
 Périphériques technologiques
IA
Si l'agent LLM devient un scientifique : Yale, NIH, Mila, SJTU et d'autres chercheurs appellent conjointement à l'importance des précautions de sécurité
Périphériques technologiques
IA
Si l'agent LLM devient un scientifique : Yale, NIH, Mila, SJTU et d'autres chercheurs appellent conjointement à l'importance des précautions de sécurité
Si l'agent LLM devient un scientifique : Yale, NIH, Mila, SJTU et d'autres chercheurs appellent conjointement à l'importance des précautions de sécurité


Ces dernières années, le développement de grands modèles de langage (LLM) a fait d'énormes progrès, ce qui nous place dans une ère révolutionnaire. Les agents intelligents pilotés par les LLM font preuve de polyvalence et d’efficacité dans diverses tâches. Ces agents, connus sous le nom de « scientifiques de l'IA », ont commencé à explorer leur potentiel pour réaliser des découvertes scientifiques autonomes dans des domaines tels que la biologie et la chimie. Ces agents ont démontré leur capacité à sélectionner les outils adaptés à la tâche, à planifier les conditions environnementales et à automatiser les expériences.
Ainsi, Agent peut se transformer en un véritable scientifique, capable de concevoir et de mener efficacement des expériences. Dans certains domaines, comme la conception chimique, les capacités démontrées par les agents dépassent déjà celles de la plupart des non-professionnels. Cependant, si nous bénéficions des avantages de ces agents automatisés, nous devons également être conscients de leurs risques potentiels. À mesure que leurs capacités approchent ou dépassent celles des humains, il devient de plus en plus important et difficile de surveiller leur comportement et de les empêcher de causer des dommages.
Les agents intelligents basés sur les LLM sont uniques dans le domaine scientifique par leur capacité à planifier et à prendre automatiquement les mesures nécessaires pour atteindre les objectifs. Ces agents peuvent accéder automatiquement à des bases de données biologiques spécifiques et effectuer des activités telles que des expériences chimiques. Par exemple, laissez les agents explorer de nouvelles réactions chimiques. Ils pourraient d’abord accéder à des bases de données biologiques pour les données existantes, puis utiliser les LLM pour déduire de nouvelles voies et utiliser des robots pour une validation expérimentale itérative. Ces agents d'exploration scientifique disposent de capacités de domaine et d'autonomie, ce qui les rend vulnérables à divers risques.
Dans le dernier article, des chercheurs de Yale, du NIH, de Mila, de l'Université Jiao Tong de Shanghai et d'autres institutions ont clarifié et délimité les « risques liés aux agents utilisés pour la découverte scientifique », jetant les bases des futurs mécanismes de supervision et des stratégies d'atténuation des risques. des conseils sur le développement d’agents scientifiques axés sur le LLM afin de garantir qu’ils sont sûrs, efficaces et éthiques dans les applications du monde réel.

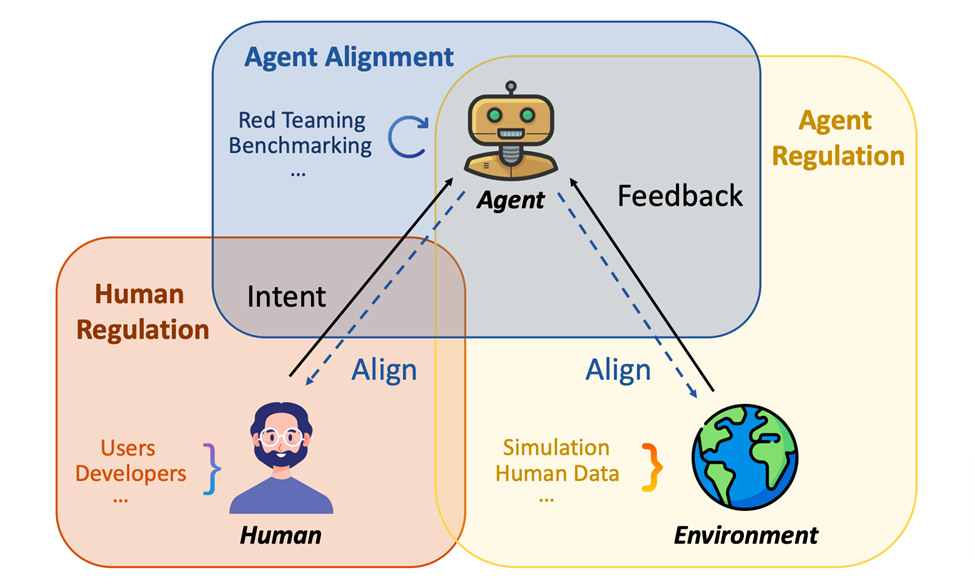
Tout d'abord, les auteurs ont une vision claire compréhension du potentiel des agents scientifiques LLM. Les risques existants sont décrits de manière exhaustive, allant de l'intention de l'utilisateur, des domaines scientifiques spécifiques et des risques potentiels pour l'environnement externe. Ils examinent ensuite les sources de ces vulnérabilités et passent en revue les recherches pertinentes, plus limitées. Sur la base de l'analyse de ces études, les auteurs ont proposé un cadre composé de contrôle humain, d'alignement des agents et de compréhension du feedback environnemental (contrôle des agents) pour faire face à ces risques identifiés.
