
 Tutoriel système
Linux
Arrêtez de dire que vous ne comprenez pas la gestion de la mémoire Linux, 10 images vous le montreront clairement !
Tutoriel système
Linux
Arrêtez de dire que vous ne comprenez pas la gestion de la mémoire Linux, 10 images vous le montreront clairement !
Arrêtez de dire que vous ne comprenez pas la gestion de la mémoire Linux, 10 images vous le montreront clairement !

Aujourd’hui, nous étudierons la gestion de la mémoire de Linux.
Pour les étudiants en commerce maîtrisant CURD, la gestion de la mémoire semble loin de nous. Mais bien que ce point de connaissance ne soit pas populaire (on estime que beaucoup de gens ne l'utiliseront pas du tout après l'avoir appris), il constitue définitivement le fondement des bases.
C'est comme l'entraînement de force intérieure dans les romans d'arts martiaux. Vous ne verrez pas de résultats immédiats après l'avoir appris, mais cela sera d'un grand bénéfice pour votre futur travail de développement car vous vous tiendrez plus grand.
Tous les exemples d’images dans l’article sont dessinés par moi. Dessiner des images prend plus de temps que coder, mais tout le monde comprend plus intuitivement en regardant des images qu'en regardant des mots, donc je continue de les dessiner. Pour les étudiants qui ont besoin d’échantillons d’images haute définition, il existe des moyens de les obtenir à la fin de l’article.
Pour le dire plus utilitairement, si vous révélez par inadvertance que vous comprenez ces connaissances lors de l'entretien et que vous pouvez les raconter en détail, cela peut rendre l'intervieweur plus intéressé par vous, et vous pourrez peut-être obtenir une promotion, une augmentation de salaire, et commencez votre vie. Le sommet est un pas de plus.
Accord de principe : le principe du contenu technique abordé dans cet article est que l'environnement du système d'exploitation est x86 système x86 架构的 32 位 Linux 32 bits.
Adresse Virtuelle
Même dans les systèmes d'exploitation modernes, la mémoire reste une ressource extrêmement précieuse dans votre ordinateur. Regardez simplement la taille du disque SSD de votre ordinateur, puis la taille de la mémoire.
Afin d'utiliser et de gérer pleinement les ressources de mémoire système, Linux utilise la technologie de gestion de la mémoire virtuelle. Grâce à la technologie de mémoire virtuelle, chaque processus dispose d'un espace d'adressage virtuel de 4 Go qui n'interfère pas les uns avec les autres.
L'allocation et les opérations d'initialisation du processus sont basées sur cette "adresse virtuelle". Ce n'est que lorsque le processus doit réellement accéder aux ressources mémoire que le mappage entre l'adresse virtuelle et l'adresse physique sera établi et que la page de mémoire physique sera transférée.
Pour donner une analogie inappropriée, ce principe est en fait le même que celui du disque réseau XX actuel. Si votre espace disque réseau est de 1 To, pensez-vous vraiment que vous disposerez d'un si grand espace d'un seul coup ? C'est encore trop jeune. L'espace vous est alloué uniquement lorsque vous y placez des objets. Vous disposerez d'autant d'espace réel que vous en avez mis. Mais il semble que vous et votre ami disposez tous les deux de 1 To d’espace.
Avantages de l'adresse virtuelle
- Empêchez les utilisateurs d'accéder directement aux adresses de mémoire physique, empêchez les opérations destructrices et protégez le système d'exploitation.
- Chaque processus se voit attribuer 4 Go de mémoire virtuelle, permettant aux programmes utilisateur d'utiliser un espace d'adressage plus grand que la mémoire physique réelle.
L'espace d'adressage virtuel du processus de 4 Go est divisé en deux parties : « l'espace utilisateur » et « l'espace noyau ».
