
 Tutoriel système
Linux
Des trucs secs ! 9 architectures techniques performantes et à haute concurrence
Tutoriel système
Linux
Des trucs secs ! 9 architectures techniques performantes et à haute concurrence
Des trucs secs ! 9 architectures techniques performantes et à haute concurrence

La superposition est le modèle architectural le plus courant dans les systèmes d'applications d'entreprise. Elle divise le système en plusieurs parties dans la dimension horizontale, chaque partie est responsable d'une responsabilité relativement simple et unique, puis s'appuie et planifie les couches inférieures jusqu'à la couche supérieure. . forment un système complet.
Dans l'architecture en couches d'un site Web, il existe trois couches communes, à savoir la couche application, la couche service et la couche données. La couche application est spécifiquement responsable de l'affichage des activités et des vues ; la couche service fournit un support de services pour la couche application ; la base de données fournit des services d'accès au stockage de données, tels que des bases de données, des caches, des fichiers, des moteurs de recherche, etc.
L'architecture en couches est logique. En termes de déploiement physique, l'architecture à trois niveaux peut être déployée sur la même machine physique. Cependant, avec le développement de l'activité site Web, il est nécessaire de déployer les modules déjà en couches séparément, c'est-à-dire. , la structure à trois niveaux est déployée séparément sur différents serveurs, le site Web dispose de plus de ressources informatiques pour faire face à des visites toujours plus nombreuses.
Ainsi, bien que l'objectif initial du modèle d'architecture en couches soit de planifier une structure logique claire du logiciel pour faciliter le développement et la maintenance, dans le processus de développement du site Web, la structure en couches est cruciale pour que le site Web prenne en charge le développement d'une concurrence élevée. et direction distribuée.
Le site Web doit fonctionner en continu 7 × 24 heures, il doit donc disposer d'un mécanisme de redondance correspondant pour l'empêcher d'être accessible lorsqu'une certaine machine tombe en panne. La redondance peut être obtenue en déployant au moins deux serveurs pour former un cluster afin d'atteindre un niveau élevé. disponibilité du service. En plus des sauvegardes régulières, la base de données doit également mettre en œuvre des sauvegardes à chaud et à froid. Les centres de données de reprise après sinistre peuvent même être déployés à l’échelle mondiale.
Si la superposition consiste à diviser le logiciel horizontalement, alors le partitionnement consiste à diviser le logiciel verticalement.
Plus le site Web est grand, plus les fonctions sont complexes et plus il y a de types de services et de traitements de données. Séparer ces différentes fonctions et services et les regrouper en unités modulaires à forte cohésion et faible couplage contribuera non seulement au développement et à la maintenance du site Web. logiciel Il facilite également le déploiement distribué de différents modules et améliore les capacités de traitement simultané du site Web et les capacités d’extension des fonctions.
La granularité de la séparation peut être faible pour les grands sites Web. Par exemple, au niveau de l'application, différentes activités sont séparées, telles que les achats, les forums, la recherche et la publicité, en différentes applications. Des équipes opposées en sont responsables et sont déployées sur différents serveurs.
En utilisant l'asynchrone, la transmission de messages entre entreprises n'est pas un appel synchrone, mais une opération commerciale est divisée en plusieurs étapes, et chaque étape est exécutée de manière asynchrone pour la collaboration en partageant des données.
L'implémentation spécifique peut être traitée au sein d'un seul serveur via une mémoire partagée multithread ; dans un système distribué, une implémentation asynchrone peut être réalisée via des files d'attente de messages distribuées.
L'architecture asynchrone typique est la méthode producteur-consommateur, et il n'y a pas d'appel direct entre les deux.
Pour les grands sites Web, l'un des principaux objectifs de la superposition et de la séparation est de faciliter le déploiement distribué de modules divisés, c'est-à-dire de déployer différents modules sur différents serveurs et de travailler ensemble via des appels à distance. La distribution signifie que plus d'ordinateurs peuvent être utilisés pour effectuer le même travail. Plus il y a d'ordinateurs, plus il y a de ressources de processeur, de mémoire et de stockage, et plus la quantité d'accès simultanés et de données pouvant être traitées est grande, offrant ainsi à davantage d'utilisateurs Serve.
Dans les applications de sites Web, il existe plusieurs solutions distribuées couramment utilisées.
Applications et services distribués : le déploiement distribué de modules d'applications et de services en couches et séparés peut améliorer les performances et la concurrence des sites Web, accélérer le développement et la publication et réduire la consommation des ressources de connexion à la base de données.