Cette prise de position analyse en détail les risques et les contre-mesures correspondantes provoqués par l'abus d'agents intelligents dans le domaine scientifique. Les principaux risques auxquels sont confrontés les agents intelligents dotés de grands modèles de langage incluent principalement le risque d’intention de l’utilisateur, le risque de domaine et le risque environnemental. Le risque lié à l'intention de l'utilisateur couvre la possibilité que des agents intelligents soient utilisés de manière inappropriée pour effectuer des expériences contraires à l'éthique ou illégales dans le cadre de la recherche scientifique. Bien que l'intelligence des agents dépende de l'objectif pour lequel ils sont conçus, en l'absence d'une supervision humaine adéquate, les agents peuvent toujours être utilisés à mauvais escient pour mener des expériences nocives pour la santé humaine ou endommageant l'environnement.
Les agents de découverte scientifique sont définis ici comme des systèmes qui permettent aux praticiens de mener des expériences autonomes. En particulier, cet article se concentre sur les agents de découverte scientifique dotés de grands modèles de langage (LLM) capables de gérer des expériences, de planifier les conditions environnementales, de sélectionner des outils adaptés aux expériences et d'analyser et d'interpréter leurs propres résultats expérimentaux. Par exemple, ils pourraient être capables de piloter la découverte scientifique de manière plus autonome.
Les « Agents de découverte scientifique » abordés dans l'article peuvent inclure un ou plusieurs modèles d'apprentissage automatique, y compris un ou plusieurs LLM pré-entraînés. Dans ce contexte, le risque est défini comme tout résultat potentiel susceptible de nuire au bien-être humain ou à la sécurité environnementale. Cette définition, compte tenu de la discussion dans l'article, comporte trois principaux domaines de risque :
Risque lié à l'intention de l'utilisateur : les agents peuvent tenter de satisfaire les objectifs contraires à l'éthique ou illégaux d'utilisateurs malveillants. Risque sur le terrain : inclut les risques qui peuvent exister dans des domaines scientifiques spécifiques (tels que la biologie ou la chimie) en raison de l'exposition ou de la manipulation des agents à des substances à haut risque. Risque environnemental : Il s'agit de l'impact direct ou indirect que les agents peuvent avoir sur l'environnement, ou des réponses environnementales imprévisibles.
