
 Java
javaDidacticiel
Analyse approfondie des fonctions et des avantages du cache de premier niveau mybatis
Java
javaDidacticiel
Analyse approfondie des fonctions et des avantages du cache de premier niveau mybatis
Analyse approfondie des fonctions et des avantages du cache de premier niveau mybatis


Analyse des fonctions et avantages du cache de premier niveau MyBatis
Introduction :
Pendant le processus de développement, les opérations d'accès à la base de données sont inévitables. Afin d'améliorer les performances et de réduire le nombre d'accès à la base de données, MyBatis fournit un mécanisme de cache de premier niveau. Cet article explorera les fonctions et les avantages du cache de premier niveau MyBatis et l'illustrera avec des exemples de code spécifiques.
1. Le rôle du cache de premier niveau
Le cache de premier niveau de MyBatis fait référence au mécanisme de mise en cache dans la même SqlSession. Le cache de premier niveau est activé par défaut et peut améliorer les performances des requêtes. Les fonctions spécifiques sont les suivantes :
- Réduire le nombre d'accès à la base de données : l'utilisation du cache de premier niveau peut éviter les requêtes répétées à la base de données et améliorer les performances du système.
- Amélioration de la vitesse de réponse : étant donné que le cache de premier niveau est situé dans la mémoire, les données sont lues plus rapidement, ce qui peut réduire le temps de transmission sur le réseau, raccourcissant ainsi le temps de réponse.
- Cohérence des données : dans la même SqlSession, lorsque plusieurs opérations de requête opèrent sur le même élément de données, MyBatis obtiendra automatiquement les données du cache pour garantir la cohérence des données.
2. Avantages du cache de premier niveau
Le cache de premier niveau de MyBatis présente les avantages suivants :
- Simple et facile à utiliser : L'utilisation du cache de premier niveau est transparente pour les développeurs, aucune opération manuelle n'est nécessaire. requis et peut être directement effectué des opérations d'accès aux données.
- Activé par défaut : le cache de premier niveau est activé par défaut, c'est-à-dire que les résultats d'exécution des instructions SQL seront mis en cache. De cette manière, les avantages de la mise en cache peuvent être directement obtenus sans configuration supplémentaire.
- Portée limitée : la portée du cache de premier niveau est limitée à la même SqlSession. Lorsque la SqlSession est soumise ou fermée, le cache sera invalidé pour éviter toute incohérence des données.
3. Exemples de code
Ce qui suit utilise des exemples de code spécifiques pour démontrer l'utilisation du cache de premier niveau.
- Créer une interface UserMapper :
public interface UserMapper {
User getUserById(int id);
void updateUser(User user);
}- Activer le cache de premier niveau dans le fichier de configuration MyBatis :
<configuration>
<!-- 其他配置 -->
<settings>
<setting name="cacheEnabled" value="true" />
</settings>
<!-- 其他配置 -->
</configuration>- Exemple d'écriture de code :
public static void main(String[] args) {
try (SqlSessionFactory sessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("mybatis-config.xml"))) {
try (SqlSession sqlSession = sessionFactory.openSession()) {
// 创建 UserMapper 的代理对象
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
// 第一次查询,会从数据库中获取数据,并将数据缓存到一级缓存中
User user1 = userMapper.getUserById(1);
System.out.println(user1);
// 第二次查询,会从一级缓存中获取数据,不会访问数据库
User user2 = userMapper.getUserById(1);
System.out.println(user2);
// 更新用户信息
user1.setName("New Name");
userMapper.updateUser(user1);
// 清除一级缓存
sqlSession.clearCache();
// 第三次查询,会从数据库中获取数据,并将新的数据缓存到一级缓存中
User user3 = userMapper.getUserById(1);
System.out.println(user3);
}
}
}Dans l'exemple ci-dessus, la première requête proviendra de la base de données Récupérez les données et mettez-les en cache dans le cache de premier niveau. Lors de la deuxième requête, les données sont obtenues directement du cache de premier niveau, évitant ainsi d'avoir à accéder à nouveau à la base de données. Une fois les informations utilisateur mises à jour, le cache de premier niveau est vidé et la troisième requête réobtiendra les dernières données de la base de données et les mettra en cache dans le cache de premier niveau.
