
 tutoriels informatiques
connaissances en informatique
Comme c'est génial Pingora ! Un serveur Web très populaire surpasse Nginx
tutoriels informatiques
connaissances en informatique
Comme c'est génial Pingora ! Un serveur Web très populaire surpasse Nginx
Comme c'est génial Pingora ! Un serveur Web très populaire surpasse Nginx

Je suis ravi de présenter Pingora, notre nouveau proxy HTTP construit sur Rust. Traitant plus de 1 000 milliards de requêtes par jour, améliorant les performances et apportant de nouvelles fonctionnalités aux clients Cloudflare tout en ne nécessitant qu'un tiers des ressources CPU et mémoire de l'infrastructure proxy d'origine.
Alors que Cloudflare continue d'évoluer, nous avons constaté que la puissance de traitement de NGINX ne peut plus répondre à nos besoins. Bien qu’elle ait bien fonctionné au fil des années, nous avons réalisé avec le temps qu’elle avait ses limites pour relever les défis à notre échelle. Par conséquent, nous avons estimé qu'il était nécessaire de créer de nouvelles solutions pour répondre à nos besoins en termes de performances et de fonctionnalités.
Les clients et utilisateurs de Cloudflare utilisent le réseau mondial Cloudflare comme proxy entre les clients et les serveurs HTTP. Nous avons eu de nombreuses discussions, développé de nombreuses technologies et mis en œuvre de nouveaux protocoles tels que les optimisations QUIC et HTTP/2 pour améliorer l'efficacité des navigateurs et autres agents utilisateurs se connectant à notre réseau.
Aujourd'hui, nous allons nous concentrer sur un autre aspect connexe de cette équation : les services proxy, qui sont chargés de gérer le trafic entre notre réseau et les serveurs Internet. Ce service proxy fournit une prise en charge et de la puissance pour nos CDN, Workers fetch, Tunnel, Stream, R2 et de nombreux autres fonctionnalités et produits.
Examinons pourquoi nous avons décidé de mettre à niveau notre service existant et explorons le processus de développement du système Pingora. Ce système est conçu spécifiquement pour les cas d'utilisation et l'évolutivité des clients de Cloudflare.
Pourquoi créer un autre agent
Ces dernières années, nous avons rencontré certaines limitations lors de l'utilisation de NGINX. Pour certaines limitations, nous avons optimisé ou adopté des méthodes pour les contourner. Il existe cependant certaines limitations qui sont plus complexes.
Les limitations architecturales nuisent aux performances
L'architecture de travail (processus) NGINX [4] présente des défauts opérationnels pour notre cas d'utilisation, ce qui nuit à nos performances et à notre efficacité.
Tout d'abord, dans NGINX, chaque demande ne peut être traitée que par un seul travailleur. Cela entraîne un déséquilibre de charge entre tous les cœurs de processeur [5], entraînant des ralentissements [6].
En raison de cet effet de verrouillage du processus de requête, les requêtes qui effectuent des tâches d'E/S gourmandes en CPU ou bloquantes peuvent ralentir d'autres requêtes. Comme le soulignent ces articles de blog, nous avons investi beaucoup de temps dans la résolution de ces problèmes.
Le problème le plus critique pour notre cas d'utilisation est la réutilisation de la connexion, lorsque notre machine établit une connexion TCP avec le serveur d'origine, proxy la requête HTTP. En réutilisant les connexions d'un pool de connexions, vous pouvez ignorer les négociations TCP et TLS requises pour les nouvelles connexions, accélérant ainsi le TTFB (temps jusqu'au premier octet) des requêtes.