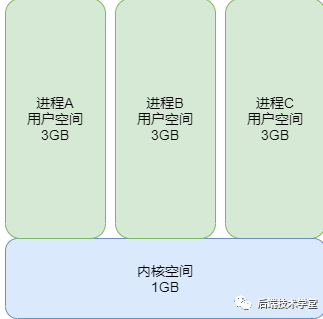
Espace noyau de l'espace utilisateur
Adresse physique
Dans le chapitre ci-dessus, nous savons déjà que qu'il s'agisse de l'espace utilisateur ou de l'espace noyau, les adresses utilisées sont des adresses virtuelles. Lorsque le processus doit réellement accéder à la mémoire, une « exception de défaut de page » sera générée par la « requête » du noyau. mécanisme de pagination" et transféré à l'adresse physique. page mémoire.
Convertir l'adresse virtuelle en adresse physique de la mémoire, ce qui implique d'utiliser l'unité de gestion de la mémoire MMU pour segmenter et paginer la conversion d'adresse de l'adresse virtuelle (type page de segment). Concernant le processus spécifique de segmentation et de pagination, nous n'en discuterons pas. ici. Pour plus de détails, vous pouvez vous référer à n'importe quel manuel sur les principes de composition informatique pour une description.

Conversion d'adresse de gestion de mémoire de page de segment
Linux Le noyau divisera la mémoire physique en 3 zones de gestion, qui sont :
ZONE_DMA
DMA内存区域。包含0MB~16MB之间的内存页框,可以由老式基于ISA的设备通过DMAUtilisé, mappé directement sur l'espace d'adressage du noyau.
ZONE_NORMAL
Zone de mémoire normale. Contient des cadres de page mémoire compris entre 16 Mo et 896 Mo, des cadres de page normaux, directement mappés à l'espace d'adressage du noyau.
ZONE_HIGHMEM
Zone mémoire haut de gamme. Contient des cadres de page mémoire supérieurs à 896 Mo, qui ne sont pas directement mappés. Cette partie du cadre de page mémoire est accessible via un mappage permanent et un mappage temporaire.
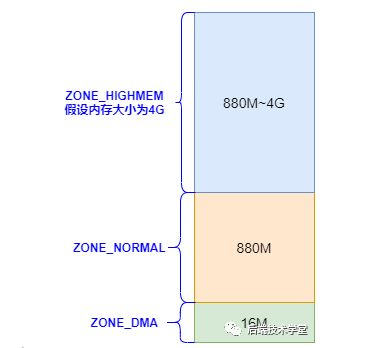
Division de la zone de mémoire physique
Espace utilisateur
Ce à quoi les processus utilisateur peuvent accéder est « l'espace utilisateur ». Chaque processus a son propre espace utilisateur indépendant, et la plage d'adresses virtuelles est de 0x00000000 至 0xBFFFFFFF La capacité totale est de 3G.
Les processus utilisateur ne peuvent généralement accéder qu'aux adresses virtuelles dans l'espace utilisateur et ne peuvent accéder à l'espace du noyau que lors de l'exécution d'opérations en ligne ou d'appels système.
Processus et mémoire
L'espace utilisateur occupé par le processus (programme exécuté) est divisé en 5différentes zones de mémoire selon le principe selon lequel "les espaces d'adressage avec des attributs d'accès cohérents sont stockés ensemble". Les propriétés d'accès font référence à « lisible, inscriptible, exécutable, etc.
-
Extrait de code
Le segment de code est utilisé pour stocker les instructions de fonctionnement du fichier exécutable et l'image du programme exécutable dans la mémoire. Le segment de code doit être protégé contre les modifications illégales au moment de l'exécution, donc seules les opérations de lecture sont autorisées, il n'est pas accessible en écriture.
-
Segment de données
Le segment de données est utilisé pour stocker les variables globales initialisées dans le fichier exécutable. En d'autres termes, il stocke les variables et les variables globales allouées statiquement par le programme.
-
Section BSS
BSS段包含了程序中未初始化的全局变量,在内存中bssRéglez tous les segments à zéro. -
Tas
heapLe tas est utilisé pour stocker des segments de mémoire alloués dynamiquement pendant l'exécution du processus. Sa taille n'est pas fixe et peut être étendue ou réduite dynamiquement. Lorsqu'un processus appelle des fonctions telles que malloc pour allouer de la mémoire, la mémoire nouvellement allouée est ajoutée dynamiquement au tas (le tas est étendu) ; lorsque des fonctions telles que free sont utilisées pour libérer de la mémoire, la mémoire libérée est supprimée du tas (le tas est étendu) ; le tas est réduit).
