

Dans les systèmes Linux, la gestion de la mémoire est l'une des parties les plus importantes du système d'exploitation. Il est chargé d'allouer une mémoire physique limitée à plusieurs processus et de fournir une abstraction de la mémoire virtuelle afin que chaque processus dispose de son propre espace d'adressage et puisse protéger et partager la mémoire. Cet article présentera les principes et méthodes de gestion de la mémoire Linux, y compris des concepts tels que la mémoire virtuelle, la mémoire physique, la mémoire logique et la mémoire linéaire, ainsi que le modèle de base, les appels système et les méthodes d'implémentation de la gestion de la mémoire Linux.
Cet article est basé sur des machines 32 bits et parle de quelques points de connaissances sur la gestion de la mémoire.
L'adresse virtuelle est également appelée adresse linéaire. Linux n'utilise pas de mécanisme de segmentation, donc l'adresse logique et l'adresse virtuelle (adresse linéaire) (En mode utilisateur, l'adresse logique en mode noyau fait spécifiquement référence à l'adresse avant le décalage linéaire mentionnée ci-dessous) sont le même concept. Il n'est pas nécessaire de mentionner l'adresse physique. La plupart des adresses virtuelles et physiques du noyau ne diffèrent que par un décalage linéaire. Les adresses virtuelles et physiques dans l'espace utilisateur sont mappées à l'aide de tables de pages à plusieurs niveaux, mais elles sont toujours appelées adresses linéaires.
Dans la structure x86, l'espace d'adressage virtuel du noyau Linuxest divisé en 0~3G comme espace utilisateur et 3~4G comme espace noyau (notez que l'adresse linéaire que le noyau peut utiliser n'est que de 1G). L'espace virtuel du noyau (3G~4G) est divisé en trois types de zones :
ZONE_DMA commence à partir de 16 Mo après la 3G
ZONE_NORMAL 16 Mo ~ 896 Mo
ZONE_HIGHMEM 896 Mo ~ 1 Go
Puisque les adresses virtuelles et physiques du noyau ne diffèrent que d'un seul décalage : adresse physique = adresse logique – 0xC0000000. Par conséquent, si l'espace du noyau 1G est entièrement utilisé pour le mappage linéaire, la mémoire physique ne peut évidemment accéder qu'à la plage 1G, ce qui est évidemment déraisonnable. HIGHMEM est destiné à résoudre ce problème. Il a spécialement ouvert une zone qui ne nécessite pas de mappage linéaire et peut être personnalisée de manière flexible pour accéder à une zone de mémoire physique supérieure à 1G. J'ai pris une photo sur Internet,
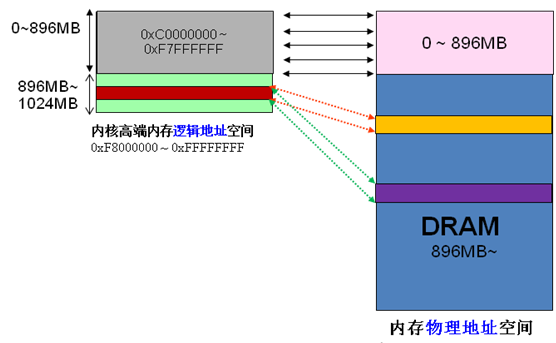
La division de la mémoire haut de gamme est comme indiqué ci-dessous,
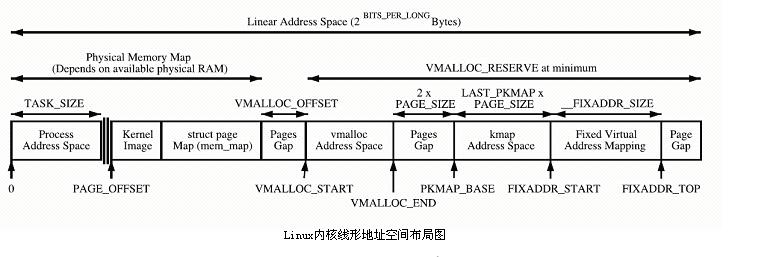
Le noyau mappe directement l'espace PAGE_OFFSET~VMALLOC_START, kmalloc et __get_free_page() allouent les pages ici. Les deux utilisent l'allocateur de dalle pour allouer directement des pages physiques, puis les convertir en adresses logiques (les adresses physiques sont continues). Convient pour allouer de petits segments de mémoire. Cette zone contient des ressources telles que l'image du noyau et la table de cadres de page physique mem_map.
L'espace de mappage dynamique du noyau VMALLOC_START~VMALLOC_END, utilisé par vmalloc, possède un grand espace représentable.
Espace de cartographie permanent du noyau PKMAP_BASE ~ FIXADDR_START, kmap
Espace de cartographie temporaire du noyau FIXADDR_START~FIXADDR_TOP, kmap_atomic
L'algorithme Buddy résout le problème de fragmentation externe. Le noyau gère les pages disponibles dans chaque zone, les organise dans une file d'attente de liste chaînée selon la taille de la puissance 2 (ordre) et les stocke dans le tableau free_area.
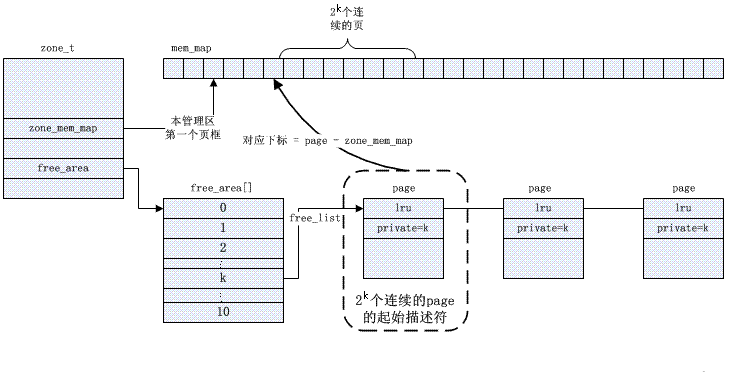
La gestion spécifique des copains est basée sur des bitmaps, et l'algorithme d'allocation et de recyclage des pages est décrit ci-dessous,
Description de l'exemple d'algorithme Buddy :
Supposons que notre mémoire système ne contienne que ***16****** pages*****RAM*. Étant donné que la RAM n'a que 16 pages, nous n'avons besoin d'utiliser que quatre niveaux (ordres) de bitmaps partenaires (car la taille maximale de la mémoire contiguë est de ******16****** pages***), comme indiqué ci-dessous.
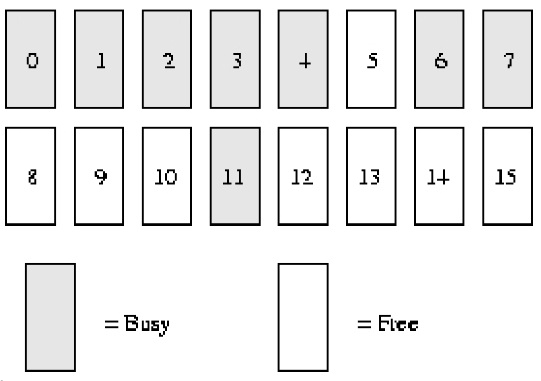

order(0) bimap a 8 bits (*** les pages peuvent avoir jusqu'à ******16****** pages, donc ******16/2***)
order(1) bimap a 4 bits (***order******(******0******)******bimap****** Il y a ******8****** ******bit****** bits***, donc 8/2);
C'est-à-dire que le premier bloc de commande (1) se compose de *** deux cadres de page ****page1* *** et ******page2***** et est composé de * commande (1) Le bloc 2 se compose de deux cadres de page ****page3**** et ******page4******, il y a un **** entre ces deux bloque **bit****bit*
order(2) bimap a 2 bits (***order******(******1******)******bimap****** Il y a ******4************bit******chiffres***, donc 4/2)
order(3) bimap a 1 bit (***order******(******2******)******bimap****** Il y a ******4************bit******chiffres***, donc 2/2)
Dans l'ordre (0), le premier bit représente les ****2****** pages***, et le deuxième bit représente les 2 pages suivantes. Comme la page 4 a été allouée et que la page 5 est libre, le troisième bit est 1.
