
 Périphériques technologiques
IA
RAG ou mise au point ? Microsoft a publié un guide sur le processus de construction d'applications de grands modèles dans des domaines spécifiques
Périphériques technologiques
IA
RAG ou mise au point ? Microsoft a publié un guide sur le processus de construction d'applications de grands modèles dans des domaines spécifiques
RAG ou mise au point ? Microsoft a publié un guide sur le processus de construction d'applications de grands modèles dans des domaines spécifiques

La génération augmentée de récupération (RAG) et le réglage fin (Fine-tuning) sont deux méthodes courantes pour améliorer les performances des grands modèles de langage, alors quelle méthode est la meilleure ? Qu'est-ce qui est le plus efficace lors de la création d'applications dans un domaine spécifique ? Ce document de Microsoft est destiné à votre référence lors du choix.
Lors de la création d'applications de modèles de langage à grande échelle, deux approches sont souvent utilisées pour incorporer des données propriétaires et spécifiques à un domaine : la génération d'améliorations de récupération et le réglage fin. La génération améliorée par la récupération améliore les capacités génératives du modèle en introduisant des données externes, tandis que le réglage fin intègre des connaissances supplémentaires dans le modèle lui-même. Cependant, notre compréhension des avantages et des inconvénients de ces deux approches est insuffisante.
Cet article présente une nouvelle orientation proposée par les chercheurs de Microsoft, qui consiste à créer des assistants d'IA avec un contexte spécifique et des capacités de réponse adaptative pour l'industrie agricole. En introduisant un processus complet de modèle de langage à grande échelle, des questions et des réponses de haute qualité et spécifiques à l'industrie peuvent être générées. Le processus consiste en une série systématique d'étapes, commençant par l'identification et la collecte de documents pertinents couvrant un large éventail de sujets agricoles. Ces documents sont ensuite nettoyés et structurés pour générer des paires question-réponse significatives à l'aide du modèle GPT de base. Enfin, les paires question-réponse générées sont évaluées et filtrées en fonction de leur qualité. Cette approche fournit à l'industrie agricole un outil puissant qui peut fournir des informations précises et pratiques pour aider les agriculteurs et les praticiens concernés à mieux faire face aux divers problèmes et défis.
Cet article vise à créer des ressources de connaissances précieuses pour l'industrie agricole, en utilisant l'agriculture comme étude de cas. Son objectif ultime est de contribuer au développement du LLM dans le secteur agricole.

Adresse de l'article : https://arxiv.org/pdf/2401.08406.pdf
Titre de l'article : RAG vs Fine-tuning : pipelines, compromis et étude de cas sur l'agriculture
L'objectif du processus de cet article est de générer des questions et des réponses spécifiques à un domaine qui répondent aux besoins de professionnels et de parties prenantes spécifiques de l'industrie. Dans ce secteur, les réponses attendues des assistants IA doivent être basées sur des facteurs pertinents spécifiques au secteur.
Cet article porte sur la recherche agricole et le but est de générer des réponses dans ce domaine spécifique. Le point de départ de la recherche est donc un ensemble de données agricoles, qui est alimenté en trois composants principaux : Génération de questions et réponses, génération d'amélioration de la récupération et processus de réglage fin. La génération question-réponse crée des paires question-réponse basées sur les informations contenues dans l'ensemble de données agricoles, et la génération augmentée par récupération l'utilise comme source de connaissances. Les données générées sont affinées et utilisées pour affiner plusieurs modèles, dont la qualité est évaluée via un ensemble de métriques proposées. Grâce à cette approche globale, exploitez la puissance des grands modèles linguistiques au profit du secteur agricole et d’autres parties prenantes.
Cet article apporte des contributions particulières à la compréhension des grands modèles de langage dans le domaine agricole. Ces contributions peuvent être résumées comme suit :
1, Évaluation complète des LLM : Cet article mène une évaluation approfondie des grands modèles de langage, dont LlaMa2-13B, GPT-4 et Vicuna pour répondre aux questions liées à l'agriculture. Un ensemble de données de référence provenant des principaux pays producteurs agricoles a été utilisé pour l’évaluation. Dans cette analyse, GPT-4 surpasse systématiquement les autres modèles, mais les coûts associés à son réglage fin et à son inférence doivent être pris en compte.
2. L'impact de la technologie de récupération et du réglage fin sur les performances : Cet article étudie l'impact de la technologie de récupération et du réglage fin sur les performances des LLM. La recherche a montré que la génération d’améliorations de récupération et le réglage fin sont des techniques efficaces pour améliorer les performances des LLM.
3. Impact des applications potentielles des LLM dans différentes industries : Pour les processus qui souhaitent établir un RAG et affiner la technologie pour une application dans les LLM, cet article franchit une étape pionnière et favorise la coopération entre plusieurs industries.
Méthodologie
La partie 2 de cet article détaille la méthodologie adoptée, y compris le processus d'acquisition de données, le processus d'extraction d'informations, la génération de questions et réponses et l'affinement du modèle. La méthodologie s'articule autour d'un processus conçu pour générer et évaluer des paires question-réponse pour créer des assistants spécifiques à un domaine, comme le montre la figure 1 ci-dessous.
