
 Périphériques technologiques
IA
Comment explorer et visualiser les données ML pour la détection d'objets dans les images
Périphériques technologiques
IA
Comment explorer et visualiser les données ML pour la détection d'objets dans les images
Comment explorer et visualiser les données ML pour la détection d'objets dans les images

Ces dernières années, les gens ont acquis une compréhension plus profonde de l'importance d'une compréhension approfondie des données d'apprentissage automatique (ML-data). Cependant, comme la détection de grands ensembles de données nécessite généralement un investissement humain et matériel important, son application généralisée dans le domaine de la vision par ordinateur nécessite encore des développements supplémentaires.
Habituellement, dans la détection d'objets (un sous-ensemble de la vision par ordinateur), les objets dans l'image sont positionnés en définissant des cadres de délimitation. Non seulement l'objet peut être identifié, mais le contexte, la taille et le contexte de l'objet peuvent également être identifiés. compris. Relation avec d’autres éléments de la scène. Dans le même temps, une compréhension globale de la répartition des classes, de la diversité des tailles d'objets et des environnements communs dans lesquels les classes apparaissent aidera également à découvrir des modèles d'erreur dans le modèle de formation lors de l'évaluation et du débogage, afin que des données de formation supplémentaires puissent être sélectionnés de manière plus ciblée.
En pratique, j'ai tendance à adopter l'approche suivante :