-
Pile
stackLa pile est une variable locale créée temporairement par l'utilisateur pour stocker le programme, c'est-à-dire les variables définies dans la fonction (mais sans compter les variables déclarées par
static, statique signifie stocker des variables dans le segment de données). De plus, lorsqu'une fonction est appelée, ses paramètres seront également placés sur la pile du processus qui a lancé l'appel, et une fois l'appel terminé, la valeur de retour de la fonction sera également stockée sur la pile. En raison de la fonction premier entré, dernier sorti de la pile, la pile est particulièrement pratique pour sauvegarder/restaurer la scène d'appel. En ce sens, on peut considérer la pile comme une zone mémoire qui stocke et échange des données temporaires.
Dans les zones de mémoire mentionnées ci-dessus, le segment de données et BSS 段、堆通常是被连续存储在内存中,在位置上是连续的,而代码段和栈往往会被独立存放。堆和栈两个区域在 i386dans l'architecture, la pile s'étend vers le bas et le tas s'étend vers le haut, qui sont les uns par rapport aux autres. 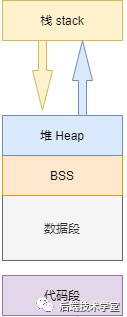
Vous pouvez également utiliser la commande size sous Linux pour vérifier la taille de chaque zone mémoire du programme compilé :
[lemon ~]# size /usr/local/sbin/sshd text data bss dec hexfilename 1924532 12412 4268962363840 2411c0/usr/local/sbin/sshd
Espace noyau
La capacité de x86 32 位系统里,Linux 内核地址空间是指虚拟地址从 0xC0000000 开始到 0xFFFFFFFF 为止的高端内存地址空间,总计 1G inclut l'image du noyau, la table des pages physiques, le pilote, etc. exécutés dans l'espace du noyau.
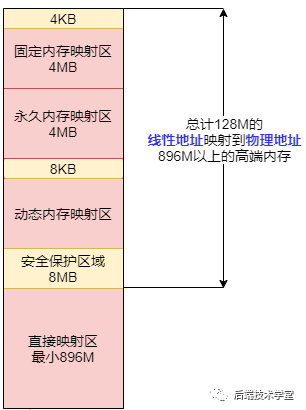
Zone de subdivision spatiale du noyau.
Zone de cartographie directe
Zone de mappage direct La plage d'adresses de l'espace noyau de Direct Memory Region:从内核空间起始地址开始,最大896M est une zone de mappage direct de la mémoire.
L'"adresse linéaire" de 896 Mo dans la zone de mappage direct est directement connectée au recto de "l'adresse physique" 896MB进行映射,也就是说线性地址和分配的物理地址都是连续的。内核地址空间的线性地址0xC0000001所对应的物理地址为0x00000001,它们之间相差一个偏移量PAGE_OFFSET = 0xC0000000
Il existe une relation de conversion linéaire entre l'adresse linéaire et l'adresse physique dans cette zone. "Adresse linéaire = PAGE_OFFSET + 物理地址」也可以用 virt_to_phys()La fonction convertit l'adresse linéaire dans l'espace virtuel du noyau en une adresse physique.
Espace d'adressage linéaire de mémoire haut de gamme
La plage d'adresses linéaires de l'espace noyau est de 896 Mo à 1 Go, et la plage d'adresses d'une capacité de 128 Mo est l'espace d'adressage linéaire de la mémoire haut de gamme. Pourquoi est-il appelé espace d'adressage linéaire de la mémoire haut de gamme ? Laissez-moi vous l'expliquer :
Comme mentionné précédemment, la taille totale de l'espace noyau est de 1 Go et l'adresse linéaire de 896 Mo à partir de l'adresse de départ de l'espace noyau peut être directement mappée à une plage d'adresses avec une taille d'adresse physique de 896 Mo.
