
 Périphériques technologiques
IA
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Périphériques technologiques
IA
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome

Titre original : SIMPL : A Simple and Efficient Multi-agent Motion Prediction Baseline for Autonomous Driving
Lien papier : https://arxiv.org/pdf/2402.02519.pdf
Lien code : https://github.com /HKUST-Aerial-Robotics/SIMPL
Affiliation de l'auteur : Hong Kong University of Science and Technology DJI

Idée de thèse :
Cet article propose une ligne de base de prédiction de mouvement simple et efficace (SIMPL) pour les véhicules autonomes. Contrairement aux méthodes traditionnelles centrées sur les agents (qui ont une grande précision mais nécessitent des calculs répétés) et aux méthodes centrées sur la scène (où la précision et la généralité en souffrent), SIMPL peut fournir une solution complète pour tout le trafic concerné, fournissant des prévisions de mouvement précises en temps réel. Pour améliorer la précision et la vitesse d'inférence, cet article propose un module global de fusion de fonctionnalités compact et efficace qui effectue la transmission de messages dirigés de manière symétrique, permettant au réseau de prédire le mouvement futur de tous les usagers de la route en une seule passe avec anticipation, et de réduire la précision. perte causée par le mouvement du point de vue. En outre, cet article étudie l'utilisation des polynômes de base de Bernstein pour le paramétrage continu de trajectoire dans le décodage de trajectoire, permettant l'évaluation des états et de leurs dérivées d'ordre supérieur à tout instant souhaité, ce qui est précieux pour les tâches de planification en aval. En tant que base de référence solide, SIMPL affiche des performances très compétitives sur les références de prédiction de mouvement Argoverse 1 et 2 par rapport aux autres méthodes de pointe. De plus, sa conception légère et sa faible latence d’inférence rendent SIMPL hautement évolutif et prometteur pour les déploiements aéroportés réels.
Conception du réseau :
La prévision des mouvements des usagers du trafic environnants est cruciale pour les véhicules autonomes, en particulier dans les modules de prise de décision et de planification en aval. Une prédiction précise des intentions et des trajectoires améliorera la sécurité et le confort de conduite.
Pour la prédiction de mouvement basée sur l'apprentissage, l'un des sujets les plus importants est la représentation du contexte. Les premières méthodes représentaient généralement la scène environnante sous la forme d'une image multicanal vue à vol d'oiseau [1]–[4]. En revanche, les recherches récentes adoptent de plus en plus une représentation de scène vectorisée [5]-[13], dans laquelle les emplacements et les géométries sont annotés à l'aide d'ensembles de points ou de polylignes avec des coordonnées géographiques, améliorant ainsi la fidélité et élargissant le champ de réception. Cependant, tant pour les représentations rastérisées que vectorisées, une question clé se pose : comment choisir le référentiel approprié pour tous ces éléments ? Une approche simple consiste à décrire toutes les instances au sein d'un système de coordonnées partagé (centré sur la scène), tel qu'un système centré sur un véhicule autonome, et à utiliser les coordonnées directement comme entités d'entrée. Cela nous permet de faire des prédictions pour plusieurs agents cibles en une seule passe de rétroaction [8, 14]. Cependant, en utilisant les coordonnées globales comme entrée, les prédictions sont généralement faites pour plusieurs agents cibles en une seule passe de rétroaction [8, 14]. Cependant, l'utilisation de coordonnées globales comme entrée (qui varient souvent dans une large mesure) exacerbera considérablement la complexité inhérente de la tâche, entraînant une dégradation des performances du réseau et une adaptabilité limitée à de nouveaux scénarios. Pour améliorer la précision et la robustesse, une solution courante consiste à normaliser le contexte de la scène en fonction de l'état actuel de l'agent cible [5, 7, 10]-[13] (centré sur l'agent). Cela signifie que le processus de normalisation et le codage des fonctionnalités doivent être effectués de manière répétée pour chaque agent cible, ce qui entraîne de meilleures performances au détriment de calculs redondants. Par conséquent, il est nécessaire d’explorer une méthode capable de coder efficacement les caractéristiques de plusieurs objets tout en conservant la robustesse aux changements de perspective.
