

L'éditeur php Strawberry vous présentera aujourd'hui comment utiliser Python pour extraire une ou plusieurs pages d'un PDF et l'enregistrer en tant que nouveau fichier PDF. Cette fonction est souvent utilisée dans le travail réel, notamment lorsqu'il est nécessaire d'organiser des documents PDF, ce qui peut améliorer l'efficacité. Ensuite, apprenons les étapes spécifiques !
edge, Chrome et d'autres navigateurs courants. Faites un clic droit sur le document pdf qui doit être extrait, sélectionnez « Ouvrir avec » et sélectionnez un navigateur. Ici, j'utilise le navigateur Edge ;
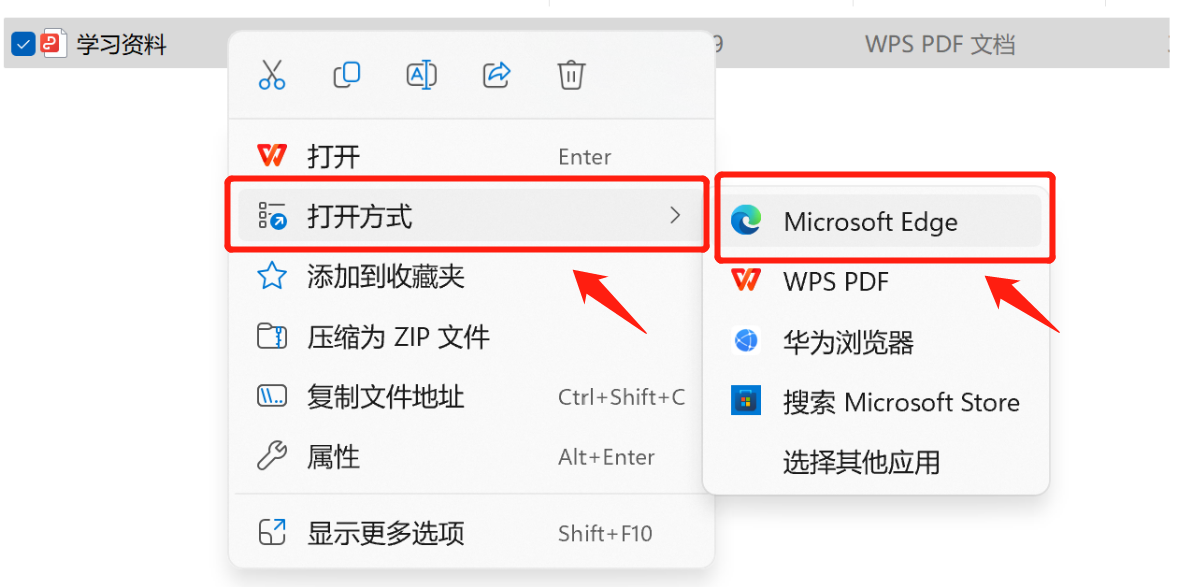
;
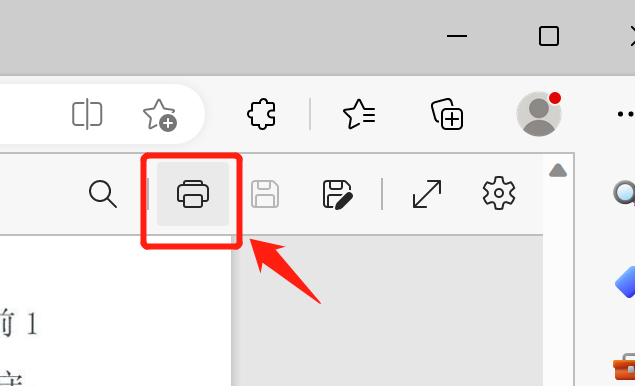
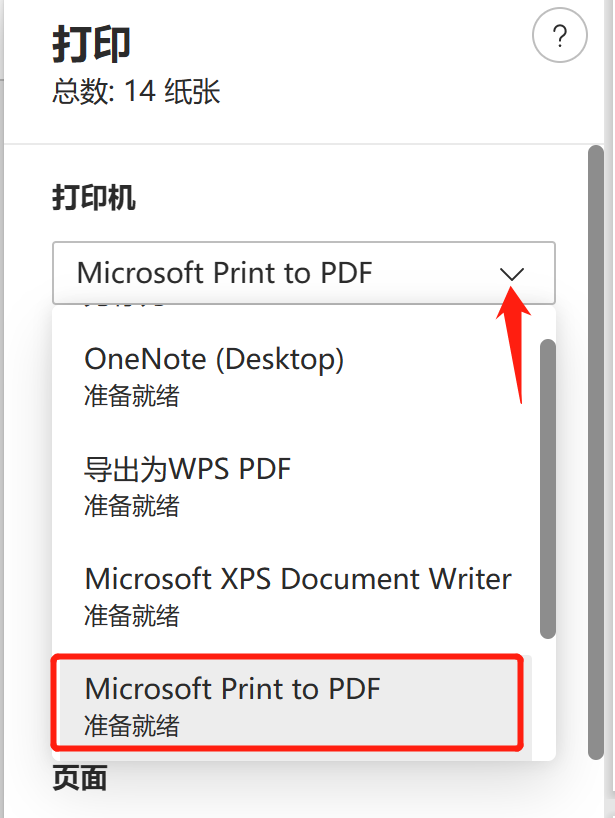 Définissez la « page » d'impression sur la page qui doit être extraite, puis cliquez sur Enregistrer pour obtenir une page séparée.
Définissez la « page » d'impression sur la page qui doit être extraite, puis cliquez sur Enregistrer pour obtenir une page séparée.
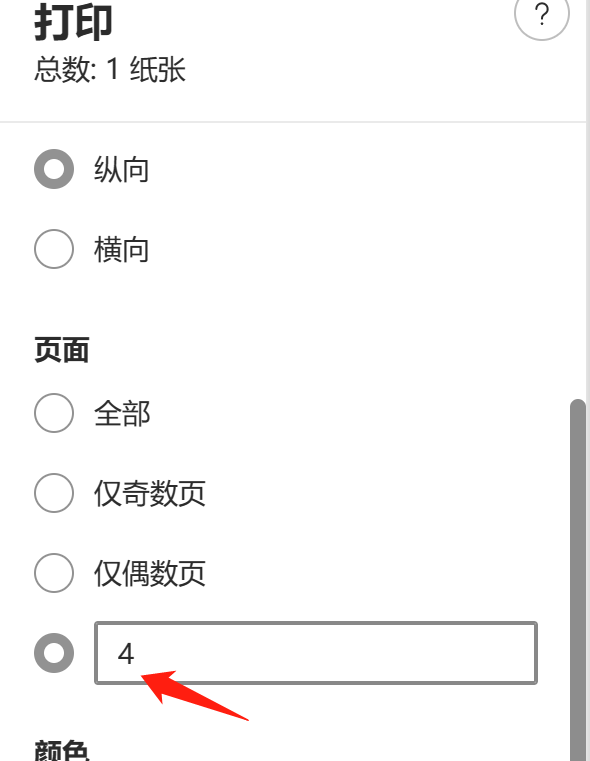
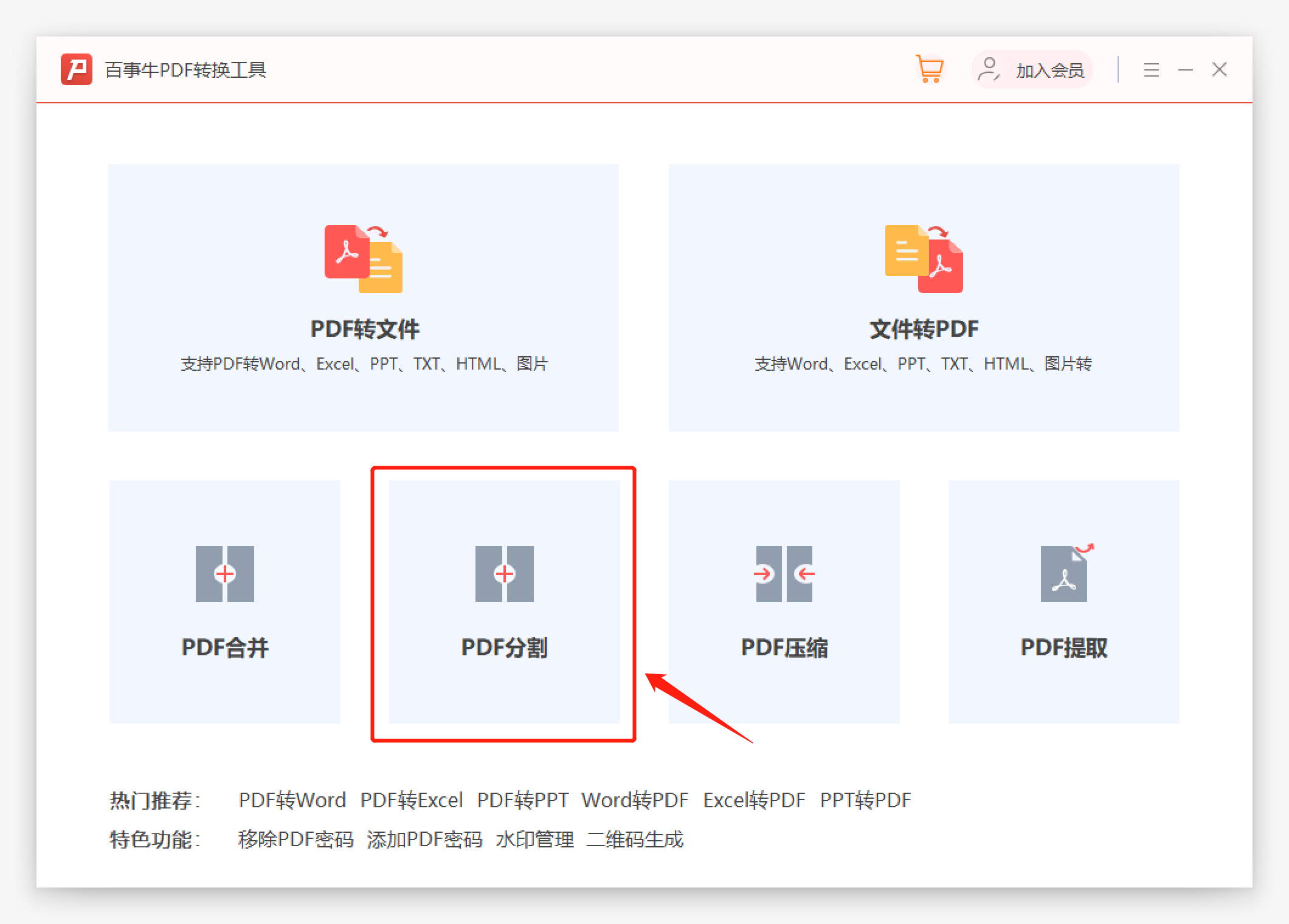 Dans l'interface de fractionnement PDF de Pepsi