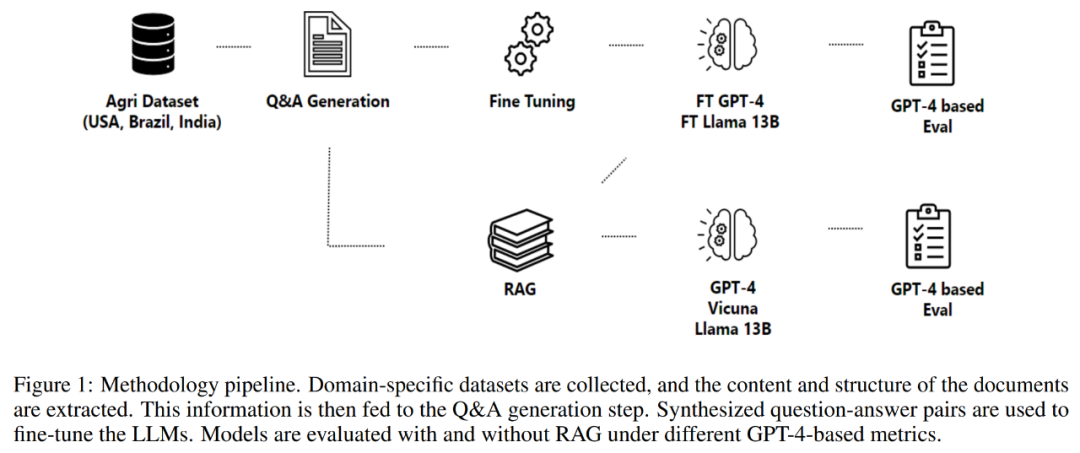
Le processus commence par l'acquisition de données, qui comprend l'obtention de données provenant de divers référentiels de haute qualité, tels que des agences gouvernementales, des bases de données de connaissances scientifiques, et l'utilisation de données propriétaires si nécessaire.
Après avoir terminé l'acquisition des données, le processus continue d'extraire des informations des documents collectés. Cette étape est cruciale car elle implique d’analyser des fichiers PDF complexes et non structurés pour récupérer leur contenu et leur structure. La figure 2 ci-dessous montre un exemple de fichier PDF de l'ensemble de données.

La prochaine étape du processus est la génération de questions et de réponses. L’objectif ici est de générer des questions contextuelles de haute qualité qui reflètent fidèlement le contenu du texte extrait. Cette méthode adopte un cadre pour contrôler la composition structurelle des entrées et des sorties, améliorant ainsi l'effet global de la réponse générée par le modèle de langage.
Le processus génère ensuite des réponses aux questions formulées. L'approche adoptée ici exploite la génération améliorée par la récupération, combinant les capacités des mécanismes de récupération et de génération pour créer des réponses de haute qualité.
Enfin, le processus affine le modèle via des questions-réponses. Le processus d'optimisation utilise des méthodes telles que l'ajustement de bas rang (LoRA) pour garantir une compréhension complète du contenu et du contexte de la littérature scientifique, ce qui en fait une ressource précieuse dans divers domaines ou industries.
Ensembles de données
L'étude évalue un modèle de langage généré par un réglage fin et une amélioration de la récupération, à l'aide d'un ensemble de données de questions et réponses contextuelles provenant de trois principaux pays producteurs de cultures : les États-Unis, le Brésil et l'Inde. Dans le cas de cet article, l’agriculture est utilisée comme contexte industriel. Les données disponibles varient considérablement dans leur format et leur contenu, allant des documents réglementaires aux rapports scientifiques en passant par les examens agronomiques et les bases de données de connaissances.
Cet article a rassemblé des informations à partir de documents en ligne, de manuels et de rapports accessibles au public du ministère américain de l'Agriculture, des agences nationales de services agricoles et aux consommateurs, et d'autres.
Les documents disponibles comprennent des informations sur la réglementation et la politique fédérales sur la gestion des cultures et du bétail, les maladies et les meilleures pratiques, l'assurance qualité et les réglementations d'exportation, les détails du programme d'assistance, ainsi que des conseils en matière d'assurance et de tarification. Les données collectées totalisent plus de 23 000 fichiers PDF contenant plus de 50 millions de jetons et couvrent 44 États américains. Les chercheurs ont téléchargé et prétraité ces fichiers pour extraire des informations textuelles qui pourraient être utilisées comme entrée dans le processus de génération de questions et réponses.
Pour comparer et évaluer le modèle, cet article utilise des documents liés à l'État de Washington, qui comprennent 573 fichiers contenant plus de 2 millions de jetons. Le listing 5 ci-dessous montre un exemple du contenu de ces fichiers.

Metrics
L'objectif principal de cette section est d'établir un ensemble complet de métriques dans le but de guider l'évaluation de la qualité du processus de génération de questions et réponses, en particulier l'évaluation du réglage fin et de l'amélioration de la récupération. méthodes de génération.
Lors de l’élaboration de métriques, plusieurs facteurs clés doivent être pris en compte. Premièrement, la subjectivité inhérente à la qualité des questions pose des défis importants.
Deuxièmement, les métriques doivent prendre en compte la pertinence du problème et la dépendance de l'aspect pratique au contexte.
Troisièmement, la diversité et la nouveauté des questions générées doivent être évaluées. Un système de génération de questions solide doit être capable de générer un large éventail de questions couvrant tous les aspects d'un élément de contenu donné. Cependant, quantifier la diversité et la nouveauté peut s’avérer difficile, car cela implique d’évaluer le caractère unique des questions et leur similitude avec le contenu et d’autres questions générées.