Pour les modules en aval de prédiction de mouvement, tels que la prise de décision et la planification de mouvements, non seulement la position future doit être prise en compte, mais également le cap, la vitesse et d'autres dérivés d'ordre élevé doivent être pris en compte. Par exemple, les caps prévus des véhicules environnants jouent un rôle clé dans la détermination de l'occupation spatio-temporelle future, ce qui est un facteur clé pour garantir une planification de mouvement sûre et robuste [15, 16]. De plus, prédire indépendamment des quantités d’ordre élevé sans adhérer aux contraintes physiques peut conduire à des résultats de prédiction incohérents [17, 18]. Par exemple, même si la vitesse est nulle, elle peut produire un déplacement de position qui perturbe le module de planification.
Cet article présente une méthode appelée SIMPL (Simple and Efficient Motion Prediction Baseline) pour résoudre le problème clé de la prédiction de trajectoire multi-agents dans les systèmes de conduite autonome. La méthode adopte d'abord une représentation de scène centrée sur l'instance, puis introduit la technologie de transformateur de fusion symétrique (SFT), capable de prédire efficacement les trajectoires de tous les agents en une seule passe à action directe tout en conservant la précision et la robustesse de l'invariance de la perspective. Comparée à d’autres méthodes basées sur la fusion symétrique de contextes, SFT est plus simple, plus légère et plus facile à mettre en œuvre, ce qui la rend adaptée au déploiement dans les environnements automobiles.
Deuxièmement, cet article présente une nouvelle méthode de paramétrage pour les trajectoires prédites basée sur le polynôme de base de Bernstein (également connu sous le nom de courbe de Bézier). Cette représentation continue garantit la fluidité et permet une évaluation facile de l'état précis et de ses dérivées d'ordre supérieur à tout moment donné. L'étude empirique de cet article montre qu'apprendre à prédire les points de contrôle des courbes de Bézier est plus efficace et numériquement plus stable que l'estimation des coefficients des polynômes à base monôme.
Enfin, les composants proposés sont bien intégrés dans un modèle simple et efficace. Cet article évalue la méthode proposée sur deux ensembles de données de prédiction de mouvement à grande échelle [22, 23], et les résultats expérimentaux montrent que SIMPL est très compétitif par rapport aux autres méthodes de pointe malgré sa conception simplifiée. Plus important encore, SIMPL permet une prédiction efficace de trajectoire multi-agents avec moins de paramètres à apprendre et une latence d'inférence plus faible sans sacrifier les performances de quantification, ce qui est prometteur pour un déploiement aéroporté réel. Cet article souligne également que, en tant que base de référence solide, SIMPL présente une excellente évolutivité. L'architecture simple facilite l'intégration directe avec les dernières avancées en matière de prédiction de mouvement, offrant ainsi la possibilité d'améliorer encore les performances globales.
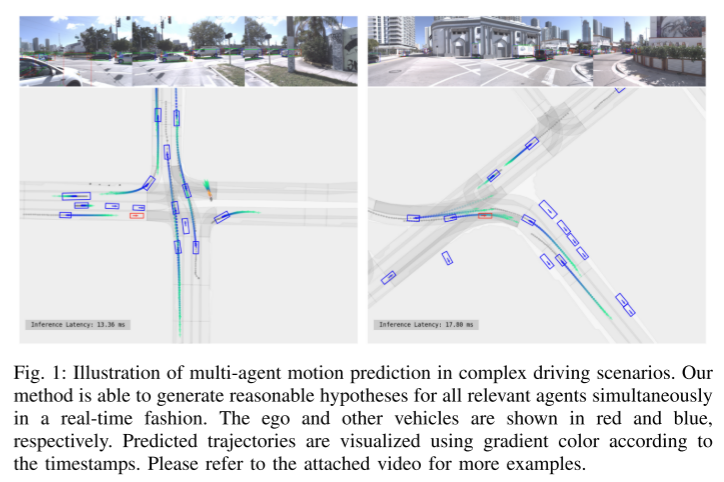
Figure 1 : Illustration de la prédiction de mouvement multi-agents dans des scénarios de conduite complexes. Notre approche est capable de générer simultanément et en temps réel des hypothèses raisonnables pour tous les agents concernés. Votre propre véhicule et les autres véhicules sont représentés respectivement en rouge et en bleu. Utilisez des couleurs dégradées pour visualiser les trajectoires prévues en fonction des horodatages. Veuillez vous référer à la vidéo ci-jointe pour plus d'exemples.