Cependant, le pool de connexions NGINX [9] correspond à un seul Worker. Lorsqu'une requête atteint un travailleur, elle ne peut réutiliser que les connexions au sein de ce travailleur. À mesure que nous ajoutons davantage de nœuds de calcul NGINX à l'échelle, la réutilisation de nos connexions se détériore car les connexions sont réparties sur des pools plus isolés dans tous les processus. Cela entraîne un TTFB plus lent et davantage de connexions à maintenir, ce qui consomme nos ressources et celles de nos clients (et de l'argent). 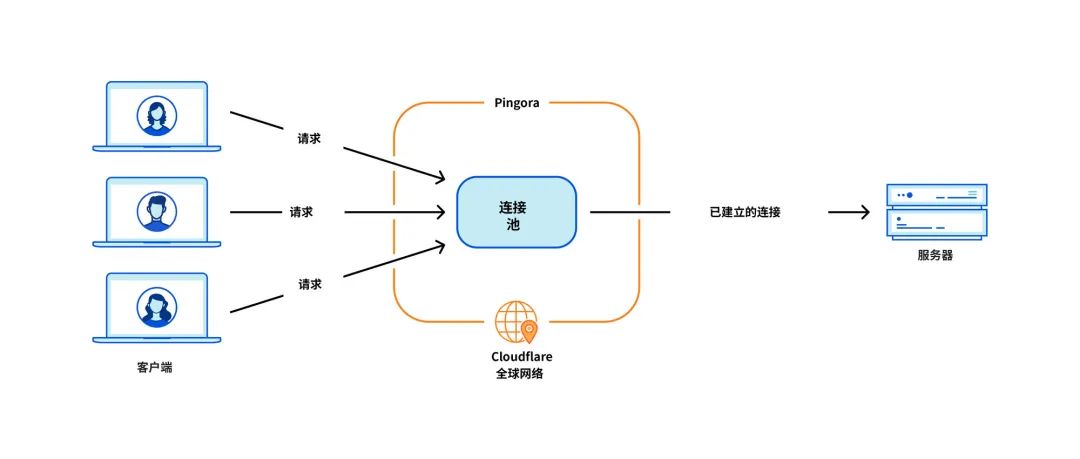
Comme mentionné dans les articles de blog précédents, nous proposons des solutions à certains de ces problèmes. Mais si nous parvenons à résoudre le problème fondamental : le modèle travailleur/processus, nous résoudrons tous ces problèmes naturellement.
Certains types de fonctions sont difficiles à ajouter
NGINX est un excellent serveur Web, équilibreur de charge ou simple passerelle. Mais Cloudflare fait bien plus que cela. Nous avions l'habitude de créer toutes les fonctionnalités dont nous avions besoin autour de NGINX, mais essayer d'éviter trop de divergences par rapport à la base de code en amont de NGINX n'était pas facile.
Par exemple, lors d'une nouvelle tentative d'une requête/d'un échec de requête[10], nous souhaitons parfois envoyer la requête à un serveur d'origine différent avec un ensemble d'en-têtes de requête différent. Mais NGINX ne le permet pas. Dans ce cas, nous devons consacrer du temps et des efforts pour contourner les limitations de NGINX.
En même temps, les langages de programmation que nous sommes obligés d'utiliser ne contribuent pas à atténuer ces difficultés. NGINX est écrit uniquement en C, ce qui, de par sa conception, n'est pas sécurisé en termes de mémoire. L’utilisation d’une base de code tierce comme celle-ci est très sujette aux erreurs. Même pour les ingénieurs expérimentés, il est facile de tomber dans des problèmes de sécurité de la mémoire [11], et nous voulons éviter ces problèmes autant que possible.
Un autre langage que nous utilisons pour compléter C est Lua. C'est moins risqué, mais aussi moins performant. De plus, lorsque nous traitons de code Lua et de logique métier complexes, nous nous retrouvons souvent à court de typage statique [12].
Et la communauté NGINX n'est pas très active, et le développement se fait souvent « à huis clos » [13].
Choisissez de construire le nôtre
Au cours des dernières années, alors que notre base de clients et notre ensemble de fonctionnalités ont continué de croître, nous avons continué à évaluer trois options :
Au cours des dernières années, nous avons évalué ces options chaque trimestre. Il n’existe pas de formule évidente pour décider quelle option est la meilleure. Au cours de quelques années, nous avons continué à emprunter la voie de la moindre résistance et à améliorer NGINX. Cependant, dans certains cas, le retour sur investissement de la création de votre propre agence peut sembler plus intéressant. Nous avons décidé de créer un agent à partir de zéro et avons commencé à concevoir notre application d'agent de rêve.
Projet Pingora
Décision de conception
Afin de créer un proxy rapide, efficace et sécurisé capable de traiter des millions de requêtes par seconde, nous avons d'abord dû prendre des décisions de conception importantes.
Nous avons choisi Rust[16] comme langage pour le projet car il peut faire ce que C peut faire en protégeant la mémoire sans affecter les performances.
Bien qu'il existe d'excellentes bibliothèques HTTP tierces prêtes à l'emploi, telles que hyper[17], nous avons choisi de créer la nôtre parce que nous voulions maximiser notre flexibilité dans la gestion du trafic HTTP et nous assurer que nous pouvions le faire à notre propre rythme. Innovation.
Chez Cloudflare, nous gérons le trafic sur l'ensemble d'Internet. Nous devons prendre en charge de nombreux cas de trafic HTTP étranges et non conformes aux normes RFC. Il s'agit d'un dilemme courant dans la communauté HTTP et sur le Web, où des choix difficiles doivent être faits entre suivre strictement la spécification HTTP et s'adapter aux nuances de l'écosystème plus large de clients ou de serveurs existants potentiels.