Enfin, les bonnes questions devraient pouvoir trouver une réponse en fonction du contenu fourni. Évaluer si une question peut recevoir une réponse précise à l’aide des informations disponibles nécessite une compréhension approfondie du contenu et la capacité d’identifier les informations pertinentes pour répondre à la question.
Ces mesures jouent un rôle essentiel pour garantir que les réponses fournies par le modèle répondent à la question avec précision, pertinence et efficacité. Cependant, il existe un manque important de mesures spécifiquement conçues pour évaluer la qualité des questions.
Conscient de ce manque, cet article se concentre sur le développement de mesures conçues pour évaluer la qualité des questions. Étant donné le rôle essentiel des questions dans la conduite de conversations significatives et la génération de réponses utiles, garantir la qualité de vos questions est tout aussi important que garantir la qualité de vos réponses.
La métrique développée dans cet article vise à combler les lacunes des recherches précédentes dans ce domaine et à fournir un moyen d'évaluer de manière globale la qualité des questions, ce qui aura un impact significatif sur la progression du processus de génération de questions et réponses. "Évaluation du problème" tour
Divers Sexualité
- Détails
- Maîtrise
- Évaluation des réponses Étant donné que les grands modèles de langage ont tendance à générer des réponses conversationnelles longues, détaillées, informatives, évaluer les réponses qu'ils génèrent est un défi.
Cet article utilise l'évaluation du modèle AzureML, en utilisant les métriques suivantes pour comparer les réponses générées à la situation réelle :
Cohérence : compare la cohérence entre la situation réelle et la prédiction, compte tenu du contexte.
Pertinence : mesure l'efficacité avec laquelle une réponse répond aux principaux aspects de la question dans son contexte.
Authenticité : définit si la réponse correspond logiquement aux informations contenues dans le contexte et fournit un score entier pour déterminer l'authenticité de la réponse.
Évaluation du modèle
Pour évaluer différents modèles affinés, cet article utilise GPT-4 comme évaluateur. Environ 270 paires de questions et réponses ont été générées à partir de documents agricoles en utilisant GPT-4 comme ensemble de données réelles. Pour chaque modèle affiné et modèle génératif augmenté par la récupération, des réponses à ces questions sont générées.
Cet article évalue les LLM sur plusieurs mesures différentes :
Évaluation avec des lignes directrices : pour chaque paire question-réponse du monde réel, cet article invite GPT-4 à générer un guide d'évaluation qui répertorie la bonne réponse si ce qui est inclus . GPT-4 a ensuite été invité à noter chaque réponse sur une échelle de 0 à 1 en fonction des critères du guide d'évaluation. Voici un exemple :
Brièveté : Créez une rubrique qui décrit ce que des réponses concises et longues pourraient inclure. Sur la base de cette rubrique, les réponses à la situation réelle et les invites de réponse LLM sont demandées à GPT-4 pour une note sur une échelle de 1 à 5.
Exactement : Cet article crée une rubrique qui décrit ce que doit contenir une réponse complète, partiellement correcte ou incorrecte. Sur la base de cette rubrique, les réponses à la situation réelle et les invites de réponse LLM sont demandées à GPT-4 pour une note correcte, incorrecte ou partiellement correcte.
Expériences
Les expériences de cet article sont divisées en plusieurs expériences indépendantes, chacune se concentrant sur des aspects spécifiques de la génération et de l'évaluation de questions et réponses, de la génération d'amélioration de la récupération et du réglage fin.
Ces expériences explorent les domaines suivants :
Qualité des questions et réponses
Etudes contextuelles
Calculs du modèle aux métriques
Génération combinée vs génération séparée
-
Études d'ablation de récupération
Affiner la
Qualité des questions et réponses
Cette expérience évalue la qualité des paires question-réponse générées par trois grands modèles de langage, à savoir GPT-3, GPT-3.5 et GPT-4, dans différents contextes. L'évaluation de la qualité est basée sur plusieurs mesures, notamment la pertinence, la couverture, le chevauchement et la diversité.
Context Study
Cette expérience étudie l'impact de différents paramètres de contexte sur les performances des questions et réponses générées par le modèle. Il évalue les paires question-réponse générées selon trois paramètres de contexte : aucun contexte, contexte et contexte externe. Un exemple est fourni dans le tableau 12.

Dans le cadre sans contexte, GPT-4 a la couverture et la taille d'indices les plus élevées parmi les trois modèles, ce qui indique qu'il peut couvrir plus de parties de texte, mais génère des questions plus longues. Cependant, les trois modèles ont des valeurs numériques similaires en termes de variété, de chevauchement, de pertinence et de fluidité.
Lorsque le contexte est inclus, GPT-3.5 a une légère augmentation de couverture par rapport à GPT-3, tandis que GPT-4 conserve la couverture la plus élevée. Pour Size Prompt, GPT-4 a la valeur la plus élevée, indiquant sa capacité à générer des questions et des réponses plus longues.
En termes de diversité et de chevauchement, les trois modèles fonctionnent de manière similaire. En termes de pertinence et de fluidité, GPT-4 présente une légère augmentation par rapport aux autres modèles.
Dans des contextes externes, la situation est similaire.
