
 Tutoriel système
Linux
Comprendre les quatre principaux algorithmes de planification des E/S du noyau Linux dans un seul article
Tutoriel système
Linux
Comprendre les quatre principaux algorithmes de planification des E/S du noyau Linux dans un seul article
Comprendre les quatre principaux algorithmes de planification des E/S du noyau Linux dans un seul article

Le noyau Linux contient 4 types de planificateurs d'IO, à savoir le planificateur d'IO Noop, le planificateur d'IO anticipé, le planificateur d'IO Deadline et le planificateur d'IO CFQ.
Normalement, les retards de lecture et d'écriture du disque sont causés par le déplacement de la tête vers le cylindre. Afin de résoudre ce retard, le noyau adopte principalement deux stratégies : les algorithmes de mise en cache et de planification des E/S.
Concept d'algorithme de planification
- Lorsqu'un bloc de données est écrit ou lu sur l'appareil, la requête est placée dans une file d'attente en attente d'achèvement.
- Chaque périphérique bloc possède sa propre file d'attente.
- Le planificateur d'E/S est chargé de maintenir l'ordre de ces files d'attente afin d'utiliser les médias plus efficacement. Le planificateur d'E/S transforme les opérations d'E/S non ordonnées en opérations d'E/S ordonnées.
- Avant la planification, le noyau doit d'abord déterminer le nombre de requêtes dans la file d'attente.
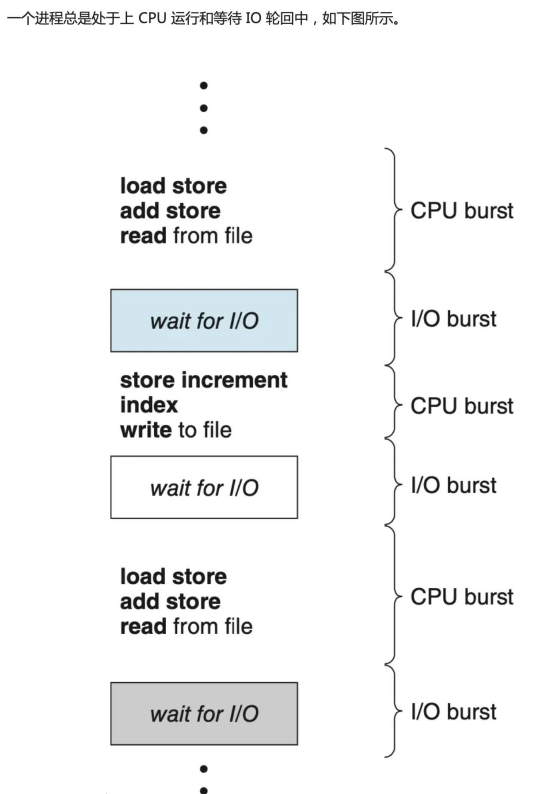
Planificateur IO
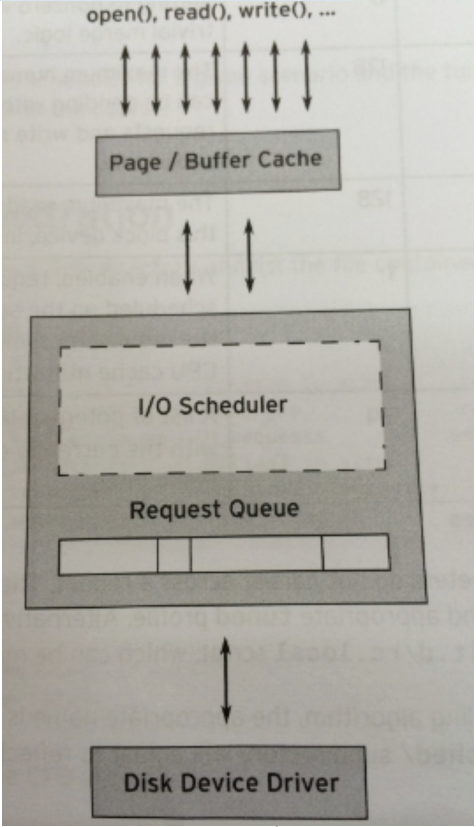
IO Scheduler (IO Scheduler) est la méthode utilisée par le système d'exploitation pour déterminer l'ordre de soumission des opérations IO sur les périphériques en bloc. Il existe deux objectifs, l'un est d'améliorer le débit des E/S et l'autre est de réduire le temps de réponse des E/S.
Cependant, le débit et le temps de réponse des IO sont souvent contradictoires. Afin d'équilibrer les deux autant que possible, le planificateur IO fournit une variété d'algorithmes de planification pour s'adapter aux différents scénarios de requêtes IO. Parmi eux, l'algorithme le plus avantageux pour les scénarios de lecture et d'écriture aléatoires tels que les bases de données est DEANLINE.