De même dans l'ordre (1), la raison pour laquelle bit3 vaut 1 est qu'un partenaire est totalement gratuit (pages 8 et 9), mais son partenaire correspondant (pages 10 et 11) ne l'est pas, donc lorsque les pages seront recyclées à l'avenir, ils peuvent être fusionnés.
Processus d'attribution
***Lorsque nous avons besoin du bloc de page gratuit de ******order****** (******1******), *** effectuez les étapes suivantes :
1. La liste chaînée gratuite initiale est :
commande(0) : 5, 10
commande(1) : 8 [8,9]
commande(2) : 12 [12,13,14,15]
commande(3):
2. À partir de la liste chaînée gratuite ci-dessus, nous pouvons voir qu'il y a * un bloc de page gratuit sur la liste chaînée de commande (1). Attribuez-le à l'utilisateur et supprimez-le de la liste chaînée. *
3. Lorsque nous avons besoin d'un autre bloc de commande (1), nous commençons également à numériser à partir de la liste gratuite de commande (1).
4. S'il n'y a pas de bloc de page gratuit*** sur ***commande****** (******1******), alors nous passerons à un niveau supérieur (commande ) Trouvez en haut, commandez(2).
5. À l'heure actuelle (il n'y a pas de bloc de page gratuit sur ***commande****** (******1*****)*), il y a un bloc de page gratuit, qui est l'esclave la page 12 démarre. Le bloc de page est divisé en deux blocs de page d'ordre légèrement plus petit (1), [12, 13] et [14, 15]. [14, 15] Le bloc page est ajouté à la commande****** (******1*****) liste gratuite*, et en même temps [12 ****** ,******13]****Le bloc de page est renvoyé à l'utilisateur. *
6. La dernière liste chaînée gratuite est :
commande(0) : 5, 10
commande(1) : 14 [14,15]
commande(2):
commande(3):
Processus de recyclage
***Lorsque nous recyclons la page ******11****** (******commande 0****), les étapes suivantes sont effectuées : *
***1******, ****** a trouvé un partenaire dans ******ordre****** (******0******) L'image représente le bit **** de la page ******11****** Le calcul utilise les informations publiques suivantes : *
.*index =* *page_idx >> (commande + 1)*
*= 11 >> (0 + 1)*
*=5*
2. Vérifiez l'étape ci-dessus pour calculer la valeur du bit correspondant dans le bitmap. Si la valeur du bit est 1, il y a un partenaire inactif proche de nous. La valeur de Bit5 est 1 (notez qu'il part du bit0, Bit5 est le 6ème bit) car sa page partenaire 10 est libre.
3. Maintenant, nous remettons la valeur de ce bit à 0, car les deux partenaires (page 10 et page 11) sont complètement inactifs à ce moment-là.
4. Nous supprimons la page 10 de la liste des commandes gratuites (0).
5. A ce moment, nous effectuons d'autres opérations sur les 2 pages libres (pages 10 et 11, commande (1)).
6. La nouvelle page gratuite commence à partir de la page 10, nous trouvons donc son index dans le bitmap partenaire de order(1) pour voir s'il existe un partenaire inactif pour d'autres opérations de fusion. En utilisant la société calculée à la première étape, nous obtenons le bit 2 (chiffre 3).
7. Le bit 2 (bitmap order(1)) vaut également 1 car ses blocs de pages partenaires (pages 8 et 9) sont gratuits.
8. Réinitialisez la valeur de bit2 (bitmap order(1)), puis supprimez le bloc de page libre dans la liste chaînée order(1).
9. Maintenant, nous fusionnons en blocs libres de 4 tailles de page (à partir de la page 8), entrant ainsi dans un autre niveau. Recherchez la valeur du bit correspondant au bitmap partenaire dans l'ordre (2), qui est le bit1, et la valeur est 1. Elle doit être davantage fusionnée (la raison est la même que ci-dessus).
10. Supprimez le bloc de page gratuit (à partir de la page 12) de la liste chaînée oder(2), puis fusionnez davantage ce bloc de page avec le bloc de page obtenu par la fusion précédente. Nous obtenons maintenant un bloc de pages gratuites à partir de la page 8 et de taille 8 pages.
11. Nous entrons dans un autre niveau, commande (3). Son indice de bit est 0 et sa valeur est également 0. Cela signifie que les partenaires correspondants ne sont pas tous libres et qu'il n'y a donc aucune possibilité de fusion ultérieure. Nous définissons uniquement ce bit sur 1, puis plaçons les blocs de pages libres fusionnés dans la liste chaînée gratuite order(3).
12. Finalement, nous obtenons un bloc gratuit de 8 pages,

les efforts de mon copain pour éviter les débris internes
La fragmentation de la mémoire physique a toujours été l'une des faiblesses du système d'exploitation Linux. Bien que de nombreuses solutions aient été proposées, aucune méthode ne peut la résoudre complètement. L'allocation de mémoire est l'une des solutions. Nous savons que les fichiers disque ont également des problèmes de fragmentation, mais la fragmentation des fichiers disque ne fera que ralentir la vitesse de lecture et d'écriture du système et ne provoquera pas d'erreurs fonctionnelles. De plus, nous pouvons également fragmenter le disque sans affecter le fonctionnement du disque. rangé. La fragmentation de la mémoire physique est complètement différente. La mémoire physique et le système d'exploitation sont si étroitement intégrés qu'il nous est difficile de déplacer la mémoire physique pendant l'exécution (à ce stade, la fragmentation du disque est beaucoup plus facile ; en fait, Mel Gorman a le patch de compactage de la mémoire. a été soumis, mais il n'a pas encore été reçu par le noyau principal). Par conséquent, la direction de la solution est principalement axée sur la prévention des débris. Lors du développement du noyau 2.6.24, une fonctionnalité du noyau pour empêcher la fragmentation a été ajoutée au noyau principal. Avant de comprendre les principes de base de l'anti-fragmentation, classifiez d'abord les pages mémoire :
1. Pages inamovibles : l'emplacement dans la mémoire doit être fixe et ne peut pas être déplacé vers d'autres emplacements. La plupart des pages allouées par le noyau principal entrent dans cette catégorie.
2. Page récupérable récupérable : Elle ne peut pas être déplacée directement, mais elle peut être recyclée, car la page peut également être reconstruite à partir de certaines sources. Par exemple, les données du fichier de mappage appartiennent à cette catégorie. selon certaines règles.
3. Page mobile : peut être déplacée à volonté. Les pages appartenant aux applications de l'espace utilisateur appartiennent à ce type de page. Elles sont mappées via la table des pages, il suffit donc de mettre à jour les entrées de la table des pages et de copier les données vers le nouvel emplacement. peut être utilisé par plusieurs Le partage de processus correspond à plusieurs entrées de table de pages.
Le moyen d'éviter la fragmentation est de placer ces trois types de pages sur des listes chaînées différentes pour éviter que différents types de pages n'interfèrent les unes avec les autres. Considérons la situation où une page immobile se trouve au milieu d'une page mobile. Après avoir déplacé ou recyclé ces pages, cette page immobile nous empêche d'obtenir un espace libre physique continu plus grand.
De plus, Chaque zone possède sa propre file d'attente des pages sales désactivée, qui correspond à deux files d'attente globales inter-zones, la file d'attente des pages sales désactivée et la file d'attente active. Ces files d'attente sont liées via le pointeur lru de la structure de la page.