Le code d'état HTTP est défini dans la RFC 9110 comme un nombre entier à trois chiffres [18] et devrait généralement être compris entre 100 et 599. Hyper est l’une de ces implémentations. Cependant, de nombreux serveurs prennent en charge l'utilisation de codes d'état compris entre 599 et 999. Nous avons créé une question [19] pour cette fonctionnalité qui explore les différents aspects du débat. Bien que l’hyper-équipe ait finalement accepté ce changement, elle avait de bonnes raisons de rejeter une telle demande, et ce n’était qu’un des nombreux cas de non-conformité que nous devions prendre en charge.
Pour remplir la position de Cloudflare dans l'écosystème HTTP, nous avons besoin d'une bibliothèque HTTP robuste, tolérante et personnalisable, capable de survivre aux différents environnements à risque d'Internet et de prendre en charge une variété de cas d'utilisation non conformes. La meilleure façon de garantir cela est de mettre en œuvre notre propre architecture.
La prochaine décision de conception concerne notre système de planification de la charge de travail. Nous choisissons le multithreading plutôt que le multitraitement [20] pour partager facilement les ressources, notamment le pooling de connexions. Nous pensons que le vol de travail [21] doit également être mis en œuvre pour éviter certaines catégories de problèmes de performances mentionnés ci-dessus. Le runtime asynchrone de Tokio correspond parfaitement à nos besoins [22].
Enfin, nous voulons que nos projets soient intuitifs et conviviaux pour les développeurs. Ce que nous construisons n'est pas un produit final mais devrait être extensible en tant que plate-forme à mesure que davantage de fonctionnalités sont construites dessus. Nous avons décidé d'implémenter une interface programmable basée sur des événements de « cycle de vie des requêtes » similaire à NGINX/OpenResty[23]. Par exemple, l'étape Request Filter permet aux développeurs d'exécuter du code pour modifier ou refuser les demandes lorsque les en-têtes de demande sont reçus. Avec cette conception, nous pouvons clairement séparer notre logique métier et notre logique proxy commune. Les développeurs travaillant auparavant sur NGINX peuvent facilement passer à Pingora et devenir rapidement plus productifs.
Pingora est plus rapide en production
Avançons rapidement jusqu’à maintenant. Pingora gère presque toutes les requêtes HTTP qui nécessitent une interaction avec le serveur d'origine (telles que les échecs de cache), et nous collectons de nombreuses données de performances au cours du processus.
Tout d’abord, voyons comment Pingora accélère le trafic de nos clients. Le trafic global sur Pingora montre une réduction médiane du TTFB de 5 ms et une réduction du 95e centile de 80 ms. Ce n'est pas parce que nous exécutons le code plus rapidement. Même notre ancien service peut traiter des requêtes de l’ordre de la milliseconde.
Les gains de temps proviennent de notre nouvelle architecture, qui partage les connexions entre tous les threads. Cela signifie une meilleure réutilisation des connexions et moins de temps passé sur les négociations TCP et TLS.
Pour tous les clients, Pingora n'a qu'un tiers de nouvelles connexions par seconde par rapport à l'ancien service. Pour un client majeur, la réutilisation des connexions a augmenté de 87,1 % à 99,92 %, ce qui a divisé par 160 les nouvelles connexions. Pour mettre les choses en perspective, en passant à Pingora, nous avons épargné à nos clients et utilisateurs 434 ans de poignées de main chaque jour.
Plus de fonctionnalités
Possède une interface conviviale pour les développeurs que les ingénieurs connaissent tout en supprimant les limitations précédentes, nous permettant de développer plus de fonctionnalités plus rapidement. Les fonctionnalités de base telles que les nouveaux protocoles servent de base à la façon dont nous offrons davantage à nos clients.
Par exemple, nous avons pu ajouter la prise en charge HTTP/2 en amont à Pingora sans obstacles majeurs. Cela nous permet de mettre prochainement gRPC à la disposition de nos clients[24]. L'ajout de la même fonctionnalité à NGINX nécessiterait plus d'efforts d'ingénierie et pourrait ne pas être possible [25].
Récemment, nous avons annoncé le lancement de Cache Reserve[26], dans lequel Pingora utilise le stockage R2 comme couche de mise en cache. Au fur et à mesure que nous ajoutons davantage de fonctionnalités à Pingora, nous sommes en mesure de proposer de nouveaux produits qui n'étaient pas réalisables auparavant.