Prenez du recul, même si l'adresse linéaire de 1 Go dans l'espace du noyau est mappée à une adresse physique, elle ne peut adresser qu'un maximum de 1 Go de plage d'adresses de mémoire physique.
Quelle est la taille de la clé USB que vous possédez actuellement ? Réveillez-vous, nous sommes presque en 2023, et la mémoire de la plupart des PC est supérieure à 1 Go !
Ainsi, l'espace du noyau a retiré la dernière plage d'adresses de 128 Mo et l'a divisée en trois zones de mappage de mémoire haut de gamme suivantes pour traiter l'intégralité de la plage d'adresses physiques. Ce problème n'existe pas sur les systèmes 64 bits, car l'espace d'adressage linéaire disponible est bien plus grand que la mémoire installable.
Zone de mappage de mémoire dynamique
vmalloc Region 该区域由内核函数vmalloc来分配,特点是:线性空间连续,但是对应的物理地址空间不一定连续。vmalloc La page physique correspondant à l'adresse linéaire allouée peut être en mémoire bas de gamme ou en mémoire haut de gamme.
Zone de cartographie de la mémoire permanente
La fonctionPersistent Kernel Mapping Region 该区域可访问高端内存。访问方法是使用 alloc_page (_GFP_HIGHMEM) 分配高端内存页或者使用kmap mappe la mémoire haut de gamme allouée à cette zone.
Zone de cartographie fixe
Fixing kernel Mapping Region 该区域和 4G 的顶端只有 4k 的隔离带,其每个地址项都服务于特定的用途,如 ACPI_BASEetc.
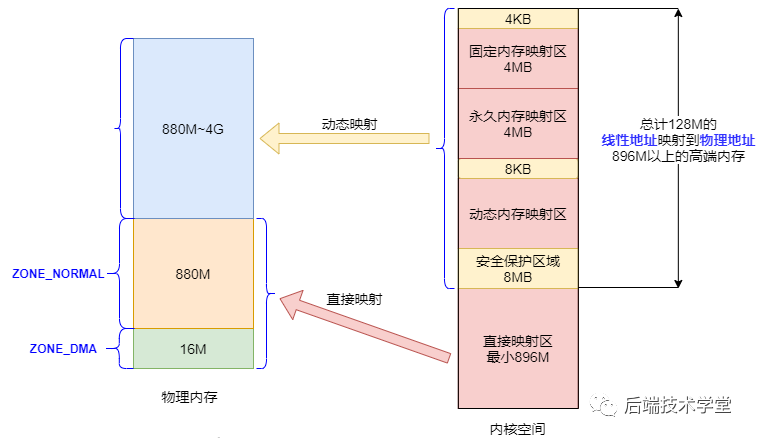
Cartographie de la mémoire physique de l'espace noyau
Revue
Il y a beaucoup de choses à dire ci-dessus, alors ne vous précipitez pas dans la section suivante. Avant cela, passons en revue ce que nous avons dit ci-dessus. Si vous lisez attentivement les chapitres ci-dessus, j'ai dessiné ici une autre image, et maintenant vous devriez avoir en tête une image globale de la gestion de la mémoire.
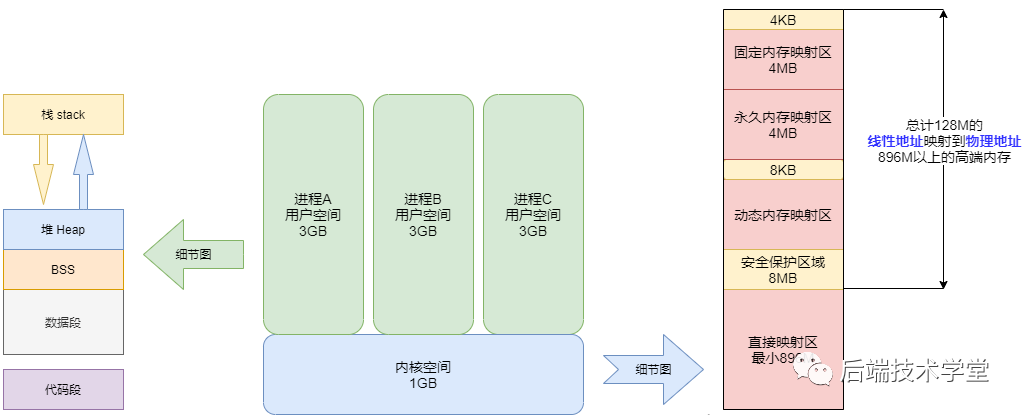
Image complète de l'espace noyau et de l'espace utilisateur
Structure des données mémoire
Pour que le noyau puisse gérer la mémoire virtuelle dans le système, la structure des données de gestion de la mémoire doit en être abstraite. Les opérations de gestion de la mémoire telles que « l'allocation, la libération, etc. » sont basées sur ces opérations de structure de données. structures qui gèrent la zone de mémoire virtuelle.