Réflexion : Quelle est la signification de la file d'attente de désactivation (voir
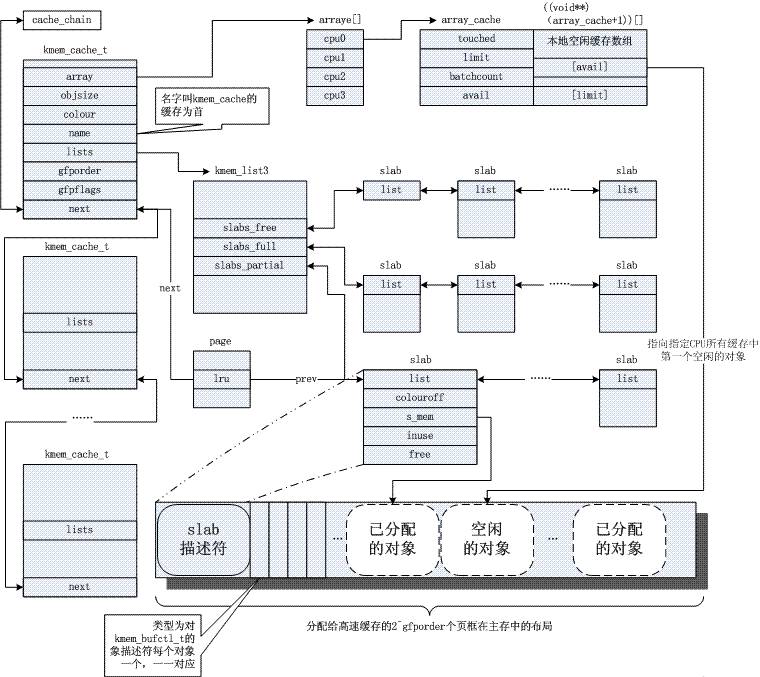
allocateur de dalle : résoudre le problème de fragmentation interne
Le noyau repose souvent sur l'allocation de petits objets, qui sont alloués plusieurs fois au cours de la durée de vie du système. L'allocateur de cache slab fournit cette fonctionnalité en mettant en cache des objets de taille similaire (beaucoup plus petite qu'une page), évitant ainsi le problème courant de fragmentation interne. Voici pour l'instant une photo. Concernant son principe, merci de vous référer à la référence commune 3. De toute évidence, le mécanisme de dalle est basé sur l’algorithme de buddy, et le premier est un raffinement du second.
4. Mécanisme de recyclage/mise au point des pages
Utilisation de la page À propos
Dans certains articles précédents, nous avons appris que le noyau Linux alloue des pages dans de nombreuses situations.
1. Le code du noyau peut appeler des fonctions telles que alloc_pages pour allouer directement des pages du système partenaire qui gère les pages physiques (la liste libre free_area sur la zone de gestion) (voir « Une brève analyse de la gestion de la mémoire du noyau Linux »). Par exemple : le pilote peut allouer le cache de cette manière ; lors de la création d’un processus, le noyau alloue également deux pages consécutives de cette manière en tant que structure thread_info et pile du noyau du processus ; L'allocation de pages à partir du système partenaire est la méthode d'allocation de pages la plus basique, et d'autres allocations de mémoire sont basées sur cette méthode ;
2. De nombreux objets du noyau sont gérés à l'aide du mécanisme slab (voir « Une brève analyse de Linux Slub Allocator »). Slab est équivalent à un pool d'objets, qui « formate » les pages en « objets » et les stocke dans le pool pour un usage humain. Lorsqu'il n'y a pas suffisamment d'objets dans la dalle, le mécanisme de la dalle allouera automatiquement les pages du système partenaire et les « formatera » en nouveaux objets
;
3. Cache disque (voir « Une brève analyse de la lecture et de l'écriture des fichiers du noyau Linux »). Lors de la lecture et de l'écriture de fichiers, les pages sont allouées depuis le système partenaire et utilisées pour le cache disque, puis les données des fichiers sur le disque sont chargées dans la page de cache disque correspondante
;
4. Cartographie de la mémoire. Ce que l'on appelle ici le mappage de la mémoire fait en fait référence au mappage des pages mémoire vers l'espace utilisateur pour une utilisation par les processus utilisateur. Chaque vma dans la structure task_struct->mm du processus représente un mappage, et la véritable implémentation du mappage est qu'après que le programme utilisateur a accédé à l'adresse mémoire correspondante, la page provoquée par l'exception de défaut de page est allouée et la table des pages est mis à jour (Voir "Une brève analyse de la gestion de la mémoire du noyau Linux");
Lorsqu’il y a allocation de pages, il y aura recyclage de pages. Les méthodes de recyclage de pages peuvent être grossièrement divisées en deux types :
L’une est la version active. Tout comme le programme utilisateur libère la mémoire une fois allouée via la fonction malloc via la fonction free, l'utilisateur de la page sait clairement quand la page sera utilisée et quand elle n'est plus nécessaire.
Les deux premières méthodes d'allocation mentionnées ci-dessus sont généralement activement publiées par le programme du noyau. Pour les pages allouées directement depuis le système partenaire, elles sont activement libérées par l'utilisateur à l'aide de fonctions telles que free_pages. Une fois la page libérée, elle est directement libérée vers le système partenaire ; les objets alloués depuis le slab (à l'aide de la fonction kmem_cache_alloc) le sont également. publié par l'utilisateur Activement publié (en utilisant la fonction kmem_cache_free).
Une autre façon de recycler les pages consiste à utiliser l'algorithme de recyclage des cadres de page (PFRA) fourni par le noyau Linux. Les utilisateurs de la page traitent généralement la page comme une sorte de cache pour améliorer l'efficacité opérationnelle du système. C'est bien que le cache existe toujours, mais si le cache disparaît, cela ne provoquera aucune erreur, seule l'efficacité sera affectée. L'utilisateur de la page ne sait pas clairement quand ces pages mises en cache sont mieux conservées et quand elles sont mieux recyclées, ce qui relève du PFRA.
Les deux dernières méthodes d'allocation mentionnées ci-dessus sont généralement recyclées par PFRA (ou recyclées de manière synchrone par des processus tels que la suppression de fichiers et les sorties de processus).
Pour les deux premières méthodes d'allocation de pages mentionnées ci-dessus (allocation directe de pages et allocation d'objets via slab), il peut également être nécessaire d'effectuer un recyclage via PFRA.
Les utilisateurs de la page peuvent enregistrer une fonction de rappel auprès de PFRA (en utilisant la fonction register_shrink). Ces fonctions de rappel sont ensuite appelées par PFRA aux moments appropriés pour déclencher le recyclage des pages ou objets correspondants.
L’un des plus courants est le recyclage des dents. Dentry est un objet alloué par dalle et utilisé pour représenter la structure de répertoires du système de fichiers virtuel. Lorsque le nombre de références du dentry est réduit à 0, le dentry n'est pas libéré directement, mais est mis en cache dans une liste chaînée LRU pour une utilisation ultérieure. (Voir "Une brève analyse du système de fichiers virtuel du noyau Linux".)
Le dentry dans cette liste chaînée LRU doit éventuellement être recyclé, donc lorsque le système de fichiers virtuel est initialisé, register_shrinker est appelé pour enregistrer la fonction de recyclage Shrink_dcache_memory.
Les objets superblocs de tous les systèmes de fichiers du système sont stockés dans une liste chaînée. La fonction Shrink_dcache_memory analyse cette liste chaînée, obtient le LRU des entrées inutilisées de chaque superbloc, puis en récupère certaines des entrées les plus anciennes. Au fur et à mesure que le dentry est libéré, l'inode correspondant sera déréférencé, ce qui peut également entraîner la libération de l'inode.
Une fois l'inode libéré, il est également placé dans une liste chaînée inutilisée. Lors de l'initialisation, le système de fichiers virtuel appelle également register_shrinker pour enregistrer la fonction de rappel Shrink_icache_memory afin de recycler ces inodes inutilisés, afin que le cache disque associé à l'inode soit également libéré.
De plus, pendant le fonctionnement du système, il peut y avoir de nombreux objets inactifs dans la dalle (par exemple, après le passage de la pointe d'utilisation d'un certain objet). La fonction cache_reap de PFRA est utilisée pour recycler ces objets inactifs redondants. Si certains objets inactifs peuvent être restaurés sur une page, la page peut être renvoyée vers le système partenaire ;
Ce que fait la fonction cache_reap est simple à dire. Toutes les structures kmem_cache stockant les pools d'objets dans le système sont connectées dans une liste chaînée. La fonction cache_reap analyse chaque pool d'objets, puis recherche les pages pouvant être recyclées et les recycle. (Bien sûr, le processus lui-même est un peu plus compliqué.)
À propos de la cartographie de la mémoire
Comme mentionné précédemment, le cache disque et le mappage mémoire sont généralement recyclés par PFRA. Le recyclage des deux par PFRA est très similaire. En fait, le cache disque est probablement mappé sur l'espace utilisateur. Voici une brève introduction à la cartographie de la mémoire :
Le mappage de fichiers signifie que le vma représentant ce mappage correspond à une certaine zone d'un fichier. Cette méthode de mappage est relativement rarement utilisée explicitement par les programmes en mode utilisateur. Les programmes en mode utilisateur sont généralement habitués à ouvrir un fichier, puis à lire/écrire le fichier.