- Utiliser des modèles pré-entraînés ou des améliorations du modèle de base pour ajouter de la structure aux données. Par exemple : créer diverses incorporations d'images et utiliser des techniques de réduction de dimensionnalité telles que t-SNE ou UMAP. Ceux-ci peuvent générer des cartes de similarité pour faciliter la navigation dans les données. De plus, l'utilisation de modèles pré-entraînés pour la détection peut également faciliter l'extraction du contexte.
- Utilisez des outils de visualisation capables d'intégrer de telles structures avec des fonctions statistiques et d'examen des données brutes.
Ci-dessous, je présenterai comment utiliser Renomics Spotlight pour créer des visualisations interactives de détection d'objets. A titre d'exemple, je vais essayer de :
- Construire une visualisation pour un détecteur de personne dans une image.
- Les visualisations incluent des cartes de similarité, des filtres et des statistiques pour une exploration facile de vos données.
- Visualisez chaque image en détail avec la détection Ground Truth et Ultralytics YOLOv8.
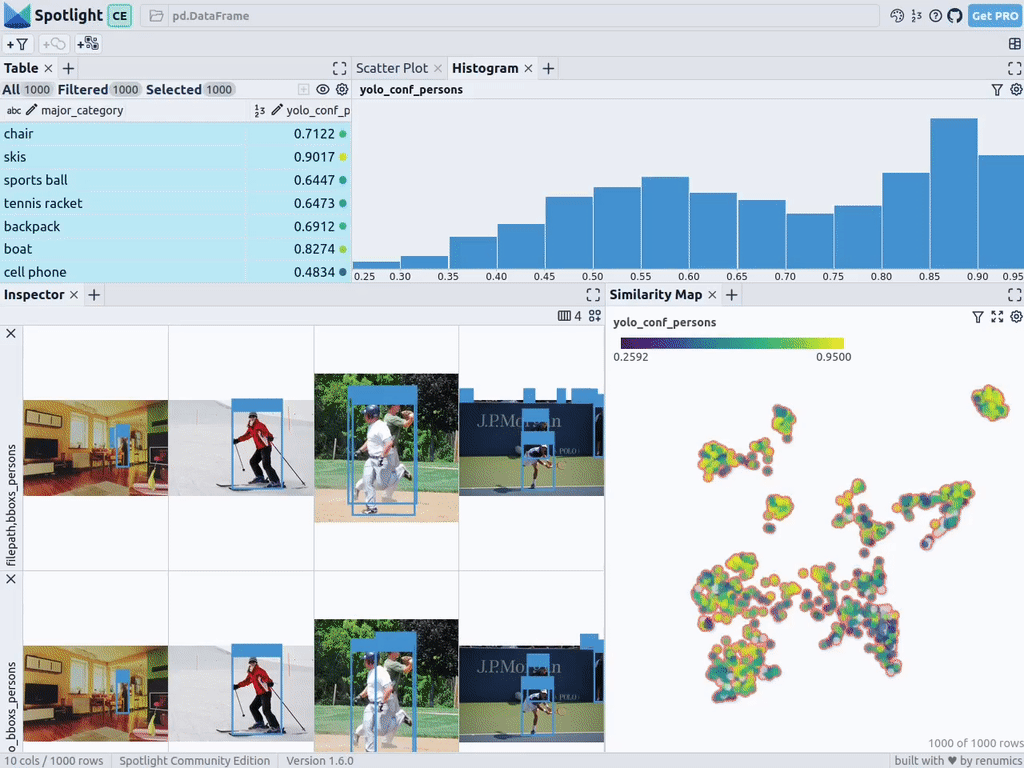
Téléchargez les images des personnes dans l'ensemble de données COCO
Tout d'abord, installez les packages requis via la commande :
!pip install fiftyone ultralytics renumics-spotlight
importpandasaspdimportnumpyasnpimportfiftyone.zooasfoz# 从 COCO 数据集中下载 1000 张带人的图像dataset = foz.load_zoo_dataset( "coco-2017"、split="validation"、label_types=[ "detections"、],classes=["person"]、 max_samples=1000、dataset_name="coco-2017-person-1k-validations"、)
Ensuite, vous pouvez utiliser le code suivant :
def xywh_too_xyxyn(bbox): "" convert from xywh to xyxyn format """ return[bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]].行 = []fori, samplein enumerate(dataset):labels = [detection.labelfordetectioninsample.ground_truth.detections] bboxs = [...bboxs = [xywh_too_xyxyn(detection.bounding_box) fordetectioninsample.ground_truth.detections]bboxs_persons = [bboxforbbox, labelin zip(bboxs, labels)iflabel =="person"] 行。