Structure des données de la mémoire de l'espace utilisateur
Dans le chapitre précédent « Processus et mémoire », nous avons mentionné que le processus Linux peut être divisé en 5 zones de mémoire différentes, à savoir : segment de code, segment de données, BSS、堆、栈,内核管理这些区域的方式是,将这些内存区域抽象成vm_area_structobjet de gestion de mémoire.
vm_area_struct是描述进程地址空间的基本管理单元,一个进程往往需要多个vm_area_struct来描述它的用户空间虚拟地址,需要使用「链表」和「红黑树」来组织各个vm_area_struct.
Les listes chaînées sont utilisées lorsque tous les nœuds doivent être parcourus, tandis que les arbres rouge-noir conviennent pour localiser des zones de mémoire spécifiques dans l'espace d'adressage. Le noyau utilise les deux structures de données afin d'obtenir des performances élevées pour diverses opérations sur les zones de mémoire.
Modèle de gestion des adresses du processus de l'espace utilisateur :
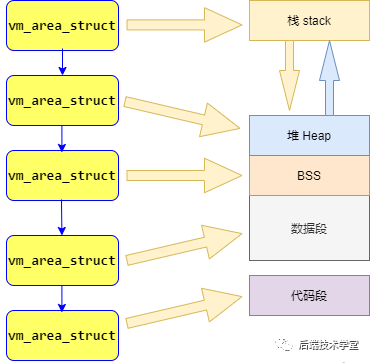
wm_arem_struct
L'espace noyau alloue dynamiquement la structure des données de mémoire
Dans le chapitre sur l'espace noyau, nous avons mentionné la "zone de mappage de mémoire dynamique". La page physique correspondant à l'adresse linéaire allouée par la fonction noyau vmalloc来分配,特点是:线性空间连续,但是对应的物理地址空间不一定连续。vmalloc peut être en mémoire bas de gamme ou en mémoire haut de gamme.
vmalloc 分配的地址则限于vmalloc_start与vmalloc_end之间。每一块vmalloc分配的内核虚拟内存都对应一个vm_struct结构体,不同的内核空间虚拟地址之间有4k Cloison de zone libre anti-traversement de taille.
Semblables aux caractéristiques des adresses virtuelles dans l'espace utilisateur, ces adresses virtuelles n'ont pas de relation de mappage simple avec la mémoire physique. Elles doivent être converties en adresses physiques ou en pages physiques via la table des pages du noyau. un défaut de page se produit, allouez vraiment des pages physiques.
