

Le cœur des systèmes distribués - les journaux

Un journal est une séquence complètement ordonnée d'enregistrements ajoutés par ordre chronologique. Il s'agit en fait d'un format de fichier spécial. Le fichier est un tableau d'octets, et le journal ici est une donnée d'enregistrement, mais par rapport au fichier, chaque élément ici est un enregistrement. organisé dans un ordre relatif dans le temps.On peut dire que le journal est le modèle de stockage le plus simple.Par exemple, les files d'attente de messages écrivent généralement de manière linéaire dans le fichier journal.L'ordre du consommateur commence à partir du décalage. .
En raison des caractéristiques inhérentes du journal lui-même, les enregistrements sont insérés séquentiellement de gauche à droite, ce qui signifie que les enregistrements de gauche sont « plus anciens » que ceux de droite. En d'autres termes, nous n'avons pas besoin de nous fier aux enregistrements. horloge système. Cette fonctionnalité est très utile pour les distributions très importantes pour le système.
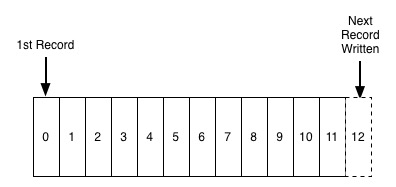
Il est impossible de savoir quand le journal est apparu. Il se peut que son concept soit trop simple. Dans le domaine de la base de données, les journaux sont davantage utilisés pour synchroniser les données et les index lorsque le système tombe en panne, comme le journal redo dans MySQL. Le journal redo est une structure de données basée sur le disque utilisée pour garantir l'exactitude et l'exhaustivité des données en cas de panne du système. Le système est également appelé journaux à écriture anticipée. Par exemple, lors de l'exécution d'une chose, le journal redo sera écrit en premier, puis les modifications réelles seront appliquées de cette façon, lorsque le système récupère après un crash. réécrit en fonction du journal redo. Remettez-le pour restaurer les données (pendant le processus d'initialisation, il n'y aura pas de connexion client pour le moment). Le journal peut également être utilisé pour la synchronisation entre le maître et l'esclave de la base de données, car essentiellement, tous les enregistrements d'opérations de la base de données ont été écrits dans le journal. Il nous suffit de synchroniser le journal avec l'esclave et de le relire sur l'esclave pour devenir maître. -synchronisation esclave. De nombreux autres composants requis peuvent également être implémentés ici. Nous pouvons obtenir toutes les modifications dans la base de données en nous abonnant au redo log, implémentant ainsi une logique métier personnalisée, telle que l'audit, la synchronisation du cache, etc.
Les services système distribués concernent essentiellement les changements d'état, qui peuvent être compris comme des machines à états. Deux processus indépendants (ne dépendant pas de l'environnement externe, comme les horloges système, les interfaces externes, etc.) produiront des sorties cohérentes avec des entrées cohérentes et, en fin de compte, les maintiendront. un état cohérent et le journal ne dépend pas de l'horloge système en raison de sa séquence inhérente, qui peut être utilisée pour résoudre le problème de l'ordre de modification.
Nous utilisons cette fonctionnalité pour résoudre de nombreux problèmes rencontrés dans les systèmes distribués. Par exemple, dans le nœud de veille de RocketMQ, le courtier principal reçoit la demande du client et enregistre le journal, puis le synchronise avec l'esclave en temps réel. L'esclave le relit localement. Lorsque le maître raccroche, l'esclave peut continuer à le faire. traiter la demande, par exemple rejeter la demande d'écriture et continuer. Gérer les demandes de lecture. Le journal peut non seulement enregistrer des données, mais également enregistrer directement des opérations, telles que des instructions SQL.
