

Résumé des outils d'analyse des performances Linux

En raison de mon intérêt pour le système d'exploitation Linux et de mon désir de connaissances de bas niveau, j'ai compilé cet article. Il sert à vérifier les connaissances de base et couvre tous les aspects du système. Les outils présentés dans la documentation ne peuvent être entièrement maîtrisés sans une connaissance complète des systèmes informatiques, des réseaux et des systèmes d'exploitation. De plus, l'analyse et l'optimisation des performances du système sont une série à long terme.
Ce document est principalement un article complet compilé en combinant le billet de blog mis à jour sur l'outil de réglage des performances Linux par le gourou Linux et architecte des performances senior de Netflix Brendan Gregg, et en collectant des articles liés à l'optimisation des performances du système Linux. Il explique principalement les principes et les outils de test de performances impliqués en conjonction avec l'article de blog.
Connaissances de base : lors de l'analyse des problèmes de performances, la compréhension des connaissances de base est nécessaire. Par exemple, le cache matériel ; un autre exemple est le noyau du système d’exploitation. Les détails du comportement de l'application sont souvent liés à ces éléments, et ces éléments de bas niveau peuvent affecter les performances de l'application de manière inattendue. Par exemple, certains programmes ne parviennent pas à utiliser pleinement le cache, ce qui entraîne de mauvaises performances. Par exemple, trop d'appels système sont appelés inutilement, provoquant des changements fréquents noyau/utilisateur, etc.
Outil d'analyse des performances
Tout d’abord, regardons une image :
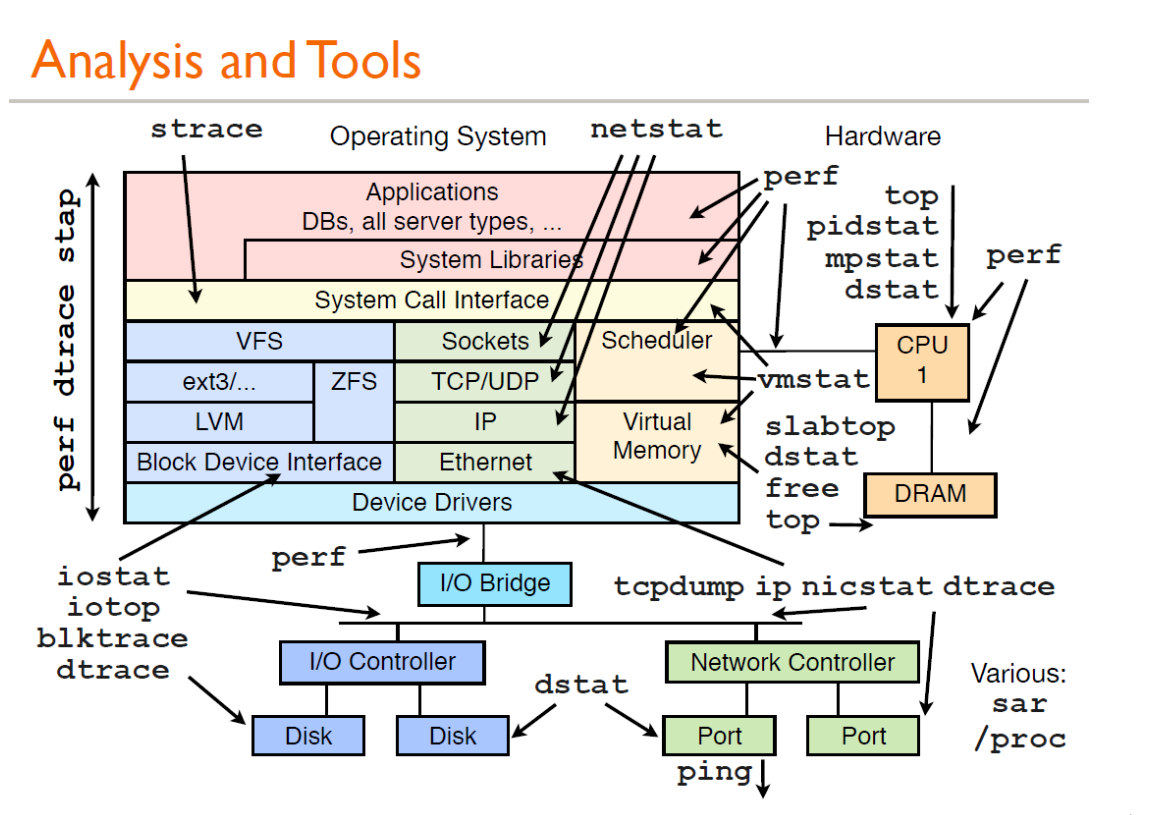
L'image ci-dessus est une analyse des performances partagée par Brendan Gregg. Tous les outils ici peuvent obtenir leurs documents d'aide via man Voici une brève introduction à l'utilisation générale :
vmstat – statistiques de mémoire virtuelle
vmstat (VirtualMeomoryStatistics, statistiques de mémoire virtuelle) est un outil courant pour surveiller la mémoire sous Linux. Il peut surveiller la situation globale de la mémoire virtuelle, des processus, du processeur, etc. Utilisation courante de vmstat : vmstat interval times 即每隔 interval 秒采样一次,共采样 times 次,如果省略 times, les données seront collectées jusqu'à ce que l'utilisateur les arrête manuellement. Donnez juste un exemple simple :