De plus, lorsque l'on examine chaque modèle, le paramètre sans contexte semble offrir le meilleur équilibre pour GPT-4 en termes de couverture moyenne, de diversité, de chevauchement, de pertinence et de fluidité, mais génère des paires de questions-réponses plus courtes. Le contexte a entraîné des paires de questions-réponses plus longues et une légère diminution des autres mesures, à l'exception de la taille. Le contexte externe a produit les paires de questions-réponses les plus longues, mais a maintenu une couverture moyenne et une pertinence et une fluidité moyennes légèrement accrues.
Dans l'ensemble, pour GPT-4, le paramètre sans contexte semble offrir le meilleur équilibre en termes de couverture moyenne, de diversité, de chevauchement, de pertinence et de fluidité, mais génère des réponses plus courtes. Les paramètres contextuels ont entraîné des invites plus longues et de légères diminutions des autres mesures. Le contexte externe a généré les invites les plus longues, mais a maintenu une couverture moyenne avec de légères augmentations de la pertinence et de la fluidité moyennes.
Le choix entre ces trois dépendra donc des exigences spécifiques de la tâche. Si la longueur de l’invite n’est pas prise en compte, le contexte externe peut être le meilleur choix en raison de scores de pertinence et de fluidité plus élevés.
Calcul du modèle au calcul métrique
Cette expérience compare les performances de GPT-3.5 et GPT-4 dans le calcul d'une métrique utilisée pour évaluer la qualité des paires question-réponse.
Dans l'ensemble, bien que GPT-4 évalue généralement les paires de questions-réponses générées comme plus fluides et contextuellement authentiques, elles sont moins diversifiées et moins pertinentes que les évaluations de GPT-3.5. Ces perspectives sont essentielles pour comprendre comment différents modèles perçoivent et évaluent la qualité du contenu généré.
Comparaison entre génération combinée et génération individuelle
Cette expérience explore les avantages et les inconvénients entre la génération de questions et de réponses individuellement et la génération de questions et de réponses en combinaison, et se concentre sur la comparaison en termes d'efficacité d'utilisation des jetons.
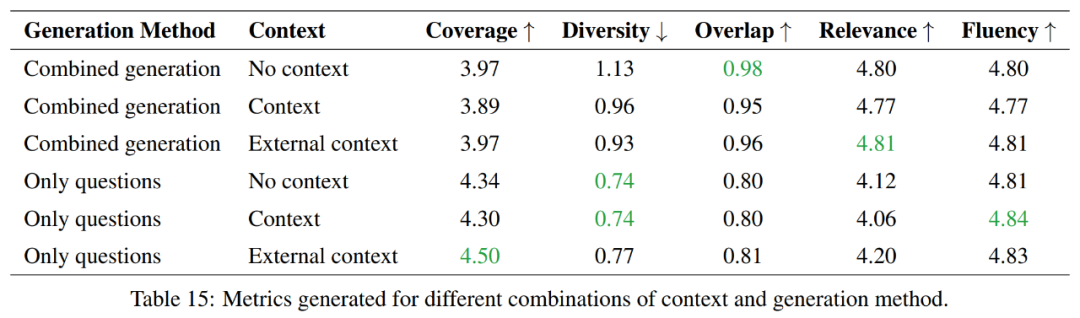
Dans l'ensemble, les méthodes de génération de questions uniquement offrent une meilleure couverture et une diversité moindre, tandis que les méthodes de génération combinées obtiennent des résultats plus élevés en termes de chevauchement et de corrélation. En termes de fluidité, les deux méthodes fonctionnent de manière similaire. Le choix entre ces deux méthodes dépendra donc des exigences spécifiques de la tâche.
Si l'objectif est de couvrir plus d'informations et de maintenir plus de diversité, alors l'approche par questions uniquement sera privilégiée. Toutefois, si l’on souhaite maintenir un degré élevé de chevauchement avec le matériel source, une approche de génération combinée serait alors un meilleur choix.
Retrieval Ablation Study
Cette expérience évalue les capacités de récupération de la génération d'amélioration de la récupération, une méthode qui améliore les connaissances inhérentes aux LLM en fournissant un contexte supplémentaire lors de la réponse aux questions.
Cet article étudie l'impact du nombre de fragments récupérés (c'est-à-dire top-k) sur les résultats et présente les résultats dans le tableau 16. En considérant davantage de fragments, la génération améliorée par la récupération est capable de récupérer les extraits originaux de manière plus cohérente.
