
 Tutoriel système
Linux
Mécanisme de planification de groupe de processus Linux : comment regrouper et planifier des processus
Tutoriel système
Linux
Mécanisme de planification de groupe de processus Linux : comment regrouper et planifier des processus
Mécanisme de planification de groupe de processus Linux : comment regrouper et planifier des processus

Le groupe de processus est un moyen de classer et de gérer les processus dans les systèmes Linux. Il peut regrouper des processus ayant les mêmes caractéristiques ou relations pour former une unité logique. La fonction du groupe de processus est de faciliter le contrôle, la communication et l'allocation des ressources des processus afin d'améliorer l'efficacité et la sécurité du système. La planification de groupes de processus est un mécanisme de planification de groupes de processus dans les systèmes Linux. Elle peut allouer le temps CPU et les ressources appropriés en fonction des attributs et des besoins du groupe de processus, améliorant ainsi la concurrence et la réactivité du système. Mais comprenez-vous vraiment le mécanisme de planification des groupes de processus Linux ? Savez-vous comment créer et gérer des groupes de processus sous Linux ? Savez-vous comment utiliser et configurer le mécanisme de planification des groupes de processus sous Linux ? Cet article vous présentera en détail les connaissances pertinentes du mécanisme de planification des groupes de processus Linux, vous permettant de mieux utiliser et comprendre cette puissante fonction du noyau sous Linux.

J'ai rencontré un autre problème de planification de processus magique. Au cours du processus de redémarrage du système, j'ai constaté que le système raccrochait et qu'il était réinitialisé après 30 secondes. La véritable raison de la réinitialisation du système était que le système de surveillance matériel avait redémarré le système, et non l'original. processus de redémarrage normal. Le temps de réinitialisation de l'enregistrement matériel du chien est avancé de 30 secondes lorsque le chien n'est pas nourri. Lors de l'analyse du journal d'enregistrement du port série, le journal à ce moment-là imprimait une phrase : "sched : RT throttling activé".
Comme le montre le code du noyau de la version linux-3.0.101-0.7.17, sched_rt_runtime_exceeded imprime cette phrase. Dans le processus de planification des groupes de processus du noyau, la planification des processus en temps réel est limitée par rt_rq->rt_throttled Parlons en détail ci-dessous du mécanisme de planification des groupes de processus sous Linux.
Mécanisme de planification des groupes de processus
La planification de groupe est un concept de cgroup, qui fait référence au traitement de N processus dans leur ensemble et à la participation au processus de planification dans le système. Cela se reflète spécifiquement dans l'exemple : la tâche A a 8 processus ou threads et la tâche B a 2 processus. ou des threads. S'il existe encore d'autres processus ou threads, vous devez contrôler que l'utilisation du processeur de la tâche A ne dépasse pas 40 %, que l'utilisation du processeur de la tâche B ne dépasse pas 40 % et que l'occupation des autres tâches. ne doit pas être inférieur à 20 %. Ensuite, il y a un droit Pour définir le seuil du groupe de contrôle, le groupe de contrôle A est défini sur 200, le groupe de contrôle B est défini sur 200 et les autres tâches sont définies par défaut sur 100, réalisant ainsi la fonction de contrôle du processeur.
Dans le noyau, les groupes de processus sont gérés par task_group, et la plupart des contenus impliqués sont des mécanismes de contrôle de cgroup. De plus, l'unité de développement est en cours d'écriture à la partie qui se concentre sur la planification de groupe. Voir les commentaires suivants pour plus de détails. .
struct task_group {
struct cgroup_subsys_state css;
//下面是普通进程调度使用
#ifdef CONFIG_FAIR_GROUP_SCHED
/* schedulable entities of this group on each cpu */
//普通进程调度单元,之所以用调度单元,因为被调度的可能是一个进程,也可能是一组进程
struct sched_entity **se;
/* runqueue "owned" by this group on each cpu */
//公平调度队列
struct cfs_rq **cfs_rq;
//下面就是如上示例的控制阀值
unsigned long shares;
atomic_t load_weight;
#endif
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程调度单元
struct sched_rt_entity **rt_se;
//实时进程调度队列
struct rt_rq **rt_rq;
//实时进程占用CPU时间的带宽(或者说比例)
struct rt_bandwidth rt_bandwidth;
#endif
struct rcu_head rcu;
struct list_head list;
//task_group呈树状结构组织,有父节点,兄弟链表,孩子链表,内核里面的根节点是root_task_group
struct task_group *parent;
struct list_head siblings;
struct list_head children;
#ifdef CONFIG_SCHED_AUTOGROUP
struct autogroup *autogroup;
#endif
struct cfs_bandwidth cfs_bandwidth;
};
Il existe deux types d'unités de planification, à savoir l'unité de planification ordinaire et l'unité de planification de processus en temps réel.
