

Cet article est une étude sur l'amélioration de l'évolutivité de l'optimisation d'ordre zéro. Le code est open source et l'article a été accepté par l'ICLR 2024.
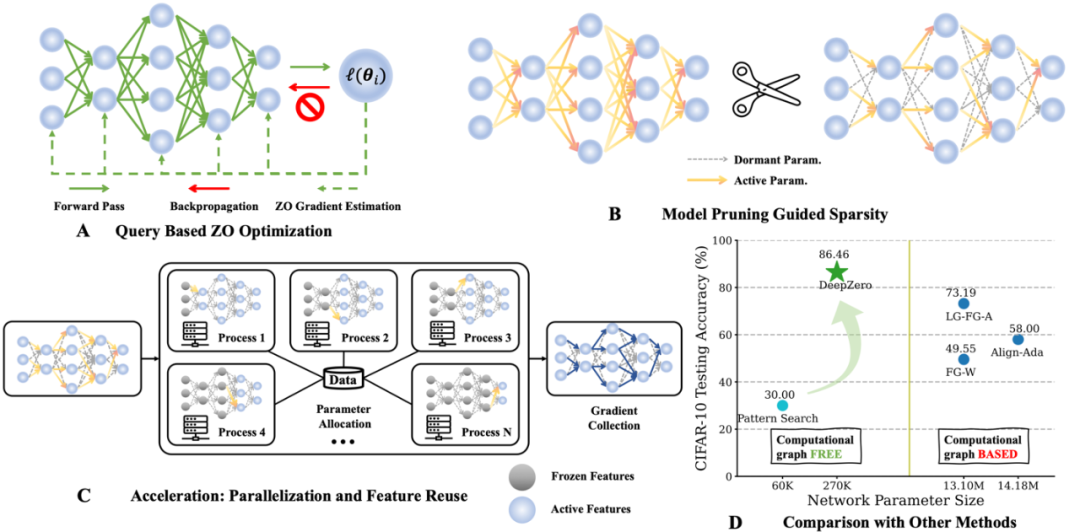
Aujourd'hui, j'aimerais vous présenter un article intitulé "DeepZero : Scaling up Zeroth-Order Optimization for Deep Model Training", qui a été réalisé en collaboration avec la Michigan State University et le Lawrence Livermore National Laboratory. Cet article a récemment été accepté par la conférence ICLR 2024 et l'équipe de recherche a rendu le code open source. L'objectif principal de cet article est d'étendre les techniques d'optimisation d'ordre zéro dans la formation de modèles d'apprentissage profond. L'optimisation d'ordre zéro est une méthode d'optimisation qui ne repose pas sur des informations de gradient et peut mieux gérer les espaces de paramètres de grande dimension et les structures de modèles complexes. Cependant, les méthodes d’optimisation d’ordre zéro existantes sont confrontées à des problèmes d’échelle et d’efficacité lorsqu’elles traitent des modèles d’apprentissage profond. Pour relever ces défis, l'équipe de recherche a proposé le cadre DeepZero. Ce cadre peut gérer efficacement la formation de modèles d'apprentissage profond à grande échelle en introduisant de nouvelles stratégies d'échantillonnage et des mécanismes d'ajustement adaptatifs. DeepZero profite de l'optimisation d'ordre zéro et combine la technologie de calcul distribué et de parallélisation pour accélérer la formation

Adresse papier : https://arxiv.org/abs/2310.02025
Adresse du projet : https ://www.optml-group.com/posts/deepzero_iclr24
1. Contexte
L'optimisation de l'ordre zéro (ZO) est devenue une solution à l'apprentissage automatique (Machine Learning) Techniques populaires pour les problèmes, en particulier lorsque les informations de premier ordre (FO) sont difficiles ou indisponibles :
Disciplines telles que la physique et la chimie : les modèles d'apprentissage automatique peuvent être couplés à des simulateurs ou à des expériences complexes. Interactions dans lesquelles le système sous-jacent n'est pas différenciable.
Scénario d'apprentissage en boîte noire : lorsqu'un modèle d'apprentissage en profondeur (Deep Learning) est intégré à une API tierce, comme les attaques contradictoires et les défenses contre les modèles d'apprentissage en profondeur en boîte noire et l'apprentissage rapide en boîte noire de services de modèles de langage.
