
 Périphériques technologiques
IA
Introduction à cinq méthodes d'échantillonnage dans les tâches de génération de langage naturel et l'implémentation du code Pytorch
Périphériques technologiques
IA
Introduction à cinq méthodes d'échantillonnage dans les tâches de génération de langage naturel et l'implémentation du code Pytorch
Introduction à cinq méthodes d'échantillonnage dans les tâches de génération de langage naturel et l'implémentation du code Pytorch

Dans les tâches de génération de langage naturel, la méthode d'échantillonnage est une technique permettant d'obtenir une sortie de texte à partir d'un modèle génératif. Cet article abordera 5 méthodes courantes et les implémentera à l'aide de PyTorch.
1. Décodage gourmand
Dans le décodage gourmand, le modèle génératif prédit les mots de la séquence de sortie en fonction du temps de la séquence d'entrée, pas à pas. À chaque pas de temps, le modèle calcule la distribution de probabilité conditionnelle de chaque mot, puis sélectionne le mot avec la probabilité conditionnelle la plus élevée comme sortie du pas de temps actuel. Ce mot devient l'entrée du pas de temps suivant et le processus de génération se poursuit jusqu'à ce qu'une condition de fin soit remplie, telle qu'une séquence d'une longueur spécifiée ou un marqueur de fin spécial. La caractéristique du décodage gourmand est qu'à chaque fois, le mot avec la probabilité conditionnelle actuelle la plus élevée est sélectionné comme sortie, sans tenir compte de la solution optimale globale. Cette méthode est simple et efficace, mais peut aboutir à des séquences générées moins précises ou moins diverses. Le décodage gourmand convient à certaines tâches simples de génération de séquences, mais pour les tâches complexes, des stratégies de décodage plus complexes peuvent devoir être utilisées pour améliorer la qualité de la génération.
Bien que cette méthode soit plus rapide en calcul, puisque le décodage glouton se concentre uniquement sur la solution optimale locale, le texte généré peut manquer de diversité ou être inexact, et la solution optimale globale ne peut pas être obtenue.
Bien que le décodage glouton ait ses limites, il est encore largement utilisé dans de nombreuses tâches de génération de séquences, en particulier lorsqu'une exécution rapide est requise ou que la tâche est relativement simple.
def greedy_decoding(input_ids, max_tokens=300): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] next_token = torch.argmax(next_token_logits, dim=-1) if next_token == tokenizer.eos_token_id: break input_ids = torch.cat([input_ids, rearrange(next_token, 'c -> 1 c')], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
2. Beam Search
Beam Search est une extension du décodage glouton, qui surmonte le problème optimal local du décodage glouton en conservant plusieurs séquences candidates à chaque pas de temps.
La recherche par faisceau est une méthode de génération de texte qui conserve les mots candidats avec la probabilité la plus élevée à chaque pas de temps, puis continue à se développer en fonction de ces mots candidats au pas de temps suivant jusqu'à la fin de la génération. Cette méthode peut améliorer la diversité du texte généré en considérant plusieurs chemins de mots candidats.
Dans la recherche de faisceaux, le modèle génère simultanément plusieurs séquences candidates au lieu de sélectionner une seule meilleure séquence. Il prédit les mots possibles au prochain pas de temps sur la base de la séquence partielle actuellement générée et des états cachés, et calcule la distribution de probabilité conditionnelle de chaque mot. Cette méthode de génération de plusieurs séquences candidates en parallèle contribue à améliorer l’efficacité de la recherche, permettant au modèle de trouver plus rapidement la séquence présentant la probabilité globale la plus élevée.
