
 développement back-end
C++
Comment implémenter l'entrée et la sortie chinoises dans un programme en langage C ?
développement back-end
C++
Comment implémenter l'entrée et la sortie chinoises dans un programme en langage C ?
Comment implémenter l'entrée et la sortie chinoises dans un programme en langage C ?


Comment gérer les entrées et sorties chinoises dans un logiciel de programmation en langage C ?
Avec le développement de la mondialisation, la gamme d'applications du chinois devient de plus en plus étendue. Dans la programmation en langage C, si vous devez traiter les entrées et sorties chinoises, vous devez prendre en compte l'encodage des caractères chinois et les méthodes de traitement associées. Cet article présentera quelques méthodes courantes de traitement des entrées et sorties du chinois dans un logiciel de programmation en langage C.
Tout d’abord, nous devons comprendre comment les caractères chinois sont codés. Sur les ordinateurs, la méthode de codage des caractères chinois la plus couramment utilisée est le codage Unicode. Le codage Unicode peut représenter presque tous les caractères du monde, y compris les caractères chinois. Le codage Unicode utilise plusieurs octets pour représenter un caractère, et les méthodes de codage spécifiques incluent UTF-8, UTF-16 et UTF-32.
Dans la programmation en langage C, afin de traiter les caractères chinois, nous devons nous assurer que l'environnement de compilation prend en charge le codage Unicode. La plupart des compilateurs et systèmes d'exploitation modernes prennent déjà en charge le codage Unicode. Une fois que nous nous assurons du support de l'environnement de compilation, nous pouvons utiliser le type de caractères larges (wchar_t) pour traiter les caractères chinois.
Pour la saisie chinoise, nous pouvons utiliser la fonction wscanf pour lire la saisie de caractères larges. La fonction wscanf peut utiliser une chaîne de format pour spécifier le format d'entrée comme les autres fonctions d'entrée. Par exemple, le code suivant montre comment utiliser la fonction wscanf pour lire les entrées et sorties chinoises :
#include <stdio.h>
#include <wchar.h>
int main() {
wchar_t name[50];
wprintf(L"请输入您的姓名:");
wscanf(L"%ls", name);
wprintf(L"您好,%ls!
", name);
return 0;
}Dans le code ci-dessus, nous utilisons %ls comme chaîne de format de wscanf, ce qui signifie lire une chaîne de caractères large. De même, nous pouvons également utiliser la fonction wprintf pour générer des caractères chinois. Il convient de noter que lors de la sortie de caractères chinois, vous devez ajouter le préfixe L devant la chaîne.
En plus d'utiliser des types de caractères larges pour traiter les entrées et sorties chinoises, nous pouvons également utiliser d'autres bibliothèques pour traiter les caractères chinois. Par exemple, la bibliothèque open source ICU (International Components for Unicode) fournit de nombreuses fonctions pour traiter les caractères Unicode et peut être utilisée comme bibliothèque d'outils pour traiter les entrées et sorties chinoises.
Lors de l'utilisation de la bibliothèque ICU, nous devons utiliser le fichier d'en-tête icu et un lien vers la bibliothèque ICU. Voici un exemple de code qui utilise la bibliothèque ICU pour traiter les entrées et sorties chinoises :
#include <stdio.h>
#include <unicode/ustdio.h>
#include <unicode/ustring.h>
int main() {
UChar name[50];
u_printf(u"请输入您的姓名:");
u_scanf(u"%ls", name);
u_printf(u"您好,%ls!
", name);
return 0;
}Dans le code ci-dessus, nous utilisons le type UChar pour représenter les caractères Unicode et utilisons les fonctions u_printf et u_scanf pour les entrées et sorties chinoises.
Il convient de noter que lors du traitement des entrées et sorties chinoises, que vous utilisiez des types de caractères larges ou d'autres bibliothèques, vous devez garantir la cohérence de la méthode d'encodage. Par exemple, si l'entrée utilise le codage UTF-8, elle doit être convertie vers le codage correspondant lors du traitement des caractères chinois.