struct sched_entity {
struct load_weight load; /* for load-balancing */
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
//当前调度单元归属于某个父调度单元
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
//当前调度单元归属的父调度单元的调度队列,即当前调度单元插入的队列
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
//当前调度单元的调度队列,即管理子调度单元的队列,如果调度单元是task_group,my_q才会有值
//如果当前调度单元是task,那么my_q自然为NULL
struct cfs_rq *my_q;
#endif
void *suse_kabi_padding;
};
struct sched_rt_entity {
struct list_head run_list;
unsigned long timeout;
unsigned int time_slice;
int nr_cpus_allowed;
struct sched_rt_entity *back;
#ifdef CONFIG_RT_GROUP_SCHED
//实时进程的管理和普通进程类似,下面三项意义参考普通进程
struct sched_rt_entity *parent;
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;
/* rq "owned" by this entity/group: */
struct rt_rq *my_q;
#endif
};
Jetons un coup d'œil à la file d'attente de planification, car les options qui doivent être expliquées pour la planification en temps réel et les files d'attente de planification ordinaires sont similaires :
struct rt_rq {
struct rt_prio_array active;
unsigned long rt_nr_running;
#if defined CONFIG_SMP || defined CONFIG_RT_GROUP_SCHED
struct {
int curr; /* highest queued rt task prio */
#ifdef CONFIG_SMP
int next; /* next highest */
#endif
} highest_prio;
#endif
#ifdef CONFIG_SMP
unsigned long rt_nr_migratory;
unsigned long rt_nr_total;
int overloaded;
struct plist_head pushable_tasks;
#endif
//当前队列的实时调度是否受限
int rt_throttled;
//当前队列的累计运行时间
u64 rt_time;
//当前队列的最大运行时间
u64 rt_runtime;
/* Nests inside the rq lock: */
raw_spinlock_t rt_runtime_lock;
#ifdef CONFIG_RT_GROUP_SCHED
unsigned long rt_nr_boosted;
//当前实时调度队列归属调度队列
struct rq *rq;
struct list_head leaf_rt_rq_list;
//当前实时调度队列归属的调度单元
struct task_group *tg;
#endif
};
Grâce à l'analyse des trois structures ci-dessus, l'image suivante peut être obtenue (cliquez pour agrandir l'image) :
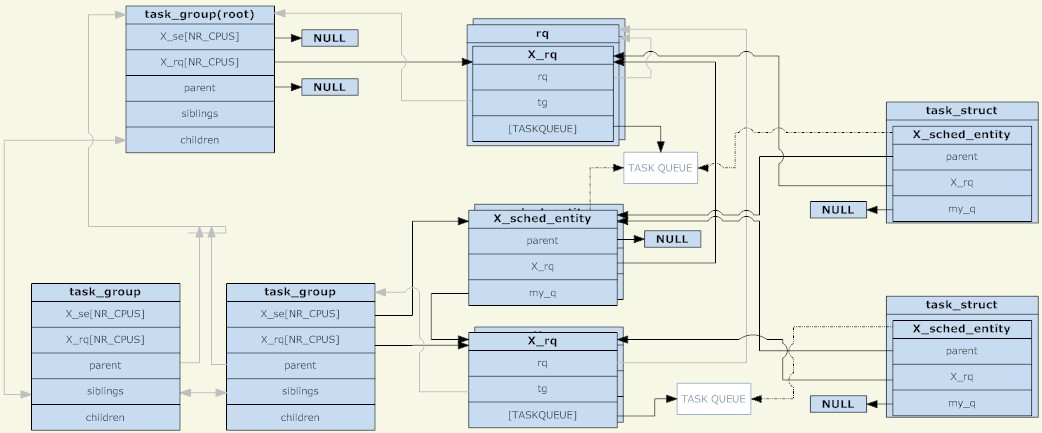
task_group
Comme le montre la figure, l'unité de planification et la file d'attente de planification sont combinées dans un nœud d'arborescence, qui est une autre structure arborescente distincte. Cependant, il convient de noter que l'unité de planification ne sera placée que lorsqu'il y a un processus TASK_RUNNING. dans l'unité de planification dans la file d'attente d'envoi.
