

Lors de l'utilisation du système d'exploitation Linux, nous devons souvent gérer et configurer des périphériques de stockage. Parmi eux, la résolution et le partitionnement des périphériques de stockage sont l'une des tâches de gestion courantes. Comprendre comment effectuer l'analyse et le partitionnement du stockage peut nous aider à mieux utiliser les ressources de stockage et à améliorer les performances du système. Cet article présentera les connaissances pertinentes sur l'analyse et le partitionnement des périphériques de stockage dans les systèmes Linux.
Lors de l'utilisation de C/C++ pour la programmation multithread dans les systèmes Linux, le problème le plus courant que nous rencontrons est la lecture et l'écriture multithread de la même variable. Dans la plupart des cas, ces problèmes sont traités via le mécanisme de verrouillage, mais c'est le cas. les performances du programme ont un grand impact. Bien entendu, pour les types de données pour lesquels le système prend en charge nativement les opérations atomiques, nous pouvons utiliser des opérations atomiques pour les traiter, ce qui améliorera dans une certaine mesure les performances du programme. Ainsi, pour les types de données personnalisés dont les systèmes ne prennent pas en charge les opérations atomiques, comment pouvons-nous assurer la sécurité des threads sans utiliser de verrous ? Cet article explique brièvement comment gérer ce type de problème de sécurité des threads du point de vue du stockage local des threads.
1.Type de données
Dans les programmes C/C++, il existe souvent des variables globales, des variables statiques définies dans les fonctions et des variables locales. Pour les variables locales, il n'y a pas de problème de sécurité des threads, elles n'entrent donc pas dans le cadre de cet article. Les variables globales et les variables statiques définies dans les fonctions sont des variables partagées accessibles par tous les threads du même processus, elles présentent donc des problèmes de lecture et d'écriture multithread. Lorsque le contenu d'une variable est modifié dans un thread, d'autres threads peuvent percevoir et lire le contenu modifié. Ceci est très rapide pour l'échange de données. Cependant, en raison de l'existence de multi-threads, il peut y avoir des contenus différents pour la même variable. . Deux threads ou plus modifient le contenu de la mémoire de la variable en même temps, et plusieurs threads lisent la valeur de la mémoire lorsque la variable est modifiée. Si le mécanisme de synchronisation correspondant n'est pas utilisé pour protéger la mémoire, alors toutes les données sont lues. sera imprévisible et peut même provoquer le crash du programme.
Si vous avez besoin d'une variable accessible par chaque appel de fonction dans un thread mais non accessible par d'autres threads, un nouveau mécanisme est nécessaire pour l'implémenter. Nous l'appelons mémoire statique locale à un thread (variable statique locale du thread), et. Il peut également être appelé données spécifiques au thread (TSD : Thread-Specific Data) ou stockage local au thread (TLS : Thread-Local Storage). Pour ce type de données, chaque thread du programme conservera une copie de la variable, et elle existera dans ce thread pendant une longue période. Les opérations sur ces variables n'affecteront pas les autres threads. Comme indiqué ci-dessous : 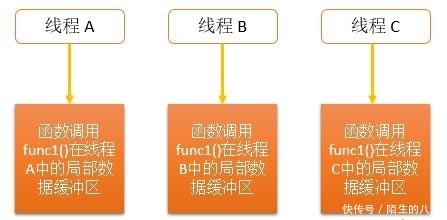
2. Initialisation unique
Avant d'expliquer les données spécifiques au thread, comprenons d'abord l'initialisation unique. Les programmes multithread ont parfois une telle exigence : quel que soit le nombre de threads créés, l'initialisation de certaines données ne peut avoir lieu qu'une seule fois. Par exemple : dans un programme C++, un seul objet instance d'une certaine classe peut exister tout au long du cycle de vie du processus, afin de permettre l'initialisation de l'objet en toute sécurité, l'initialisation unique. Le mécanisme est particulièrement important. ——Dans les modèles de conception, cette implémentation est souvent appelée modèle singleton (Singleton). Linux fournit les fonctions suivantes pour réaliser une initialisation unique :
#include
// Returns 0 on success, or a positive error number on error
int pthread_once (pthread_once_t *once_control, void (*init) (void));
利用参数once_control的状态,函数pthread_once()可以确保无论有多少个线程调用多少次该函数,也只会执行一次由init所指向的由调用者定义的函数。init所指向的函数没有任何参数,形式如下:
void init (void)
{
// some variables initializtion in here
}
De plus, le paramètre once_control doit être un pointeur vers une variable de type pthread_once_t, pointant vers une variable statique initialisée à PTHRAD_ONCE_INIT. Après C++0x, une fonction std::call_once() avec des fonctions similaires est fournie et son utilisation est similaire à cette fonction.