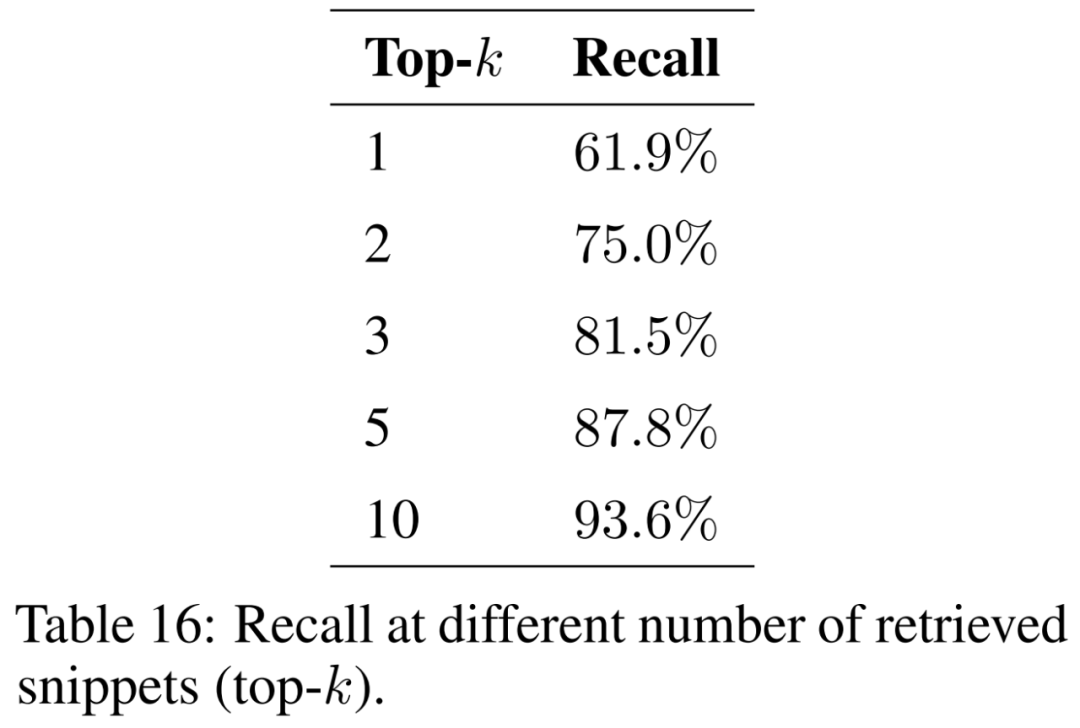
Pour garantir que le modèle puisse traiter des problèmes issus de divers contextes et phénomènes géographiques, le corpus de documents justificatifs doit être élargi pour couvrir une variété de sujets. On s'attend à ce que la taille de l'index augmente à mesure que davantage de documents sont pris en compte. Cela peut augmenter le nombre de collisions entre segments similaires lors de la récupération, entravant la capacité de récupérer les informations pertinentes pour la question saisie et réduisant le rappel.
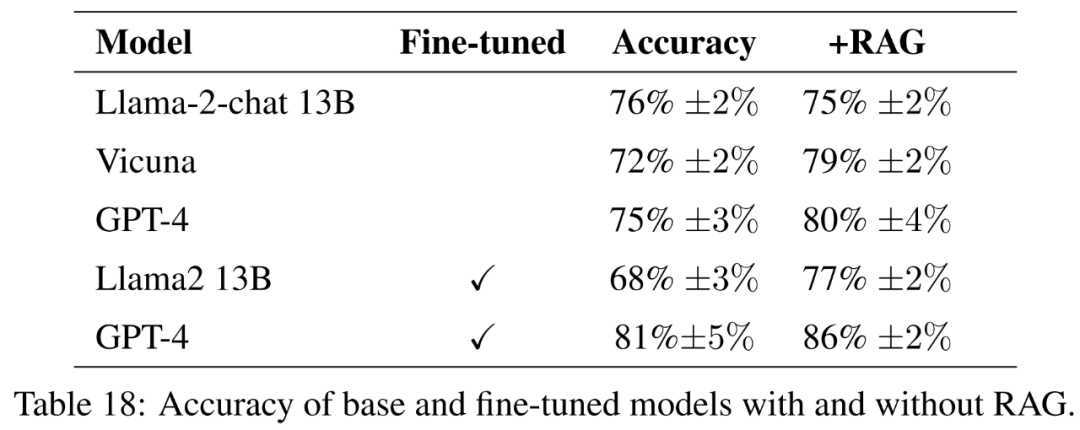
Réglage fin
Cette expérience évalue la différence de performances entre le modèle affiné et le modèle affiné des instructions de base. L’objectif est de comprendre le potentiel du réglage fin pour aider les modèles à acquérir de nouvelles connaissances.
Pour le modèle de base, cet article évalue les modèles open source Llama2-13B-chat et Vicuna-13B-v1.5-16k. Ces deux modèles sont relativement petits et représentent un compromis intéressant entre calcul et performances. Les deux modèles sont des versions affinées du Llama2-13B, utilisant des méthodes différentes.
Llama2-13B-chat est un enseignement affiné via un réglage fin supervisé et un apprentissage par renforcement. Vicuna-13B-v1.5-16k est une version affinée de l'instruction via un réglage fin supervisé sur l'ensemble de données ShareGPT. De plus, cet article évalue la base GPT-4 comme une alternative plus grande, plus coûteuse et plus puissante.
Pour le modèle affiné, cet article affine Llama2-13B directement sur les données agricoles afin de comparer ses performances avec des modèles similaires affinés pour des tâches plus générales. Cet article affine également GPT-4 pour évaluer si le réglage fin est toujours utile sur les très grands modèles. Les résultats de l’évaluation avec lignes directrices sont présentés dans le tableau 18.
Pour mesurer pleinement la qualité des réponses, en plus de l'exactitude, cet article évalue également la concision des réponses.