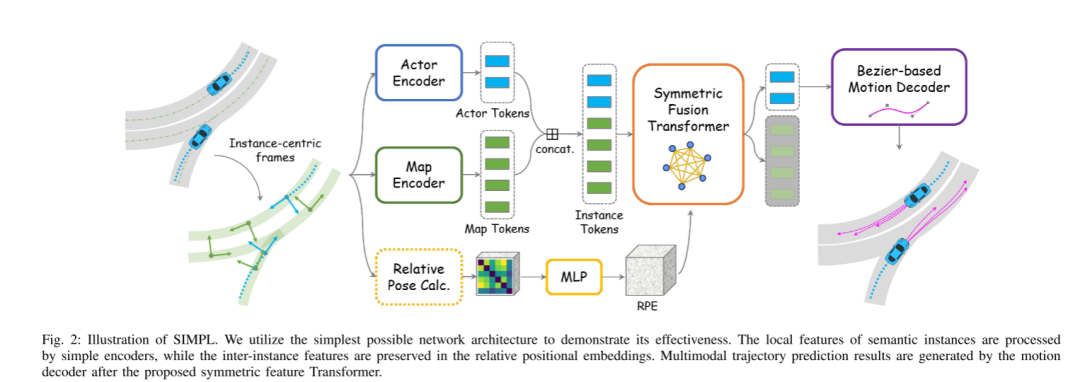
Figure 2 : Schéma SIMPL. Cet article utilise l'architecture réseau la plus simple possible pour démontrer son efficacité. Les caractéristiques locales des instances sémantiques sont traitées par un simple encodeur, tandis que les caractéristiques inter-instances sont préservées dans des intégrations de position relative. Les résultats de prédiction de trajectoire multimodale sont générés par un décodeur de mouvement après le transformateur de caractéristiques symétrique proposé.
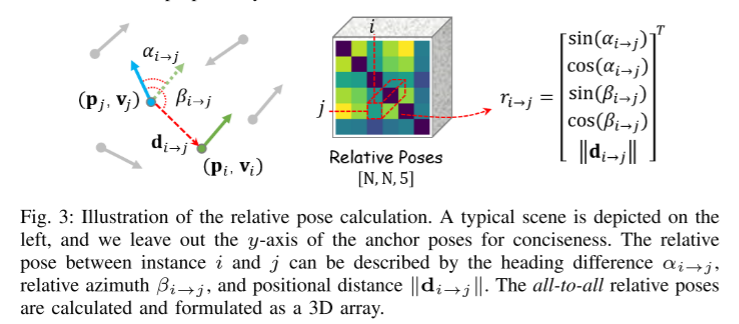
Figure 3 : Diagramme schématique du calcul de la pose relative.
