
 Périphériques technologiques
IA
L'effet est explosif ! Lancement du premier modèle de génération vidéo d'OpenAI, fluide et haute définition en 1 minute, internautes : toute l'industrie est RIP
Périphériques technologiques
IA
L'effet est explosif ! Lancement du premier modèle de génération vidéo d'OpenAI, fluide et haute définition en 1 minute, internautes : toute l'industrie est RIP
L'effet est explosif ! Lancement du premier modèle de génération vidéo d'OpenAI, fluide et haute définition en 1 minute, internautes : toute l'industrie est RIP

Tout à l'heure, Ultraman a publié le premier modèle de génération vidéo d'OpenAI Sora.
Hérite parfaitement de la qualité d'image et des capacités de suivi de commandes du DALL·E 3, et peut générer des vidéos haute définition d'une durée maximale d'une minute.
La Fête du Printemps de l'Année du Dragon imaginée par AI, avec des drapeaux rouges agités et une foule immense.
De nombreux enfants ont regardé l'équipe de danse du dragon avec curiosité, et certaines personnes ont sorti leur téléphone portable pour enregistrer les différents comportements des gens.

Les rues de Tokyo après la pluie, le sol mouillé RéflexionL'effet d'ombre au néon est comparable à RTX ON.

La vitre du train en marche est parfois bloquée, et le reflet des personnes dans la voiture apparaît brièvement, ce qui est très étonnant.

Vous pouvez également regarder une bande-annonce de film avec la qualité d'un blockbuster hollywoodien :

Du point de vue très rapproché de l'écran vertical, ce lézard regorge de détails :

Les internautes disent que le jeu est terminé, le travail est trop perdu :

Certaines personnes ont même commencé à "pleurer" toute une industrie :
L'IA comprend le monde physique en mouvement
OpenAI a déclaré que c'est apprendre à l'IA à comprendre et à simuler le monde physique en mouvement , l'objectif est de former des modèles pour aider les gens à résoudre des problèmes qui nécessitent une interaction dans le monde réel
Générer des vidéos basées sur des invites textuelles n'est qu'une étape de l'ensemble du plan.

Actuellement, Sora peut générer des scènes complexes avec plusieurs personnages et mouvements spécifiques Il peut non seulement comprendre les exigences formulées par les utilisateurs dans les invites, mais également comprendre comment ces objets existent dans le monde physique.
Sora peut également créer plusieurs plans dans une seule vidéo et s'appuyer sur sa compréhension approfondie du langage pour interpréter avec précision les mots indicateurs, tout en préservant le caractère et le style visuel.
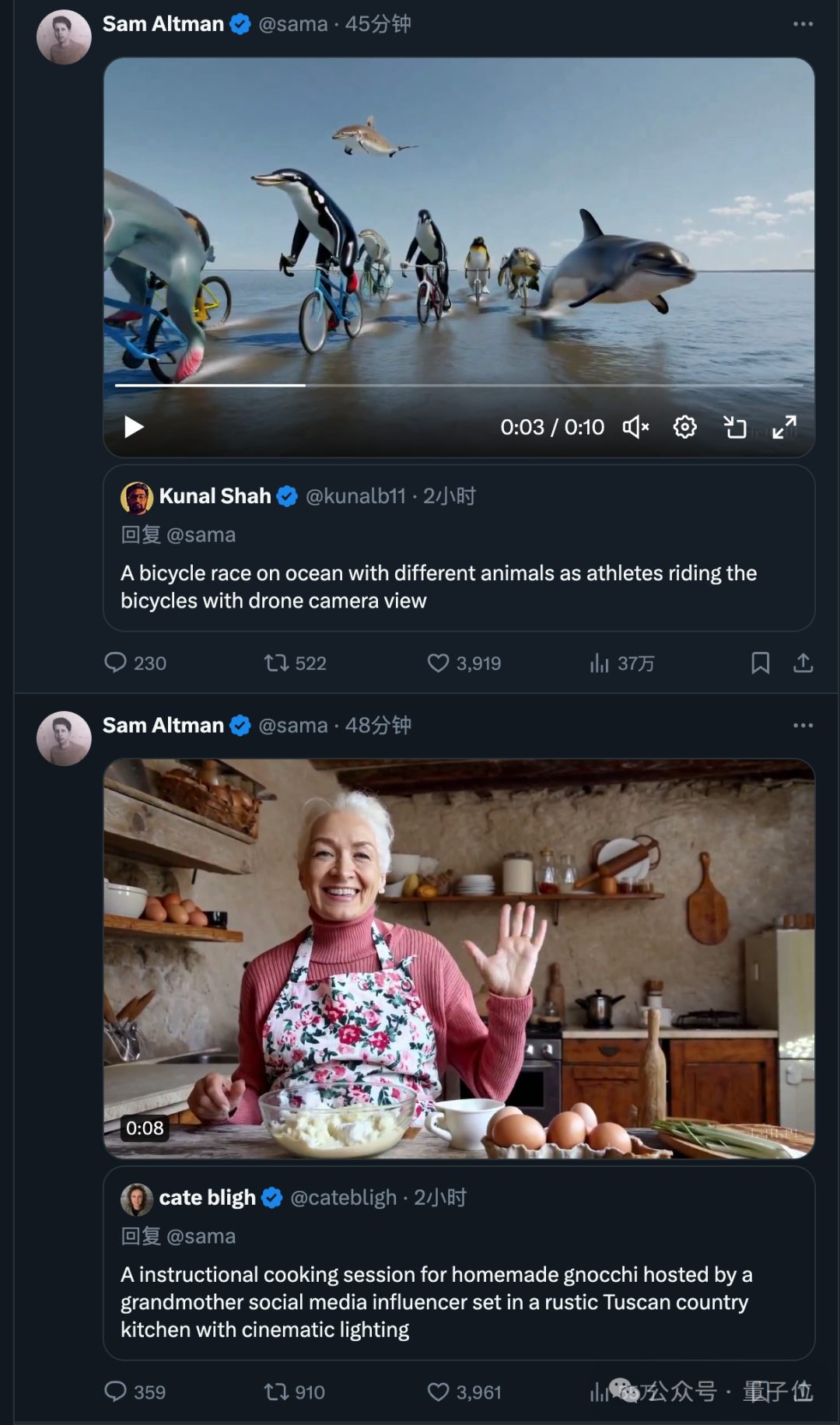
La belle Tokyo enneigée regorge de monde. La caméra se déplace dans les rues animées de la ville, suivant plusieurs personnes profitant d'une belle journée enneigée et faisant leurs achats dans les stands à proximité. Les magnifiques pétales de fleurs de cerisier flottent au vent avec les flocons de neige.
OpenAI n'hésite pas à parler des faiblesses actuelles de Sora, soulignant qu'il peut être difficile de simuler avec précision les principes physiques de scènes complexes, et qu'il peut ne pas être capable de comprendre les relations de cause à effet .
Par exemple, "Cinq louveteaux gris jouaient et se poursuivaient sur une route de gravier isolée." Le nombre de loups changera et certains apparaîtront ou disparaîtront de nulle part.

