

La planification des processus est l'une des fonctions essentielles du système d'exploitation. Elle détermine quels processus peuvent bénéficier du temps d'exécution du processeur et combien de temps ils en obtiennent. Dans les systèmes Linux, il existe de nombreux algorithmes de planification de processus, le plus important et le plus couramment utilisé est l'algorithme de planification complètement équitable (CFS), introduit à partir de la version 2.6.23 de Linux. L'objectif de CFS est de permettre à chaque processus d'obtenir une allocation raisonnable et équitable du temps CPU en fonction de son propre poids et de ses besoins, améliorant ainsi les performances globales et la vitesse de réponse du système. Cet article présentera les principes de base, la structure des données, les détails de mise en œuvre, les avantages et les inconvénients de CFS, et vous aidera à comprendre en profondeur l'équité totale de la planification des processus Linux.
Un bref historique du planificateur Linux
Les premiers planificateurs Linux utilisaient une conception minimaliste qui n'était clairement pas axée sur les grandes architectures dotées de nombreux processeurs, et encore moins sur l'hyper-threading. 1.2 Le planificateur Linux utilise une file d'attente en anneau pour la gestion des tâches exécutables et utilise une stratégie de planification à tour de rôle. Ce planificateur ajoute et supprime des processus de manière très efficace (avec des verrous protégeant la structure). Bref, le planificateur n'est pas complexe mais simple et rapide.
Linux version 2.2 a introduit le concept de classes de planification, permettant des stratégies de planification pour les tâches en temps réel, les tâches non préemptives et les tâches non en temps réel. Le planificateur 2.2 inclut également la prise en charge du multitraitement symétrique (SMP).
Le noyau 2.4 inclut un planificateur relativement simple qui s'exécute à intervalles O(N) (il itère sur chaque tâche pendant l'événement de planification). 2.4 Le planificateur divise le temps en époques. Dans chaque époque, chaque tâche est autorisée à s'exécuter jusqu'à ce que sa tranche de temps soit épuisée. Si une tâche n'utilise pas toutes ses tranches de temps, alors la moitié des tranches de temps restantes seront ajoutées à la nouvelle tranche de temps afin qu'elle puisse s'exécuter plus longtemps à l'époque suivante. Le planificateur parcourt simplement les tâches et applique une fonction de qualité (métrique) pour décider quelle tâche exécuter ensuite. Bien que cette méthode soit relativement simple, elle est inefficace, manque d’évolutivité et ne convient pas à une utilisation dans des systèmes temps réel. Il lui manque également la capacité de tirer parti des nouvelles architectures matérielles, telles que les processeurs multicœurs.
Le premier planificateur 2.6, appelé planificateur O(1), a été conçu pour résoudre un problème avec le planificateur 2.4 : le planificateur n'avait pas besoin de parcourir toute la liste des tâches pour déterminer la prochaine tâche à planifier (d'où le nom O( 1) , ce qui signifie qu'il est plus efficace et évolutif). Le planificateur O(1) garde une trace des tâches exécutables dans la file d'attente d'exécution (en fait, il y a deux files d'attente d'exécution par niveau de priorité - une pour les tâches actives et une pour les tâches expirées), ce qui signifie déterminer quelles tâches exécuter la tâche suivante, la le planificateur retire simplement la tâche suivante de la file d'attente d'exécution d'une activité spécifique par priorité). Le planificateur O(1) s'adapte mieux et inclut l'interactivité, fournissant une multitude d'informations permettant de déterminer si une tâche est liée aux E/S ou au processeur. Mais le planificateur O(1) est maladroit dans le noyau. Nécessite beaucoup de code pour calculer les révélations, est difficile à gérer et, pour les puristes, ne parvient pas à capturer l'essence de l'algorithme.
Pour résoudre les problèmes rencontrés par le planificateur O(1) et pour faire face à d'autres pressions externes, quelque chose doit être changé. Ce changement vient du patch du noyau de Con Kolivas, qui inclut son Rotating Staircase Deadline Scheduler (RSDL), qui intègre ses premiers travaux sur le planificateur d'escalier. Le résultat de ce travail est un planificateur de conception simple qui intègre équité et latence limitée. Le planificateur de Kolivas attirant beaucoup d'attention (et beaucoup réclament son inclusion dans le noyau courant 2.6.21 actuel), il est clair que des changements dans le planificateur sont à venir. Ingo Molnar, le créateur de l'ordonnanceur O(1), a ensuite développé un ordonnanceur basé sur CFS autour de certaines idées de Kolivas. Analysons le CFS et voyons comment il fonctionne à un niveau élevé.