Ressources statiques distribuées : les ressources statiques du site Web, telles que JS, CSS, images de logo et autres ressources, sont déployées de manière distribuée et adoptent des noms de domaine indépendants, ce que les gens appellent souvent la séparation des ressources statiques et dynamiques. Le déploiement distribué de ressources statiques peut réduire la pression de charge sur le serveur d'applications ; accélérer le chargement simultané du navigateur en utilisant des noms de domaine indépendants.
Données et stockage distribués : les grands sites Web doivent traiter des données massives en unités P. Un seul ordinateur ne peut pas fournir un espace de stockage aussi important. Ces bases de données nécessitent un stockage distribué.
Informatique distribuée : actuellement, les sites Web utilisent généralement les cadres informatiques distribués Hadoop et MapReduce pour ces calculs par lots, qui sont caractérisés par l'informatique mobile plutôt que par les données mobiles, et le programme informatique est distribué à l'emplacement des données pour accélérer le calcul et l'informatique distribuée.
Les sites Web disposent de nombreux modes en termes d'architecture de sécurité : l'authentification de l'identité via des mots de passe et des codes de vérification du téléphone mobile ; les communications réseau doivent être cryptées pour la connexion et les transactions afin d'empêcher les robots d'abuser des ressources, des codes de vérification doivent être utilisés pour l'identification ; attaques XSS courantes, l'injection SQL nécessite une conversion de codage ; les informations de spam doivent être filtrées, etc.
Plus précisément, cela comprend le processus de publication automatisé, la gestion automatisée du code, les tests automatisés, la détection de sécurité automatisée, le déploiement automatisé, la surveillance automatisée, les alarmes automatisées, le basculement automatisé, la récupération automatisée en cas de panne, etc.
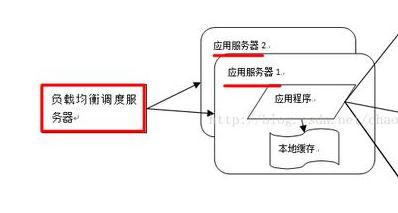
Pour les modules avec accès utilisateur centralisé, les serveurs déployés indépendamment doivent être regroupés, c'est-à-dire que plusieurs serveurs déploient la même application pour former un cluster et fournissent conjointement des services externes via un équipement d'équilibrage de charge.
Le cluster de serveurs peut fournir une prise en charge plus simultanée pour le même service, donc lorsque plus d'utilisateurs y accèdent, il vous suffit d'ajouter de nouvelles machines au cluster. De plus, lorsque l'un des serveurs tombe en panne, le mécanisme de basculement d'équilibrage de charge peut être utilisé ; pour transférer les requêtes vers d'autres serveurs du cluster, améliorant ainsi la disponibilité du système.
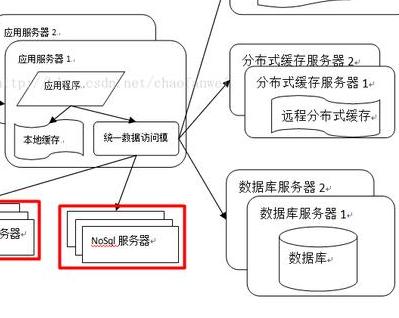
Le but de la mise en cache est de réduire le calcul du serveur afin que les données puissent être restituées directement à l'utilisateur. Dans la conception logicielle actuelle, la mise en cache est omniprésente. Les implémentations spécifiques incluent CDN, proxy inverse, cache local, cache distribué, etc.
Il existe deux conditions pour utiliser le cache : un accès déséquilibré aux points d'accès aux données, c'est-à-dire que certaines données fréquemment consultées doivent être placées dans le cache ; les données sont valides pendant une certaine période de temps, mais expireront bientôt, sinon une lecture sale se produira en raison de l'expiration des données, affectant l'exactitude des données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Comment résoudre les problèmes d'autorisation lors de l'utilisation de la commande python --version dans le terminal Linux?
Apr 02, 2025 am 06:36 AM
Utilisation de Python dans Linux Terminal ...
 Quatre façons d'implémenter le multithreading dans le langage C
Apr 03, 2025 pm 03:00 PM
Quatre façons d'implémenter le multithreading dans le langage C
Apr 03, 2025 pm 03:00 PM
Le multithreading dans la langue peut considérablement améliorer l'efficacité du programme. Il existe quatre façons principales d'implémenter le multithreading dans le langage C: créer des processus indépendants: créer plusieurs processus en cours d'exécution indépendante, chaque processus a son propre espace mémoire. Pseudo-Multithreading: Créez plusieurs flux d'exécution dans un processus qui partagent le même espace mémoire et exécutent alternativement. Bibliothèque multi-thread: Utilisez des bibliothèques multi-threades telles que PTHEADS pour créer et gérer des threads, en fournissant des fonctions de fonctionnement de thread riches. Coroutine: une implémentation multi-thread légère qui divise les tâches en petites sous-tâches et les exécute tour à tour.