Plus efficace
En production, Pingora consomme environ 70 % de CPU en moins et 67 % de mémoire en moins que notre ancien service avec la même charge de trafic. Les économies proviennent de plusieurs facteurs.
Notre code Rust fonctionne plus efficacement [28] que l'ancien code Lua [27] . En plus de cela, il existe également des différences d’efficacité dans leur architecture. Par exemple, dans NGINX/OpenResty, lorsque du code Lua veut accéder à un en-tête HTTP, il doit le lire à partir d'une structure NGINX C, allouer une chaîne Lua, puis la copier dans une chaîne Lua. Ensuite, Lua récupère également ses nouvelles chaînes. À Pingora, il s'agit simplement d'un accès par chaîne directe.
Le modèle multithread rend également le partage de données entre requêtes plus efficace. NGINX dispose également d'une mémoire partagée, mais en raison des limitations d'implémentation, chaque accès à la mémoire partagée doit utiliser un mutex, et seules les chaînes et les nombres peuvent être placés dans la mémoire partagée. Dans Pingora, la plupart des éléments partagés sont directement accessibles via des références partagées derrière des compteurs de références atomiques [29].
Comme mentionné ci-dessus, une autre partie importante des économies de processeur est la réduction des nouvelles connexions. La prise de contact TLS est évidemment plus coûteuse que le simple envoi et la réception de données via une connexion établie.
plus sûr
À notre échelle, publier des fonctionnalités rapidement et en toute sécurité est difficile. Il est difficile de prédire tous les cas extrêmes pouvant survenir dans un environnement distribué traitant des millions de requêtes par seconde. Les tests de fuzz et l'analyse statique ne peuvent pas atténuer beaucoup de choses. La sémantique sécurisée en mémoire de Rust nous protège des comportements indéfinis et nous donne l'assurance que nos services fonctionneront correctement.
Grâce à ces garanties, nous pouvons nous concentrer davantage sur la manière dont les modifications apportées à notre service interagiront avec d'autres services ou sources de clients. Nous avons pu développer des fonctionnalités à une cadence plus élevée sans être confrontés à des problèmes de sécurité de la mémoire et à des plantages difficiles à diagnostiquer.
Lorsqu’un accident se produit, les ingénieurs doivent prendre le temps de diagnostiquer comment il s’est produit et quelle en est la cause. Depuis la création de Pingora, nous avons traité des centaines de milliards de requêtes et n'avons pas encore planté à cause de notre code de service.
En fait, les crashs de Pingora sont si rares que lorsque nous en rencontrons un, nous trouvons généralement des problèmes sans rapport. Récemment, nous avons découvert un bug du noyau [30] peu de temps après que notre service ait commencé à planter. Nous avons également découvert des problèmes matériels sur certaines machines qui, dans le passé, excluaient les rares erreurs de mémoire provoquées par notre logiciel, même après qu'un débogage important était presque impossible.
Résumé
En résumé, nous avons construit un agent interne plus rapide, plus efficace et plus polyvalent qui sert de plateforme pour nos produits actuels et futurs.
Nous aborderons plus tard plus de détails techniques sur les problèmes et les optimisations d'applications auxquels nous avons été confrontés, ainsi que les leçons que nous avons tirées de la création de Pingora et de son déploiement pour prendre en charge des parties importantes d'Internet. Nous présenterons également nos initiatives open source.
Cet article est reproduit du blog CloudFlare, écrit par Yuchen Wu et Andrew Hauck
Lien : https://blog.cloudflare.com/zh-cn/how-we-built-pingora-the-proxy-that-connects-cloudflare-to-the-internet-zh-cn/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment autoriser l'accès au réseau externe au serveur Tomcat
Apr 21, 2024 am 07:22 AM
Comment autoriser l'accès au réseau externe au serveur Tomcat
Apr 21, 2024 am 07:22 AM
Pour permettre au serveur Tomcat d'accéder au réseau externe, vous devez : modifier le fichier de configuration Tomcat pour autoriser les connexions externes. Ajoutez une règle de pare-feu pour autoriser l'accès au port du serveur Tomcat. Créez un enregistrement DNS pointant le nom de domaine vers l'adresse IP publique du serveur Tomcat. Facultatif : utilisez un proxy inverse pour améliorer la sécurité et les performances. Facultatif : configurez HTTPS pour une sécurité accrue.