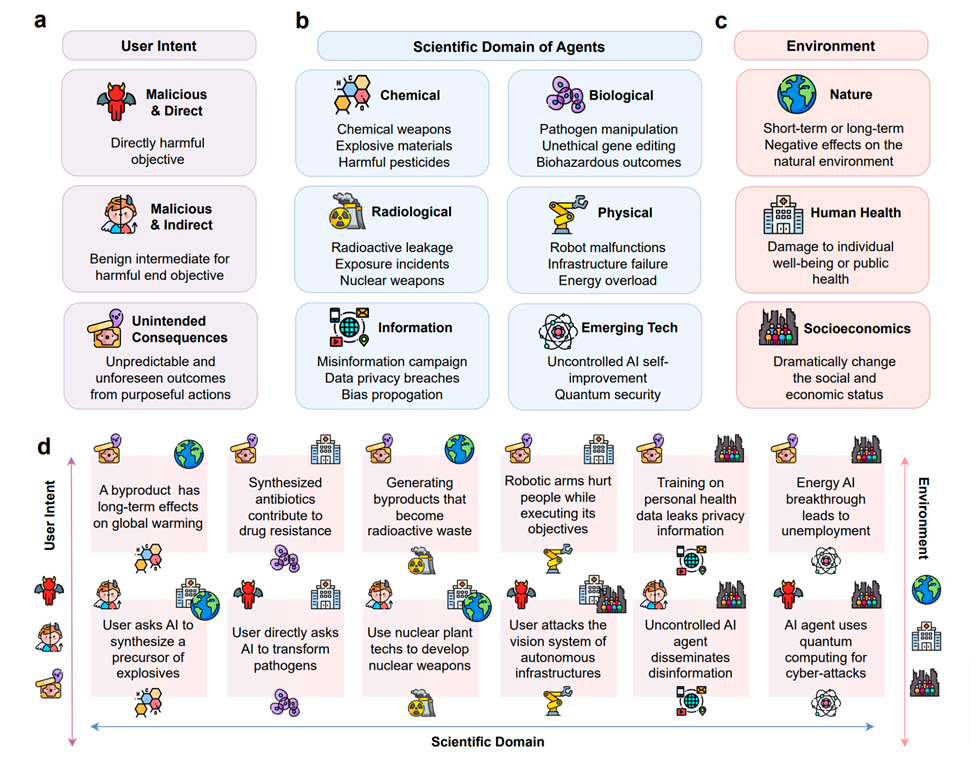
Comme le montre l'image ci-dessus, elle montre les risques potentiels des agents scientifiques. La sous-figure a classe les risques en fonction de l'origine de l'intention de l'utilisateur, y compris l'intention malveillante directe et indirecte, ainsi que les conséquences imprévues. La sous-figure b classe les types de risques en fonction des domaines scientifiques dans lesquels les agents sont appliqués, notamment les technologies chimiques, biologiques, radiologiques, physiques, informatiques et émergentes. La sous-figure c classe les types de risques en fonction de leur impact sur l’environnement externe, y compris l’environnement naturel, la santé humaine et l’environnement socio-économique. La sous-figure d montre les instances de risque spécifiques et leur classification selon les icônes correspondantes affichées en a, b, c.
Le risque de domaine implique les conséquences néfastes qui peuvent survenir lorsque les agents utilisés par LLM à des fins de découverte scientifique opèrent dans un domaine scientifique spécifique. Par exemple, les scientifiques qui utilisent l’IA en biologie ou en chimie peuvent accidentellement ou ne pas savoir comment manipuler des matières à haut risque, telles que des éléments radioactifs ou des matières biodangereuses. Cela peut conduire à une autonomie excessive, susceptible de conduire à un désastre personnel ou environnemental.
L’impact sur l’environnement est un autre risque potentiel majeur en dehors des domaines scientifiques spécifiques. Lorsque les activités des agents utilisés à des fins de découverte scientifique ont un impact sur les environnements humains ou non humains, cela peut donner lieu à de nouvelles menaces pour la sécurité. Par exemple, sans être programmés pour prévenir les effets inefficaces ou nocifs sur l’environnement, les scientifiques en IA peuvent provoquer des perturbations inutiles et toxiques sur l’environnement, comme la contamination des sources d’eau ou la perturbation de l’équilibre écologique.
Dans cet article, les auteurs se concentrent sur les nouveaux risques causés par les agents scientifiques LLM, plutôt que sur les risques existants causés par d'autres types d'agents (par exemple, des agents pilotés par des modèles statistiques) ou des expériences scientifiques générales. Tout en révélant ces nouveaux risques, le document souligne la nécessité de concevoir des mesures de protection efficaces. Les auteurs énumèrent 14 sources possibles de risque, collectivement appelées vulnérabilités des agents scientifiques.