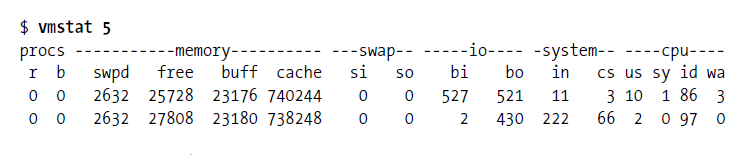
Vous pouvez utiliser ctrl+c 停止 vmstat pour collecter des données.
La première ligne montre la moyenne depuis le démarrage du système, la deuxième ligne commence à montrer ce qui se passe actuellement, les lignes suivantes montreront ce qui se passe dans chaque intervalle de 5 secondes, la signification de chaque colonne est dans l'en-tête, comme indiqué ci-dessous :
- procs : r Cette colonne montre combien de processus attendent le processeur, et la colonne b montre combien de processus dorment sans interruption (en attente d'E/S).
- La colonne memory:swapd indique combien de blocs ont été échangés hors du disque (échange de pages), les colonnes restantes indiquent combien de blocs sont libres (non utilisés), combien de blocs sont utilisés comme tampons et combien sont utilisés comme tampons. Cache du système d'exploitation.
- swap : affiche l'activité de swap : combien de blocs sont échangés (à partir du disque) et échangés (vers le disque) par seconde.
- io : affiche le nombre de blocs lus (bi) et écrits (bo) à partir du périphérique bloc, reflétant généralement les E/S du disque dur.
- système : affiche le nombre d'interruptions (in) et de changements de contexte (cs) par seconde.
- cpu : affiche le pourcentage de tout le temps CPU consacré à diverses opérations, y compris l'exécution du code utilisateur (hors noyau), l'exécution du code système (noyau), l'inactivité et l'attente des E/S.
Symptômes de mémoire insuffisante : la mémoire libre diminue fortement, le recyclage du tampon et du cache n'aide pas, utilisation intensive des partitions de swap (swpd), échanges fréquents de pages (swap), augmentation du nombre de disques de lecture et d'écriture (io), et augmentation des interruptions de défaut de page (in), le nombre de commutateurs de contexte (cs) augmente, le nombre de processus en attente d'IO (b) augmente et beaucoup de temps CPU est passé à attendre IO (wa)
iostat – pour rapporter les statistiques du processeur
iostat est utilisé pour rapporter les statistiques de l'unité centrale (CPU) et les statistiques d'entrée/sortie pour l'ensemble du système, les adaptateurs, les périphériques tty, les disques et les CD-ROM. Par défaut, il affiche les mêmes informations d'utilisation du processeur que vmstat. commande pour afficher l'extension Statistiques de l'appareil :

La première ligne affiche la moyenne depuis le démarrage du système, puis la moyenne incrémentielle, une ligne par appareil.
