cpu(s): 31.4%us, 0.7%sy, 0.0%ni, 68.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st ...... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 28324 root -51 0 1620 332 272 R 60 0.0 0:06.49 ./a.out ......
可以看到,CPU虽然闲着,但是却不分给a.out程序使用。由于双核的原因,a.out实际的CPU占用是60%而不是30%。
其他
前段时间,有一篇“200+行Kernel补丁显著改善Linux桌面性能”的新闻比较火。这个内核补丁能让高负载条件下的桌面程序响应延迟得到大幅度降低。其实现原理是,自动创建基于TTY的task_group,所有进程都会被放置在它所关联的TTY组中。通过这样的自动分组,就将桌面程序(Xwindow会占用一个TTY)和其他终端或伪终端(各自占用一个TTY)划分开了。终端上运行的高负载程序(比如make -j64)对桌面程序的影响将大大减少。(根据前面描述的普通进程的组调度的实现可以知道,如果一个任务给系统带来了很高的负载,只会影响到与它同组的进程。这个任务包含一个或是一万个TASK_RUNNING状态的进程,对于其他组的进程来说是没有影响的。)
本文浅析了linux组调度的方法,包括组调度的原理、实现、配置和优缺点等方面。通过了解和掌握这些知识,我们可以深入理解Linux进程调度的高级知识,从而更好地使用和优化Linux系统。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
CentOS a été interrompu, les alternatives comprennent: 1. Rocky Linux (meilleure compatibilité); 2. Almalinux (compatible avec CentOS); 3. Serveur Ubuntu (configuration requise); 4. Red Hat Enterprise Linux (version commerciale, licence payante); 5. Oracle Linux (compatible avec Centos et Rhel). Lors de la migration, les considérations sont: la compatibilité, la disponibilité, le soutien, le coût et le soutien communautaire.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Une fois CentOS arrêté, les utilisateurs peuvent prendre les mesures suivantes pour y faire face: sélectionnez une distribution compatible: comme Almalinux, Rocky Linux et CentOS Stream. Migrez vers les distributions commerciales: telles que Red Hat Enterprise Linux, Oracle Linux. Passez à Centos 9 Stream: Rolling Distribution, fournissant les dernières technologies. Sélectionnez d'autres distributions Linux: comme Ubuntu, Debian. Évaluez d'autres options telles que les conteneurs, les machines virtuelles ou les plates-formes cloud.
 Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Vs Code Système Exigences: Système d'exploitation: Windows 10 et supérieur, MacOS 10.12 et supérieur, processeur de distribution Linux: minimum 1,6 GHz, recommandé 2,0 GHz et au-dessus de la mémoire: minimum 512 Mo, recommandée 4 Go et plus d'espace de stockage: Minimum 250 Mo, recommandée 1 Go et plus d'autres exigences: connexion du réseau stable, xorg / wayland (Linux) recommandé et recommandée et plus
 Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Dépannage des étapes pour la construction d'image Docker échouée: cochez la syntaxe Dockerfile et la version de dépendance. Vérifiez si le contexte de construction contient le code source et les dépendances requis. Affichez le journal de construction pour les détails d'erreur. Utilisez l'option - cibler pour créer une phase hiérarchique pour identifier les points de défaillance. Assurez-vous d'utiliser la dernière version de Docker Engine. Créez l'image avec --t [Image-Name]: Debug Mode pour déboguer le problème. Vérifiez l'espace disque et assurez-vous qu'il est suffisant. Désactivez SELINUX pour éviter les interférences avec le processus de construction. Demandez de l'aide aux plateformes communautaires, fournissez Dockerfiles et créez des descriptions de journaux pour des suggestions plus spécifiques.