Un autre point est qu'avant la planification de groupe, il n'y avait qu'une seule file d'attente de planification sur chaque CPU. À cette époque, on pouvait comprendre que tous les processus étaient dans un seul groupe de planification. Désormais, chaque groupe de planification a une file d'attente de planification sur chaque CPU. Au cours du processus de planification, le système a initialement sélectionné un processus à exécuter. Actuellement, il sélectionne une unité de planification à exécuter. Lorsque la planification se produit, le processus de planification démarre à partir de root_task_group et recherche l'unité de planification déterminée par la politique de planification. est task_group, il entre dans task_group. La file d'attente d'exécution sélectionne une unité de planification appropriée et trouve enfin une unité de planification de tâches appropriée. L'ensemble du processus est une traversée d'arborescence. Le groupe de tâches avec le processus TASK_RUNNING est le nœud de l'arborescence et l'unité de planification des tâches est la feuille de l'arborescence.
Stratégie de planification des processus de groupe
Le but de la planification des processus de groupe n'est pas différent de celui d'origine, qui est de compléter la planification des processus en temps réel et la planification des processus ordinaires, c'est-à-dire la planification rt et cfs.
CFS组调度策略:
文章前面示例中提到的任务分配CPU,说的就是cfs调度,对于CFS调度而言,调度单元和普通调度进程没有多大区别,调度单元由自己的调度优先级,而且不受调度进程的影响,每个task_group都有一个shares,share并非我们说的进程优先级,而是调度权重,这个是cfs调度管理的概念,但在cfs中最终体现到调度优先排序上。shares值默认都是相同的,所有没有设置权重的值,CPU都是按旧有的cfs管理分配的。总结的说,就是cfs组调度策略没变化。具体到cgroup的CPU控制机制上再说。
RT组调度策略:
实时进程的优先级是设置固定,调度器总是选择优先级最高的进程运行。而在组调度中,调度单元的优先级则是组内优先级最高的调度单元的优先级值,也就是说调度单元的优先级受子调度单元影响,如果一个进程进入了调度单元,那么它所有的父调度单元的调度队列都要重排。实际上我们看到的结果是,调度器总是选择优先级最高的实时进程调度,那么组调度对实时进程控制机制是怎么样的?
在前面的rt_rq实时进程运行队列里面提到rt_time和rt_runtime,一个是运行累计时间,一个是最大运行时间,当运行累计时间超过最大运行时间的时候,rt_throttled则被设置为1,见sched_rt_runtime_exceeded函数。
if (rt_rq->rt_time > runtime) {
rt_rq->rt_throttled = 1;
if (rt_rq_throttled(rt_rq)) {
sched_rt_rq_dequeue(rt_rq);
return 1;
}
}
设置为1意味着实时队列中被限制了,如__enqueue_rt_entity函数,不能入队。
static inline int rt_rq_throttled(struct rt_rq *rt_rq)
{
return rt_rq->rt_throttled && !rt_rq->rt_nr_boosted;
}
static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, bool head)
{
/*
* Don't enqueue the group if its throttled, or when empty.
* The latter is a consequence of the former when a child group
* get throttled and the current group doesn't have any other
* active members.
*/
if (group_rq && (rt_rq_throttled(group_rq) || !group_rq->rt_nr_running))
return;
.....
}
其实还有一个隐藏的时间概念,即sched_rt_period_us,意味着sched_rt_period_us时间内,实时进程可以占用CPU rt_runtime时间,如果实时进程每个时间周期内都没有调度,则在do_sched_rt_period_timer定时器函数中将rt_time减去一个周期,然后比较rt_runtime,恢复rt_throttled。
//overrun来自对周期时间定时器误差的校正 rt_rq->rt_time -= min(rt_rq->rt_time, overrun*runtime); if (rt_rq->rt_throttled && rt_rq->rt_time rt_throttled = 0; enqueue = 1;
则对于cgroup控制实时进程的占用比则是通过rt_runtime实现的,对于root_task_group,也即是所有进程在一个cgroup下,则是通过/proc/sys/kernel/sched_rt_period_us和/proc/sys/kernel/sched_rt_runtime_us接口设置的,默认值是1s和0.95s。这么看以为实时进程只能占用95%CPU,那么实时进程占用CPU100%导致进程挂死的问题怎么出现了?