———————————————————————————————————————
L'idée principale derrière CFS est de maintenir l'équilibre (équité) en termes de temps de processeur alloué aux tâches. Cela signifie que les processus doivent se voir attribuer un nombre important de processeurs. Lorsque le temps alloué à une tâche est déséquilibré (ce qui signifie qu’une ou plusieurs tâches ne disposent pas d’un temps significatif par rapport à d’autres tâches), la tâche déséquilibrée doit avoir le temps de s’exécuter.
Pour atteindre l'équilibre, CFS maintient le temps accordé à une tâche dans ce qu'on appelle un environnement d'exécution virtuel. Plus le temps d'exécution virtuel d'une tâche est petit, plus le temps pendant lequel la tâche est autorisée à accéder au serveur est court – plus la demande sur le processeur est élevée. CFS inclut également le concept d'équité du sommeil pour garantir que les tâches qui ne sont pas en cours d'exécution (par exemple, en attente d'E/S) obtiennent une part équitable du processeur lorsqu'elles en ont éventuellement besoin.
Mais contrairement aux planificateurs Linux précédents, qui ne maintenaient pas les tâches dans une file d'attente d'exécution, CFS maintenait une arborescence rouge-noir classée dans le temps (voir Figure 1). Un arbre rouge-noir est un arbre doté de nombreuses propriétés intéressantes et utiles. Premièrement, il est auto-équilibré, ce qui signifie qu’aucun chemin dans l’arbre n’est plus de deux fois plus long qu’un autre chemin. Deuxièmement, l'exécution sur l'arborescence se produit en un temps O (log n) (où n est le nombre de nœuds dans l'arborescence). Cela signifie que vous pouvez insérer ou supprimer des tâches rapidement et efficacement.
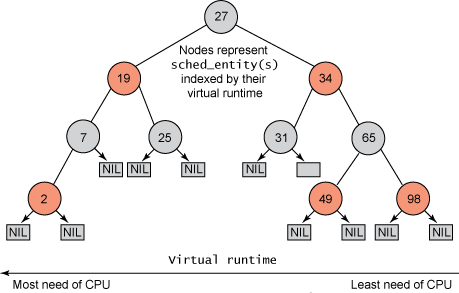
Les tâches sont stockées dans une arborescence rouge-noir ordonnée dans le temps (représentée par sched_entity objets), avec les tâches les plus exigeantes en termes de processeur (temps d'exécution virtuel le plus bas) stockées sur le côté gauche de l'arborescence et les tâches les moins exigeantes en termes de processeur ( le temps d'exécution virtuel le plus élevé) est stocké sur le côté droit de l'arborescence. Par souci d'équité, le planificateur sélectionne ensuite le nœud le plus à gauche de l'arborescence rouge-noir à planifier ensuite pour maintenir l'équité. Une tâche comptabilise son temps CPU en ajoutant son temps d'exécution au runtime virtuel, puis, si elle est exécutable, en la réinsérant dans l'arborescence. De cette façon, les tâches situées sur le côté gauche de l’arborescence ont le temps de s’exécuter et le contenu de l’arborescence est migré de droite à gauche pour maintenir l’équité. Par conséquent, chaque tâche exécutable rattrape les autres tâches pour maintenir l’équilibre d’exécution sur l’ensemble des tâches exécutables.