Limites matérielles : Le principal mécanisme de rétropropagation utilisé pour calculer les gradients de premier ordre peut ne pas être pris en charge lors de la mise en œuvre de modèles d'apprentissage en profondeur sur des systèmes matériels.
Cependant, l'évolutivité de l'optimisation d'ordre zéro reste actuellement un problème non résolu : son utilisation est principalement limitée à des problèmes d'apprentissage automatique à relativement petite échelle, tels que la génération d'attaques contradictoires au niveau de l'échantillon. À mesure que la dimensionnalité du problème augmente, la précision et l’efficacité des méthodes traditionnelles d’ordre zéro diminuent. En effet, l’estimation du gradient basée sur la différence finie d’ordre zéro est une estimation biaisée du gradient du premier ordre et l’écart est plus évident dans un espace de grande dimension. Ces défis motivent la question centrale abordée dans cet article : Comment étendre l'optimisation d'ordre zéro afin qu'elle puisse former des modèles d'apprentissage profond ?
2. Estimation du gradient d'ordre zéro : RGE ou CGE ?
L'optimiseur d'ordre zéro interagit avec la fonction objectif uniquement en soumettant des entrées et en recevant les valeurs de fonction correspondantes. Il existe deux principales méthodes d'estimation du gradient : l'estimation du gradient de coordonnées (CGE) et l'estimation du gradient aléatoire (RGE), comme indiqué ci-dessous :
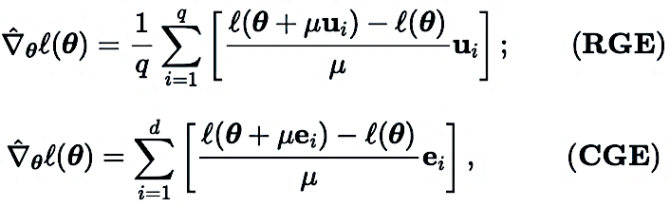
où 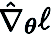 représente la variable d'optimisation
représente la variable d'optimisation 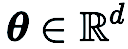 (par exemple, l'estimation neuronale du gradient de premier ordre des paramètres du modèle du réseau).
(par exemple, l'estimation neuronale du gradient de premier ordre des paramètres du modèle du réseau).
Dans (RGE), 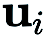 représente un vecteur de perturbation aléatoire, par exemple, tiré d'une distribution gaussienne standard ;
représente un vecteur de perturbation aléatoire, par exemple, tiré d'une distribution gaussienne standard ; 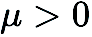 est la taille de la perturbation (également connue sous le nom de paramètre de lissage q est le nombre de directions aléatoires utilisées pour obtenir le fini) ; différence.
est la taille de la perturbation (également connue sous le nom de paramètre de lissage q est le nombre de directions aléatoires utilisées pour obtenir le fini) ; différence.
Dans (CGE), 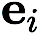 représente les vecteurs de base standard et
représente les vecteurs de base standard et 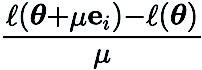 fournit une estimation par différences finies des dérivées partielles de
fournit une estimation par différences finies des dérivées partielles de 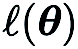 aux coordonnées correspondantes.
aux coordonnées correspondantes.
Par rapport au CGE, RGE a la flexibilité de réduire le nombre d'évaluations de fonctions. Malgré sa grande efficacité de requête, il est encore incertain si RGE peut fournir une précision satisfaisante lors de la formation de modèles approfondis à partir de zéro. À cette fin, nous avons mené une enquête dans laquelle nous avons formé de petits réseaux de neurones convolutifs (CNN) de différentes tailles sur CIFAR-10 en utilisant RGE et CGE. Comme le montre la figure ci-dessous, CGE peut atteindre une précision de test comparable à la formation d'optimisation de premier ordre, et est nettement meilleure que RGE. Elle est également plus efficace en termes de temps que RGE.