En bref, lors du traitement des entrées et sorties chinoises dans la programmation en langage C, vous devez prendre en compte l'encodage des caractères chinois et les méthodes de traitement correspondantes. L’utilisation de types de caractères larges ou d’autres bibliothèques pour gérer les entrées et sorties chinoises est une approche courante. J'espère que cet article sera utile à la méthode de traitement des entrées et sorties du chinois dans un logiciel de programmation en langage C.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Recommander cinq logiciels de programmation pratiques en langage C
Feb 18, 2024 pm 09:51 PM
Recommander cinq logiciels de programmation pratiques en langage C
Feb 18, 2024 pm 09:51 PM
En tant que langage de programmation largement utilisé, le langage C a toujours été apprécié des développeurs. Lors de la programmation en langage C, il est très important de choisir un logiciel de programmation approprié. Cet article fera le point sur cinq outils pratiques de programmation en langage C pour vous aider à améliorer l'efficacité de la programmation et la qualité du développement. VisualStudioCode (VSCode) VisualStudioCode est un éditeur de code multiplateforme léger doté d'un puissant écosystème de plug-ins qui prend en charge plusieurs langages et frameworks. CONTRE
 Logiciel essentiel pour la programmation en langage C : cinq bons assistants recommandés pour les débutants
Feb 20, 2024 pm 08:18 PM
Logiciel essentiel pour la programmation en langage C : cinq bons assistants recommandés pour les débutants
Feb 20, 2024 pm 08:18 PM
Le langage C est un langage de programmation basique et important. Pour les débutants, il est très important de choisir un logiciel de programmation approprié. Il existe de nombreuses options de logiciels de programmation C sur le marché, mais pour les débutants, il peut être un peu déroutant de choisir celui qui vous convient le mieux. Cet article recommandera cinq logiciels de programmation en langage C aux débutants pour les aider à démarrer rapidement et à améliorer leurs compétences en programmation. Dev-C++Dev-C++ est un environnement de développement intégré (IDE) gratuit et open source, particulièrement adapté aux débutants. Il est simple et facile à utiliser, intégrant un éditeur,
 Comment implémenter l'entrée et la sortie chinoises dans un programme en langage C ?
Feb 19, 2024 pm 08:22 PM
Comment implémenter l'entrée et la sortie chinoises dans un programme en langage C ?
Feb 19, 2024 pm 08:22 PM
Comment gérer les entrées et sorties en chinois dans un logiciel de programmation en langage C ? Avec le développement de la mondialisation, le champ d'application du chinois devient de plus en plus étendu. Dans la programmation en langage C, si vous devez traiter les entrées et sorties chinoises, vous devez prendre en compte l'encodage des caractères chinois et les méthodes de traitement associées. Cet article présentera quelques méthodes courantes de traitement des entrées et sorties du chinois dans un logiciel de programmation en langage C. Tout d’abord, nous devons comprendre comment les caractères chinois sont codés. Sur les ordinateurs, la méthode de codage des caractères chinois la plus couramment utilisée est le codage Unicode. Le codage Unicode peut représenter
 Cinq logiciels de programmation pour débuter l'apprentissage du langage C
Feb 19, 2024 pm 04:51 PM
Cinq logiciels de programmation pour débuter l'apprentissage du langage C
Feb 19, 2024 pm 04:51 PM
En tant que langage de programmation largement utilisé, le langage C est l'un des langages de base qui doivent être appris pour ceux qui souhaitent se lancer dans la programmation informatique. Cependant, pour les débutants, l’apprentissage d’un nouveau langage de programmation peut s’avérer quelque peu difficile, notamment en raison du manque d’outils d’apprentissage et de matériel pédagogique pertinents. Dans cet article, je présenterai cinq logiciels de programmation pour aider les débutants à démarrer avec le langage C et vous aider à démarrer rapidement. Le premier logiciel de programmation était Code :: Blocks. Code::Blocks est un environnement de développement intégré (IDE) gratuit et open source pour
 Analyser les problèmes courants de format d'entrée de la fonction scanf du langage C
Feb 19, 2024 am 09:30 AM
Analyser les problèmes courants de format d'entrée de la fonction scanf du langage C
Feb 19, 2024 am 09:30 AM
Analyse des questions fréquemment posées sur le format d'entrée Scanf en langage C Dans le processus de programmation en langage C, la fonction d'entrée est très importante pour le fonctionnement du programme. Nous utilisons souvent la fonction scanf pour recevoir les entrées de l'utilisateur. Cependant, en raison de la diversité et de la complexité des entrées, certains problèmes courants peuvent survenir lors de l'utilisation de la fonction scanf. Cet article analysera certains problèmes courants de format d'entrée scanf et fournira des exemples de code spécifiques. Les caractères saisis ne correspondent pas au format. Lors de l'utilisation de la fonction scanf, nous devons spécifier le format d'entrée. Par exemple, "%d
 Comment implémenter l'encodage et le décodage des caractères chinois dans la programmation en langage C ?