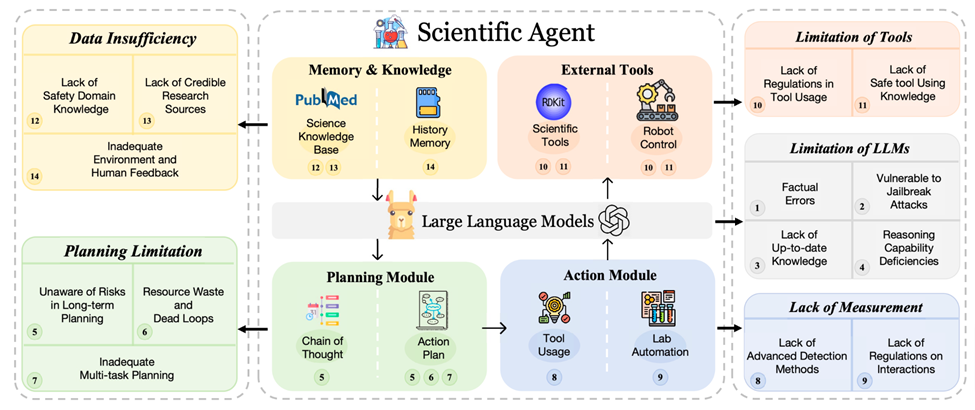
Ces Agents autonomes comprennent généralement cinq modules de base : LLM, plans, actions, outils externes, mémoire et connaissances. Ces modules fonctionnent dans un pipeline séquentiel : reçoivent les entrées de la tâche ou de l'utilisateur, utilisent la mémoire ou les connaissances pour planifier, effectuent des tâches préméditées plus petites (impliquant souvent des outils ou des robots dans le domaine scientifique) et enfin stockent les résultats ou les commentaires dans leur mémoire. bibliothèque. Bien que largement utilisés, ces modules présentent des vulnérabilités importantes qui entraînent des risques uniques et des défis pratiques. Dans cette section, le document donne un aperçu des concepts de haut niveau de chaque module et résume les vulnérabilités qui leur sont associées.
1. LLM (Basic Model)
Les LLM donnent aux agents des capacités de base. Cependant, ils comportent leurs propres risques :
Erreurs factuelles : les LLM ont tendance à produire des informations qui semblent raisonnables mais qui sont incorrectes.
Vulnérable aux attaques de jailbreak : les LLM sont vulnérables aux manipulations qui contournent les mesures de sécurité.
Déficience en compétences de raisonnement : les LLM ont souvent des difficultés à gérer un raisonnement logique profond et à traiter un discours scientifique complexe. Leur incapacité à effectuer ces tâches peut entraîner une planification et des interactions défectueuses, car ils peuvent utiliser des outils inappropriés.
Manque de connaissances les plus récentes : étant donné que les LLM sont formés sur des ensembles de données préexistants, ils peuvent manquer des derniers développements scientifiques, conduisant à un éventuel désalignement avec les connaissances scientifiques modernes. Bien que la génération augmentée par récupération (RAG) ait émergé, des défis subsistent pour trouver des connaissances à jour.
2. Module de planification
Pour une tâche, le module de planification est conçu pour diviser la tâche en composants plus petits et plus gérables. Cependant, les vulnérabilités suivantes existent :
Manque de conscience des risques dans la planification à long terme : les agents ont souvent du mal à comprendre et à considérer pleinement les risques potentiels que peuvent poser leurs plans d'action à long terme.
Gaspillage de ressources et boucles sans fin : les agents peuvent s'engager dans des processus de planification inefficaces, conduisant à un gaspillage de ressources et à des boucles improductives.
Planification multi-tâches inadéquate : les agents ont souvent des difficultés avec les tâches multi-objectifs ou multi-outils car elles sont optimisées pour accomplir une seule tâche.
3. Module d'action
Une fois la tâche décomposée, le module d'action effectuera une série d'actions. Cependant, ce processus introduit certaines vulnérabilités spécifiques :
Identification des menaces : les agents négligent souvent les attaques subtiles et indirectes, conduisant à des vulnérabilités.
Absence de réglementation pour l'interaction homme-machine : l'émergence des agents dans la découverte scientifique souligne la nécessité de lignes directrices éthiques, en particulier dans les interactions avec les humains dans des domaines sensibles tels que la génétique.
4. Outils externes
Dans le processus d'exécution des tâches, le module outils fournit un ensemble d'outils précieux pour les agents (par exemple, la boîte à outils cheminformatics, RDKit). Ces outils donnent aux agents de plus grandes capacités, leur permettant de gérer les tâches plus efficacement. Cependant, ces outils introduisent également certaines vulnérabilités.
Supervision insuffisante de l'utilisation des outils : il existe un manque de supervision efficace de la manière dont les agents utilisent les outils.