Habitudes courantes d'abréviation de l'indicateur IO de disque Linux : rq est une demande, r est une lecture, w est une écriture, qu est une file d'attente, sz est une taille, a est une moyenne, tm est une heure et svc est un service.
- rrqm/s et wrqm/s : requêtes de lecture et d'écriture combinées par seconde, « fusionnées » signifie que le système d'exploitation prend plusieurs requêtes logiques de la file d'attente et les fusionne en une seule requête sur le disque réel.
- r/s et w/s : nombre de requêtes de lecture et d'écriture envoyées à l'appareil par seconde.
- rsec/s et wsec/s : Nombre de secteurs lus et écrits par seconde.
- avgrq –sz : Nombre de secteurs demandés.
- avgqu –sz : nombre de requêtes en attente dans la file d'attente du périphérique.
- wait : le temps passé sur chaque demande d'E/S.
- svctm : heure réelle de la demande (service).
- %util : Le pourcentage de temps pendant lequel il y a eu au moins une demande active.
dstat – outil de surveillance du système
dstat affiche l'utilisation du processeur, l'état des E/S du disque, l'état d'envoi des paquets réseau et l'état de la pagination. La sortie est colorée et hautement lisible. Par rapport à l'entrée de vmstat et iostat, elle est plus détaillée et intuitive. Lorsque vous l'utilisez, entrez simplement la commande directement, et bien sûr vous pouvez également utiliser des paramètres spécifiques.
Comme suit :dstat –cdlmnpsy
iotop – Outil de surveillance en temps réel des processus LINUX
La commande iotop est une commande spécialement conçue pour afficher les E/S du disque dur. Le style d'interface est similaire à la commande top. Elle peut afficher quel processus génère spécifiquement la charge IO. Il s'agit d'un outil de pointe utilisé pour surveiller l'utilisation des E/S du disque. Il possède une interface utilisateur similaire à celle de top, comprenant le PID, l'utilisateur, les E/S, le processus et d'autres informations connexes.
Peut être utilisé de manière non interactive :
iotop –bod interval
Pour visualiser le I/O de chaque processus, vous pouvez utiliser