row.append([sample.filepath, labels, bboxs, bboxs_persons])df = pd.DataFrame(row, columns=["filepath","categories", "bboxs", "bboxs_persons"])df["major_category"] = df["categories"].apply( lambdax:max(set(x) -set(["person"]), key=x.count) if len(set(x)) >1 else "only person"。)
pour préparer les données en tant que Pandas DataFrame, les colonnes incluent : chemin du fichier, catégorie de boîte englobante, bordure box, la personne contenue dans la case de bordure, et la catégorie principale (bien qu'il y ait des personnes) pour préciser le contexte de la personne dans l'image :
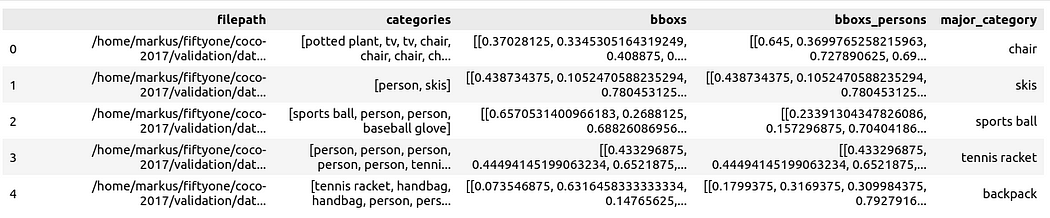
Vous pouvez ensuite la visualiser via Spotlight :
From renumics import spotlightspotlight.show(df)
Vous Vous pouvez utiliser le bouton Ajouter une vue dans la vue inspecteur et sélectionner bboxs_persons et filepath dans la vue bordure pour afficher la bordure correspondante avec l'image :
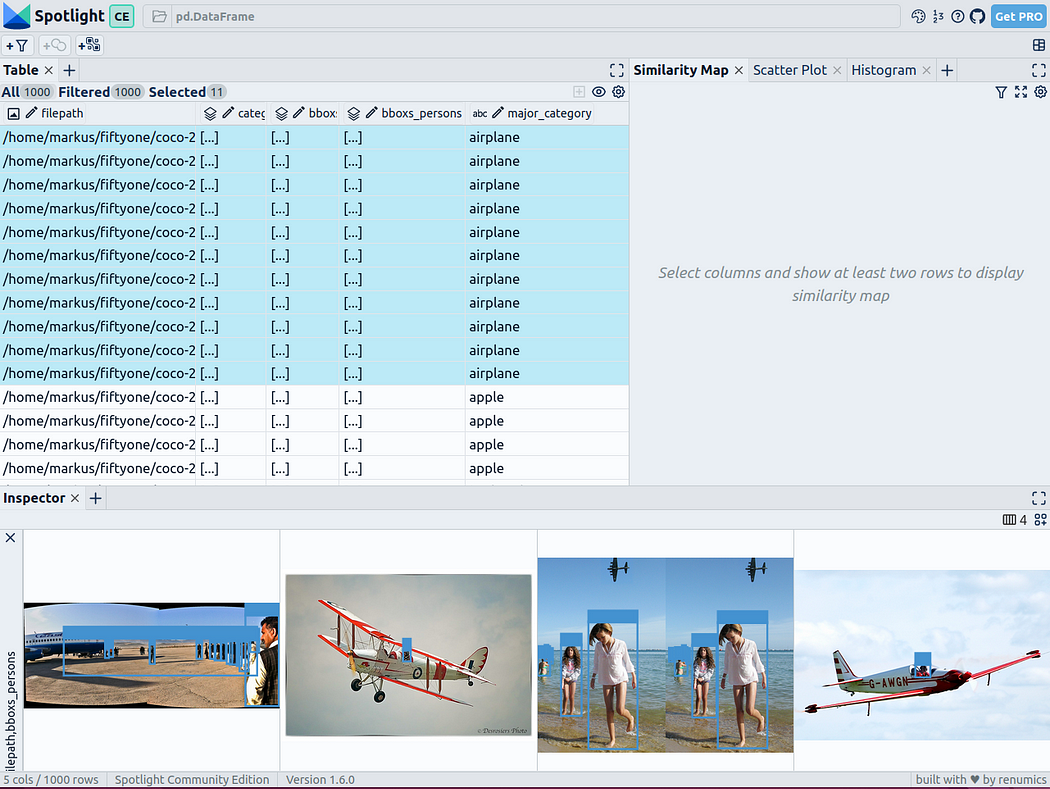
Intégrer des données riches
Pour donner de la structure aux données, nous pouvons adopter des intégrations d'images de divers modèles de base (c'est-à-dire une représentation vectorielle dense). Pour ce faire, vous pouvez utiliser d'autres techniques de réduction de dimensionnalité telles que UMAP ou t-SNE pour appliquer des intégrations Vision Transformer (ViT) de l'image entière à la structuration de l'ensemble de données, fournissant ainsi une carte de similarité 2D de l'image. De plus, vous pouvez utiliser la sortie d'un détecteur d'objets pré-entraîné pour structurer vos données en les classant selon la taille ou le nombre d'objets qu'elles contiennent. Puisque l’ensemble de données COCO fournit déjà ces informations, nous pouvons les utiliser directement.