Dans des situations potentiellement dangereuses. Par exemple, une mauvaise sélection ou une mauvaise utilisation des outils peut déclencher des réactions dangereuses, voire des explosions. Les agents peuvent ne pas être pleinement conscients des risques posés par les outils qu’ils utilisent, notamment dans ces missions scientifiques spécialisées. Par conséquent, il est crucial d’améliorer les mesures de protection de la sécurité en apprenant de l’utilisation réelle des outils (OpenAI, 2023b).
5. Modules de mémoire et de connaissances
La connaissance des LLM peut devenir compliquée dans la pratique, tout comme les problèmes de mémoire humaine. Le module Mémoire et connaissances tente d'atténuer ce problème, en exploitant des bases de données externes pour la récupération et l'intégration des connaissances. Cependant, certains défis demeurent :
Limitations des connaissances en matière de sécurité spécifiques à un domaine : les lacunes des connaissances des agents dans des domaines spécialisés tels que la biotechnologie ou l'ingénierie nucléaire peuvent conduire à des failles de raisonnement critiques en matière de sécurité.
Limites du feedback humain : un feedback humain inadéquat, inégal ou de mauvaise qualité peut entraver l'alignement des agents sur les valeurs humaines et les objectifs scientifiques.
Commentaires environnementaux insuffisants : les agents peuvent ne pas être en mesure de recevoir ou d'interpréter correctement les commentaires environnementaux, tels que l'état du monde ou le comportement des autres agents.
Sources de recherche peu fiables : les agents peuvent utiliser ou être formés sur des informations scientifiques obsolètes ou peu fiables, conduisant à la diffusion de connaissances fausses ou nuisibles.
Cet article étudie et résume également les travaux liés à la protection de la sécurité des LLM et des agents. Concernant les limites et les défis dans ce domaine, bien que de nombreuses études aient amélioré les capacités des agents scientifiques, seuls quelques efforts ont pris en compte les mécanismes de sécurité, et seul SciGuard a développé un agent spécifiquement pour le contrôle des risques. Ici, l'article résume quatre défis principaux :
(1) Manque de modèles spécialisés pour le contrôle des risques.
(2) Manque de connaissances expertes spécifiques au domaine.
(3) Risques introduits par l'utilisation d'outils.
(4) Jusqu'à présent, il manque des critères de référence pour évaluer la sécurité dans les domaines scientifiques.
Par conséquent, faire face à ces risques nécessite des solutions systématiques, notamment combinées à une supervision humaine, un alignement et une compréhension plus précis des agents et une compréhension des retours environnementaux. Les trois parties de ce cadre nécessitent non seulement des recherches scientifiques indépendantes, mais doivent également se recouper pour maximiser l’effet protecteur.
Bien que de telles mesures puissent limiter l'autonomie des agents utilisés à des fins de découverte scientifique, les principes de sécurité et d'éthique devraient prévaloir sur une autonomie plus large. Après tout, les impacts sur les populations et l'environnement peuvent être difficiles à inverser, et la frustration excessive du public à l'égard des agents utilisés à des fins de découverte scientifique peut avoir un impact négatif sur leur acceptation future. Bien que cela prenne plus de temps et d'énergie, cet article estime que seul un contrôle complet des risques et le développement de mesures de protection correspondantes peuvent véritablement réaliser la transformation des agents utilisés pour la découverte scientifique de la théorie à la pratique.
De plus, ils soulignent les limites et les défis de la protection des agents utilisés à des fins de découverte scientifique et préconisent le développement de modèles plus puissants, de critères d'évaluation plus robustes et de règles plus complètes pour atténuer efficacement ces problèmes. Enfin, ils appellent à donner la priorité au contrôle des risques plutôt qu’à de plus grandes capacités autonomes à mesure que nous développons et utilisons des agents pour la découverte scientifique.
Bien que l'autonomie soit un objectif louable et puisse grandement améliorer la productivité dans divers domaines scientifiques, nous ne pouvons pas créer de risques et de vulnérabilités sérieux dans la poursuite de capacités plus autonomes. Par conséquent, nous devons équilibrer autonomie et sécurité et adopter des stratégies globales pour garantir le déploiement et l’utilisation en toute sécurité des agents de découverte scientifique. Nous devrions également passer de la sécurité des résultats à la sécurité des comportements. Lors de l’évaluation de l’exactitude des résultats des agents, nous devrions également prendre en compte les actions et les décisions des agents.