pidstat,pidstat –d instat
pidstat – Surveiller les ressources système
pidstat est principalement utilisé pour surveiller l'utilisation des ressources système par tous les processus ou des processus spécifiés, tels que le processeur, la mémoire, les E/S du périphérique, la commutation de tâches, les threads, etc.
使用方法:
pidstat –d interval
pidstat 还可以用以统计CPU使用信息:
pidstat –u interval
统计内存信息:
pidstat –r interval
top
- top 命令的汇总区域显示了五个方面的系统性能信息:
- 负载:时间,登陆用户数,系统平均负载;
- 进程:运行,睡眠,停止,僵尸;
- cpu:用户态,核心态,NICE,空闲,等待IO,中断等;
- 内存:总量,已用,空闲(系统角度),缓冲,缓存;
- 交换分区:总量,已用,空闲
任务区域默认显示:进程 ID,有效用户,进程优先级,NICE 值,进程使用的虚拟内存,物理内存和共享内存,进程状态,CPU 占用率,内存占用率,累计 CPU 时间,进程命令行信息。
htop
htop 是 Linux 系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台或者X终端中),需要 ncurses。
Htop 可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
与 top 相比,htop 有以下优点:
- 可以横向或者纵向滚动浏览进程列表,以便看到所有的进程和完整的命令行。
- 在启动上,比top更快。
- 杀进程时不需要输入进程号。
- htop支持鼠标操作。
mpstat
mpstat 是 Multiprocessor Statistics的缩写,是实时系统监控工具。其报告CPU的一些统计信息,这些信息存放在 /proc/stat 文件中。在多 CPUs 系统里,其不但能查看所有 CPU 的平均状况信息,而且能够查看特定 CPU 的信息。常见用法:
mpstat –P ALL interval times
netstat
netstat 用于显示与 IP、TCP、UDP和 ICMP 协议相关的统计数据,一般用于检验本机各端口的网络连接情况。
常见用法:
netstat –npl # 可以查看你要打开的端口是否已经打开。 netstat –rn # 打印路由表信息。 netstat –in # 提供系统上的接口信息,打印每个接口的MTU,输入分组数,输入错误,输出分组数,输出错误,冲突以及当前的输出队列的长度。
ps–显示当前进程的状态
ps 参数太多,具体使用方法可以参考 man ps
常用的方法:
ps aux #hsserver ps –ef |grep #hundsun
杀掉某一程序的方法:
ps aux | grep mysqld | grep –v grep | awk ‘{print $2 }’ xargs kill -9
杀掉僵尸进程:
ps –eal | awk ‘{if ($2 == “Z”){print $4}}’ | xargs kill -9
strace
跟踪程序执行过程中产生的系统调用及接收到的信号,帮助分析程序或命令执行中遇到的异常情况。
举例:查看 mysqld 在 linux 上加载哪种配置文件,可以通过运行下面的命令:
strace –e stat64 mysqld –print –defaults > /dev/null
uptime
能够打印系统总共运行了多长时间和系统的平均负载,uptime 命令最后输出的三个数字的含义分别是 1分钟,5分钟,15分钟内系统的平均负荷。
lsof
lsof(list open files)是一个列出当前系统打开文件的工具。通过 lsof 工具能够查看这个列表对系统检测及排错,常见的用法:
查看文件系统阻塞
lsof /boot
查看端口号被哪个进程占用
lsof -i : 3306
查看用户打开哪些文件
lsof –u username
查看进程打开哪些文件
lsof –p 4838
查看远程已打开的网络链接
lsof –i @192.168.34.128
perf
perf 是 Linux kernel 自带的系统性能优化工具。优势在于与 Linux Kernel 的紧密结合,它可以最先应用到加入 Kernel 的new feature,用于查看热点函数,查看 cashe miss 的比率,从而帮助开发者来优化程序性能。