En fait, le programme utilisateur peut également utiliser l'appel système mmap pour mapper une certaine partie d'un fichier en mémoire (correspondant à un vma), puis lire et écrire le fichier en accédant à la mémoire. Bien que les programmes utilisateur utilisent rarement cette méthode, les processus utilisateur regorgent de tels mappages : le code exécutable (y compris les fichiers exécutables et les fichiers de bibliothèque lib) exécuté par le processus est mappé de cette manière.
Dans l'article « Une brève analyse de la lecture et de l'écriture des fichiers du noyau Linux », nous n'avons pas abordé la mise en œuvre du mappage de fichiers. En fait, le mappage de fichiers mappe directement les pages du cache disque du fichier à l'espace utilisateur (on peut voir que les pages mappées par le fichier sont un sous-ensemble des pages du cache disque), et les utilisateurs peuvent les lire et les écrire avec 0 copies. Lors de l'utilisation de la lecture/écriture, une copie se produira entre la mémoire de l'espace utilisateur et le cache disque.
Le mappage anonyme est relatif au mappage de fichiers, ce qui signifie que le vma de ce mappage ne correspond pas à un fichier. Pour l'allocation de mémoire ordinaire dans l'espace utilisateur (espace tas, espace pile), ils appartiennent tous à un mappage anonyme.
Évidemment, plusieurs processus peuvent mapper vers le même fichier via leurs propres mappages de fichiers (par exemple, la plupart des processus mappent le fichier so de la bibliothèque libc) ; En fait, plusieurs processus peuvent être mappés sur la même mémoire physique via leurs propres mappages anonymes. Cette situation est causée par le processus parent-enfant partageant la mémoire physique d'origine (copie sur écriture) après le fork.
Quelles pages doivent être recyclées
En ce qui concerne le recyclage, les pages du cache disque (y compris les pages mappées sur des fichiers) peuvent être supprimées et recyclées. Mais si la page est sale, elle doit être réécrite sur le disque avant d'être supprimée.
Les pages mappées anonymes ne peuvent pas être supprimées, car elles contiennent des données utilisées par le programme utilisateur et les données ne peuvent pas être restaurées après avoir été supprimées. En revanche, les données des pages de cache disque elles-mêmes sont enregistrées sur le disque et peuvent être reproduites.
Par conséquent, si vous souhaitez recycler des pages mappées de manière anonyme, vous devez d'abord vider les données des pages sur le disque. Il s'agit d'un échange de pages (swap). Évidemment, le coût de l’échange de pages est relativement plus élevé.
Les pages mappées de manière anonyme peuvent être échangées vers un fichier d'échange ou une partition d'échange sur le disque (une partition est un périphérique et un périphérique est également un fichier. Elle est donc collectivement appelée fichier d'échange ci-dessous).
Bien qu'il existe de nombreuses pages qui peuvent être recyclées, il est évident que PFRA devrait recycler/échanger le moins possible (car ces pages doivent être restaurées à partir du disque, ce qui nécessite beaucoup de coûts). Par conséquent, PFRA ne récupère/échange qu’une partie des pages rarement utilisées lorsque cela est nécessaire, et le nombre de pages récupérées à chaque fois est une valeur empirique : 32.
Ainsi, toutes ces pages de cache disque et pages mappées anonymes sont placées dans un ensemble de LRU. (En fait, chaque zone possède un ensemble de ces LRU, et les pages sont placées dans les LRU de leurs zones correspondantes.)
Un groupe de LRU se compose de plusieurs paires de listes chaînées, y compris des listes chaînées de pages de cache disque (y compris des pages de mappage de fichiers), des listes chaînées de pages de mappage anonymes, etc. Une paire de listes chaînées est en fait deux listes chaînées : la première est la page récemment utilisée et la seconde est la page récemment inutilisée.
Lors du recyclage des pages, PFRA doit faire deux choses. L'une consiste à déplacer la page la moins récemment utilisée de la liste chaînée active vers la liste chaînée inactive. L'autre consiste à essayer de recycler la page la moins récemment utilisée dans la liste chaînée inactive.
Déterminer le moins récemment utilisé
Il y a maintenant une question : comment déterminer quelles pages de la liste active/inactive sont les moins récemment utilisées ?
Une approche consiste à trier et, lorsqu'on accède à une page, à la déplacer vers la fin de la liste chaînée (en supposant que le recyclage commence en tête). Mais cela signifie que la position de la page dans la liste chaînée peut être déplacée fréquemment et qu'elle doit être verrouillée avant de se déplacer (il peut y avoir plusieurs processeurs qui y accèdent en même temps), ce qui a un grand impact sur l'efficacité.
Le noyau Linux adopte la méthode de marquage et de classement. Lorsqu'une page se déplace entre les listes chaînées actives et inactives, elle est toujours placée à la fin de la liste chaînée (comme ci-dessus, en supposant que le recyclage commence par la tête).
Lorsque les pages ne sont pas déplacées entre les listes chaînées, leur ordre n'est pas ajusté. Au lieu de cela, la balise d'accès est utilisée pour indiquer si la page vient d'être consultée. Si une page avec une balise d'accès définie dans la liste chaînée inactive est à nouveau consultée, elle sera déplacée vers la liste chaînée active et la balise d'accès sera effacée. (En fait, afin d'éviter les conflits d'accès, la page ne passe pas directement de la liste chaînée inactive à la liste chaînée active, mais il existe une structure intermédiaire pagevec utilisée comme tampon pour éviter de verrouiller la liste chaînée.)
Il existe deux types de balises d'accès sur la page. L'une est la balise PG_referenced placée dans page->flags. Cette balise est définie lors de l'accès à la page. Pour les pages du cache disque (non mappées), le processus utilisateur y accède via des appels système tels que la lecture et l'écriture. Le code d'appel système définira l'indicateur PG_referenced de la page correspondante.
Pour les pages mappées en mémoire, les processus utilisateur peuvent y accéder directement (sans passer par le noyau), donc l'indicateur d'accès dans ce cas n'est pas défini par le noyau, mais par mmu. Après avoir mappé l'adresse virtuelle sur une adresse physique, mmu définira un indicateur d'accès sur l'entrée correspondante de la table de pages pour indiquer que la page a été accédée. (De la même manière, mmu placera un drapeau sale sur l'entrée du tableau des pages correspondant à la page en cours d'écriture, indiquant que la page est une page sale.)
La balise d'accès de la page (y compris les deux balises ci-dessus) sera effacée lors du processus de recyclage des pages par PFRA, car la balise d'accès doit évidemment avoir une période de validité, et le cycle d'exécution de PFRA représente cette période de validité. La marque PG_referenced dans page->flags peut être effacée directement, tandis que le bit accédé dans l'entrée de la table des pages ne peut être effacé qu'après avoir trouvé son entrée correspondante dans la table des pages (voir "Mappage inverse" ci-dessous).
Alors, comment le processus de recyclage analyse-t-il la liste chaînée LRU ?
Puisqu'il existe plusieurs groupes de LRU (il existe plusieurs zones dans le système et chaque zone comporte plusieurs groupes de LRU), si PFRA analyse tous les LRU pour chaque recyclage afin de trouver les pages qui valent le plus la peine d'être recyclées, l'efficacité de l'algorithme de recyclage sera évident.
La méthode d'analyse utilisée par le noyau Linux PFRA consiste à définir une priorité d'analyse et à utiliser cette priorité pour calculer le nombre de pages à analyser sur chaque LRU. L'ensemble de l'algorithme de recyclage commence par la priorité la plus basse, analyse les pages les moins récemment utilisées dans chaque LRU, puis tente de les récupérer. Si un nombre suffisant de pages a été recyclé après une numérisation, le processus de recyclage se termine. Sinon, augmentez la priorité et réanalysez jusqu'à ce qu'un nombre suffisant de pages ait été récupéré. Et si un nombre suffisant de pages ne peut pas être recyclé, la priorité sera augmentée au maximum, c'est-à-dire que toutes les pages seront numérisées. A ce moment, même si le nombre de pages recyclées est encore insuffisant, le processus de recyclage prendra fin.