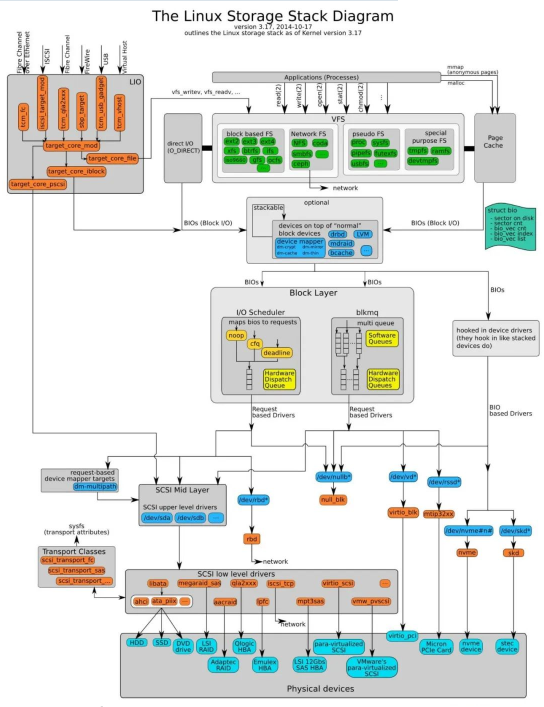
L'emplacement du planificateur IO dans la pile du noyau est le suivant :
La chose la plus tragique à propos des périphériques bloc est la rotation du disque, qui est un processus très long. Chaque périphérique bloc ou partition d'un périphérique bloc correspond à sa propre file d'attente de requêtes (request_queue), et chaque file d'attente de requêtes peut choisir un planificateur d'E/S pour coordonner les requêtes soumises.
L'objectif fondamental du planificateur d'E/S est d'organiser les demandes en fonction de leurs numéros de secteur correspondants sur le périphérique de bloc afin de réduire les mouvements de la tête et d'améliorer l'efficacité. Les demandes dans la file d'attente de demandes de chaque appareil recevront une réponse dans l'ordre.
En fait, en plus de cette file d'attente, chaque planificateur lui-même maintient un nombre différent de files d'attente pour traiter les demandes soumises, et la demande en haut de la file d'attente sera déplacée vers la file d'attente des demandes en temps voulu pour attendre une réponse.

La fonction principale du planificateur IO est de réduire le besoin de rotation du disque. Principalement réalisé de 2 manières :
- Fusionner
- Trier
Chaque appareil aura sa propre file d'attente de demandes correspondante, et toutes les demandes seront dans la file d'attente de demandes avant d'être traitées. Lorsqu'une nouvelle demande arrive, s'il s'avère que l'emplacement de cette demande est adjacent à une demande précédente, elle peut alors être fusionnée en une seule demande.
Si celui fusionné est introuvable, il sera trié en fonction du sens de rotation du disque. Habituellement, le rôle du planificateur d'E/S est d'effectuer la fusion et le tri sans trop affecter le temps de traitement d'une seule requête.
1、NOOP
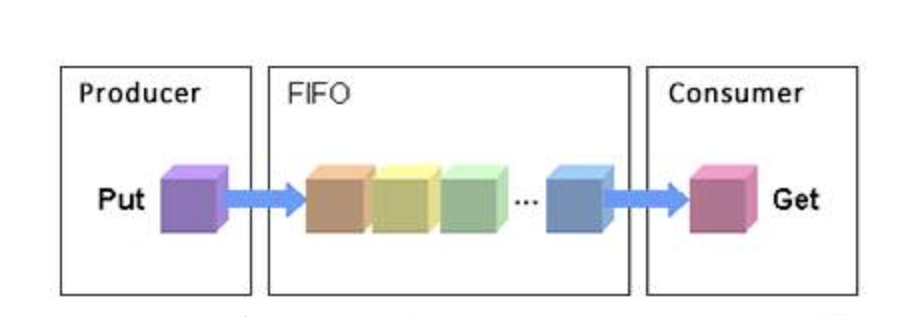
FIFO
- Qu'est-ce que noop ? Noop est un algorithme de planification d'entrée et de sortie, No Operation. Cette méthode est en réalité plus simple et plus efficace. Le problème est qu'il y a trop de recherches de disque, ce qui est inacceptable pour les disques traditionnels. Mais c'est OK pour les disques SSD, car les disques SSD n'ont pas besoin de tourner.
- Un autre nom pour noop est également appelé algorithme de planification d'ascenseur.
- Quel est le principe du noop ?