性能调优工具如 perf,Oprofile 等的基本原理都是对被监测对象进行采样,最简单的情形是根据 tick 中断进行采样,即在 tick 中断内触发采样点,在采样点里判断程序当时的上下文。
假如一个程序 90% 的时间都花费在函数 foo() 上,那么 90% 的采样点都应该落在函数 foo() 的上下文中。运气不可捉摸,但我想只要采样频率足够高,采样时间足够长,那么以上推论就比较可靠。因此,通过 tick 触发采样,我们便可以了解程序中哪些地方最耗时间,从而重点分析。
汇总
结合以上常用的性能测试命令并联系文初的性能分析工具的图,就可以初步了解到性能分析过程中哪个方面的性能使用哪方面的工具(命令)。
常用的性能测试工具
熟练并精通了第二部分的性能分析命令工具,引入几个性能测试的工具,介绍之前先简单了解几个性能测试工具:
- perf_events:一款随 Linux 内核代码一同发布和维护的性能诊断工具,由内核社区维护和发展。Perf 不仅可以用于应用程序的性能统计分析,也可以应用于内核代码的性能统计和分析。
- eBPF tools:一款使用 bcc 进行的性能追踪的工具,eBPF map可以使用定制的 eBPF 程序被广泛应用于内核调优方面,也可以读取用户级的异步代码。重要的是这个外部的数据可以在用户空间管理。这个 k-v 格式的 map 数据体是通过在用户空间调用 bpf 系统调用创建、添加、删除等操作管理的。
- perf-tools:一款基于 perf_events (perf) 和 ftrace 的Linux性能分析调优工具集。Perf-Tools 依赖库少,使用简单。支持Linux 3.2 及以上内核版本。
- bcc(BPF Compiler Collection)::一款使用 eBP F的 perf 性能分析工具。一个用于创建高效的内核跟踪和操作程序的工具包,包括几个有用的工具和示例。利用扩展的BPF(伯克利数据包过滤器),正式称为eBPF,一个新的功能,首先被添加到Linux 3.15。多用途需要Linux 4.1以上BCC。
- ktap:一种新型的linux脚本动态性能跟踪工具。允许用户跟踪Linux内核动态。ktap是设计给具有互操作性,允许用户调整操作的见解,排除故障和延长内核和应用程序。它类似于Linux和Solaris DTrace SystemTap。
-
Flame Graphs:是一款使用 perf,system tap,ktap 可视化的图形软件,允许最频繁的代码路径快速准确地识别,可以是使用
github.com/brendangregg/flamegraph中的开发源代码的程序生成。
Linux observability tools | Linux 性能观测工具
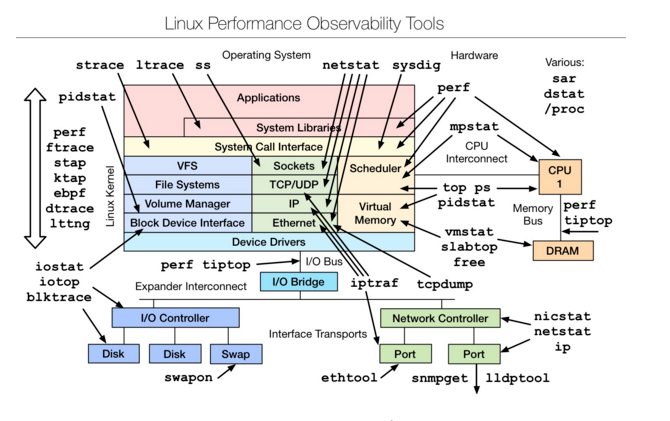
- 首先学习的Basic Tool有如下:uptime、top(htop)、mpstat、isstat、vmstat、free、ping、nicstat、dstat。
- 高级的命令如下:sar、netstat、pidstat、strace、tcpdump、blktrace、iotop、slabtop、sysctl、/proc。
Linux benchmarking tools | Linux 性能测评工具
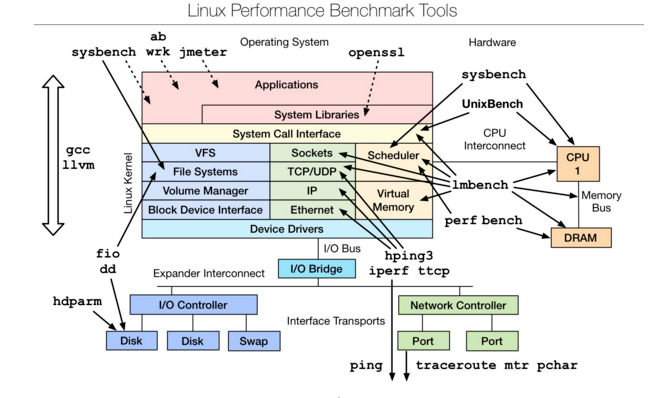
是一款性能测评工具,对于不同模块的性能测试可以使用相应的工具,想要深入了解,可以参考最下文的附件文档。
Linux tuning tools | Linux 性能调优工具
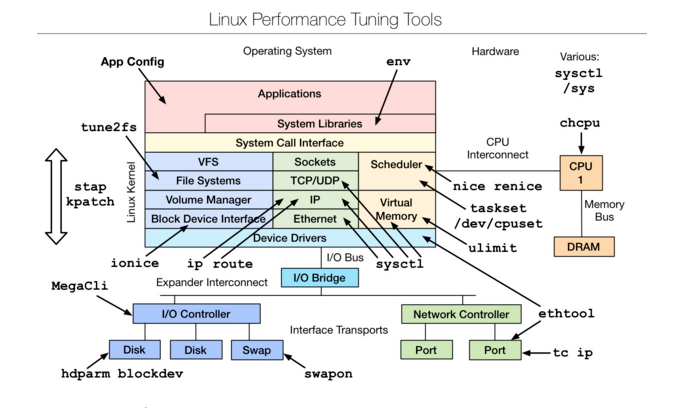
是一款性能调优工具,主要是从linux内核源码层进行的调优,想要深入了解,可以参考下文附件文档。
Linux observability sar | linux性能观测工具
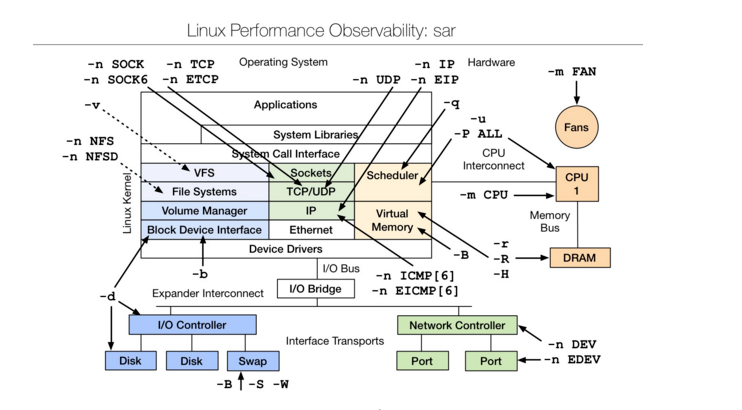
sar(System Activity Reporter系统活动情况报告)是目前LINUX上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC 有关的活动等方面。sar 的常规使用方式:
sar [options] [-A] [-o file] t [n]
其中:t 为采样间隔,n 为采样次数,默认值是1;-o file 表示将命令结果以二进制格式存放在文件中,file 是文件名。options 为命令行选项