Chaque fois qu'un LRU est scanné, le nombre de pages correspondant à la priorité actuelle est obtenu à partir de la liste chaînée active et de la liste chaînée inactive, puis ces pages sont traitées : si la page ne peut pas être recyclée (comme être conservée ou verrouillée ), il est remis Correspondant à la tête de la liste chaînée (comme ci-dessus, en supposant que le recyclage commence par la tête sinon si le flag d'accès de la page est activé, effacez le flag et remettez la page en fin de) ; la liste chaînée correspondante (comme ci-dessus, en supposant que le recyclage commence par la tête) ; sinon la page Elle sera déplacée de la liste chaînée active vers la liste chaînée inactive ou recyclée de la liste chaînée inactive.
Les pages numérisées sont déterminées selon que l'indicateur d'accès est défini ou non. Alors, comment cette balise d’accès est-elle définie ? Il existe deux manières. L'une est que lorsque l'utilisateur accède au fichier via des appels système tels que la lecture/écriture, le noyau exploite les pages dans le cache disque et définit les indicateurs d'accès de ces pages (définis dans la structure des pages) ; est que le processus accède directement au fichier lorsqu'une page a été mappée, mmu ajoutera automatiquement une balise d'accès (définie dans le pte de la table des pages) à l'entrée correspondante de la table des pages. Le jugement sur l’étiquette d’accès est basé sur ces deux éléments d’information. (Étant donné une page, plusieurs PTE peuvent y faire référence. Comment savoir si ces PTE ont des balises d'accès définies ? Ensuite, vous devez trouver ces PTE via le mappage inversé. Ce sera discuté ci-dessous.)
PFRA n'a pas tendance à recycler les pages mappées de manière anonyme à partir de la liste chaînée active, car la mémoire utilisée par les processus utilisateur est généralement relativement petite et le recyclage nécessite un échange, ce qui est coûteux. Ainsi, lorsqu'il reste beaucoup de mémoire restante et une faible proportion de mappage anonyme, les pages de la liste chaînée active correspondant au mappage anonyme ne seront pas recyclées. (Et si la page a été placée dans la liste inactive, vous n'avez plus à vous en soucier.)
Cartographie inversée
Ainsi, lors du processus de recyclage des pages géré par PFRA, certaines pages de la liste inactive du LRU peuvent être sur le point d'être recyclées.
Si la page n'est pas mappée, elle peut être recyclée directement vers le système partenaire (pour les pages sales, réécrivez-les d'abord puis recyclez-les). Sinon, il reste encore une chose gênante à régler. Étant donné qu'une certaine entrée de table de pages du processus utilisateur fait référence à cette page, avant de recycler la page, l'entrée de table de pages qui y fait référence doit recevoir une explication.
Alors, la question se pose : comment le noyau sait-il quelles entrées de table de pages sont référencées par cette page ? Pour ce faire, le noyau établit un mappage inverse des pages vers les entrées de la table des pages.
Le vma correspondant à une page mappée peut être trouvé via le mappage inverse, et la table de pages correspondante peut être trouvée via vma->vm_mm->pgd. Obtenez ensuite l’adresse virtuelle de la page via page->index. Recherchez ensuite l’entrée de table de pages correspondante dans la table de pages via l’adresse virtuelle. (La balise accessible dans l'entrée du tableau des pages mentionnée précédemment est obtenue grâce au mappage inversé.)
Dans la structure de page correspondant à la page, si le bit le plus bas de page->mapping est défini, c'est une page de mappage anonyme, et page->mapping pointe vers une structure anon_vma ; sinon, c'est une page de mappage de fichiers, et page->mapping est la structure d'espace d'adresse correspondant au fichier. (Évidemment, lorsque la structure anon_vma et la structure address_space sont allouées, les adresses doivent être alignées, au moins le bit le plus bas doit être 0.)
Pour les pages mappées de manière anonyme, la structure anon_vma sert d'en-tête de liste chaînée, connectant tous les vmas mappant cette page via le pointeur de liste chaînée vma->anon_vma_node. Chaque fois qu'une page est (anonymement) mappée à un espace utilisateur, le vma correspondant est ajouté à cette liste chaînée.
Pour les pages mappées sur des fichiers, la structure d'espace d'adresse gère non seulement une arborescence de base pour stocker les pages de cache disque, mais gère également une arborescence de recherche prioritaire pour tous les vmas mappés au fichier. Étant donné que ces VMA mappés par fichiers ne mappent pas nécessairement l’intégralité du fichier, il est possible que seule une partie du fichier soit mappée. Par conséquent, en plus d’indexer tous les vma mappés, cet arbre de recherche prioritaire doit également savoir quelles zones du fichier sont mappées à quel vma. Chaque fois qu'une page (fichier) est mappée à un espace utilisateur, le vma correspondant est ajouté à cette arborescence de recherche prioritaire. Par conséquent, étant donné une page sur le cache disque, la position de la page dans le fichier peut être obtenue via page->index, et tous les vmas mappés sur cette page peuvent être trouvés via l'arborescence de recherche prioritaire.
Dans les deux étapes ci-dessus, la page magique->index fait deux choses : obtenir l'adresse virtuelle de la page et obtenir l'emplacement de la page dans le cache disque de fichiers.
vma->vm_start enregistre la première adresse virtuelle du vma, vma->vm_pgoff enregistre le décalage du vma dans le fichier de mappage correspondant (ou mémoire partagée), et page->index enregistre la page dans le fichier (ou mémoire partagée) décalé en .
Le décalage de la page dans vma peut être obtenu via vma->vm_pgoff et page->index, et l'adresse virtuelle de la page peut être obtenue en ajoutant vma->vm_start et la page dans le cache disque de fichiers peut être obtenue via ; page->index.
Échange de pages entrantes et sortantes
Après avoir trouvé l'entrée de table de pages qui fait référence à la page à recycler, pour le mappage de fichiers, l'entrée de table de pages qui fait référence à la page peut être effacée directement. Lorsque l'utilisateur accède à nouveau à cette adresse, une exception de défaut de page est déclenchée. Le code de gestion des exceptions réaffecte alors une page et lit les données correspondantes sur le disque (peut-être que la page est déjà dans le cache disque correspondant. Parce que d'autres processus y ont accédé. d'abord). C'est la même chose que la première fois que la page est consultée après le mappage ;
Pour le mappage anonyme, la page est d'abord réécrite dans le fichier d'échange, puis l'index de la page dans le fichier d'échange doit être enregistré dans l'entrée de la table des pages.
Il y a un bit présent dans l’entrée de la table des pages. Si ce bit est effacé, le mmu considère l’entrée de la table des pages comme invalide. Lorsque l'entrée de la table des pages n'est pas valide, les autres bits ne sont pas pris en charge par mmu et peuvent être utilisés pour stocker d'autres informations. Ils sont utilisés ici pour stocker l'index de la page dans le fichier d'échange (en fait le numéro du fichier d'échange + le numéro d'index dans le fichier d'échange).
Le processus d'échange de pages mappées de manière anonyme vers le fichier d'échange (le processus d'échange) est très similaire au processus d'écriture de pages sales dans le cache disque dans le fichier.
Le fichier d'échange a également sa structure d'espace d'adresse correspondante. Lors de l'échange, les pages mappées de manière anonyme sont d'abord placées dans le cache disque correspondant à cet espace d'adresse, puis réécrites dans le fichier d'échange tout comme les pages sales sont réécrites. Une fois la réécriture terminée, la page est libérée (rappelez-vous, notre objectif est de libérer la page).
Alors pourquoi ne pas simplement réécrire la page dans le fichier d'échange au lieu de passer par le cache disque ? Étant donné que cette page peut avoir été mappée plusieurs fois, il est impossible de modifier les entrées de table de pages correspondantes dans les tables de pages de tous les processus utilisateur en même temps (les modifier avec l'index de la page dans le fichier d'échange), donc pendant le processus de la page étant libérée, la page est temporairement placée sur le cache disque.
Toutes les modifications apportées aux entrées de la table des pages ne réussissent pas (par exemple, la page a été consultée à nouveau avant la modification, il n'est donc pas nécessaire de recycler la page maintenant), donc le temps nécessaire pour que la page soit placée dans le cache disque peut être aussi très long.
De même, le processus de lecture des pages mappées de manière anonyme à partir du fichier d'échange (le processus d'échange) est également très similaire au processus de lecture des données du fichier.