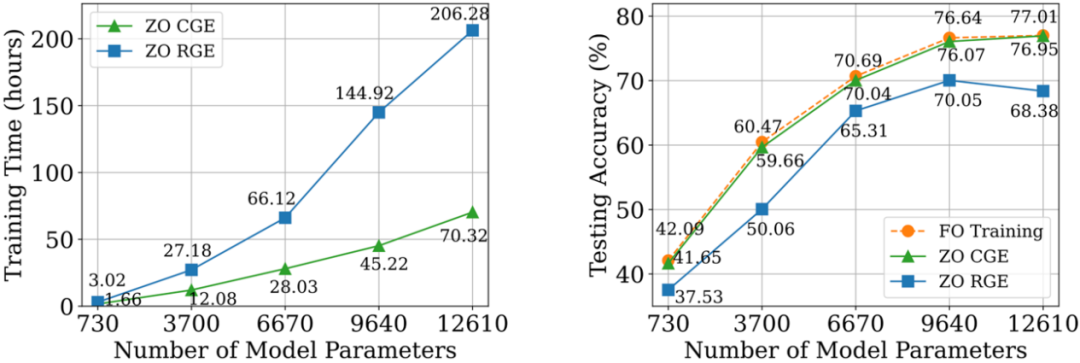
Sur la base des avantages du CGE par rapport au RGE en termes de précision et d'efficacité de calcul, Nous avons choisi le CGE comme estimateur de gradient d'ordre zéro préféré. Cependant, la complexité des requêtes de CGE reste un goulot d'étranglement car elle évolue avec la taille du modèle.
3. Framework d'apprentissage profond d'ordre zéro : DeepZero
À notre connaissance, aucun travail antérieur n'a démontré l'efficacité de l'optimisation ZO sans réduire considérablement les performances lors de la formation des réseaux de neurones profonds (DNN). Pour surmonter cet obstacle, nous avons développé DeepZero, un cadre d'apprentissage profond d'optimisation d'ordre zéro qui peut étendre l'optimisation d'ordre zéro à la formation des réseaux neuronaux à partir de zéro.
a) Élagage du modèle d'ordre zéro (ZO-GraSP) : Un réseau neuronal dense initialisé de manière aléatoire contient souvent un sous-réseau clairsemé de haute qualité. Cependant, les méthodes d’élagage les plus efficaces incluent la formation du modèle comme étape intermédiaire. Par conséquent, ils ne conviennent pas pour trouver la parcimonie via une optimisation d’ordre zéro. Pour relever les défis ci-dessus, nous nous inspirons d'une méthode d'élagage sans formation appelée élagage d'initialisation. Parmi ces méthodes, la préservation du signal de gradient (GraSP) a été choisie, qui est une méthode permettant d'identifier la rareté préalable des réseaux de neurones en initialisant de manière aléatoire le flux de gradient du réseau.
b) Sparse Gradient : Pour conserver les avantages en matière de précision de l'entraînement de modèles denses, dans CGE, nous intégrons la parcimonie du gradient au lieu de la parcimonie du poids. Cela garantit que nous formons un modèle dense dans l'espace de poids, plutôt que de former un modèle clairsemé. Plus précisément, nous utilisons ZO-GraSP pour déterminer les ratios d'élagage (LPR) par couche qui peuvent capturer la compressibilité DNN, puis l'optimisation d'ordre zéro peut former des modèles denses en mettant à jour de manière itérative et continue les poids des paramètres partiels du modèle, où le rapport de gradient clairsemé est déterminé par les LPR.
c) Réutilisation des caractéristiques : étant donné que CGE perturbe chaque paramètre par élément, il peut réutiliser les caractéristiques immédiatement avant la couche de perturbation et effectuer l'opération de propagation vers l'avant restante au lieu de partir de la couche d'entrée. Empiriquement, la CGE avec réutilisation des fonctionnalités peut permettre de réduire de plus de 2 fois le temps de formation.
d) Parallélisation passe-front : CGE prend en charge la parallélisation de la formation de modèles. Cette propriété de découplage permet d'étendre la propagation sur des machines distribuées, augmentant ainsi considérablement la vitesse de formation d'ordre zéro.