Étant donné que Spotlight intègre la prise en charge des modèles google/vit-base-patch16-224-in21k(ViT) et UMAP , lorsque vous créez diverses intégrations à l'aide de chemins de fichiers, il sera automatiquement appliqué :
spotlight.show(df, embed=["filepath"])
通过上述代码,Spotlight 将各种嵌入进行计算,并应用 UMAP 在相似性地图中显示结果。其中,不同的颜色代表了主要的类别。据此,您可以使用相似性地图来浏览数据:
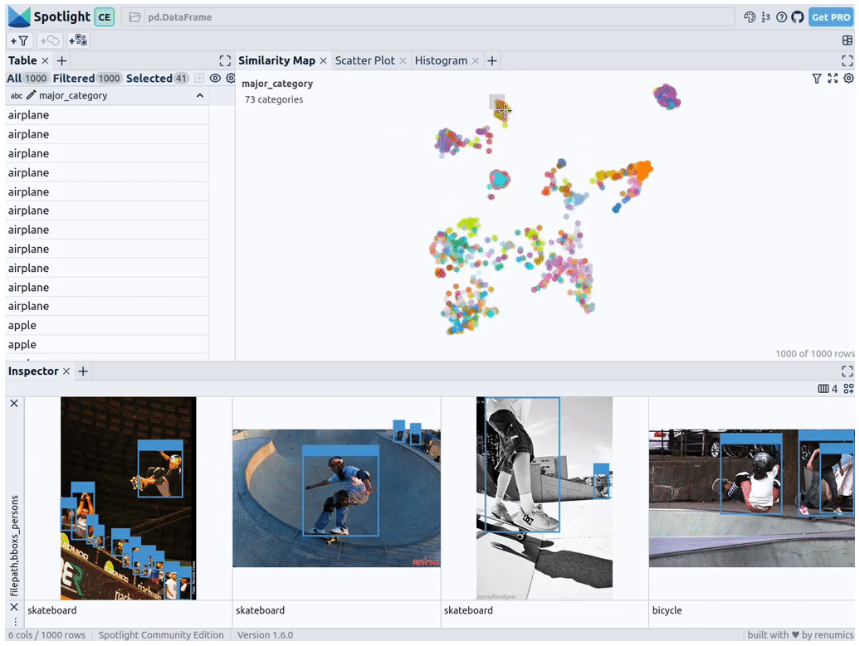
预训练YOLOv8的结果
可用于快速识别物体的Ultralytics YOLOv8,是一套先进的物体检测模型。它专为快速图像处理而设计,适用于各种实时检测任务,特别是在被应用于大量数据时,用户无需浪费太多的等待时间。
为此,您可以首先加载预训练模型:
From ultralytics import YOLOdetection_model = YOLO("yolov8n.pt")并执行各种检测:
detections = []forfilepathindf["filepath"].tolist():detection = detection_model(filepath)[0]detections.append({ "yolo_bboxs":[np.array(box.xyxyn.tolist())[0]forboxindetection.boxes]、 "yolo_conf_persons": np.mean([np.array(box.conf.tolist())[0]. forboxindetection.boxes ifdetection.names[int(box.cls)] =="person"]), np.mean(]), "yolo_bboxs_persons":[np.array(box.xyxyn.tolist())[0] forboxindetection.boxes ifdetection.names[int(box.cls)] =="person],"yolo_categories": np.array([np.array(detection.names[int(box.cls)])forboxindetection.boxes], "yolo_categories": np.array(),})df_yolo = pd.DataFrame(detections)在12gb的GeForce RTX 4070 Ti上,上述过程在不到20秒的时间内便可完成。接着,您可以将结果包含在DataFrame中,并使用Spotlight将其可视化。请参考如下代码:
df_merged = pd.concat([df, df_yolo], axis=1)spotlight.show(df_merged, embed=["filepath"])
下一步,Spotlight将再次计算各种嵌入,并应用UMAP到相似度图中显示结果。不过这一次,您可以为检测到的对象选择模型的置信度,并使用相似度图在置信度较低的集群中导航检索。毕竟,鉴于这些图像的模型是不确定的,因此它们通常有一定的相似度。
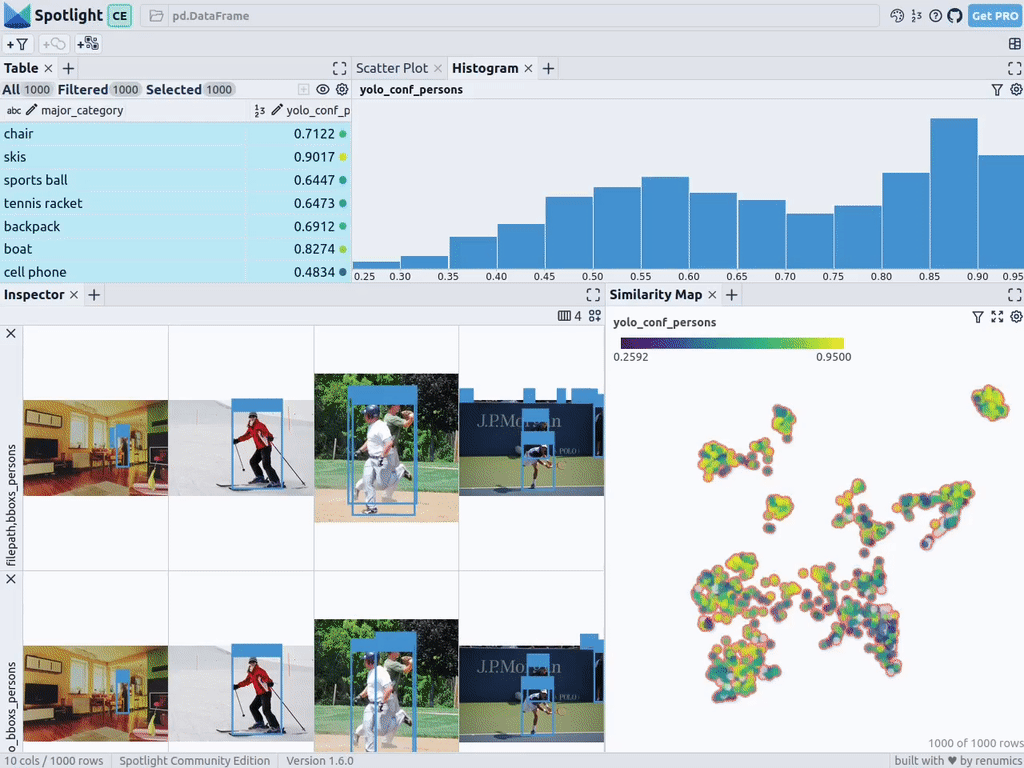
当然,上述简短的分析也表明了,此类模型在如下场景中会遇到系统性的问题:
- 由于列车体积庞大,站在车厢外的人显得非常渺小
- 对于巴士和其他大型车辆而言,车内的人员几乎看不到
- 有人站在飞机的外面
- 食物的特写图片上有人的手或手指
您可以判断这些问题是否真的会影响您的人员检测目标,如果是的话,则应考虑使用额外的训练数据,来增强数据集,以优化模型在这些特定场景中的性能。
小结
综上所述,预训练模型和 Spotlight 等工具的使用,可以让我们的对象检测可视化过程变得更加容易,进而增强数据科学的工作流程。您可以使用自己的数据去尝试和体验上述代码。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:How to Explore and Visualize ML-Data for Object Detection in Images,作者:Markus Stoll
链接:https://itnext.io/how-to-explore-and-visualize-ml-data-for-object-detection-in-images-88e074f46361。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
15 outils d'annotation d'images gratuits open source recommandés
Mar 28, 2024 pm 01:21 PM