Accédez d’abord au cache disque correspondant pour voir si la page est là. Sinon, lisez-la dans le fichier d’échange. Les données du fichier sont également lues dans le cache disque, puis l'entrée de la table des pages correspondante dans la table des pages du processus utilisateur sera réécrite pour pointer directement vers cette page.
Cette page ne peut pas être récupérée immédiatement du cache disque, car si d'autres processus utilisateur sont également mappés sur cette page (leurs entrées de table de pages correspondantes ont été modifiées pour être indexées dans le fichier d'échange), ils peuvent également y faire référence. . La page ne peut pas être récupérée du cache disque tant qu'aucune autre entrée de la table des pages ne fait référence à l'index du fichier d'échange.
La dernière tuerie sûre
Comme mentionné précédemment, PFRA a peut-être analysé tous les LRU et n'a toujours pas pu récupérer les pages requises. De même, les pages ne peuvent pas être recyclées en slab, dentry cache, inode cache, etc.
À ce stade, que se passe-t-il si un certain morceau de code du noyau doit obtenir une page (sans page, le système peut planter) ? PFRA n'a eu d'autre choix que de recourir au dernier recours - MOO (mémoire insuffisante). Le soi-disant MOO consiste à trouver le processus le moins important, puis à le tuer. Soulagez la pression du système en libérant les pages mémoire occupées par ce processus.
5. Architecture de gestion de la mémoire
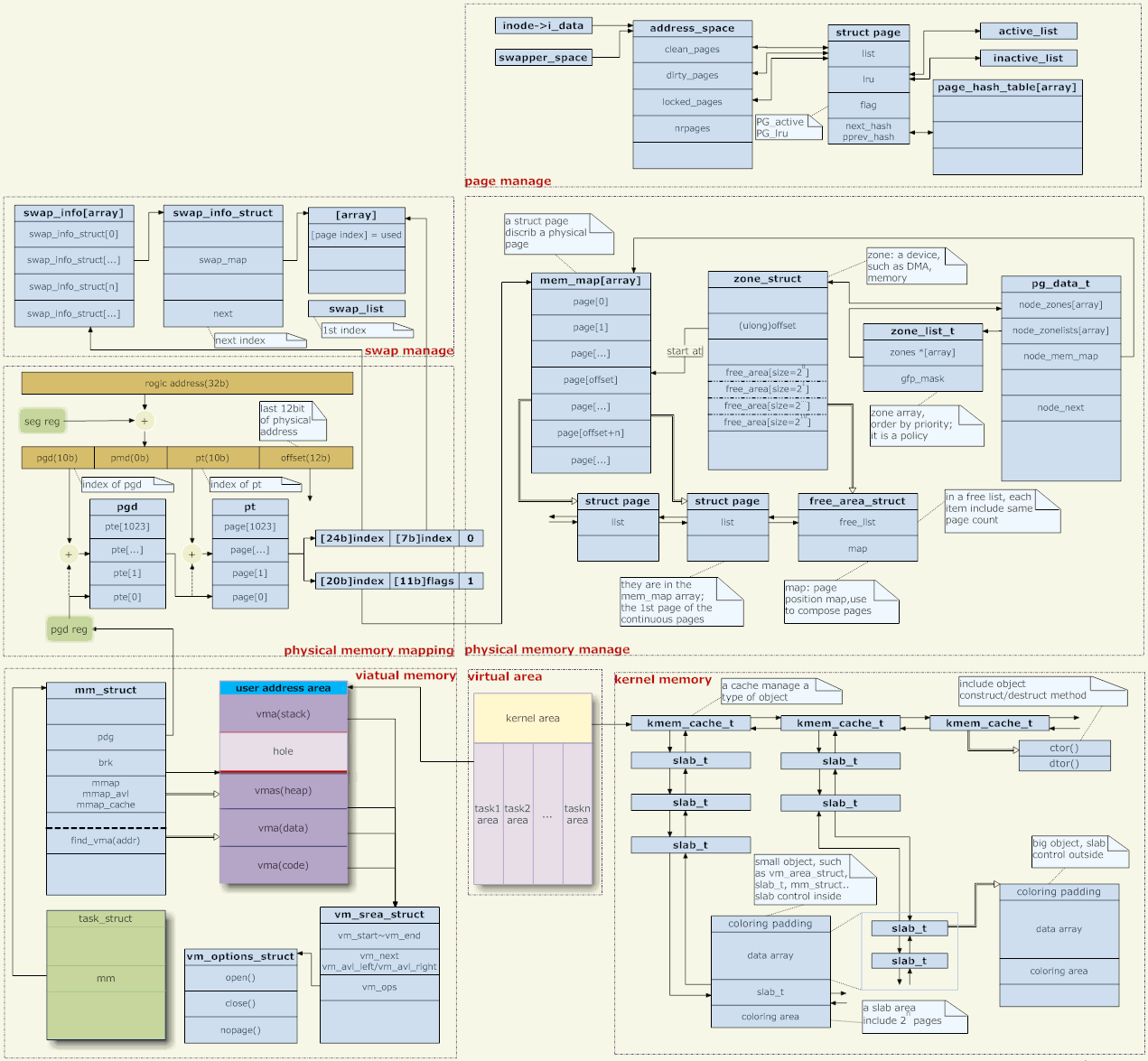
Quelques mots sur la photo ci-dessus,
Mappage d'adresses
Le noyau Linux utilise la gestion de la mémoire des pages. L'adresse mémoire donnée par l'application est une adresse virtuelle, qui doit être transformée niveau par niveau à travers plusieurs niveaux de tables de pages avant de devenir une véritable adresse physique.
Pensez-y, le mappage d’adresses fait toujours peur. Lors de l'accès à un espace mémoire représenté par une adresse virtuelle, plusieurs accès mémoire sont nécessaires pour obtenir les entrées de la table des pages utilisées pour la conversion dans chaque niveau de la table des pages (la table des pages est stockée dans la mémoire) avant que le mappage puisse être terminé. En d'autres termes, pour réaliser un accès mémoire, la mémoire est effectivement accédée N+1 fois (N = niveau table des pages), et N opérations d'addition doivent être effectuées.
Par conséquent, le mappage d'adresses doit être pris en charge par le matériel, et la mmu (unité de gestion de la mémoire) est ce matériel. Et un cache est nécessaire pour enregistrer la table des pages. Ce cache est le TLB (Translation lookaside buffer).
Malgré cela, le mappage d’adresses entraîne encore une surcharge considérable. En supposant que la vitesse d'accès au cache est 10 fois supérieure à celle de la mémoire, que le taux de réussite est de 40 % et que la table des pages comporte trois niveaux, alors en moyenne, un accès à une adresse virtuelle consomme environ deux temps d'accès à la mémoire physique.
Par conséquent, certains matériels embarqués peuvent abandonner l'utilisation de mmu. Ce matériel peut exécuter VxWorks (un système d'exploitation embarqué en temps réel très efficace), Linux (Linux dispose également d'une option de compilation pour désactiver mmu) et d'autres systèmes.
Mais les avantages de l’utilisation de mmu sont également importants, le plus important étant les considérations de sécurité. Chaque processus dispose d'un espace d'adressage virtuel indépendant et n'interfère pas les uns avec les autres. Après avoir abandonné le mappage d’adresses, tous les programmes s’exécuteront dans le même espace d’adressage. Par conséquent, sur une machine sans mmu, l'accès mémoire hors limites d'un processus peut provoquer des erreurs inexplicables dans d'autres processus, voire provoquer le crash du noyau.
En ce qui concerne le mappage d'adresses, le noyau ne fournit que des tables de pages et la conversion proprement dite est effectuée par le matériel. Alors, comment le noyau génère-t-il ces tables de pages ? Cela comporte deux aspects, la gestion de l'espace d'adressage virtuel et la gestion de la mémoire physique. (En fait, seul le mappage d'adresses en mode utilisateur doit être géré et le mappage d'adresses en mode noyau est codé en dur.)
