

Linux, en tant que système d'exploitation largement utilisé dans les serveurs et les appareils embarqués, occupe une part de marché croissante. Dans ces scénarios, la gestion de la mémoire est cruciale car elle affecte directement les performances et la stabilité du système, notamment pour les programmeurs. Pour les programmeurs qui souhaitent développer des applications hautes performances sur la plate-forme Linux, la maîtrise de la gestion de la mémoire Linux est indispensable. Aujourd'hui, nous allons présenter un article que tout programmeur devrait lire : la gestion de la mémoire Linux.
Ce qu'il faut savoir sur la partie mémoire :
Regardons d'abord quelques connaissances de base. Du point de vue d'un processus, la mémoire est divisée en deux parties : le mode noyau et le mode utilisateur. Le ratio classique est le suivant :
.
Le passage du mode utilisateur au mode noyau s'effectue généralement via des appels système et des interruptions. La mémoire du mode utilisateur est divisée en différentes zones à des fins différentes :

Bien entendu, le mode noyau ne sera pas utilisé sans discernement, il se répartit donc comme suit :

Regardons de plus près comment ces souvenirs sont gérés.
Adresse
Le processus de mappage des adresses sous Linux est l'adresse logique -> adresse linéaire -> adresse physique. L'adresse physique est le plus simple : un signal numérique transmis dans le bus d'adresse, tandis que l'adresse linéaire et l'adresse logique représentent une règle de conversion. sont les suivants :
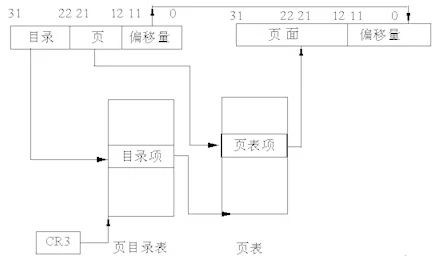
Cette partie est complétée par le MMU, qui fait intervenir les registres principaux CR0 et CR3. Ce qui apparaît dans les instructions de la machine est l'adresse logique, et les règles d'adresse logique sont les suivantes :
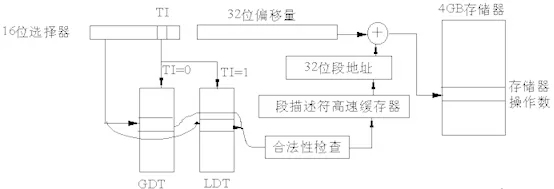
L'adresse logique sous Linux est égale à l'adresse linéaire, ce qui signifie qu'Inter rend les choses très compliquées pour la compatibilité, et Linux la simplifie pour être paresseux.
Comment gérer la mémoire
Au démarrage du système, il détectera la taille et l'état de la mémoire. Avant d'établir des structures complexes, il est nécessaire de gérer ces mémoires de manière simple. Il s'agit d'un bootmem, qui est simplement un bitmap, mais il y a aussi quelques optimisations. dedans.
Peu importe à quel point le bootmem est optimisé, l'efficacité n'est pas élevée. Après tout, il doit être parcouru lors de l'allocation de mémoire. Le système compagnon peut simplement résoudre ce problème : enregistrez en interne des fragments de mémoire libres avec une puissance de 2. souhaitez allouer 3 pages, accédez à la liste de 4 pages et choisissez-en une, allouez-en 3 et remettez la 1 restante en place. Le processus de libération de mémoire est simplement le processus inverse. Utilisez une image pour le représenter :