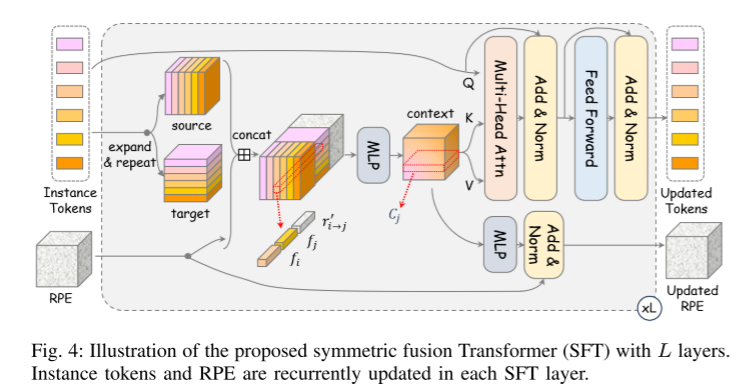
Figure 4 : Illustration du transformateur à fusion symétrique (SFT) proposé en couche L. Les jetons d'instance et les intégrations de position relative (RPE) sont mis à jour de manière cyclique dans chaque couche SFT.
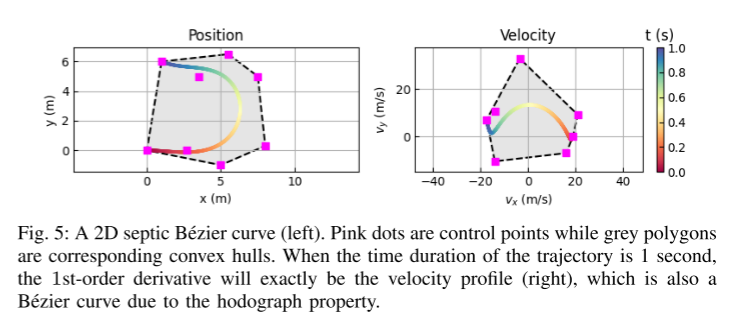
Figure 5 : Courbe de Bézier septique 2D (à gauche).
Résultats expérimentaux :
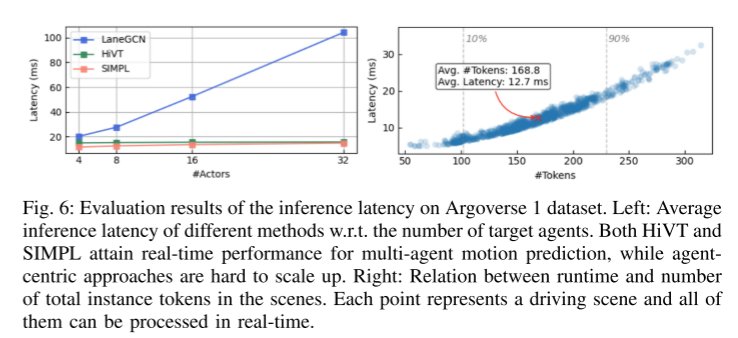
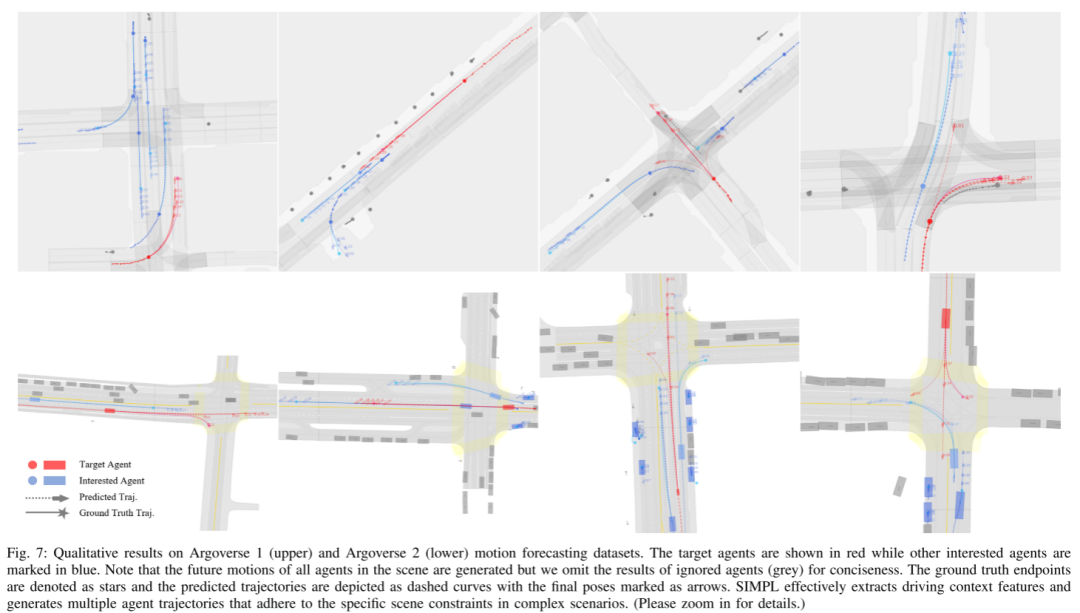
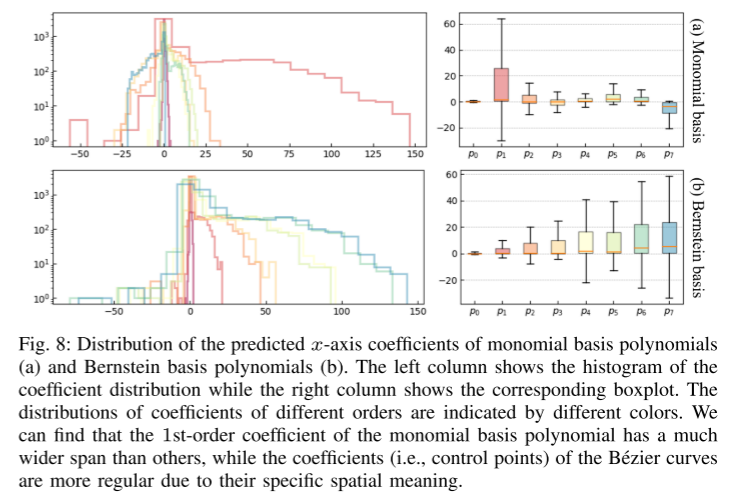
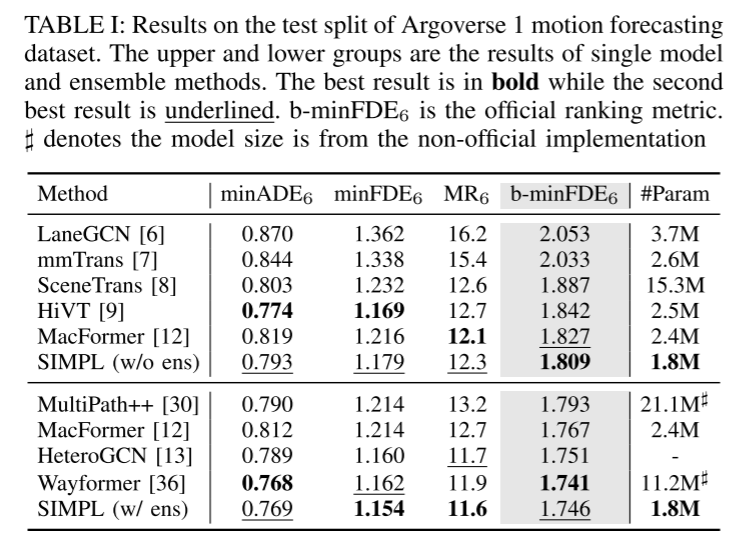
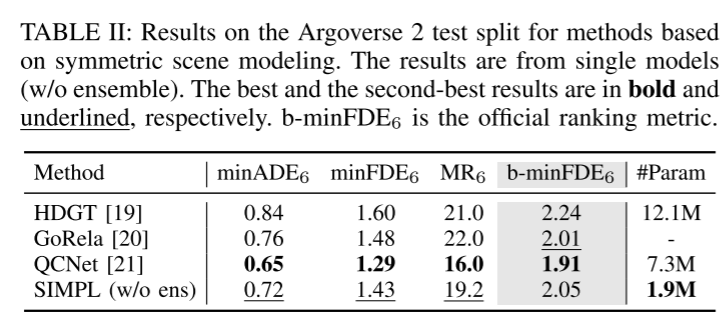
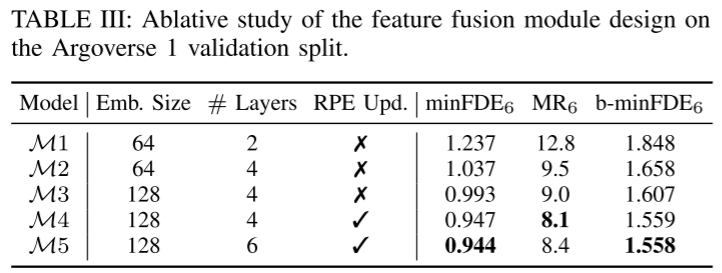
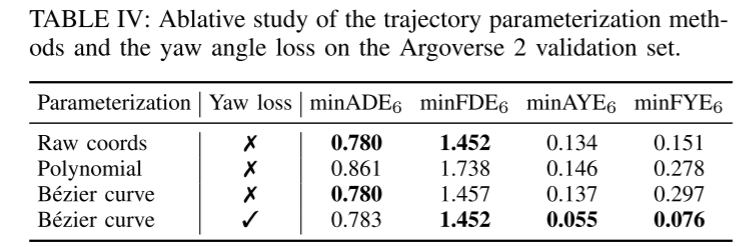
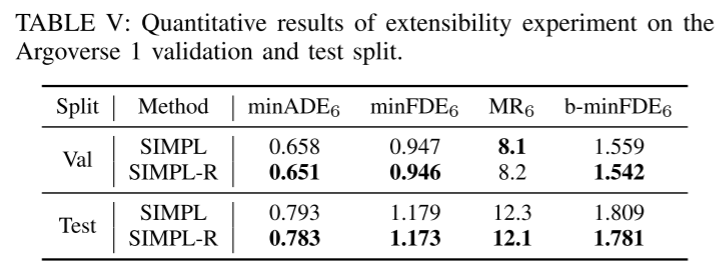
Résumé :
Cet article propose une conduite autonome simple et efficace multi- Objectif Base de référence pour la prédiction du mouvement des agents. En utilisant le transformateur de fusion symétrique proposé, la méthode proposée permet une fusion globale efficace des