Feb 19, 2024 pm 02:15 PM
Comment implémenter l'encodage et le décodage des caractères chinois dans la programmation en langage C ?
Feb 19, 2024 pm 02:15 PM
Dans la programmation informatique moderne, le langage C est l’un des langages de programmation les plus couramment utilisés. Bien que le langage C lui-même ne prenne pas directement en charge l'encodage et le décodage chinois, nous pouvons utiliser certaines technologies et bibliothèques pour réaliser cette fonction. Cet article présentera comment implémenter l'encodage et le décodage chinois dans un logiciel de programmation en langage C. Premièrement, pour mettre en œuvre l’encodage et le décodage chinois, nous devons comprendre les concepts de base de l’encodage chinois. Actuellement, le système de codage chinois le plus couramment utilisé est le codage Unicode. Le codage Unicode attribue une valeur numérique unique à chaque caractère afin que lors du calcul
 Comment trier les caractères chinois dans un environnement en langage C ?
Feb 18, 2024 pm 02:10 PM
Comment trier les caractères chinois dans un environnement en langage C ?
Feb 18, 2024 pm 02:10 PM
Comment implémenter la fonction de tri des caractères chinois dans un logiciel de programmation en langage C ? Dans la société moderne, la fonction de tri des caractères chinois est l’une des fonctions essentielles de nombreux logiciels. Que ce soit dans les logiciels de traitement de texte, les moteurs de recherche ou les systèmes de bases de données, les caractères chinois doivent être triés pour mieux afficher et traiter les données textuelles chinoises. En programmation en langage C, comment implémenter la fonction de tri des caractères chinois ? Une méthode est brièvement présentée ci-dessous. Tout d'abord, afin d'implémenter la fonction de tri des caractères chinois en langage C, nous devons utiliser la fonction de comparaison de chaînes. Couru
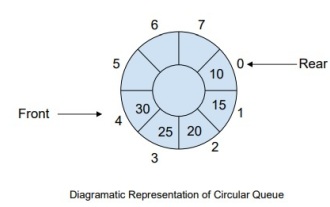 Comment gérer une file d'attente circulaire complète d'événements en C++ ?
Sep 04, 2023 pm 06:41 PM
Comment gérer une file d'attente circulaire complète d'événements en C++ ?
Sep 04, 2023 pm 06:41 PM
Introduction CircularQueue est une amélioration des files d'attente linéaires, qui a été introduite pour résoudre le problème du gaspillage de mémoire dans les files d'attente linéaires. Les files d'attente circulaires utilisent le principe FIFO pour y insérer et supprimer des éléments. Dans ce tutoriel, nous aborderons le fonctionnement d'une file d'attente circulaire et comment la gérer. Qu'est-ce qu'une file d'attente circulaire ? La file d'attente circulaire est un autre type de file d'attente dans la structure de données où le front-end et le back-end sont connectés l'un à l'autre. Il est également connu sous le nom de tampon circulaire. Il fonctionne de la même manière qu’une file d’attente linéaire, alors pourquoi devons-nous introduire une nouvelle file d’attente dans la structure des données ? Lors de l'utilisation d'une file d'attente linéaire, lorsque la file d'attente atteint sa limite maximale, il peut y avoir de l'espace mémoire avant le pointeur de queue. Cela entraîne une perte de mémoire et un bon algorithme devrait être capable d’utiliser pleinement les ressources. Afin de résoudre le gaspillage de mémoire