Niu PDF Conversion Tool, ajoutez le document PDF qui doit être extrait. Vous pouvez choisir de « diviser par numéro de page » ou « diviser à un point fixe » selon vos besoins ; diviser chaque page Diviser un nouveau document PDF à un moment précis : diviser la page avec le numéro de page spécifié en un nouveau document PDF
Dans l'interface de fractionnement PDF de Pepsi Niu PDF Conversion Tool, ajoutez le document PDF qui doit être extrait. Vous pouvez choisir de « diviser par numéro de page » ou « diviser à un point fixe » selon vos besoins ; diviser chaque page Diviser un nouveau document PDF à un moment précis : diviser la page avec le numéro de page spécifié en un nouveau document PDF
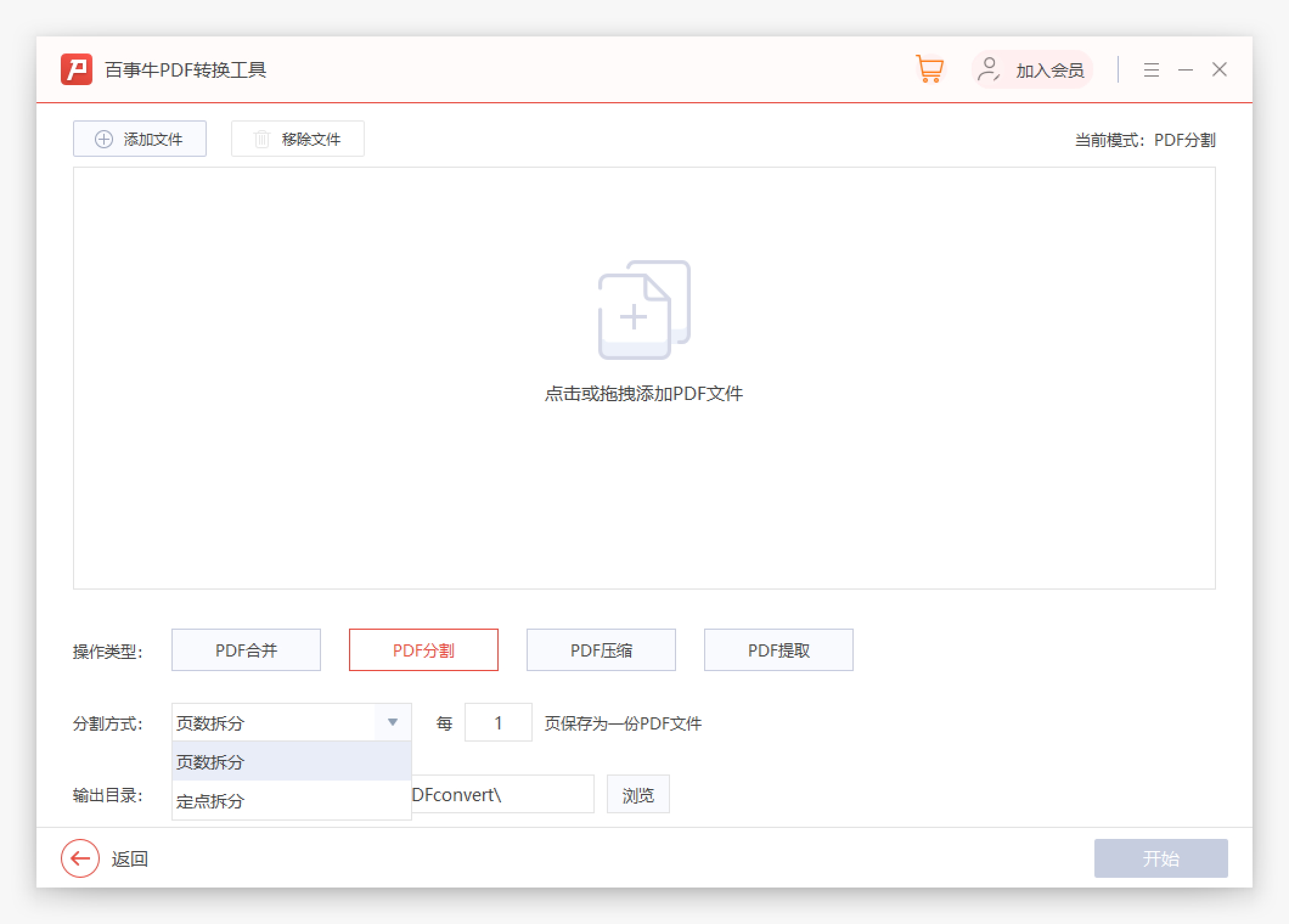 Cliquez sur "Démarrer" pour obtenir rapidement le nouveau document PDF divisé.
Cliquez sur "Démarrer" pour obtenir rapidement le nouveau document PDF divisé.
Adresse de téléchargement officielle de l'outil de conversion PDF Pepsi Niu : https://dl.passneo.cn/down/down?path=passneo_pdf_converter_setup.exe
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