Mettez les requêtes d'entrée et de sortie dans une file d'attente FIFO, puis exécutez les requêtes d'entrée et de sortie dans la file d'attente dans l'ordre : Lorsqu'une nouvelle requête arrive :
-
S'il peut être fusionné, fusionnez-le
-
S'il ne peut pas être fusionné, il tentera de trier. Si les requêtes dans la file d'attente sont déjà très anciennes, cette nouvelle requête ne peut pas sauter dans la file d'attente et ne peut être placée qu'à la fin. Sinon, insérez-le dans la position appropriée
-
S'il ne peut pas être fusionné et qu'il n'y a pas de position appropriée pour l'insertion, il sera placé à la fin de la file d'attente des demandes.
-
Scénarios applicables
4.1 Dans les scénarios où vous ne souhaitez pas modifier l'ordre des requêtes d'entrée et de sortie
;4.2 Appareils dotés d'algorithmes de planification plus intelligents en entrée et en sortie, tels que les périphériques de stockage NAS ;
4.3 Les requêtes d'entrée et de sortie de l'application de couche supérieure ont été soigneusement optimisées ;4.4 Périphériques de disques à tête non rotative, tels que les disques SSD
. L'algorithme CFQ (Completely Fair Queuing), comme son nom l'indique, est un algorithme absolument équitable. Il tente d'attribuer une file d'attente de requêtes et une tranche de temps à tous les processus en compétition pour le droit d'utiliser le périphérique de bloc. Dans la tranche de temps attribuée au processus par le planificateur, le processus peut envoyer ses requêtes de lecture et d'écriture au périphérique de bloc sous-jacent. . Lorsque la tranche de temps du processus est consommée. Une fois terminée, la file d'attente des demandes du processus sera suspendue, en attente de planification.
La tranche de temps de chaque processus et la longueur de la file d'attente de chaque processus dépendent de la priorité IO du processus. Chaque processus aura une priorité IO, et le planificateur CFQ l'utilisera comme l'un des facteurs à prendre en compte pour déterminer le processus. Lorsque la file d'attente des requêtes peut obtenir le droit d'utiliser le périphérique de blocage.
Les priorités IO peuvent être divisées en trois catégories de haut en bas :
RT (temps réel)
ÊTRE (meilleur essai)
IDLE(inactif)
RT et BE peuvent être divisés en 8 sous-priorités. Vous pouvez le visualiser et le modifier via ionice. Plus la priorité est élevée, plus elle est traitée tôt, plus de tranches de temps sont utilisées pour ce processus et plus de demandes peuvent être traitées en même temps.
En fait, nous savons déjà que l'équité du planificateur CFQ concerne le processus, et que seules les requêtes synchrones (lecture ou écriture synchronisée) existent pour le processus. Elles seront placées dans la propre file d'attente des requêtes du processus, et toutes les requêtes asynchrones avec. la même priorité, quel que soit le processus dont elles proviennent, sera placée dans une file d'attente commune. Il y a un total de 8 (RT) + 8 (BE) + 1 (IDLE) = 17 files d'attente de requêtes asynchrones.
À partir de Linux 2.6.18, CFQ est utilisé comme algorithme de planification des E/S par défaut. Pour les serveurs à usage général, CFQ est un meilleur choix. L'algorithme de planification spécifique à utiliser doit être sélectionné sur la base de références suffisantes basées sur des scénarios commerciaux spécifiques, et ne peut pas être décidé uniquement par les mots d'autres personnes.
3.DATE LIMITEDEADLINE résout la situation extrême de manque de demandes d'IO basée sur CFQ.
En plus de la file d'attente de tri des E/S dont dispose CFQ lui-même, DEADLINE fournit également des files d'attente FIFO pour les E/S en lecture et en écriture.
Le temps d'attente maximum pour lire la file d'attente FIFO est de 500 ms, et le temps d'attente maximum pour l'écriture de la file d'attente FIFO est de 5 s (bien entendu, ces paramètres peuvent être définis manuellement).
La priorité des requêtes IO dans la file d'attente FIFO est supérieure à celle de la file d'attente CFQ, et la priorité de la file d'attente FIFO de lecture est supérieure à la priorité de la file d'attente FIFO d'écriture. La priorité peut être exprimée comme suit :
«FIFO(Lire) > FIFO(Écrire) > CFQ
”
L'algorithme de délai garantit le temps de retard minimum pour une requête IO donnée. De cette manière, il devrait être très adapté aux applications DSS.
la date limite est en fait une amélioration par rapport à Elevator :
1. Évitez certaines demandes qui ne peuvent pas être traitées trop longtemps.