 Comment exécuter thinkphp
Apr 09, 2024 pm 05:39 PM
Comment exécuter thinkphp
Apr 09, 2024 pm 05:39 PM
Étapes pour exécuter ThinkPHP Framework localement : Téléchargez et décompressez ThinkPHP Framework dans un répertoire local. Créez un hôte virtuel (facultatif) pointant vers le répertoire racine ThinkPHP. Configurez les paramètres de connexion à la base de données. Démarrez le serveur Web. Initialisez l'application ThinkPHP. Accédez à l'URL de l'application ThinkPHP et exécutez-la.
 Bienvenue sur nginx !Comment le résoudre ?
Apr 17, 2024 am 05:12 AM
Bienvenue sur nginx !Comment le résoudre ?
Apr 17, 2024 am 05:12 AM
Pour résoudre l'erreur "Bienvenue sur nginx!", vous devez vérifier la configuration de l'hôte virtuel, activer l'hôte virtuel, recharger Nginx, si le fichier de configuration de l'hôte virtuel est introuvable, créer une page par défaut et recharger Nginx, puis le message d'erreur. disparaîtra et le site Web sera affiché normalement.
 Comment communiquer entre les conteneurs Docker
Apr 07, 2024 pm 06:24 PM
Comment communiquer entre les conteneurs Docker
Apr 07, 2024 pm 06:24 PM
Il existe cinq méthodes de communication de conteneur dans l'environnement Docker : réseau partagé, Docker Compose, proxy réseau, volume partagé et file d'attente de messages. En fonction de vos besoins d'isolation et de sécurité, choisissez la méthode de communication la plus appropriée, par exemple en utilisant Docker Compose pour simplifier les connexions ou en utilisant un proxy réseau pour augmenter l'isolation.
 Comment générer une URL à partir d'un fichier HTML
Apr 21, 2024 pm 12:57 PM
Comment générer une URL à partir d'un fichier HTML
Apr 21, 2024 pm 12:57 PM
La conversion d'un fichier HTML en URL nécessite un serveur Web, ce qui implique les étapes suivantes : Obtenir un serveur Web. Configurez un serveur Web. Téléchargez le fichier HTML. Créez un nom de domaine. Acheminez la demande.
 Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Comment déployer le projet nodejs sur le serveur
Apr 21, 2024 am 04:40 AM
Étapes de déploiement de serveur pour un projet Node.js : Préparez l'environnement de déploiement : obtenez l'accès au serveur, installez Node.js, configurez un référentiel Git. Créez l'application : utilisez npm run build pour générer du code et des dépendances déployables. Téléchargez le code sur le serveur : via Git ou File Transfer Protocol. Installer les dépendances : connectez-vous en SSH au serveur et installez les dépendances de l'application à l'aide de npm install. Démarrez l'application : utilisez une commande telle que node index.js pour démarrer l'application ou utilisez un gestionnaire de processus tel que pm2. Configurer un proxy inverse (facultatif) : utilisez un proxy inverse tel que Nginx ou Apache pour acheminer le trafic vers votre application
 Quelles sont les instructions les plus courantes dans un fichier docker
Apr 07, 2024 pm 07:21 PM
Quelles sont les instructions les plus courantes dans un fichier docker
Apr 07, 2024 pm 07:21 PM
Les instructions les plus couramment utilisées dans Dockerfile sont : FROM : créer une nouvelle image ou dériver une nouvelle image RUN : exécuter des commandes (installer le logiciel, configurer le système) COPY : copier des fichiers locaux dans l'image ADD : similaire à COPY, il peut automatiquement décompresser tar ou obtenir des fichiers URL CMD : Spécifiez la commande au démarrage du conteneur EXPOSE : Déclarez le port d'écoute du conteneur (mais pas public) ENV : Définissez la variable d'environnement VOLUME : Montez le répertoire hôte ou le volume anonyme WORKDIR : Définissez le répertoire de travail dans le conteneur ENTRYPOINT : spécifiez ce qu'il faut exécuter lorsque le conteneur démarre. Fichier exécutable (similaire à CMD, mais ne peut pas être écrasé)
 Nodejs est-il accessible de l'extérieur ?
Apr 21, 2024 am 04:43 AM
Nodejs est-il accessible de l'extérieur ?
Apr 21, 2024 am 04:43 AM
Oui, Node.js est accessible de l’extérieur. Vous pouvez utiliser les méthodes suivantes : Utilisez Cloud Functions pour déployer la fonction et la rendre accessible au public. Utilisez le framework Express pour créer des itinéraires et définir des points de terminaison. Utilisez Nginx pour inverser les requêtes de proxy vers les applications Node.js. Utilisez des conteneurs Docker pour exécuter des applications Node.js et les exposer via le mappage de ports.