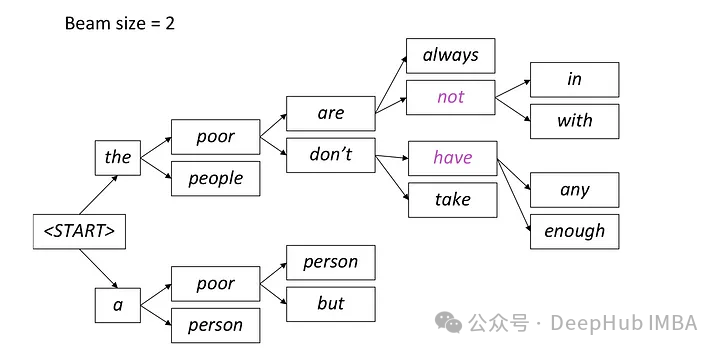
A chaque étape, seuls les deux chemins les plus probables sont conservés, et les chemins restants sont écartés selon le réglage de faisceau = 2. Ce processus se poursuit jusqu'à ce qu'une condition d'arrêt soit remplie, qui peut générer un jeton de fin de séquence ou atteindre la longueur de séquence maximale définie par le modèle. Le résultat final sera la séquence ayant la probabilité globale la plus élevée parmi le dernier ensemble de chemins.
from einops import rearrange import torch.nn.functional as F def beam_search(input_ids, max_tokens=100, beam_size=2): beam_scores = torch.zeros(beam_size).to(device) beam_sequences = input_ids.clone() active_beams = torch.ones(beam_size, dtype=torch.bool) for step in range(max_tokens): outputs = model(beam_sequences) logits = outputs.logits[:, -1, :] probs = F.softmax(logits, dim=-1) top_scores, top_indices = torch.topk(probs.flatten(), k=beam_size, sorted=False) beam_indices = top_indices // probs.shape[-1] token_indices = top_indices % probs.shape[-1] beam_sequences = torch.cat([ beam_sequences[beam_indices], token_indices.unsqueeze(-1)], dim=-1) beam_scores = top_scores active_beams = ~(token_indices == tokenizer.eos_token_id) if not active_beams.any(): print("no active beams") break best_beam = beam_scores.argmax() best_sequence = beam_sequences[best_beam] generated_text = tokenizer.decode(best_sequence) return generated_text3. Échantillonnage de température
L'échantillonnage des paramètres de température (échantillonnage de température) est souvent utilisé dans les modèles génératifs basés sur les probabilités, tels que les modèles de langage. Il contrôle la diversité du texte généré en introduisant un paramètre appelé « Température » pour ajuster la distribution de probabilité de la sortie du modèle.
Dans l'échantillonnage des paramètres de température, lorsque le modèle génère des mots à chaque pas de temps, il calculera la distribution de probabilité conditionnelle des mots. Le modèle divise ensuite la valeur de probabilité de chaque mot dans cette distribution de probabilité conditionnelle par le paramètre de température, normalise le résultat et obtient une nouvelle distribution de probabilité normalisée. Des valeurs de température plus élevées rendent la distribution de probabilité plus fluide, augmentant ainsi la diversité du texte généré. Les mots à faible probabilité ont également une probabilité plus élevée d'être sélectionnés ; tandis qu'une valeur de température plus faible rendra la distribution de probabilité plus concentrée et plus susceptible de sélectionner des mots à forte probabilité, de sorte que le texte généré est plus déterministe. Enfin, le modèle échantillonne aléatoirement selon cette nouvelle distribution de probabilité normalisée et sélectionne les mots générés.