———————————————————————————————————————
Toutes les tâches sous Linux sont organisées par task_struct. Cette structure (et tout autre contenu associé) décrit complètement la tâche et inclut l'état actuel de la tâche, sa pile, l'identité du processus, la priorité (statique et dynamique), etc. Vous pouvez trouver ces structures et celles associées dans ./linux/include/linux/sched.h. Mais comme toutes les tâches ne sont pas exécutables, vous avez , Menlo, monospace;color: #10f5d6c">task_struct ne trouvera aucun champ lié au CFS. Au lieu de cela, une nouvelle structure appelée task_struct 的任务结构表示。该结构(以及其他相关内容)完整地描述了任务并包括了任务的当前状态、其堆栈、进程标识、优先级(静态和动态)等等。您可以在 ./linux/include/linux/sched.h 中找到这些内容以及相关结构。 但是因为不是所有任务都是可运行的,您在 task_struct 中不会发现任何与 CFS 相关的字段。 相反,会创建一个名为 sched_entity est créée pour suivre les informations de planification (voir Figure 2).
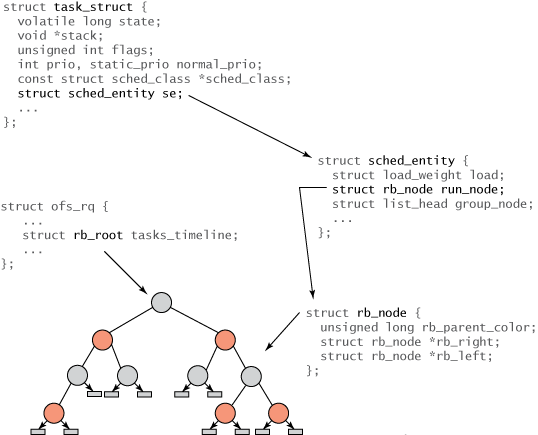
La relation entre les différentes structures est illustrée à la figure 2. La racine de l'arbre traverse la structure rb_root 元素通过 cfs_rq 结构(在 ./kernel/sched.c 中)引用。红黑树的叶子不包含信息,但是内部节点代表一个或多个可运行的任务。红黑树的每个节点都由 rb_node 表示,它只包含子引用和父对象的颜色。 rb_node 包含在sched_entity 结构中,该结构包含 rb_node 引用、负载权重以及各种统计数据。最重要的是, sched_entity 包含 vruntime(64 位字段),它表示任务运行的时间量,并作为红黑树的索引。 最后,task_struct 位于顶端,它完整地描述任务并包含 sched_entity.
En ce qui concerne la partie CFS, la fonction de planification est très simple. Dans ./kernel/sched.c, vous verrez la référence générique schedule() 函数,它会先抢占当前运行任务(除非它通过yield() 代码先抢占自己)。注意 CFS 没有真正的时间切片概念用于抢占,因为抢占时间是可变的。 当前运行任务(现在被抢占的任务)通过对 put_prev_task 调用(通过调度类)返回到红黑树。 当 schedule 函数开始确定下一个要调度的任务时,它会调用 pick_next_task函数。此函数也是通用的(在 ./kernel/sched.c 中),但它会通过调度器类调用 CFS 调度器。 CFS 中的 pick_next_task 函数可以在 ./kernel/sched_fair.c(称为 pick_next_task_fair())中找到。 此函数只是从红黑树中获取最左端的任务并返回相关 sched_entity。通过此引用,一个简单的 task_of() 调用确定返回的 task_struct. Le planificateur universel fournit enfin le processeur pour cette tâche.
———————————————————————————————————————
CFS n'utilise pas directement la priorité mais l'utilise comme facteur de décroissance pour la durée pendant laquelle une tâche est autorisée à s'exécuter. Les tâches peu prioritaires ont un coefficient de décroissance plus élevé, tandis que les tâches hautement prioritaires ont un coefficient de décroissance plus faible. Cela signifie que le temps alloué à l'exécution des tâches est plus rapide pour les tâches de faible priorité que pour les tâches de haute priorité. Il s’agit d’une solution intéressante pour éviter de maintenir une file d’attente d’exécution planifiée en priorité.