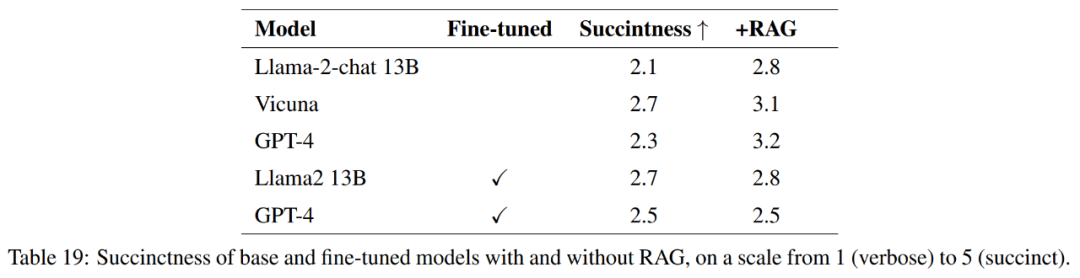
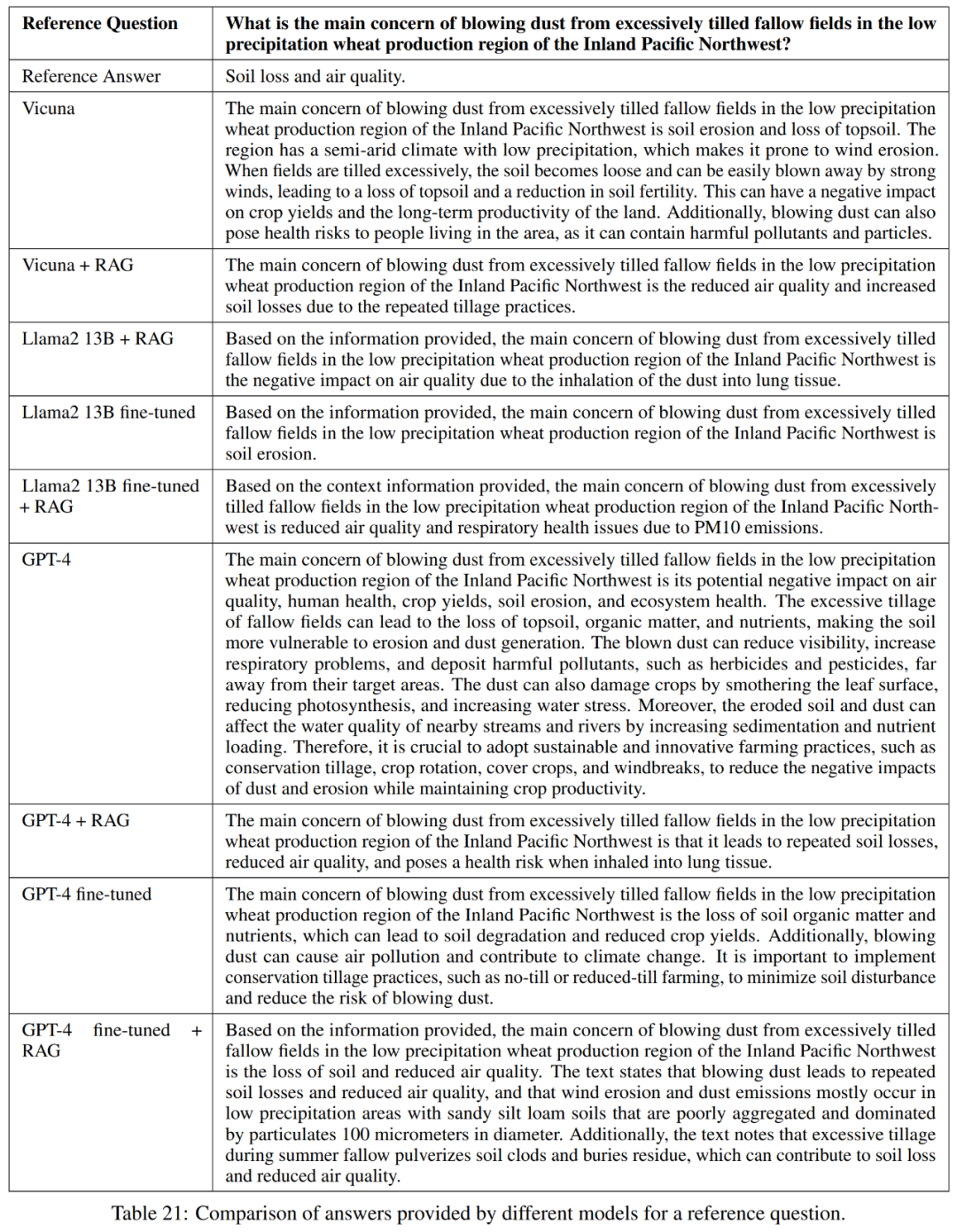
Comme le montre le tableau 21, ces modèles n'apportent pas toujours une réponse complète à la question. Par exemple, certaines réponses ont signalé l’érosion des sols comme un problème mais n’ont pas mentionné la qualité de l’air.
Dans l'ensemble, les modèles les plus performants en termes de réponse précise et concise aux réponses de référence sont Vicuna + génération améliorée par récupération, GPT-4 + génération améliorée par récupération, réglage fin GPT-4 et réglage fin GPT-4. + Génération d'amélioration de la récupération. Ces modèles offrent un mélange équilibré d’exactitude, de simplicité et de profondeur d’informations.