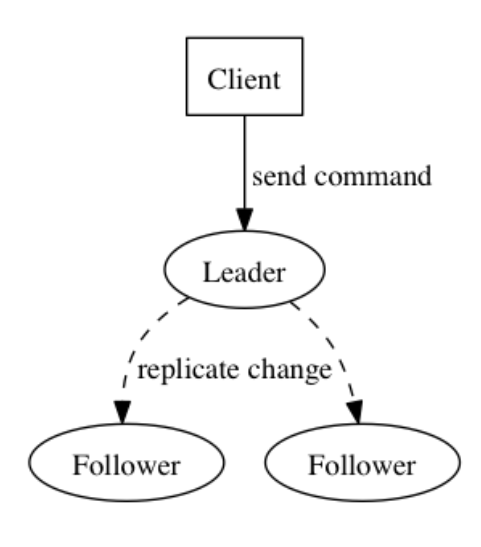
Le journal est la structure de données clé pour résoudre le problème de cohérence. Le journal est comme une séquence d'opérations. Par exemple, les protocoles Paxos et Raft largement utilisés sont tous des protocoles de cohérence construits sur la base du journal.
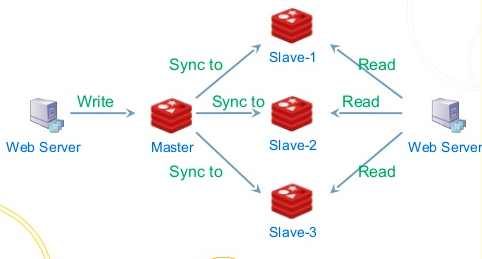
Les journaux peuvent être facilement utilisés pour gérer les entrées et les sorties de données. Chaque source de données peut générer son propre journal. Les sources de données ici peuvent provenir de divers aspects, tels qu'un flux d'événements (clic sur une page, rappel d'actualisation du cache, modifications du journal binaire de la base de données). ), nous pouvons stocker les journaux de manière centralisée dans un cluster, et les abonnés peuvent lire chaque enregistrement du journal en fonction du décalage et appliquer leurs propres modifications en fonction des données et des opérations dans chaque enregistrement.
Le journal ici peut être compris comme une file d'attente de messages, et la file d'attente de messages peut jouer le rôle de découplage asynchrone et de limitation de courant. Pourquoi parle-t-on de découplage ? Parce que pour les consommateurs et les producteurs, les responsabilités des deux rôles sont très claires, ils sont responsables de produire des messages et de consommer des messages, sans se soucier de qui est en aval ou en amont, qu'il s'agisse du journal des modifications de la base de données ou d'un certain événement. Je n'ai pas du tout besoin de me soucier d'une certaine partie. Je dois seulement faire attention aux journaux qui m'intéressent et à chaque enregistrement dans les journaux.
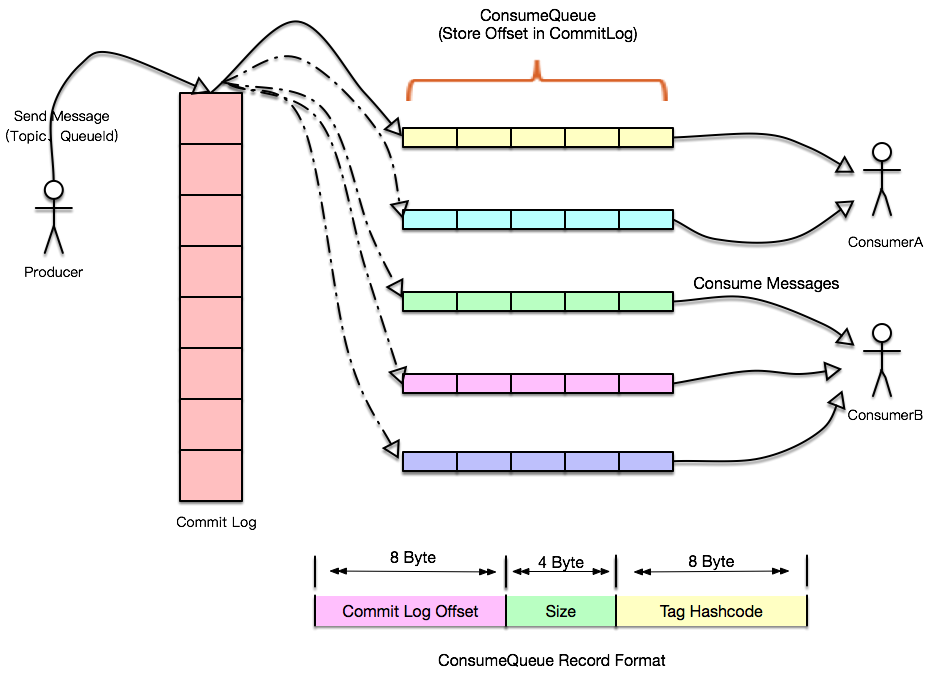