En résumé, le cache de premier niveau de MyBatis présente des avantages évidents pour améliorer les performances d'accès aux bases de données et réduire les délais de transmission réseau. Les développeurs n'ont besoin que d'une configuration simple pour profiter de la commodité apportée par le cache de premier niveau.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Séparation de la conception de la couche d'accès aux données et de la logique métier dans le framework Java
Jun 01, 2024 pm 03:49 PM
Séparation de la conception de la couche d'accès aux données et de la logique métier dans le framework Java
Jun 01, 2024 pm 03:49 PM
Réponse : La séparation de la couche d'accès aux données (DAL) de la logique métier est cruciale pour les applications Java car elle améliore la réutilisabilité, la maintenabilité et la testabilité. DAL gère l'interaction avec la base de données (lecture, mise à jour, suppression), tandis que la logique métier contient des règles métier et des algorithmes. SpringDataJPA fournit une interface d'accès aux données simplifiée qui peut être étendue en implémentant des méthodes personnalisées ou des méthodes de requête. Les services de logique métier s'appuient sur le DAL mais ne doivent pas interagir directement avec la base de données, cela peut être testé à l'aide d'une base de données fictive ou en mémoire. La séparation du DAL et de la logique métier est essentielle pour concevoir des applications Java maintenables et testables.
 Pourquoi Bittensor est-il le 'Bitcoin' sur la piste AI?
Mar 04, 2025 pm 04:06 PM
Pourquoi Bittensor est-il le 'Bitcoin' sur la piste AI?
Mar 04, 2025 pm 04:06 PM
Titre original: Bittensor = Aibitcoin? Bittensor adopte un modèle de sous-réseau qui permet l'émergence de différentes solutions d'IA et inspire l'innovation à travers les jetons Tao. Bien que le marché de l'IA soit mûr, Bittensor fait face à des risques concurrentiels et peut être soumis à d'autres open source
 A quoi sert net4.0
May 10, 2024 am 01:09 AM
A quoi sert net4.0
May 10, 2024 am 01:09 AM
.NET 4.0 est utilisé pour créer une variété d'applications et offre aux développeurs d'applications des fonctionnalités riches, notamment : programmation orientée objet, flexibilité, architecture puissante, intégration du cloud computing, optimisation des performances, bibliothèques étendues, sécurité, évolutivité, accès aux données et mobile. soutien au développement.
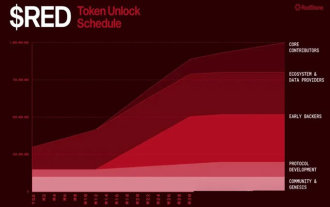 64e numéro LaunchPool Modular Oracle: Red Project Analysis & amp;
Mar 04, 2025 am 08:12 AM
64e numéro LaunchPool Modular Oracle: Red Project Analysis & amp;
Mar 04, 2025 am 08:12 AM
Analyse approfondie du 64e numéro de Launchpool Project Red: Modular Oracle Prospects and Currency Prix Prédictions Cet article analyse profondément le 64e numéro de Launchpool Project Red - un projet oracle multi-chaîne à travers les chaînes EVM et non EVM, et fait des estimations raisonnables des principes fondamentaux du projet et des prix des devises. Le projet Red a été lancé pendant seulement 2 jours, le volume total de LaunchPool étant de 40 000 000 (représentant 4% de l'offre maximale de jetons), et la circulation initiale était de 280 000 000 (représentant 28% de l'offre totale de jetons). Présentation du projet: Redstone est une blockchain modulaire oracle fondée en 2020 et incubée par la chaîne Arweave avec l'équipe d'Estonie. Prend actuellement en charge 70 chaînes
 La relation entre les modèles de conception et le développement piloté par les tests
May 09, 2024 pm 04:03 PM
La relation entre les modèles de conception et le développement piloté par les tests
May 09, 2024 pm 04:03 PM
Le TDD et les modèles de conception améliorent la qualité et la maintenabilité du code. TDD garantit la couverture des tests, améliore la maintenabilité et améliore la qualité du code. Les modèles de conception assistent le TDD grâce à des principes tels que le couplage lâche et la cohésion élevée, garantissant que les tests couvrent tous les aspects du comportement de l'application. Il améliore également la maintenabilité et la qualité du code grâce à la réutilisabilité, à la maintenabilité et à un code plus robuste.