Gestion des adresses virtuelles
Chaque processus correspond à une structure de tâches, qui pointe vers une structure mm, qui est le gestionnaire de mémoire du processus. (Pour les threads, chaque thread a également une structure de tâches, mais ils pointent tous vers le même mm, donc l'espace d'adressage est partagé.)
mm->pgd pointe vers la mémoire contenant la table des pages. Chaque processus a son propre mm, et chaque mm a sa propre table des pages. Par conséquent, lorsque le processus est planifié, la table des pages est commutée (il existe généralement un registre CPU pour enregistrer l'adresse de la table des pages, comme CR3 sous X86, et la commutation de la table des pages consiste à modifier la valeur du registre). Par conséquent, les espaces d'adressage de chaque processus ne s'affectent pas (car les tables de pages sont différentes, vous ne pouvez bien sûr pas accéder aux espaces d'adressage d'autres personnes. À l'exception de la mémoire partagée, cela est délibérément fait pour que différentes tables de pages puissent accéder à la même adresse physique. .
Les opérations du programme utilisateur sur la mémoire (allocation, recyclage, mappage, etc.) sont toutes des opérations sur mm, notamment des opérations sur le vma (espace mémoire virtuel) sur mm. Ces vma représentent diverses zones de l'espace de processus, telles que le tas, la pile, la zone de code, la zone de données, diverses zones de mappage, etc.
Les opérations du programme utilisateur sur la mémoire n'affecteront pas directement la table des pages, encore moins l'allocation de mémoire physique. Par exemple, si malloc réussit, cela ne modifie qu'un certain vma. La table des pages ne changera pas et l'allocation de mémoire physique ne changera pas.
Supposons que l'utilisateur alloue de la mémoire et accède ensuite à cette mémoire. Étant donné que le mappage correspondant n'est pas enregistré dans la table des pages, la CPU génère une exception de défaut de page. Le noyau intercepte l'exception et vérifie si l'adresse où l'exception s'est produite existe dans un vma légal. Si ce n'est pas le cas, attribuez au processus une "erreur de segmentation" et laissez-le planter ; si c'est le cas, attribuez-lui une page physique et établissez un mappage pour celle-ci.
Gestion de la mémoire physique
Alors, comment la mémoire physique est-elle allouée ?
Tout d'abord, Linux prend en charge NUMA (architecture de stockage non homogène), et le premier niveau de gestion de la mémoire physique est la gestion des médias. La structure pg_data_t décrit le support. D'une manière générale, notre support de gestion de mémoire n'est que de la mémoire, et il est uniforme, on peut donc simplement considérer qu'il n'y a qu'un seul objet pg_data_t dans le système.
Il y a plusieurs zones sous chaque support. Il y en a généralement trois : DMA, NORMAL et HIGH.
DMA : étant donné que le bus DMA de certains systèmes matériels est plus étroit que le bus système, seule une partie de l'espace d'adressage peut être utilisée pour le DMA. Cette partie de l'adresse est gérée dans la zone DMA (il s'agit d'un produit haut de gamme). ;
HIGH : Mémoire haut de gamme. Dans un système 32 bits, l'espace d'adressage est de 4G. Le noyau stipule que la plage de 3 à 4G est l'espace du noyau et 0 à 3G est l'espace utilisateur (chaque processus utilisateur dispose d'un si grand espace virtuel) (Figure : milieu en bas). Comme mentionné précédemment, le mappage d'adresses du noyau est codé en dur, ce qui signifie que la table de pages correspondante de 3~4G est codée en dur et qu'elle est mappée à l'adresse physique 0~1G. (En fait, 1G n'est pas mappé, seulement 896M. L'espace restant est laissé pour mapper les adresses physiques supérieures à 1G, et cette partie n'est évidemment pas codée en dur). Par conséquent, les adresses physiques supérieures à 896 Mo n'ont pas de tables de pages codées en dur pour leur correspondre. Le noyau ne peut pas y accéder directement (un mappage doit être établi), et elles sont appelées mémoire haut de gamme (bien sûr, si la mémoire de la machine est inférieur à 896 Mo, il n'y a pas de mémoire haut de gamme, s'il s'agit d'une machine 64 bits, il n'y a pas de mémoire haut de gamme, car l'espace d'adressage est très grand et l'espace appartenant au noyau est supérieur à 1 Go). ;
NORMAL : La mémoire qui n'appartient pas à DMA ou HIGH est appelée NORMAL.
La zone_list au-dessus de la zone représente la stratégie d'allocation, c'est-à-dire la priorité de la zone lors de l'allocation de mémoire. Une sorte d'allocation de mémoire n'est souvent pas allouée uniquement dans une seule zone. Par exemple, lors de l'allocation d'une page à utiliser par le noyau, la priorité la plus élevée est de l'allouer depuis NORMAL. Si cela ne fonctionne pas, allouez-la depuis DMA (HIGH. ne fonctionne pas car il n'a pas encore été alloué). Établir le mappage), qui est une stratégie d'allocation.
Chaque support de mémoire conserve une mem_map, et une structure de page correspondante est établie pour chaque page physique du support afin de gérer la mémoire physique.
Chaque zone enregistre sa position de départ sur mem_map. Et les pages gratuites de cette zone sont connectées via free_area. L'allocation de mémoire physique vient d'ici. Si vous supprimez la page de free_area, elle est allouée. (L'allocation de mémoire du noyau est différente de celle du processus utilisateur. L'utilisation de la mémoire par l'utilisateur sera supervisée par le noyau, et une mauvaise utilisation provoquera une « erreur de segmentation » ; tandis que le noyau n'est pas supervisé et ne peut compter que sur la conscience. . N'utilisez pas de pages que vous n'avez pas sélectionnées dans free_area )
[Créer un mappage d'adresses]
Lorsque le noyau a besoin de mémoire physique, dans de nombreux cas, la page entière est allouée. Pour ce faire, choisissez simplement une page dans la mem_map ci-dessus. Par exemple, le noyau mentionné précédemment capture les exceptions de faute de page, puis doit allouer une page pour établir le mappage.
En parlant de cela, il y aura une question. Lorsque le noyau alloue des pages et établit le mappage d'adresses, le noyau utilise-t-il des adresses virtuelles ou des adresses physiques ? Tout d'abord, les adresses auxquelles accède le code du noyau sont des adresses virtuelles, car les instructions CPU reçoivent des adresses virtuelles (le mappage d'adresses est transparent pour les instructions CPU). Cependant, lors de l'établissement du mappage d'adresses, le contenu renseigné par le noyau dans la table des pages est l'adresse physique, car le but du mappage d'adresses est d'obtenir l'adresse physique.
Alors, comment le noyau obtient-il cette adresse physique ? En fait, comme mentionné ci-dessus, les pages de mem_map sont établies en fonction de la mémoire physique, et chaque page correspond à une page physique.
On peut donc dire que le mappage des adresses virtuelles est ici complété par la structure des pages, et elles donnent l'adresse physique finale. Cependant, la structure des pages est évidemment gérée via des adresses virtuelles (comme mentionné précédemment, les instructions CPU reçoivent des adresses virtuelles). Ainsi, la structure de la page implémente le mappage d'adresses virtuelles d'autres personnes, qui implémentera le propre mappage d'adresses virtuelles de la structure de la page ? Personne ne peut y parvenir.
Cela conduit à un problème mentionné précédemment. Les entrées de la table des pages dans l'espace du noyau sont codées en dur. Lorsque le noyau est initialisé, le mappage d'adresses a été codé en dur dans l'espace d'adressage du noyau. La structure de la page existe évidemment dans l'espace du noyau, donc son problème de mappage d'adresses a été résolu par "codage en dur".
Étant donné que les entrées de la table de pages dans l'espace noyau sont codées en dur, un autre problème survient. La mémoire dans la zone NORMAL (ou DMA) peut être mappée à la fois sur l'espace noyau et sur l'espace utilisateur. Le mappage à l'espace du noyau est évident car ce mappage est codé en dur. Ces pages peuvent également être mappées à l’espace utilisateur, ce qui est possible dans le scénario d’exception de page manquante mentionné précédemment. Les pages mappées vers l'espace utilisateur doivent être obtenues d'abord à partir de la zone HIGH, car ces mémoires sont peu pratiques d'accès pour le noyau, il est donc préférable de les donner à l'espace utilisateur. Cependant, la zone HIGH peut être épuisée ou il peut n'y avoir aucune zone HIGH dans le système en raison d'une mémoire physique insuffisante sur le périphérique. Par conséquent, le mappage de la zone NORMAL à l'espace utilisateur est inévitable.