Un autre aspect intéressant de CFS est le concept de planification de groupe (introduit dans le noyau 2.6.24). La planification de groupe est un autre moyen d'apporter de l'équité à la planification, en particulier lorsqu'il s'agit de tâches qui engendrent de nombreuses autres tâches. Supposons qu'un serveur qui génère de nombreuses tâches souhaite paralléliser les connexions entrantes (une architecture typique pour les serveurs HTTP). Toutes les tâches ne sont pas traitées de manière uniforme et équitable, et CFS introduit des groupes pour gérer ce comportement. Les processus serveur qui génèrent des tâches partagent leurs environnements d'exécution virtuels au sein du groupe (dans une hiérarchie), tandis que les tâches individuelles conservent leurs propres environnements d'exécution virtuels indépendants. De cette façon, les tâches individuelles reçoivent à peu près le même temps de planification que le groupe. Vous constaterez que l'interface /proc est utilisée pour gérer les hiérarchies de processus, vous donnant un contrôle total sur la façon dont les groupes sont formés. Grâce à cette configuration, vous pouvez répartir l'équité entre les utilisateurs, les processus ou leurs variantes.
Le concept de classe de planification est introduit avec CFS (rappelez-vous la figure 2). Chaque tâche appartient à une classe de planification, qui détermine la manière dont la tâche sera planifiée. La classe de planification définit un ensemble général de fonctions (via sched_class),函数集定义调度器的行为。例如,每个调度器提供一种方式, 添加要调度的任务、调出要运行的下一个任务、提供给调度器等等。每个调度器类都在一对一连接的列表中彼此相连,使类可以迭代(例如, 要启用给定处理器的禁用)。一般结构如图 3 所示。注意,将任务函数加入队列或脱离队列只需从特定调度结构中加入或移除任务。 函数 pick_next_task pour sélectionner la prochaine tâche à exécuter (en fonction de la stratégie spécifique de la classe de planification).

Mais n'oubliez pas que la classe de planification fait partie de la structure de la tâche elle-même (voir Figure 2). Cela simplifie le fonctionnement des tâches quelle que soit leur classe de planification. Par exemple, la fonction suivante préempte la tâche en cours d'exécution (où curr 定义了当前运行任务, rq 代表 CFS 红黑树而 p est la prochaine tâche à planifier) avec une nouvelle tâche dans ./kernel/sched.c :
static inline void check_preempt( struct rq *rq, struct task_struct *p )
{
rq->curr->sched_class->check_preempt_curr( rq, p );
}
Si cette tâche utilise la classe de planification équitable, alors check_preempt_curr() 将解析为 check_preempt_wakeup(). Vous pouvez afficher ces relations dans ./kernel/sched_rt.c, ./kernel/sched_fair.c et ./kernel/sched_idle.c.
Les cours de planification sont un autre endroit intéressant où la planification change, mais à mesure que le domaine de planification augmente, la fonctionnalité augmente également. Ces domaines vous permettent de regrouper hiérarchiquement un ou plusieurs processeurs à des fins d'équilibrage de charge et d'isolation. Un ou plusieurs processeurs peuvent partager une politique de planification (et maintenir un équilibrage de charge entre eux) ou mettre en œuvre des politiques de planification indépendantes pour isoler intentionnellement les tâches.
Continuez à étudier la planification et vous trouverez des planificateurs en cours de développement qui repousseront les limites de la performance et de l'évolutivité. Sans se laisser décourager par son expérience Linux, Con Kolivas a développé un autre planificateur Linux, abrégé en : BFS. Le planificateur aurait de meilleures performances sur les systèmes NUMA et les appareils mobiles et a été introduit dans un dérivé du système d'exploitation Android.
Grâce à cet article, vous devriez avoir une compréhension de base de CFS. Il s'agit de l'un des algorithmes de planification de processus les plus avancés et les plus efficaces des systèmes Linux. Il utilise des arbres rouge-noir pour stocker les files d'attente de processus exécutables et calcule le temps d'exécution virtuel pour mesurer le temps d'exécution. l'équité du processus, la vitesse de réponse du processus interactif est améliorée par la mise en œuvre de la fonction de préemption de réveil, permettant ainsi d'obtenir une équité totale dans la planification du processus. Bien sûr, CFS n'est pas parfait. Il présente certains problèmes et limites potentiels, tels qu'une surcompensation des processus de veille actifs, une prise en charge insuffisante des processus en temps réel, une sous-utilisation des processeurs multicœurs, etc., qui doivent être résolus dans versions futures. Apporter des améliorations et des optimisations. En bref, CFS est un composant indispensable du système Linux et mérite votre étude et votre maîtrise approfondies.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