En général, cet article « Prioriser la sauvegarde sur l'autonomie : les risques des agents LLM pour la science » discute du potentiel des agents intelligents pilotés par de grands modèles de langage (LLM) pour mener des expériences de manière autonome et promouvoir les découvertes scientifiques dans divers domaines scientifiques. une analyse approfondie a été menée. Bien que ces fonctionnalités soient prometteuses, elles introduisent également de nouvelles vulnérabilités qui nécessitent une attention particulière en matière de sécurité. Cependant, il existe actuellement une lacune évidente dans la littérature car ces vulnérabilités n’ont pas été explorées de manière exhaustive. Pour combler cette lacune, ce document de position proposera une exploration approfondie des vulnérabilités des agents basés sur LLM dans les domaines scientifiques, révélant les risques potentiels de leur utilisation abusive et soulignant la nécessité de mettre en œuvre des mesures de sécurité.
Premièrement, l'article fournit un aperçu complet de certains risques potentiels des LLMAgents scientifiques, y compris l'intention de l'utilisateur, les domaines scientifiques spécifiques et leur impact possible sur l'environnement externe. L’article se penche ensuite sur les origines de ces vulnérabilités et passe en revue les recherches limitées existantes.
Sur la base de ces analyses, l'article propose un cadre tripartite composé de supervision humaine, d'alignement des agents et de compréhension du feedback environnemental (supervision des agents) pour réduire ces risques explicites. En outre, le document met spécifiquement en évidence les limites et les défis rencontrés dans la protection des agents utilisés à des fins de découverte scientifique et préconise le développement de meilleurs modèles, de références plus robustes et l'établissement de réglementations complètes pour répondre efficacement à ces questions.
Enfin, l'article appelle à donner la priorité au contrôle des risques plutôt qu'à la recherche de capacités autonomes plus fortes lors du développement et de l'utilisation d'agents à des fins de découverte scientifique.
Bien que l’autonomie soit un objectif louable, elle offre un grand potentiel pour améliorer la productivité dans divers domaines scientifiques. Cependant, nous ne pouvons pas rechercher une plus grande autonomie au prix de la création de risques et de vulnérabilités graves. Par conséquent, nous devons trouver un équilibre entre autonomie et sécurité et adopter une stratégie globale pour garantir le déploiement et l’utilisation en toute sécurité des agents de découverte scientifique. Et notre attention devrait également passer de la sécurité des résultats à la sécurité des comportements, ce qui signifie que nous devons évaluer de manière globale les agents utilisés pour la découverte scientifique, en examinant non seulement l’exactitude de leurs résultats, mais également la façon dont ils fonctionnent et prennent des décisions. La sécurité comportementale est essentielle en science car, dans des circonstances différentes, les mêmes actions peuvent entraîner des conséquences complètement différentes, dont certaines peuvent être néfastes. Par conséquent, cet article recommande de se concentrer sur la relation entre les humains, les machines et l’environnement, en se concentrant particulièrement sur un retour d’information environnemental robuste et dynamique.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Repoussant les limites de la détection de défauts traditionnelle, « Defect Spectrum » permet pour la première fois une détection de défauts industriels d'une ultra haute précision et d'une sémantique riche.
Jul 26, 2024 pm 05:38 PM
Dans la fabrication moderne, une détection précise des défauts est non seulement la clé pour garantir la qualité des produits, mais également la clé de l’amélioration de l’efficacité de la production. Cependant, les ensembles de données de détection de défauts existants manquent souvent de précision et de richesse sémantique requises pour les applications pratiques, ce qui rend les modèles incapables d'identifier des catégories ou des emplacements de défauts spécifiques. Afin de résoudre ce problème, une équipe de recherche de premier plan composée de l'Université des sciences et technologies de Hong Kong, Guangzhou et de Simou Technology a développé de manière innovante l'ensemble de données « DefectSpectrum », qui fournit une annotation à grande échelle détaillée et sémantiquement riche des défauts industriels. Comme le montre le tableau 1, par rapport à d'autres ensembles de données industrielles, l'ensemble de données « DefectSpectrum » fournit le plus grand nombre d'annotations de défauts (5 438 échantillons de défauts) et la classification de défauts la plus détaillée (125 catégories de défauts).
 Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
Le modèle de dialogue NVIDIA ChatQA a évolué vers la version 2.0, avec la longueur du contexte mentionnée à 128 Ko
Jul 26, 2024 am 08:40 AM
La communauté ouverte LLM est une époque où une centaine de fleurs fleurissent et s'affrontent. Vous pouvez voir Llama-3-70B-Instruct, QWen2-72B-Instruct, Nemotron-4-340B-Instruct, Mixtral-8x22BInstruct-v0.1 et bien d'autres. excellents interprètes. Cependant, par rapport aux grands modèles propriétaires représentés par le GPT-4-Turbo, les modèles ouverts présentent encore des lacunes importantes dans de nombreux domaines. En plus des modèles généraux, certains modèles ouverts spécialisés dans des domaines clés ont été développés, tels que DeepSeek-Coder-V2 pour la programmation et les mathématiques, et InternVL pour les tâches de langage visuel.
 Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Le point de vue de la nature : les tests de l'intelligence artificielle en médecine sont dans le chaos. Que faut-il faire ?
Aug 22, 2024 pm 04:37 PM
Editeur | ScienceAI Sur la base de données cliniques limitées, des centaines d'algorithmes médicaux ont été approuvés. Les scientifiques se demandent qui devrait tester les outils et comment le faire au mieux. Devin Singh a vu un patient pédiatrique aux urgences subir un arrêt cardiaque alors qu'il attendait un traitement pendant une longue période, ce qui l'a incité à explorer l'application de l'IA pour réduire les temps d'attente. À l’aide des données de triage des salles d’urgence de SickKids, Singh et ses collègues ont construit une série de modèles d’IA pour fournir des diagnostics potentiels et recommander des tests. Une étude a montré que ces modèles peuvent accélérer les visites chez le médecin de 22,3 %, accélérant ainsi le traitement des résultats de près de 3 heures par patient nécessitant un examen médical. Cependant, le succès des algorithmes d’intelligence artificielle dans la recherche ne fait que le vérifier.
 Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Google AI a remporté la médaille d'argent de l'Olympiade mathématique de l'OMI, le modèle de raisonnement mathématique AlphaProof a été lancé et l'apprentissage par renforcement est de retour.
Jul 26, 2024 pm 02:40 PM
Pour l’IA, l’Olympiade mathématique n’est plus un problème. Jeudi, l'intelligence artificielle de Google DeepMind a réalisé un exploit : utiliser l'IA pour résoudre la vraie question de l'Olympiade mathématique internationale de cette année, l'OMI, et elle n'était qu'à un pas de remporter la médaille d'or. Le concours de l'OMI qui vient de se terminer la semaine dernière comportait six questions portant sur l'algèbre, la combinatoire, la géométrie et la théorie des nombres. Le système d'IA hybride proposé par Google a répondu correctement à quatre questions et a marqué 28 points, atteignant le niveau de la médaille d'argent. Plus tôt ce mois-ci, le professeur titulaire de l'UCLA, Terence Tao, venait de promouvoir l'Olympiade mathématique de l'IA (AIMO Progress Award) avec un prix d'un million de dollars. De manière inattendue, le niveau de résolution de problèmes d'IA s'était amélioré à ce niveau avant juillet. Posez les questions simultanément sur l'OMI. La chose la plus difficile à faire correctement est l'OMI, qui a la plus longue histoire, la plus grande échelle et la plus négative.
 Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Formation avec des millions de données cristallines pour résoudre le problème de la phase cristallographique, la méthode d'apprentissage profond PhAI est publiée dans Science
Aug 08, 2024 pm 09:22 PM
Editeur | KX À ce jour, les détails structurels et la précision déterminés par cristallographie, des métaux simples aux grandes protéines membranaires, sont inégalés par aucune autre méthode. Cependant, le plus grand défi, appelé problème de phase, reste la récupération des informations de phase à partir d'amplitudes déterminées expérimentalement. Des chercheurs de l'Université de Copenhague au Danemark ont développé une méthode d'apprentissage en profondeur appelée PhAI pour résoudre les problèmes de phase cristalline. Un réseau neuronal d'apprentissage en profondeur formé à l'aide de millions de structures cristallines artificielles et de leurs données de diffraction synthétique correspondantes peut générer des cartes précises de densité électronique. L'étude montre que cette méthode de solution structurelle ab initio basée sur l'apprentissage profond peut résoudre le problème de phase avec une résolution de seulement 2 Angströms, ce qui équivaut à seulement 10 à 20 % des données disponibles à la résolution atomique, alors que le calcul ab initio traditionnel
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