Cependant, il n'y a aucun problème car la mémoire dans la zone NORMAL est mappée à la fois à l'espace noyau et à l'espace utilisateur, car si une page est utilisée par le noyau, la page correspondante aurait dû être supprimée de la zone libre, donc l'exception de faute de page le code de gestion ne sera plus Cette page est mappée à l'espace utilisateur. La même chose est vraie à l'inverse. La page mappée à l'espace utilisateur a naturellement été supprimée de free_area et le noyau n'utilisera plus cette page.
Gestion de l'espace noyau
En plus d'utiliser la page entière de mémoire, le noyau doit parfois également allouer un espace de n'importe quelle taille, tout comme le programme utilisateur utilise malloc. Cette fonction est implémentée par le système de dalles.
Slab équivaut à établir un pool d'objets pour certains objets structurels couramment utilisés dans le noyau, comme le pool correspondant à la structure des tâches, le pool correspondant à la structure mm, etc.
Slab gère également des pools d'objets généraux, tels que le pool d'objets « taille 32 octets », le pool d'objets « taille 64 octets », etc. La fonction kmalloc couramment utilisée dans le noyau (similaire à malloc en mode utilisateur) est allouée dans ces pools d'objets généraux.
En plus de l'espace mémoire réellement utilisé par l'objet, slab possède également sa structure de contrôle correspondante. Il existe deux manières de l'organiser : si l'objet est plus grand, la structure de contrôle utilise une page spéciale pour l'enregistrer ; si l'objet est plus petit, la structure de contrôle utilise la même page que l'espace objet.
En plus de slab, Linux 2.6 a également introduit mempool (pool de mémoire). L'intention est la suivante : nous ne voulons pas que certains objets échouent à être alloués en raison d'une mémoire insuffisante, nous en allouons donc plusieurs à l'avance et les stockons dans mempool. Dans des circonstances normales, les ressources du pool de mémoire ne seront pas touchées lors de l'allocation d'objets et seront allouées via slab comme d'habitude. Lorsque la mémoire système est insuffisante et qu'il n'est plus possible d'allouer de la mémoire via slab, le contenu du mempool sera utilisé.
Échange de pages entrantes et sortantes(Photo : en haut à droite)
L’échange de pages entrantes et sortantes est un autre système très complexe. L'échange de pages mémoire sur le disque et le mappage de fichiers disque sur la mémoire sont deux processus très similaires (la motivation derrière l'échange de pages mémoire sur le disque est de les charger à nouveau en mémoire à partir du disque à l'avenir). Swap réutilise donc certains mécanismes du sous-système de fichiers.
L'échange de pages entrantes et sortantes est une question très gourmande en CPU et en E/S, mais pour la raison historique selon laquelle la mémoire est chère, nous devons utiliser des disques pour étendre la mémoire. Mais maintenant que la mémoire devient moins chère, nous pouvons facilement installer plusieurs gigaoctets de mémoire, puis arrêter le système d'échange. Par conséquent, l’implémentation de swap est vraiment difficile à explorer, je n’entrerai donc pas dans les détails ici. (Voir aussi : "Une brève analyse du recyclage des pages du noyau Linux")
[Gestion de la mémoire de l'espace utilisateur]
Malloc est une fonction de bibliothèque de la libc, et les programmes utilisateur l'utilisent généralement (ou des fonctions similaires) pour allouer de l'espace mémoire.
Il existe deux façons pour la libc d'allouer de la mémoire. L'une consiste à ajuster la taille du tas et l'autre consiste à mapper une nouvelle zone de mémoire virtuelle (le tas est également un vma).
Dans le noyau, le tas est un vma avec une extrémité fixe et une extrémité rétractable (photo : milieu gauche). La fin évolutive est ajustée via l'appel système brk. Libc gère l'espace du tas Lorsque l'utilisateur appelle malloc pour allouer de la mémoire, libc essaie de l'allouer à partir du tas existant. Si l'espace du tas n'est pas suffisant, augmentez-le via brk.
Lorsque l'utilisateur libère l'espace alloué, la libc peut réduire l'espace du tas via brk. Cependant, il est facile d'augmenter l'espace du tas mais difficile de le réduire. Considérons une situation dans laquelle l'espace utilisateur a continuellement alloué 10 blocs de mémoire et les 9 premiers blocs ont été libérés. À l'heure actuelle, même si le 10ème bloc qui n'est pas libre ne fait que 1 octet, la libc ne peut pas réduire la taille du tas. Parce qu'une seule extrémité du tas peut être élargie et contractée, et le milieu ne peut pas être creusé. Le 10ème bloc de mémoire occupe l'extrémité évolutive du tas. La taille du tas ne peut pas être réduite et les ressources associées ne peuvent pas être restituées au noyau.
Lorsque l'utilisateur alloue une grande mémoire, la libc mappera une nouvelle vma via l'appel système mmap. Étant donné que l'ajustement de la taille du tas et la gestion de l'espace restent problématiques, il sera plus pratique de reconstruire une vma (le problème gratuit mentionné ci-dessus en est également une des raisons).
Alors pourquoi ne pas toujours mapper un nouveau vma pendant malloc ? Premièrement, pour l'allocation et le recyclage de petits espaces, l'espace de tas géré par la libc peut déjà répondre aux besoins, et il n'est pas nécessaire de faire des appels système à chaque fois. Et vma est basé sur la page, et le minimum est d'allouer une page ; deuxièmement, trop de vma réduira les performances du système. Les exceptions de défaut de page, la création et la destruction de vma, le redimensionnement de l'espace de tas, etc. nécessitent tous des opérations sur vma. Vous devez trouver le vma (ou ceux) qui doivent être exploités parmi tous les vma dans le processus en cours. Trop de vmas entraîneront inévitablement une dégradation des performances. (Lorsque le processus a moins de VMA, le noyau utilise une liste chaînée pour gérer les VMA ; lorsqu'il y a plus de VMA, une arborescence rouge-noir est utilisée à la place.)
[Pile de l'utilisateur]
Comme le tas, la pile est aussi un vma (photo : milieu gauche). Ce vma est fixe à une extrémité et extensible à l'autre extrémité (attention, il ne peut pas être contracté). Ce vma est spécial. Il n'y a pas d'appel système comme brk pour étirer ce vma. Il s'étire automatiquement.
Lorsque l'adresse virtuelle accessible par l'utilisateur dépasse cette vma, le noyau augmentera automatiquement la vma lors de la gestion des exceptions de faute de page. Le noyau vérifiera le registre de pile actuel (tel que ESP) et l'adresse virtuelle accessible ne peut pas dépasser ESP plus n (n est le nombre maximum d'octets que l'instruction push du CPU peut pousser sur la pile à la fois). En d’autres termes, le noyau utilise ESP comme référence pour vérifier si l’accès est hors limites.
Cependant, la valeur de l'ESP peut être librement lue et écrite par les programmes en mode utilisateur. Que se passe-t-il si le programme utilisateur ajuste l'ESP et rend la pile très grande ? Il existe un ensemble de configurations concernant les restrictions de processus dans le noyau, y compris la configuration de la taille de la pile. La pile ne peut être qu'une taille limitée, et si elle est plus grande, une erreur se produira.
Pour un processus, la pile peut généralement être étirée de manière relativement importante (ex : 8 Mo). Mais qu'en est-il des fils ?
Tout d’abord, que se passe-t-il avec la pile du thread ? Comme mentionné précédemment, le mm d'un thread partage son processus parent. Bien que la pile soit une vma en mm, le thread ne peut pas partager cette vma avec son processus parent (deux entités en cours d'exécution n'ont évidemment pas besoin de partager une pile). Par conséquent, lorsque le thread est créé, la bibliothèque de threads crée un nouveau vma via mmap comme pile du thread (généralement supérieure à : 2M).
On peut voir que la pile du thread n'est pas une véritable pile dans un sens. Il s'agit d'une zone fixe et sa capacité est très limitée.
Grâce à cet article, vous devriez avoir une compréhension de base de la gestion de la mémoire Linux. Il s'agit d'un moyen efficace de convertir et d'allouer de la mémoire virtuelle et de la mémoire physique, et peut s'adapter aux divers besoins des systèmes Linux. Bien entendu, la gestion de la mémoire n’est pas statique. Elle doit être personnalisée et modifiée en fonction de la plate-forme matérielle spécifique et de la version du noyau. En bref, la gestion de la mémoire est un composant indispensable du système Linux et mérite votre étude et votre maîtrise approfondies.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