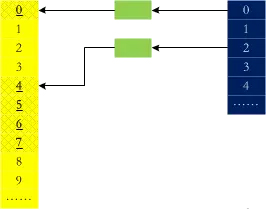
Vous pouvez voir que 0, 4, 5, 6 et 7 sont tous utilisés. Alors, lorsque 1 et 2 seront publiés, seront-ils fusionnés ?
static inline unsigned long
__find_buddy_index(unsigned long page_idx, unsigned int order)
{
return page_idx ^ (1 Comme vous pouvez le voir dans le code ci-dessus, 0 et 1 sont amis, et 2 et 3 sont amis. Bien que 1 et 2 soient adjacents, ils ne le sont pas. La fragmentation de la mémoire est l'ennemi du fonctionnement du système.Le mécanisme du système de binôme peut empêcher la fragmentation dans une certaine mesure, de plus, nous pouvons obtenir le nombre de pages libres dans chaque commande via cat /proc/buddyinfo.
Chaque fois que le système partenaire alloue de la mémoire, c'est en unités de pages (4 Ko), mais la plupart des structures de données utilisées lorsque le système fonctionne sont très petites. Il n'est évidemment pas rentable d'allouer 4 Ko à un petit objet. Utilisez slab sous Linux pour résoudre l'allocation de petits objets :
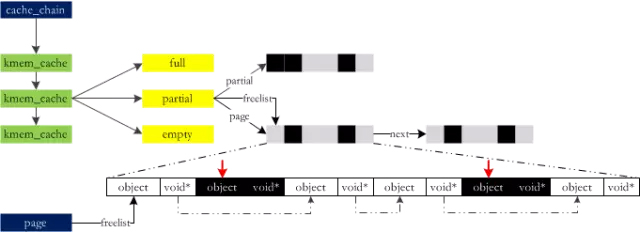
Lors de l'exécution, la dalle « vend en gros » de la mémoire à un ami, la traite et la coupe en morceaux et la « vend » en gros. Avec l'application généralisée des systèmes multiprocesseurs à grande échelle et des systèmes NUMA, la dalle a finalement révélé ses défauts :
Afin de résoudre ces problèmes, des experts ont développé le slub : la structure des pages est modifiée pour réduire la surcharge de la structure de gestion des slabs, chaque CPU possède une slab active localement (kmem_cache_cpu), etc. Pour les petits systèmes embarqués, il existe une couche de simulation de dalle, qui présente plus d'avantages dans de tels systèmes.
小内存的问题算是解决了,但还有一个大内存的问题:用伙伴系统分配10 x 4KB的数据时,会去16 x 4KB的空闲列表里面去找(这样得到的物理内存是连续的),但很有可能系统里面有内存,但是伙伴系统分配不出来,因为他们被分割成小的片段。那么,vmalloc就是要用这些碎片来拼凑出一个大内存,相当于收集一些“边角料”,组装成一个成品后“出售”:
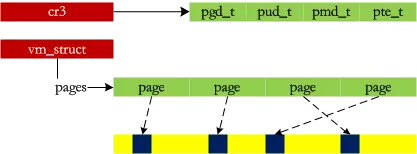
之前的内存都是直接映射的,第一次感觉到页式管理的存在:D 另外对于高端内存,提供了kmap方法为page分配一个线性地址。
进程由不同长度的段组成:代码段、动态库的代码、全局变量和动态产生数据的堆、栈等,在Linux中为每个进程管理了一套虚拟地址空间:
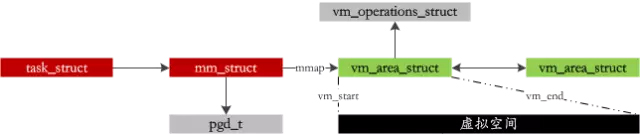
在我们写代码malloc完以后,并没有马上占用那么大的物理内存,而仅仅是维护上面的虚拟地址空间而已,只有在真正需要的时候才分配物理内存,这就是COW(COPY-ON-WRITE:写时复制)技术,而物理分配的过程就是最复杂的缺页异常处理环节了,下面来看!
缺页异常
在实际需要某个虚拟内存区域的数据之前,和物理内存之间的映射关系不会建立。如果进程访问的虚拟地址空间部分尚未与页帧关联,处理器自动引发一个缺页异常。在内核处理缺页异常时可以拿到的信息如下:
处理的流程如下:
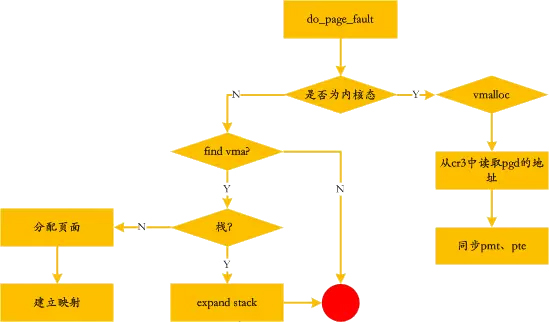
发生缺页异常的时候,可能因为不常使用而被swap到磁盘上了,swap相关的命令如下:
swapon 开启swap swapoff 关闭swap /proc/sys/vm/swapiness 分值越大越积极使用swap,可以修改/etc/sysctl.conf中添加vm.swappiness=xx[1-100]来修改
如果内存是mmap映射到内存中的,那么在读、写对应内存的时候也会产生缺页异常。
在Linux中,内存管理是一个复杂的主题,但是如果程序员能够理解并充分利用它,他们可以极大地提高他们的程序的性能和可靠性。在本文中,我们介绍了Linux内存管理的基本知识、虚拟内存的概念、内存映射文件以及交换空间等。此外,我们还介绍了一些有助于程序员优化内存使用的技巧和工具。现在,不要再让程序的性能拖慢了你的项目,去掌握Linux内存管理吧!
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