caractéristiques et maintient la robustesse contre le mouvement du point de vue. Le paramétrage de trajectoire continue basé sur les polynômes de base de Bernstein offre une meilleure compatibilité avec les modules en aval. Les résultats expérimentaux sur des ensembles de données publiques à grande échelle montrent que SIMPL présente des avantages en termes de taille de modèle et de vitesse d'inférence tout en atteignant le même niveau de précision que les autres méthodes de pointe.Citation :
Zhang L, Li P, Liu S et al SIMPL : Une base de référence de prédiction de mouvement multi-agent simple et efficace pour la conduite autonome[J].Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.
Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Régression quantile pour la prévision probabiliste de séries chronologiques
May 07, 2024 pm 05:04 PM
Régression quantile pour la prévision probabiliste de séries chronologiques
May 07, 2024 pm 05:04 PM
Ne changez pas la signification du contenu original, affinez le contenu, réécrivez le contenu et ne continuez pas. "La régression quantile répond à ce besoin, en fournissant des intervalles de prédiction avec des chances quantifiées. Il s'agit d'une technique statistique utilisée pour modéliser la relation entre une variable prédictive et une variable de réponse, en particulier lorsque la distribution conditionnelle de la variable de réponse présente un intérêt quand. Contrairement à la régression traditionnelle " Figure (A) : Régression quantile La régression quantile est une estimation. Une méthode de modélisation de la relation linéaire entre un ensemble de régresseurs X et les quantiles. des variables expliquées Y. Le modèle de régression existant est en fait une méthode pour étudier la relation entre la variable expliquée et la variable explicative. Ils se concentrent sur la relation entre variables explicatives et variables expliquées.
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