4. Analyse expérimentale
a) Classification des images
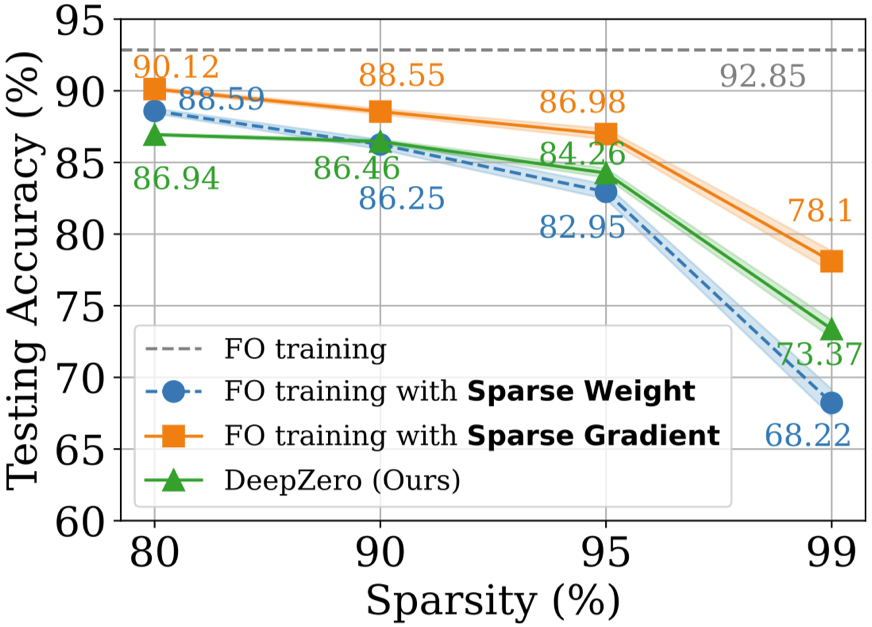
Sur l'ensemble de données CIFAR-10, nous comparons ResNet-20 entraîné par DeepZero avec deux variantes entraînées par optimisation de premier ordre :
(1) Dense ResNet -20
obtenu par formation d'optimisation de premier ordre (2) Sparse ResNet-20 obtenu par FO-GraSP par formation d'optimisation de premier ordre comme le montre la figure ci-dessous, bien qu'à 80 % à 99 % clairsemé Dans l'intervalle, par rapport à (1), le modèle formé à l'aide de DeepZero présente encore un écart de précision. Cela met en évidence les défis de l'optimisation ZO pour la formation approfondie de modèles, où des implémentations très dispersées sont souhaitées. Il convient de noter que DeepZero surpasse (2) dans l'intervalle de parcimonie de 90 % à 99 %,
démontrant la supériorité de la parcimonie du gradient sur la parcimonie du poids dans DeepZero.
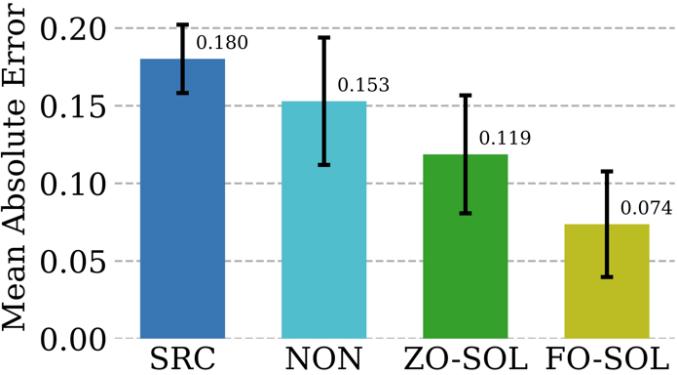
Le problème de la défense en boîte noire survient lorsque le propriétaire d'un modèle ne souhaite pas partager les détails du modèle avec le défenseur. Cela pose un défi aux algorithmes d'amélioration de la robustesse existants qui améliorent directement les modèles boîte blanche à l'aide d'un entraînement d'optimisation de premier ordre. Pour surmonter ce défi, ZO-AE-DS est proposé, qui introduit un AutoEncoder (AE) entre l'opération de défense de lissage du débruitage (DS) en boîte blanche et le classificateur d'images en boîte noire pour résoudre les défis de formation ZO Dimensionnels. ZO-AE-DS présente l'inconvénient d'être difficile à adapter à des ensembles de données haute résolution (par exemple, ImageNet), car l'utilisation d'AE compromet la fidélité des images entrées dans le classificateur d'images boîte noire et entraîne de mauvaises performances de défense. En revanche, DeepZero peut apprendre directement les opérations défensives intégrées à un classificateur boîte noire, sans avoir besoin d'un encodeur automatique. Comme le montre le tableau ci-dessous, DeepZero surpasse systématiquement le ZO-AE-DS sur tous les rayons de perturbation d'entrée en termes de précision certifiée (CA). c) Deep learning couplé à la simulation Les méthodes numériques sont indispensables pour fournir des simulations physiquement informatives, mais elles ont leurs propres défis : la discrétisation génère inévitablement des erreurs numériques. La faisabilité de la correction des réseaux de neurones grâce à un entraînement interactif cyclique avec un solveur itératif d'équation aux dérivées partielles (PDE) est appelée Solver-in-the-Loop (SOL). Alors que les travaux existants se concentrent sur l'utilisation ou le développement de simulateurs différentiables pour la formation de modèles, Nous étendons SOL en tirant parti de DeepZero pour permettre une utilisation avec des simulateurs non différentiables ou boîte noire. Le tableau suivant compare les performances