Découverte de connaissances
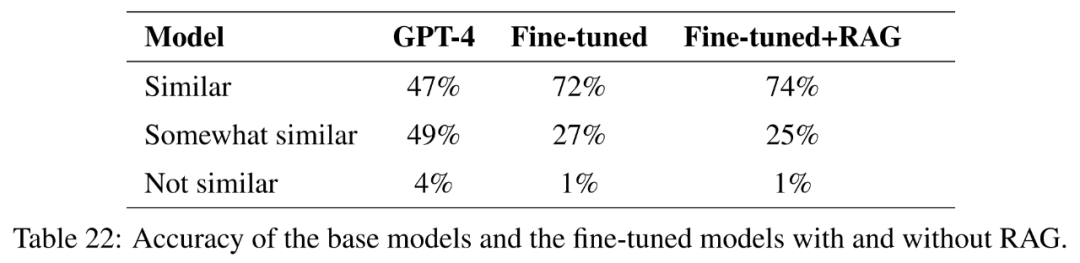
L'objectif de recherche de cet article est d'explorer le potentiel de réglage fin pour aider GPT-4 à acquérir de nouvelles connaissances, ce qui est crucial pour la recherche appliquée.
Pour tester cela, cet article sélectionne des questions similaires dans au moins trois des 50 États des États-Unis. La similarité cosinusoïdale des plongements a ensuite été calculée et une liste de 1 000 questions de ce type a été identifiée. Ces questions sont supprimées de l'ensemble de formation, et le réglage fin et la génération améliorée par récupération sont utilisés pour évaluer si GPT-4 est capable d'acquérir de nouvelles connaissances basées sur les similitudes entre les différents états.
Veuillez vous référer à l'article original pour plus de résultats expérimentaux.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Le robot DeepMind joue au tennis de table, et son coup droit et son revers glissent dans les airs, battant complètement les débutants humains
Aug 09, 2024 pm 04:01 PM
Mais peut-être qu’il ne pourra pas vaincre le vieil homme dans le parc ? Les Jeux Olympiques de Paris battent leur plein et le tennis de table suscite beaucoup d'intérêt. Dans le même temps, les robots ont également réalisé de nouvelles avancées dans le domaine du tennis de table. DeepMind vient tout juste de proposer le premier agent robot apprenant capable d'atteindre le niveau des joueurs amateurs humains de tennis de table de compétition. Adresse papier : https://arxiv.org/pdf/2408.03906 Quelle est la capacité du robot DeepMind à jouer au tennis de table ? Probablement à égalité avec les joueurs amateurs humains : tant en coup droit qu'en revers : l'adversaire utilise une variété de styles de jeu, et le robot peut également résister : recevoir des services avec des tours différents : Cependant, l'intensité du jeu ne semble pas aussi intense que le vieil homme dans le parc. Pour les robots, le tennis de table
 La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
La première griffe mécanique ! Yuanluobao est apparu à la World Robot Conference 2024 et a lancé le premier robot d'échecs pouvant entrer dans la maison
Aug 21, 2024 pm 07:33 PM
Le 21 août, la Conférence mondiale sur les robots 2024 s'est tenue en grande pompe à Pékin. La marque de robots domestiques de SenseTime, "Yuanluobot SenseRobot", a dévoilé toute sa famille de produits et a récemment lancé le robot de jeu d'échecs Yuanluobot AI - Chess Professional Edition (ci-après dénommé "Yuanluobot SenseRobot"), devenant ainsi le premier robot d'échecs au monde pour le maison. En tant que troisième produit robot jouant aux échecs de Yuanluobo, le nouveau robot Guoxiang a subi un grand nombre de mises à niveau techniques spéciales et d'innovations en matière d'IA et de machines d'ingénierie. Pour la première fois, il a réalisé la capacité de ramasser des pièces d'échecs en trois dimensions. grâce à des griffes mécaniques sur un robot domestique et effectuer des fonctions homme-machine telles que jouer aux échecs, tout le monde joue aux échecs, réviser la notation, etc.
 Microsoft publie la mise à jour cumulative Win11 août : amélioration de la sécurité, optimisation de l'écran de verrouillage, etc.
Aug 14, 2024 am 10:39 AM
Microsoft publie la mise à jour cumulative Win11 août : amélioration de la sécurité, optimisation de l'écran de verrouillage, etc.
Aug 14, 2024 am 10:39 AM
Selon les informations de ce site du 14 août, lors de la journée d'événement Patch Tuesday d'aujourd'hui, Microsoft a publié des mises à jour cumulatives pour les systèmes Windows 11, notamment la mise à jour KB5041585 pour 22H2 et 23H2 et la mise à jour KB5041592 pour 21H2. Après l'installation de l'équipement mentionné ci-dessus avec la mise à jour cumulative d'août, les changements de numéro de version attachés à ce site sont les suivants : Après l'installation de l'équipement 21H2, le numéro de version est passé à Build22000.314722H2. le numéro de version est passé à Build22621.403723H2. Après l'installation de l'équipement, le numéro de version est passé à Build22631.4037. Le contenu principal de la mise à jour KB5041585 pour Windows 1121H2 est le suivant : Amélioration : Amélioré.
 Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
Claude aussi est devenu paresseux ! Internaute : apprenez à vous accorder des vacances
Sep 02, 2024 pm 01:56 PM
La rentrée scolaire est sur le point de commencer, et ce ne sont pas seulement les étudiants qui sont sur le point de commencer le nouveau semestre qui doivent prendre soin d’eux-mêmes, mais aussi les grands modèles d’IA. Il y a quelque temps, Reddit était rempli d'internautes se plaignant de la paresse de Claude. « Son niveau a beaucoup baissé, il fait souvent des pauses et même la sortie devient très courte. Au cours de la première semaine de sortie, il pouvait traduire un document complet de 4 pages à la fois, mais maintenant il ne peut même plus produire une demi-page. !" https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dans un post intitulé "Totalement déçu par Claude", plein de
 Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference, ce robot domestique porteur de « l'espoir des futurs soins aux personnes âgées » a été entouré
Aug 22, 2024 pm 10:35 PM
Lors de la World Robot Conference qui se tient à Pékin, l'exposition de robots humanoïdes est devenue le centre absolu de la scène. Sur le stand Stardust Intelligent, l'assistant robot IA S1 a réalisé trois performances majeures de dulcimer, d'arts martiaux et de calligraphie. un espace d'exposition, capable à la fois d'arts littéraires et martiaux, a attiré un grand nombre de publics professionnels et de médias. Le jeu élégant sur les cordes élastiques permet au S1 de démontrer un fonctionnement fin et un contrôle absolu avec vitesse, force et précision. CCTV News a réalisé un reportage spécial sur l'apprentissage par imitation et le contrôle intelligent derrière "Calligraphy". Le fondateur de la société, Lai Jie, a expliqué que derrière les mouvements soyeux, le côté matériel recherche le meilleur contrôle de la force et les indicateurs corporels les plus humains (vitesse, charge). etc.), mais du côté de l'IA, les données réelles de mouvement des personnes sont collectées, permettant au robot de devenir plus fort lorsqu'il rencontre une situation forte et d'apprendre à évoluer rapidement. Et agile
 Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Annonce des prix ACL 2024 : l'un des meilleurs articles sur le déchiffrement Oracle par HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Les contributeurs ont beaucoup gagné de cette conférence ACL. L'ACL2024, d'une durée de six jours, se tient à Bangkok, en Thaïlande. ACL est la plus grande conférence internationale dans le domaine de la linguistique informatique et du traitement du langage naturel. Elle est organisée par l'Association internationale pour la linguistique informatique et a lieu chaque année. L'ACL s'est toujours classée première en termes d'influence académique dans le domaine de la PNL, et c'est également une conférence recommandée par le CCF-A. La conférence ACL de cette année est la 62e et a reçu plus de 400 travaux de pointe dans le domaine de la PNL. Hier après-midi, la conférence a annoncé le meilleur article et d'autres récompenses. Cette fois, il y a 7 Best Paper Awards (deux inédits), 1 Best Theme Paper Award et 35 Outstanding Paper Awards. La conférence a également décerné 3 Resource Paper Awards (ResourceAward) et Social Impact Award (
 Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 et conférence de lancement de nouveaux produits avec scénario complet, un certain nombre de nouveaux produits à succès ont été lancés ensemble
Aug 08, 2024 am 07:02 AM
Cet après-midi, Hongmeng Zhixing a officiellement accueilli de nouvelles marques et de nouvelles voitures. Le 6 août, Huawei a organisé la conférence de lancement de nouveaux produits Hongmeng Smart Xingxing S9 et Huawei, réunissant la berline phare intelligente panoramique Xiangjie S9, le nouveau M7Pro et Huawei novaFlip, MatePad Pro 12,2 pouces, le nouveau MatePad Air, Huawei Bisheng With de nombreux nouveaux produits intelligents tous scénarios, notamment la série d'imprimantes laser X1, FreeBuds6i, WATCHFIT3 et l'écran intelligent S5Pro, des voyages intelligents, du bureau intelligent aux vêtements intelligents, Huawei continue de construire un écosystème intelligent complet pour offrir aux consommateurs une expérience intelligente du Internet de tout. Hongmeng Zhixing : Autonomisation approfondie pour promouvoir la modernisation de l'industrie automobile intelligente Huawei s'associe à ses partenaires de l'industrie automobile chinoise pour fournir
 L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
L'équipe de Li Feifei a proposé ReKep pour donner aux robots une intelligence spatiale et intégrer GPT-4o
Sep 03, 2024 pm 05:18 PM
Intégration profonde de la vision et de l'apprentissage des robots. Lorsque deux mains de robot travaillent ensemble en douceur pour plier des vêtements, verser du thé et emballer des chaussures, associées au robot humanoïde 1X NEO qui a fait la une des journaux récemment, vous pouvez avoir le sentiment : nous semblons entrer dans l'ère des robots. En fait, ces mouvements soyeux sont le produit d’une technologie robotique avancée + d’une conception de cadre exquise + de grands modèles multimodaux. Nous savons que les robots utiles nécessitent souvent des interactions complexes et exquises avec l’environnement, et que l’environnement peut être représenté comme des contraintes dans les domaines spatial et temporel. Par exemple, si vous souhaitez qu'un robot verse du thé, le robot doit d'abord saisir la poignée de la théière et la maintenir verticalement sans renverser le thé, puis la déplacer doucement jusqu'à ce que l'embouchure de la théière soit alignée avec l'embouchure de la tasse. , puis inclinez la théière selon un certain angle. ce