3. API de données locales de discussion
Les fonctions suivantes sont fournies sous Linux pour exploiter les données locales des threads
#include // Returns 0 on success, or a positive error number on error int pthread_key_create (pthread_key_t *key, void (*destructor)(void *)); // Returns 0 on success, or a positive error number on error int pthread_key_delete (pthread_key_t key); // Returns 0 on success, or a positive error number on error int pthread_setspecific (pthread_key_t key, const void *value); // Returns pointer, or NULL if no thread-specific data is associated with key void *pthread_getspecific (pthread_key_t key);
La fonction pthread_key_create() crée une nouvelle clé pour les données locales du thread et pointe vers le tampon de clé nouvellement créé via key. Étant donné que tous les threads peuvent utiliser la nouvelle clé renvoyée, la clé de paramètre peut être une variable globale (les variables globales ne sont généralement pas utilisées dans la programmation multithread C++, mais des classes distinctes sont utilisées pour encapsuler les données locales du thread, et chaque variable utilise une variable indépendante. pthread_key_t). Le destructeur pointe vers une fonction personnalisée au format suivant :
void Dest (void *value)
{
// Release storage pointed to by 'value'
}
只要线程终止时与key关联的值不为NULL,则destructor所指的函数将会自动被调用。如果一个线程中有多个线程局部存储变量,那么对各个变量所对应的destructor函数的调用顺序是不确定的,因此,每个变量的destructor函数的设计应该相互独立。
函数pthread_key_delete()并不检查当前是否有线程正在使用该线程局部数据变量,也不会调用清理函数destructor,而只是将其释放以供下一次调用pthread_key_create()使用。在Linux线程中,它还会将与之相关的线程数据项设置为NULL。
由于系统对每个进程中pthread_key_t类型的个数是有限制的,所以进程中并不能创建无限个的pthread_key_t变量。Linux中可以通过PTHREAD_KEY_MAX(定义于limits.h文件中)或者系统调用sysconf(_SC_THREAD_KEYS_MAX)来确定当前系统最多支持多少个键。Linux中默认是1024个键,这对于大多数程序来说已经足够了。如果一个线程中有多个线程局部存储变量,通常可以将这些变量封装到一个数据结构中,然后使封装后的数据结构与一个线程局部变量相关联,这样就能减少对键值的使用。
函数pthread_setspecific()用于将value的副本存储于一数据结构中,并将其与调用线程以及key相关联。参数value通常指向由调用者分配的一块内存,当线程终止时,会将该指针作为参数传递给与key相关联的destructor函数。当线程被创建时,会将所有的线程局部存储变量初始化为NULL,因此第一次使用此类变量前必须先调用pthread_getspecific()函数来确认是否已经于对应的key相关联,如果没有,那么pthread_getspecific()会分配一块内存并通过pthread_setspecific()函数保存指向该内存块的指针。
参数value的值也可以不是一个指向调用者分配的内存区域,而是任何可以强制转换为void的变量值,在这种情况下,先前的pthread_key_create()函数应将参数
destructor设置为NULL
函数pthread_getspecific()正好与pthread_setspecific()相反,其是将pthread_setspecific()设置的value取出。在使用取出的值前最好是将void转换成原始数据类型的指针。
四、深入理解线程局部存储机制
\1. 深入理解线程局部存储的实现有助于对其API的使用。在典型的实现中包含以下数组:
pthread_key_create()返回的pthread_key_t类型值只是对全局数组的索引,该全局数组标记为pthread_keys,其格式大概如下:
数组的每个元素都是一个包含两个字段的结构,第一个字段标记该数组元素是否在用,第二个字段用于存放针对此键、线程局部存储变的解构函数的一个副本,即destructor函数。
\2. 在常见的存储pthread_setspecific()函数参数value的实现中,大多数都类似于下图的实现。图中假设pthread_keys[1]分配给func1()函数,pthread API为每个函数维护指向线程局部存储数据块的一个指针数组,其中每个数组元素都与图线程局部数据键的实现(上图)中的全局pthread_keys中元素一一对应。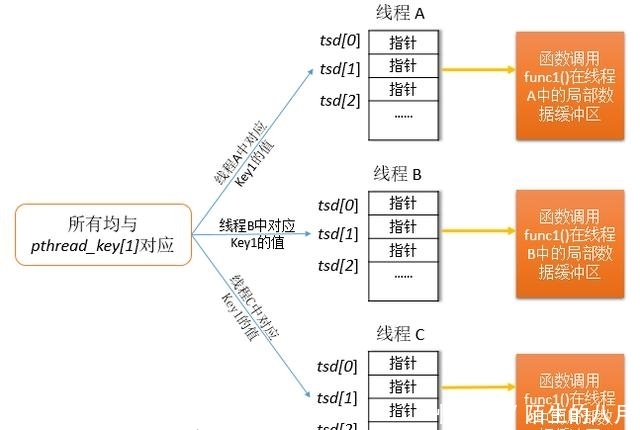
五、总结
使用全局变量或者静态变量是导致多线程编程中非线程安全的常见原因。在多线程程序中,保障非线程安全的常用手段之一是使用互斥锁来做保护,这种方法带来了并发性能下降,同时也只能有一个线程对数据进行读写。如果程序中能避免使用全局变量或静态变量,那么这些程序就是线程安全的,性能也可以得到很大的提升。如果有些数据只能有一个线程可以访问,那么这一类数据就可以使用线程局部存储机制来处理,虽然使用这种机制会给程序执行效率上带来一定的影响,但对于使用锁机制来说,这些性能影响将可以忽略。更高性能的线程局部存储机制就是使用__thread,这个以后再讨论。
需要C/C++ Linux服务器开发学习资料私信“资料”(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
本文介绍了Linux系统中存储设备解析和分区的相关知识,包括使用fdisk命令、使用parted命令、使用mkfs命令等。了解这些知识,可以帮助我们更好地管理和配置存储设备,优化系统性能。希望读者能够根据实际需求选择适合自己的方法,并加以应用。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