原来实时进程所在的CPU占用超时了,实时进程的rt_runtime可以向别的cpu借用,将其他CPU剩余的rt_runtime-rt_time的值借过来,如此rt_time可以最大等于rt_runtime,造成事实上的单核CPU达到100%。这样做的目的自然规避了实时进程缺少CPU时间而向其他核迁移的成本,未绑核的普通进程自然也可以迁移其他CPU上,不会得不到调度,当然绑核进程仍然是个杯具。
static int do_balance_runtime(struct rt_rq *rt_rq)
{
struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq);
struct root_domain *rd = cpu_rq(smp_processor_id())->rd;
int i, weight, more = 0;
u64 rt_period;
weight = cpumask_weight(rd->span);
raw_spin_lock(&rt_b->rt_runtime_lock);
rt_period = ktime_to_ns(rt_b->rt_period);
for_each_cpu(i, rd->span) {
struct rt_rq *iter = sched_rt_period_rt_rq(rt_b, i);
s64 diff;
if (iter == rt_rq)
continue;
raw_spin_lock(&iter->rt_runtime_lock);
/*
* Either all rqs have inf runtime and there's nothing to steal
* or __disable_runtime() below sets a specific rq to inf to
* indicate its been disabled and disalow stealing.
*/
if (iter->rt_runtime == RUNTIME_INF)
goto next;
/*
* From runqueues with spare time, take 1/n part of their
* spare time, but no more than our period.
*/
diff = iter->rt_runtime - iter->rt_time;
if (diff > 0) {
diff = div_u64((u64)diff, weight);
if (rt_rq->rt_runtime + diff > rt_period)
diff = rt_period - rt_rq->rt_runtime;
iter->rt_runtime -= diff;
rt_rq->rt_runtime += diff;
more = 1;
if (rt_rq->rt_runtime == rt_period) {
raw_spin_unlock(&iter->rt_runtime_lock);
break;
}
}
next:
raw_spin_unlock(&iter->rt_runtime_lock);
}
raw_spin_unlock(&rt_b->rt_runtime_lock);
return more;
}
通过本文,你应该对 Linux 进程组调度机制有了一个深入的了解,知道了它的定义、原理、流程和优化方法。你也应该明白了进程组调度机制的作用和影响,以及如何在 Linux 下正确地使用和配置进程组调度机制。我们建议你在使用 Linux 系统时,使用进程组调度机制来提高系统的效率和安全性。同时,我们也提醒你在使用进程组调度机制时要注意一些潜在的问题和挑战,如进程组类型、优先级、限制等。希望本文能够帮助你更好地使用 Linux 系统,让你在 Linux 下享受进程组调度机制的优势和便利。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Que faire si l'image Docker échoue
Apr 15, 2025 am 11:21 AM
Dépannage des étapes pour la construction d'image Docker échouée: cochez la syntaxe Dockerfile et la version de dépendance. Vérifiez si le contexte de construction contient le code source et les dépendances requis. Affichez le journal de construction pour les détails d'erreur. Utilisez l'option - cibler pour créer une phase hiérarchique pour identifier les points de défaillance. Assurez-vous d'utiliser la dernière version de Docker Engine. Créez l'image avec --t [Image-Name]: Debug Mode pour déboguer le problème. Vérifiez l'espace disque et assurez-vous qu'il est suffisant. Désactivez SELINUX pour éviter les interférences avec le processus de construction. Demandez de l'aide aux plateformes communautaires, fournissez Dockerfiles et créez des descriptions de journaux pour des suggestions plus spécifiques.
 Comment afficher le processus Docker
Apr 15, 2025 am 11:48 AM
Comment afficher le processus Docker
Apr 15, 2025 am 11:48 AM
Méthode de visualisation du processus docker: 1. Commande Docker CLI: Docker PS; 2. Commande CLI Systemd: Docker d'état SystemCTL; 3. Docker Compose CLI Commande: Docker-Compose PS; 4. Process Explorer (Windows); 5. / Répertoire proc (Linux).
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Vs Code Système Exigences: Système d'exploitation: Windows 10 et supérieur, MacOS 10.12 et supérieur, processeur de distribution Linux: minimum 1,6 GHz, recommandé 2,0 GHz et au-dessus de la mémoire: minimum 512 Mo, recommandée 4 Go et plus d'espace de stockage: Minimum 250 Mo, recommandée 1 Go et plus d'autres exigences: connexion du réseau stable, xorg / wayland (Linux) recommandé et recommandée et plus
 VScode ne peut pas installer l'extension
Apr 15, 2025 pm 07:18 PM
VScode ne peut pas installer l'extension
Apr 15, 2025 pm 07:18 PM
Les raisons de l'installation des extensions de code vs peuvent être: l'instabilité du réseau, les autorisations insuffisantes, les problèmes de compatibilité système, la version de code vs est trop ancienne, un logiciel antivirus ou des interférences de pare-feu. En vérifiant les connexions réseau, les autorisations, les fichiers journaux, la mise à jour vs du code, la désactivation des logiciels de sécurité et le redémarrage du code ou des ordinateurs, vous pouvez progressivement dépanner et résoudre les problèmes.