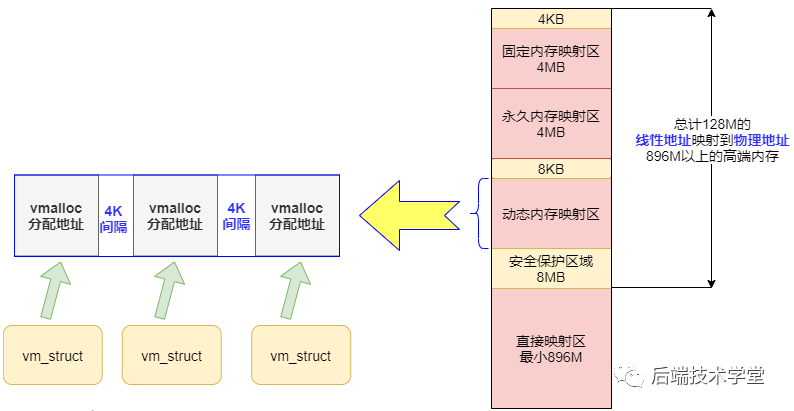
Cartographie dynamique de la mémoire
Pour résumer
LinuxLa gestion de la mémoire est un système très complexe. Ce qui est décrit dans cet article n'est que la pointe de l'iceberg. Il vous montre l'ensemble de la gestion de la mémoire d'un point de vue macro, mais d'une manière générale, ces connaissances sont encore suffisantes lorsque vous discutez. avec l'intervieweur Bien sûr, j'espère aussi que tout le monde pourra comprendre des principes plus profonds grâce à la lecture.
Cet article peut être utilisé comme un guide d'étude de type index. Lorsque vous souhaitez étudier un certain point en profondeur, vous pouvez trouver le point d'entrée dans ces chapitres et la position de ce point de connaissance dans la vue macroscopique de la gestion de la mémoire.
J'ai également dessiné de nombreux exemples de schémas lors de la création de cet article, qui peuvent être utilisés comme index de connaissances. Personnellement, je pense que regarder des images est plus clair que lire du texte. Vous pouvez les obtenir en répondant à "Mémoire". Management" en arrière-plan de mon compte officiel "Backend Technology School" Originaux haute résolution de ces images.
Anciennes règles, merci d'avoir lu. Le but de l'article est de partager la compréhension des connaissances. Pour les articles techniques, je les vérifierai à plusieurs reprises pour garantir au maximum l'exactitude. S'il y a des erreurs évidentes dans l'article, vous pouvez le faire. sommes invités à les signaler. Tirons ensemble les leçons de la discussion. C’est tout pour le partage technologique d’aujourd’hui. Rendez-vous dans le prochain numéro.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos sera fermé en 2024 parce que sa distribution en amont, Rhel 8, a été fermée. Cette fermeture affectera le système CentOS 8, l'empêchant de continuer à recevoir des mises à jour. Les utilisateurs doivent planifier la migration et les options recommandées incluent CentOS Stream, Almalinux et Rocky Linux pour garder le système en sécurité et stable.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment monter un disque dur dans les centos
Apr 14, 2025 pm 08:15 PM
Comment monter un disque dur dans les centos
Apr 14, 2025 pm 08:15 PM
Le support de disque dur CentOS est divisé en étapes suivantes: Déterminez le nom du périphérique du disque dur (/ dev / sdx); créer un point de montage (il est recommandé d'utiliser / mnt / newdisk); Exécutez la commande Mount (mont / dev / sdx1 / mnt / newdisk); modifier le fichier / etc / fstab pour ajouter une configuration de montage permanent; Utilisez la commande umount pour désinstaller l'appareil pour vous assurer qu'aucun processus n'utilise l'appareil.
 Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Une fois CentOS arrêté, les utilisateurs peuvent prendre les mesures suivantes pour y faire face: sélectionnez une distribution compatible: comme Almalinux, Rocky Linux et CentOS Stream. Migrez vers les distributions commerciales: telles que Red Hat Enterprise Linux, Oracle Linux. Passez à Centos 9 Stream: Rolling Distribution, fournissant les dernières technologies. Sélectionnez d'autres distributions Linux: comme Ubuntu, Debian. Évaluez d'autres options telles que les conteneurs, les machines virtuelles ou les plates-formes cloud.
 Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
CentOS a été interrompu, les alternatives comprennent: 1. Rocky Linux (meilleure compatibilité); 2. Almalinux (compatible avec CentOS); 3. Serveur Ubuntu (configuration requise); 4. Red Hat Enterprise Linux (version commerciale, licence payante); 5. Oracle Linux (compatible avec Centos et Rhel). Lors de la migration, les considérations sont: la compatibilité, la disponibilité, le soutien, le coût et le soutien communautaire.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