Le modèle peut également obscurcir les détails spatiaux des signaux , comme confondre gauche et droite, et peut avoir des difficultés à décrire avec précision les événements au fil du temps , comme suivre une trajectoire de caméra spécifique.
Par exemple, dans le mot d'invite « Le ballon de basket passe à travers le panier et explose », le ballon de basket n'est pas correctement bloqué par le panier.

En termes de technologie, OpenAI n'a pas divulgué grand-chose pour le moment. Une brève introduction est la suivante :
Sora est un modèle de diffusion, à partir du bruit, il peut générer la vidéo entière en une seule fois ou prolonger la durée de la vidéo. La
clé est que génère des prédictions pour plusieurs images à la fois, garantissant ainsi. que le sujet de l'image peut être détecté même s'il quitte temporairement le champ de vision. Peut rester inchangé.
Semblable au modèle GPT, Sora utilise l'architecture Transformer, qui est hautement évolutive.
En termes de données, OpenAI représente les vidéos et les images sous forme de correctifs, similaires aux jetons dans GPT.
Avec cette représentation unifiée des données, les modèles peuvent être formés sur une gamme de données visuelles plus large qu'auparavant, couvrant différentes durées, résolutions et rapports d'aspect.
Sora s'appuie sur des recherches antérieures sur les modèles DALL·E et GPT. Il utilise la technologie de reformulation de mots d'invite de DALL·E 3 pour générer des annotations hautement descriptives pour les données d'entraînement visuel, afin de pouvoir suivre plus fidèlement les instructions textuelles de l'utilisateur.
En plus de pouvoir générer des vidéos basées uniquement sur des instructions textuelles, le modèle est également capable de prendre des images statiques existantes et de générer des vidéos à partir d'elles, en animant avec précision le contenu de l'image et en prêtant attention aux petits détails.
Le modèle peut également prendre une vidéo existante et l'étendre ou remplir les images manquantes, voir le document technique pour plus d'informations (à paraître ultérieurement) .
Sora est la base de modèles capables de comprendre et de simuler le monde réel. OpenAI estime que cette fonctionnalité deviendra une étape importante dans la réalisation de l'AGI.
Ultraman prend les commandes en ligne
Un certain nombre d'artistes visuels, de designers et de cinéastes (ainsi que des employés d'OpenAI) ont déjà eu accès à Sora.
Ils ont commencé à publier de nouvelles œuvres en continu et Ultraman a également commencé à prendre des commandes en ligne.
Insérez votre mot d'invite @sama et vous recevrez peut-être une réponse vidéo générée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