de correction d'erreur de test de ZO-SOL (implémenté par DeepZero) avec trois méthodes différentiables : (1) SRC (simulation basse fidélité sans correction d'erreur) (2) NON (Non-); formation interactive, réalisée en dehors de la boucle de simulation à l'aide de données de simulation pré-générées basse et haute fidélité ; (3) FO-SOL (pour la formation de premier ordre de SOL avec un simulateur différentiable) ; L'erreur de chaque simulation de test est calculée comme l'erreur absolue moyenne (MAE) de la simulation corrigée par rapport à la simulation haute fidélité. Les résultats montrent que ZO-SOL implémenté via DeepZero surpasse toujours SRC et NON et comble l'écart de performances avec FO-SOL, même avec uniquement un accès au simulateur basé sur des requêtes. Les performances de ZO-SOL par rapport à NON mettent en évidence la promesse de ZO-SOL lorsqu'il existe une intégration de simulateur de boîte noire. 5. Résumé et discussion Cet article présente un cadre d'apprentissage en profondeur optimisé d'ordre zéro (DeepZero) pour la formation en réseau approfondie. Plus précisément, DeepZero intègre l'estimation du gradient de coordonnées, la rareté du gradient apportée par l'élagage du modèle d'ordre zéro, la réutilisation des fonctionnalités et la parallélisation passe-front dans un processus de formation unifié. En tirant parti de ces innovations, DeepZero a démontré son efficience et son efficacité dans des tâches telles que la classification d'images et une variété de scénarios pratiques d'apprentissage profond en boîte noire. De plus, l'applicabilité de DeepZero à d'autres domaines est explorée, tels que les applications impliquant des entités physiques non différenciables et la formation sur des appareils où les graphiques informatiques et les calculs de rétropropagation ne sont pas pris en charge. Présentation de l'auteur Zhang Yimeng, doctorant en informatique au laboratoire OPTML de l'Université du Michigan. Ses intérêts de recherche incluent l'IA générative, la multimodalité, la vision par ordinateur, l'IA sûre et l'IA efficace. 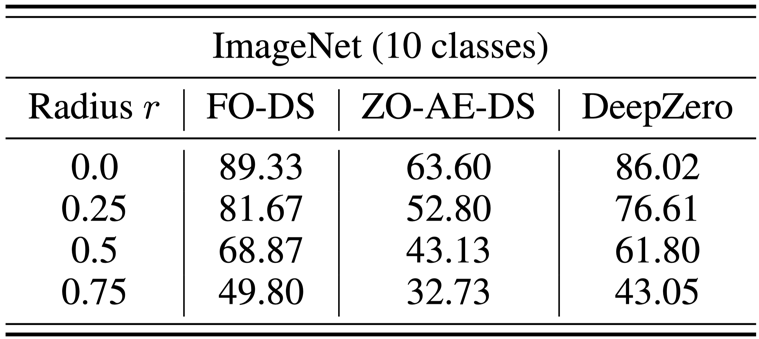
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 pas de zoom
pas de zoom
 Comment supprimer les filigranes TikTok d'autres personnes des vidéos TikTok
Comment supprimer les filigranes TikTok d'autres personnes des vidéos TikTok
 Comment déclencher un événement de pression de touche
Comment déclencher un événement de pression de touche
 Que faire si la prise chinoise est brouillée ?
Que faire si la prise chinoise est brouillée ?
 utilisation des instructions mul
utilisation des instructions mul
 Introduction à l'utilisation de Rowid dans Oracle
Introduction à l'utilisation de Rowid dans Oracle
 oracle nvl
oracle nvl
 La différence entre une demande d'obtention et une demande de publication
La différence entre une demande d'obtention et une demande de publication








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