L'annotation d'images est le processus consistant à associer des étiquettes ou des informations descriptives à des images pour donner une signification et une explication plus profondes au contenu de l'image. Ce processus est essentiel à l’apprentissage automatique, qui permet d’entraîner les modèles de vision à identifier plus précisément les éléments individuels des images. En ajoutant des annotations aux images, l'ordinateur peut comprendre la sémantique et le contexte derrière les images, améliorant ainsi la capacité de comprendre et d'analyser le contenu de l'image. L'annotation d'images a un large éventail d'applications, couvrant de nombreux domaines, tels que la vision par ordinateur, le traitement du langage naturel et les modèles de vision graphique. Elle a un large éventail d'applications, telles que l'assistance aux véhicules pour identifier les obstacles sur la route, en aidant à la détection. et le diagnostic des maladies grâce à la reconnaissance d'images médicales. Cet article recommande principalement de meilleurs outils d'annotation d'images open source et gratuits. 1.Makesens
 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Identifier le surapprentissage et le sous-apprentissage grâce à des courbes d'apprentissage
Apr 29, 2024 pm 06:50 PM
Cet article présentera comment identifier efficacement le surajustement et le sous-apprentissage dans les modèles d'apprentissage automatique grâce à des courbes d'apprentissage. Sous-ajustement et surajustement 1. Surajustement Si un modèle est surentraîné sur les données de sorte qu'il en tire du bruit, alors on dit que le modèle est en surajustement. Un modèle surajusté apprend chaque exemple si parfaitement qu'il classera mal un exemple inédit/inédit. Pour un modèle surajusté, nous obtiendrons un score d'ensemble d'entraînement parfait/presque parfait et un score d'ensemble/test de validation épouvantable. Légèrement modifié : "Cause du surajustement : utilisez un modèle complexe pour résoudre un problème simple et extraire le bruit des données. Parce qu'un petit ensemble de données en tant qu'ensemble d'entraînement peut ne pas représenter la représentation correcte de toutes les données."
 Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
Transparent! Une analyse approfondie des principes des principaux modèles de machine learning !
Apr 12, 2024 pm 05:55 PM