Nous savons que le QPS de la base de données est certain et que les applications de couche supérieure peuvent généralement être étendues horizontalement. À ce stade, s'il y a un scénario de demande soudaine comme Double 11, la base de données sera submergée, nous pouvons alors introduire des files d'attente de messages. pour combiner les opérations de la base de données de chaque équipe Écrivez dans le journal, et une autre application est responsable de la consommation de ces enregistrements de journal et de leur application à la base de données. Même si la base de données se bloque, le traitement peut continuer à partir de la position du dernier message lors de la récupération (les deux). RocketMQ et Kafka prennent en charge la sémantique Exactly Once), ici même si la vitesse du producteur est différente de la vitesse du consommateur, il n'y aura aucun impact ici. Il peut stocker tous les enregistrements dans le journal et les synchroniser. au nœud esclave régulièrement, de sorte que le message La capacité du backlog peut être considérablement améliorée car l'écriture des journaux est traitée par le nœud maître. Il existe deux types de demandes de lecture. L'une est la lecture finale, ce qui signifie que la vitesse de consommation peut suivre. avec la vitesse d'écriture. Ce type de lecture Vous pouvez accéder directement au cache, et l'autre est le consommateur qui est en retard sur la demande d'écriture. Ce type de lecture peut être lu à partir du nœud esclave, via l'isolation des E/S et certaines politiques de fichiers qui viennent. avec le système d'exploitation, tel que le cache de page, la lecture anticipée du cache, etc., les performances peuvent être considérablement améliorées.
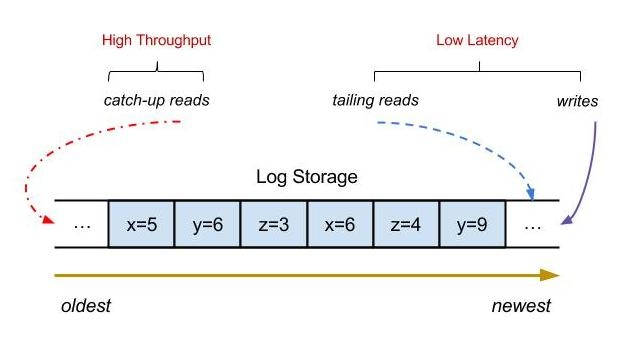
L'évolutivité horizontale est une fonctionnalité très importante dans un système distribué. Les problèmes qui peuvent être résolus en ajoutant des machines ne sont pas un problème. Alors, comment implémenter une file d'attente de messages capable de réaliser une expansion horizontale ? Si nous avons une file d'attente de messages autonome, à mesure que le nombre de sujets augmente, les E/S, le processeur, la bande passante, etc. comment procéder ici ? Qu'en est-il de l'optimisation des performances ?