 Comment interroger la somme de deux colonnes de données en même temps dans ThinkPhp6?
Apr 01, 2025 pm 02:54 PM
Comment interroger la somme de deux colonnes de données en même temps dans ThinkPhp6?
Apr 01, 2025 pm 02:54 PM
ThinkPhp6 Database Query: Comment utiliser TP6 pour implémenter les instructions SQL SelectSum (Jin), SUM (CHU) NOSYSDBUIL dans le framework ThinkPhp6, comment utiliser la déclaration SQL Select ...
 Rapport de recherche en binance: Des défis aux opportunités, comment Desci réinvente-t-il la science?
Mar 05, 2025 pm 07:42 PM
Rapport de recherche en binance: Des défis aux opportunités, comment Desci réinvente-t-il la science?
Mar 05, 2025 pm 07:42 PM
La montée en puissance de la science décentralisée (DESCI) a apporté un nouvel espoir à la recherche scientifique. Il utilise la technologie Web3 pour résoudre de nombreux défis dans la recherche scientifique traditionnelle, en particulier le phénomène "Gao of Death" - c'est-à-dire le problème que les résultats de recherche fondamentale sont difficiles à transformer en applications pratiques. L'investissement de Pfizer à Vitadao marque la reconnaissance de la desci par les géants pharmaceutiques traditionnels. Cela nous incite à réfléchir à la façon d'utiliser desci pour remodeler le modèle commercial de la santé numérique. Le rapport de BinanceReSearch "des défis aux opportunités: comment Desci réinvente la science" explore comment Desci résout le problème "de la rattrapage de la mort". Le rapport a souligné que la recherche scientifique traditionnelle est confrontée à un financement insuffisant, à une coopération réduite entre les chercheurs et les cliniciens, et le développement scientifique
 Semaine de la semaine Open Source Deepseek Jour 5: Système de fichiers 'Power Lupt' Fire-Flyer
Mar 12, 2025 pm 02:24 PM
Semaine de la semaine Open Source Deepseek Jour 5: Système de fichiers 'Power Lupt' Fire-Flyer
Mar 12, 2025 pm 02:24 PM
Deepseek Open Source Project ajoute une autre arme! Aujourd'hui, un nouveau système de fichiers parallèles 3FS a été publié pour permettre l'accès aux données Deepseek. 3FS (système de fichiers Fire-Flyer) utilise pleinement la bande passante élevée des réseaux SSD et RDMA modernes pour atteindre un débit de lecture d'agrégation jusqu'à 6,6tib / s dans un cluster de 180 nœuds, et réalise un débit de 3,66tib / min dans le test de banc de Graysort d'un groupe de 25 nœuds. Le débit de pointe de la recherche de KVCache pour un seul nœud client dépasse 40GIB / s. Le système adopte une architecture distincte, prend en charge une forte sémantique de cohérence et peut soutenir efficacement le prétraitement des données de formation, le chargement des ensembles de données, la sauvegarde / rechargement de points de contrôle et l'intégration des vecteurs dans V3 / R1.