2. Distinguer les opérations de lecture et les opérations d'écriture.
deadline IO maintient 3 files d'attente. La première file d'attente est la même que celle d'Elevator, essayant de trier en fonction de l'emplacement physique. La deuxième file d'attente et la troisième file d'attente sont toutes deux triées par heure. La différence est que l'une est une opération de lecture et l'autre une opération d'écriture.
Deadline IO fait la distinction entre la lecture et l'écriture car le concepteur estime que si l'application envoie une demande de lecture, elle s'y bloquera généralement et attendra que le résultat soit renvoyé. La demande d'écriture n'est généralement pas la demande de l'application d'écrire dans la mémoire, puis le processus en arrière-plan la réécrit sur le disque. Les candidatures n’attendent généralement pas la fin de la rédaction avant de continuer. Les demandes de lecture doivent donc avoir une priorité plus élevée que les demandes d’écriture.
Dans cette conception, chaque nouvelle requête sera placée en premier dans la première file d'attente. L'algorithme est le même que celui d'Elevator, et sera également ajoutée à la fin de la file d'attente de lecture ou d'écriture. De cette façon, nous traitons d'abord certaines requêtes de la première file d'attente, et détectons en même temps si les premières requêtes de la deuxième/troisième file d'attente attendent depuis trop longtemps. Si elles ont dépassé un seuil, elles seront traitées. Ce seuil est de 5 ms pour les requêtes de lecture et de 5 s pour les requêtes d'écriture.
Personnellement, je pense qu'il est préférable de ne pas utiliser ce type de partition pour enregistrer les journaux de modifications de bases de données, tels que le journal en ligne d'Oracle, le binlog de MySQL, etc. Parce que ce type de demande d'écriture appelle généralement fsync. Si l'écriture ne peut pas être terminée, cela affectera également grandement les performances de l'application.
4. ANTICIPATOIRE
CFQ et DEADLINE se concentrent sur la satisfaction des demandes d'IO dispersées. Pour les requêtes d'E/S continues, telles que la lecture séquentielle, il n'y a pas d'optimisation.
Afin de répondre au scénario d'E/S aléatoires mixtes et d'E/S séquentielles, Linux prend également en charge l'algorithme de planification ANTICIPATOIRE. Basé sur DEADLINE, ANTICIPATORY définit une fenêtre de temps d'attente de 6 ms pour chaque IO de lecture. Si le système d'exploitation reçoit une demande d'E/S de lecture provenant d'un emplacement adjacent dans ces 6 ms, elle peut être satisfaite immédiatement.
Résumé
Le choix de l'algorithme du planificateur d'E/S dépend à la fois des caractéristiques matérielles et des scénarios d'application.
Sur les disques SAS traditionnels, CFQ, DEADLINE et ANTICIPATORY sont tous de bons choix pour les serveurs de bases de données dédiés, DEADLINE fonctionne bien en termes de débit et de temps de réponse.
Cependant, sur les disques SSD émergents tels que SSD et Fusion IO, le NOOP le plus simple peut être le meilleur algorithme, car l'optimisation des trois autres algorithmes est basée sur le raccourcissement du temps de recherche, et les disques SSD n'ont pas de tel- appelé temps de recherche. Et le temps de réponse IO est très court.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos sera fermé en 2024 parce que sa distribution en amont, Rhel 8, a été fermée. Cette fermeture affectera le système CentOS 8, l'empêchant de continuer à recevoir des mises à jour. Les utilisateurs doivent planifier la migration et les options recommandées incluent CentOS Stream, Almalinux et Rocky Linux pour garder le système en sécurité et stable.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment monter un disque dur dans les centos
Apr 14, 2025 pm 08:15 PM
Comment monter un disque dur dans les centos
Apr 14, 2025 pm 08:15 PM
Le support de disque dur CentOS est divisé en étapes suivantes: Déterminez le nom du périphérique du disque dur (/ dev / sdx); créer un point de montage (il est recommandé d'utiliser / mnt / newdisk); Exécutez la commande Mount (mont / dev / sdx1 / mnt / newdisk); modifier le fichier / etc / fstab pour ajouter une configuration de montage permanent; Utilisez la commande umount pour désinstaller l'appareil pour vous assurer qu'aucun processus n'utilise l'appareil.
 Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Une fois CentOS arrêté, les utilisateurs peuvent prendre les mesures suivantes pour y faire face: sélectionnez une distribution compatible: comme Almalinux, Rocky Linux et CentOS Stream. Migrez vers les distributions commerciales: telles que Red Hat Enterprise Linux, Oracle Linux. Passez à Centos 9 Stream: Rolling Distribution, fournissant les dernières technologies. Sélectionnez d'autres distributions Linux: comme Ubuntu, Debian. Évaluez d'autres options telles que les conteneurs, les machines virtuelles ou les plates-formes cloud.