- Partage de sujet/journal. Essentiellement, les messages écrits par le sujet sont les enregistrements du journal. À mesure que le nombre d'écritures augmente, une seule machine deviendra lentement un goulot d'étranglement. À ce stade, nous pouvons diviser un seul sujet en plusieurs sous. -sujets. Et attribuez chaque sujet à une machine différente. De cette manière, les sujets contenant une grande quantité de messages peuvent être résolus en ajoutant des machines, tandis que certains sujets contenant une petite quantité de messages peuvent être attribués à la même machine ou ne pas être traités. . Partitionner
- La validation de groupe, telle que le client producteur de Kafka, lors de l'écriture des messages, les écrit d'abord dans une file d'attente de mémoire locale, puis résume les messages en fonction de chaque partition et nœud, et les soumet par lots. Pour le côté serveur ou côté courtier, cela peut. également En utilisant cette méthode, le cache des pages est écrit en premier, puis le disque est vidé régulièrement. La méthode de vidage peut être déterminée en fonction de l'entreprise. Par exemple, les services financiers peuvent adopter une méthode de vidage synchrone.
- Évitez les copies de données inutiles
- Isolement IO

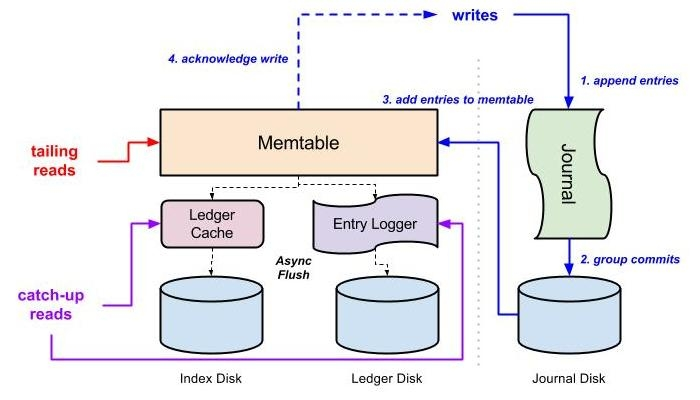
Les journaux jouent un rôle très important dans les systèmes distribués et sont la clé pour comprendre divers composants des systèmes distribués. À mesure que notre compréhension s'approfondit, nous constatons que de nombreux middleware distribués sont construits sur la base de journaux, tels que Zookeeper, HDFS, Kafka, RocketMQ, Google. Spanner, etc., et même des bases de données telles que Redis, MySQL, etc., leur maître-esclave est basé sur la synchronisation des journaux. En nous appuyant sur le système de journaux partagés, nous pouvons implémenter de nombreux systèmes : synchronisation des données et concurrence entre les nœuds. Problèmes d'ordre des données de mise à jour. (problèmes de cohérence), de persistance (le système peut continuer à fournir des services via d'autres nœuds lorsque le système tombe en panne), de services de verrouillage distribués, etc. Je crois que grâce à la pratique et à la lecture d'un grand nombre d'articles, il y aura des niveaux de compréhension plus profonds. compréhension.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Android TV Box obtient une mise à niveau non officielle d'Ubuntu 24.04
Sep 05, 2024 am 06:33 AM
Android TV Box obtient une mise à niveau non officielle d'Ubuntu 24.04
Sep 05, 2024 am 06:33 AM
Pour de nombreux utilisateurs, pirater un boîtier Android TV semble intimidant. Cependant, le développeur Murray R. Van Luyn a dû relever le défi de rechercher des alternatives appropriées au Raspberry Pi pendant la pénurie de puces Broadcom. Ses efforts de collaboration avec l'Armbia
 Entrée de la version Web Deepseek Entrée du site officiel Deepseek
Feb 19, 2025 pm 04:54 PM
Entrée de la version Web Deepseek Entrée du site officiel Deepseek
Feb 19, 2025 pm 04:54 PM
Deepseek est un puissant outil de recherche et d'analyse intelligent qui fournit deux méthodes d'accès: la version Web et le site officiel. La version Web est pratique et efficace et peut être utilisée sans installation; Que ce soit des individus ou des utilisateurs d'entreprise, ils peuvent facilement obtenir et analyser des données massives via Deepseek pour améliorer l'efficacité du travail, aider la prise de décision et promouvoir l'innovation.
 Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Comment installer Deepseek
Feb 19, 2025 pm 05:48 PM
Il existe de nombreuses façons d'installer Deepseek, notamment: Compiler à partir de Source (pour les développeurs expérimentés) en utilisant des packages précompilés (pour les utilisateurs de Windows) à l'aide de conteneurs Docker (pour le plus pratique, pas besoin de s'inquiéter de la compatibilité), quelle que soit la méthode que vous choisissez, veuillez lire Les documents officiels documentent soigneusement et les préparent pleinement à éviter des problèmes inutiles.
 Adresse de téléchargement de l'application de portefeuille BitPie Bitpie
Sep 10, 2024 pm 12:10 PM
Adresse de téléchargement de l'application de portefeuille BitPie Bitpie
Sep 10, 2024 pm 12:10 PM
Comment télécharger l'application BitPie Bitpie Wallet ? Les étapes sont les suivantes : Recherchez « BitPie Bitpie Wallet » dans l'AppStore (appareils Apple) ou Google Play Store (appareils Android). Cliquez sur le bouton « Obtenir » ou « Installer » pour télécharger l'application. Pour la version informatique, visitez le site Web officiel du portefeuille BitPie et téléchargez le progiciel correspondant.
 Installation officielle du site officiel de Bitget (Guide du débutant 2025)
Feb 21, 2025 pm 08:42 PM
Installation officielle du site officiel de Bitget (Guide du débutant 2025)
Feb 21, 2025 pm 08:42 PM
Bitget est un échange de crypto-monnaie qui fournit une variété de services de trading, notamment le trading au comptant, le trading de contrats et les dérivés. Fondée en 2018, l'échange est basée à Singapour et s'engage à fournir aux utilisateurs une plate-forme de trading sûre et fiable. Bitget propose une variété de paires de trading, notamment BTC / USDT, ETH / USDT et XRP / USDT. De plus, l'échange a une réputation de sécurité et de liquidité et offre une variété de fonctionnalités telles que les types de commandes premium, le trading à effet de levier et le support client 24/7.
 Zabbix 3.4 Installation de la compilation du code source
Sep 04, 2024 am 07:32 AM
Zabbix 3.4 Installation de la compilation du code source
Sep 04, 2024 am 07:32 AM
1. Environnement d'installation (machine virtuelle Hyper-V) : $hostnamectlStatichostname:localhost.localdomainIconname:computer-vmChassis:vmMachineID:renwoles1d8743989a40cb81db696400BootID:renwoles272f4aa59935dcdd0d456501Virtualisation:microsoftOperatingSystem:CentOS Linux7 (Core )CPEOSNom :cpe :
 Le package d'installation OUYI OKX est directement inclus
Feb 21, 2025 pm 08:00 PM
Le package d'installation OUYI OKX est directement inclus
Feb 21, 2025 pm 08:00 PM
OUYI OKX, le premier échange mondial d'actifs numériques, a maintenant lancé un package d'installation officiel pour offrir une expérience de trading sûre et pratique. Le package d'installation OKX de OUYI n'a pas besoin d'être accessible via un navigateur. Le processus d'installation est simple et facile à comprendre.
 Obtenez le package d'installation Gate.io gratuitement
Feb 21, 2025 pm 08:21 PM
Obtenez le package d'installation Gate.io gratuitement
Feb 21, 2025 pm 08:21 PM
Gate.io est un échange de crypto-monnaie populaire que les utilisateurs peuvent utiliser en téléchargeant son package d'installation et en l'installant sur leurs appareils. Les étapes pour obtenir le package d'installation sont les suivantes: Visitez le site officiel de Gate.io, cliquez sur "Télécharger", sélectionnez le système d'exploitation correspondant (Windows, Mac ou Linux) et téléchargez le package d'installation sur votre ordinateur. Il est recommandé de désactiver temporairement les logiciels antivirus ou le pare-feu pendant l'installation pour assurer une installation fluide. Une fois terminé, l'utilisateur doit créer un compte Gate.io pour commencer à l'utiliser.