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos sera fermé en 2024 parce que sa distribution en amont, Rhel 8, a été fermée. Cette fermeture affectera le système CentOS 8, l'empêchant de continuer à recevoir des mises à jour. Les utilisateurs doivent planifier la migration et les options recommandées incluent CentOS Stream, Almalinux et Rocky Linux pour garder le système en sécurité et stable.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
Le choix de Centos après l'arrêt de l'entretien
Apr 14, 2025 pm 08:51 PM
CentOS a été interrompu, les alternatives comprennent: 1. Rocky Linux (meilleure compatibilité); 2. Almalinux (compatible avec CentOS); 3. Serveur Ubuntu (configuration requise); 4. Red Hat Enterprise Linux (version commerciale, licence payante); 5. Oracle Linux (compatible avec Centos et Rhel). Lors de la migration, les considérations sont: la compatibilité, la disponibilité, le soutien, le coût et le soutien communautaire.
 Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Une fois CentOS arrêté, les utilisateurs peuvent prendre les mesures suivantes pour y faire face: sélectionnez une distribution compatible: comme Almalinux, Rocky Linux et CentOS Stream. Migrez vers les distributions commerciales: telles que Red Hat Enterprise Linux, Oracle Linux. Passez à Centos 9 Stream: Rolling Distribution, fournissant les dernières technologies. Sélectionnez d'autres distributions Linux: comme Ubuntu, Debian. Évaluez d'autres options telles que les conteneurs, les machines virtuelles ou les plates-formes cloud.
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Quelle configuration de l'ordinateur est requise pour VScode
Apr 15, 2025 pm 09:48 PM
Vs Code Système Exigences: Système d'exploitation: Windows 10 et supérieur, MacOS 10.12 et supérieur, processeur de distribution Linux: minimum 1,6 GHz, recommandé 2,0 GHz et au-dessus de la mémoire: minimum 512 Mo, recommandée 4 Go et plus d'espace de stockage: Minimum 250 Mo, recommandée 1 Go et plus d'autres exigences: connexion du réseau stable, xorg / wayland (Linux) recommandé et recommandée et plus