En termes simples, un modèle d’apprentissage automatique est une fonction mathématique qui mappe les données d’entrée à une sortie prédite. Plus précisément, un modèle d'apprentissage automatique est une fonction mathématique qui ajuste les paramètres du modèle en apprenant à partir des données d'entraînement afin de minimiser l'erreur entre la sortie prédite et la véritable étiquette. Il existe de nombreux modèles dans l'apprentissage automatique, tels que les modèles de régression logistique, les modèles d'arbre de décision, les modèles de machines à vecteurs de support, etc. Chaque modèle a ses types de données et ses types de problèmes applicables. Dans le même temps, il existe de nombreux points communs entre les différents modèles, ou il existe une voie cachée pour l’évolution du modèle. En prenant comme exemple le perceptron connexionniste, en augmentant le nombre de couches cachées du perceptron, nous pouvons le transformer en un réseau neuronal profond. Si une fonction noyau est ajoutée au perceptron, elle peut être convertie en SVM. celui-ci
 L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
L'évolution de l'intelligence artificielle dans l'exploration spatiale et l'ingénierie des établissements humains
Apr 29, 2024 pm 03:25 PM
Dans les années 1950, l’intelligence artificielle (IA) est née. C’est à ce moment-là que les chercheurs ont découvert que les machines pouvaient effectuer des tâches similaires à celles des humains, comme penser. Plus tard, dans les années 1960, le Département américain de la Défense a financé l’intelligence artificielle et créé des laboratoires pour poursuivre son développement. Les chercheurs trouvent des applications à l’intelligence artificielle dans de nombreux domaines, comme l’exploration spatiale et la survie dans des environnements extrêmes. L'exploration spatiale est l'étude de l'univers, qui couvre l'ensemble de l'univers au-delà de la terre. L’espace est classé comme environnement extrême car ses conditions sont différentes de celles de la Terre. Pour survivre dans l’espace, de nombreux facteurs doivent être pris en compte et des précautions doivent être prises. Les scientifiques et les chercheurs pensent qu'explorer l'espace et comprendre l'état actuel de tout peut aider à comprendre le fonctionnement de l'univers et à se préparer à d'éventuelles crises environnementales.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