 Comment ouvrir web.xml
Apr 03, 2025 am 06:51 AM
Comment ouvrir web.xml
Apr 03, 2025 am 06:51 AM
Pour ouvrir un fichier web.xml, vous pouvez utiliser les méthodes suivantes: Utilisez un éditeur de texte (tel que le bloc-notes ou TextEdit) pour modifier les commandes à l'aide d'un environnement de développement intégré (tel qu'Eclipse ou NetBeans) (Windows: Notepad web.xml; Mac / Linux: Open -A TextEdit web.xml)
 L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
L'interprète Python peut-il être supprimé dans le système Linux?
Apr 02, 2025 am 07:00 AM
En ce qui concerne le problème de la suppression de l'interpréteur Python qui est livré avec des systèmes Linux, de nombreuses distributions Linux préinstalleront l'interpréteur Python lors de l'installation, et il n'utilise pas le gestionnaire de packages ...
 À quoi sert le mieux le Linux?
Apr 03, 2025 am 12:11 AM
À quoi sert le mieux le Linux?
Apr 03, 2025 am 12:11 AM
Linux est mieux utilisé comme gestion de serveurs, systèmes intégrés et environnements de bureau. 1) Dans la gestion des serveurs, Linux est utilisé pour héberger des sites Web, des bases de données et des applications, assurant la stabilité et la fiabilité. 2) Dans les systèmes intégrés, Linux est largement utilisé dans les systèmes électroniques intelligents et automobiles en raison de sa flexibilité et de sa stabilité. 3) Dans l'environnement de bureau, Linux fournit des applications riches et des performances efficaces.
 Comment est la compatibilité Debian Hadoop
Apr 02, 2025 am 08:42 AM
Comment est la compatibilité Debian Hadoop
Apr 02, 2025 am 08:42 AM
Debianlinux est connu pour sa stabilité et sa sécurité et est largement utilisé dans les environnements de serveur, de développement et de bureau. Bien qu'il y ait actuellement un manque d'instructions officielles sur la compatibilité directe avec Debian et Hadoop, cet article vous guidera sur la façon de déployer Hadoop sur votre système Debian. Exigences du système Debian: Avant de commencer la configuration de Hadoop, assurez-vous que votre système Debian répond aux exigences de fonctionnement minimales de Hadoop, qui comprend l'installation de l'environnement d'exécution Java (JRE) nécessaire et des packages Hadoop. Étapes de déploiement de Hadoop: Télécharger et unzip Hadoop: Téléchargez la version Hadoop dont vous avez besoin sur le site officiel d'Apachehadoop et résolvez-le
 Dois-je installer un client Oracle lors de la connexion à une base de données Oracle à l'aide de Go?
Apr 02, 2025 pm 03:48 PM
Dois-je installer un client Oracle lors de la connexion à une base de données Oracle à l'aide de Go?
Apr 02, 2025 pm 03:48 PM
Dois-je installer un client Oracle lors de la connexion à une base de données Oracle à l'aide de Go? Lorsque vous développez GO, la connexion aux bases de données Oracle est une exigence commune ...
 Debian Strings est-il compatible avec plusieurs navigateurs
Apr 02, 2025 am 08:30 AM
Debian Strings est-il compatible avec plusieurs navigateurs
Apr 02, 2025 am 08:30 AM
"Debianstrings" n'est pas un terme standard, et sa signification spécifique n'est pas encore claire. Cet article ne peut pas commenter directement la compatibilité de son navigateur. Cependant, si "DebianStrings" fait référence à une application Web exécutée sur un système Debian, sa compatibilité du navigateur dépend de l'architecture technique de l'application elle-même. La plupart des applications Web modernes se sont engagées à compatibilité entre les navigateurs. Cela repose sur les normes Web suivantes et l'utilisation de technologies frontales bien compatibles (telles que HTML, CSS, JavaScript) et les technologies back-end (telles que PHP, Python, Node.js, etc.). Pour s'assurer que l'application est compatible avec plusieurs navigateurs, les développeurs doivent souvent effectuer des tests croisés et utiliser la réactivité