import torch import torch.nn.functional as F def temperature_sampling(logits, temperature=1.0): logits = logits / temperature probabilities = F.softmax(logits, dim=-1) sampled_token = torch.multinomial(probabilities, 1) return sampled_token.item()
4. Top-K Sampling
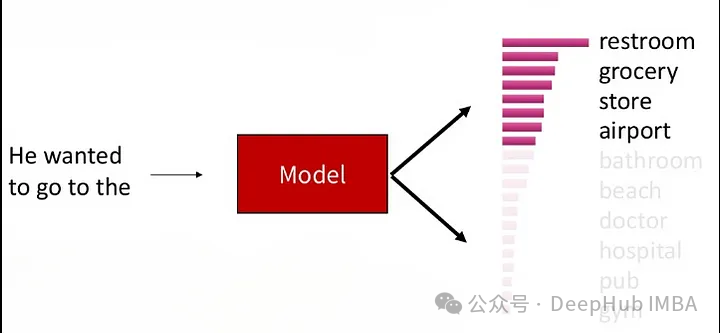
Top-K Sampling (sélectionnez les K premiers mots avec un classement de probabilité conditionnelle à chaque pas de temps, puis échantillonnez au hasard parmi ces K mots. Cette méthode peut maintenir une certaine qualité de génération. peut également augmenter la diversité du texte, et la diversité du texte généré peut être contrôlée en limitant le nombre de mots candidats
Ce processus permet au texte généré de conserver une certaine qualité de génération tout en ayant également une certaine diversité, car. il existe toujours un certain degré de compétition entre les mots candidats. Le paramètre K contrôle le nombre de mots candidats retenus à chaque pas de temps, une valeur K plus petite conduira à un comportement plus gourmand, car seuls quelques mots participent à l'échantillonnage aléatoire, et une valeur K plus grande augmentera la diversité du texte généré, mais augmentera également la charge de calcul
def top_k_sampling(input_ids, max_tokens=100, top_k=50, temperature=1.0):for _ in range(max_tokens): with torch.inference_mode(): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] top_k_logits, top_k_indices = torch.topk(next_token_logits, top_k) top_k_probs = F.softmax(top_k_logits / temperature, dim=-1) next_token_index = torch.multinomial(top_k_probs, num_samples=1) next_token = top_k_indices.gather(-1, next_token_index) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text
 .
.5、Top-P (Nucleus) Sampling:
Nucleus Sampling(核采样),也被称为Top-p Sampling旨在在保持生成文本质量的同时增加多样性。这种方法可以视作是Top-K Sampling的一种变体,它在每个时间步根据模型输出的概率分布选择概率累积超过给定阈值p的词语集合,然后在这个词语集合中进行随机采样。这种方法会动态调整候选词语的数量,以保持一定的文本多样性。

在Nucleus Sampling中,模型在每个时间步生成词语时,首先按照概率从高到低对词汇表中的所有词语进行排序,然后模型计算累积概率,并找到累积概率超过给定阈值p的最小词语子集,这个子集就是所谓的“核”(nucleus)。模型在这个核中进行随机采样,根据词语的概率分布来选择最终输出的词语。这样做可以保证所选词语的总概率超过了阈值p,同时也保持了一定的多样性。
参数p是Nucleus Sampling中的重要参数,它决定了所选词语的概率总和。p的值会被设置在(0,1]之间,表示词语总概率的一个下界。
Nucleus Sampling 能够保持一定的生成质量,因为它在一定程度上考虑了概率分布。通过选择概率总和超过给定阈值p的词语子集进行随机采样,Nucleus Sampling 能够增加生成文本的多样性。
def top_p_sampling(input_ids, max_tokens=100, top_p=0.95): with torch.inference_mode(): for _ in range(max_tokens): outputs = model(input_ids) next_token_logits = outputs.logits[:, -1, :] sorted_logits, sorted_indices = torch.sort(next_token_logits, descending=True) sorted_probabilities = F.softmax(sorted_logits, dim=-1) cumulative_probs = torch.cumsum(sorted_probabilities, dim=-1) sorted_indices_to_remove = cumulative_probs > top_p sorted_indices_to_remove[..., 0] = False indices_to_remove = sorted_indices[sorted_indices_to_remove] next_token_logits.scatter_(-1, indices_to_remove[None, :], float('-inf')) probs = F.softmax(next_token_logits, dim=-1) next_token = torch.multinomial(probs, num_samples=1) input_ids = torch.cat([input_ids, next_token], dim=-1) generated_text = tokenizer.decode(input_ids[0]) return generated_text总结
自然语言生成任务中,采样方法是非常重要的。选择合适的采样方法可以在一定程度上影响生成文本的质量、多样性和效率。上面介绍的几种采样方法各有特点,适用于不同的应用场景和需求。
贪婪解码是一种简单直接的方法,适用于速度要求较高的情况,但可能导致生成文本缺乏多样性。束搜索通过保留多个候选序列来克服贪婪解码的局部最优问题,生成的文本质量更高,但计算开销较大。Top-K 采样和核采样可以控制生成文本的多样性,适用于需要平衡质量和多样性的场景。温度参数采样则可以根据温度参数灵活调节生成文本的多样性,适用于需要平衡多样性和质量的任务。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
