
 Périphériques technologiques
IA
Lorsque Sora a fait exploser la génération vidéo, Meta a commencé à utiliser Agent pour couper automatiquement la vidéo, dirigé par des auteurs chinois.
Périphériques technologiques
IA
Lorsque Sora a fait exploser la génération vidéo, Meta a commencé à utiliser Agent pour couper automatiquement la vidéo, dirigé par des auteurs chinois.
Lorsque Sora a fait exploser la génération vidéo, Meta a commencé à utiliser Agent pour couper automatiquement la vidéo, dirigé par des auteurs chinois.

Récemment, le domaine de la technologie vidéo IA a attiré beaucoup d'attention, en particulier le grand modèle de génération vidéo Sora lancé par OpenAI, qui a suscité de nombreuses discussions. Dans le même temps, dans le domaine du montage vidéo, les modèles d'IA à grande échelle tels que Agent ont également fait preuve d'une grande solidité.
Bien que le langage naturel soit utilisé pour gérer les tâches de montage vidéo, les utilisateurs peuvent exprimer directement leurs intentions sans opérations manuelles. Cependant, la plupart des outils de montage vidéo actuels nécessitent encore de nombreuses opérations manuelles et manquent de support contextuel personnalisé. Cela oblige les utilisateurs à résoudre eux-mêmes des problèmes de montage vidéo complexes.
La clé est de savoir comment concevoir un outil de montage vidéo capable d'agir en tant que collaborateur et d'assister en permanence les utilisateurs pendant le processus de montage ? Dans cet article, des chercheurs de l'Université de Toronto, Meta (Reality Labs Research) et de l'Université de Californie à San Diego proposent d'utiliser les capacités linguistiques multifonctionnelles des grands modèles de langage (LLM) pour le montage vidéo et d'explorer l'avenir. paradigme de montage vidéo, réduisant ainsi la frustration liée au processus de montage vidéo manuel.

- Titre de l'article : LAVE : LLM-Powered Agent Assistance and Language Augmentation for Video Editing
- Adresse de l'article : https://arxiv.org/pdf/2402.10294.pdf
Research L'auteur a développé un outil de montage vidéo appelé LAVE, qui intègre plusieurs fonctions d'amélioration du langage fournies par LLM. LAVE introduit un système intelligent de planification et d'exécution basé sur LLM, qui peut interpréter les instructions en langage libre de l'utilisateur, planifier et exécuter les opérations associées pour atteindre les objectifs de montage vidéo de l'utilisateur. Ce système intelligent fournit une assistance conceptuelle, telle qu'un brainstorming créatif et des aperçus de séquences vidéo, ainsi qu'une assistance opérationnelle, notamment la récupération vidéo basée sur la sémantique, le storyboard et le découpage de clips.
Afin de faire fonctionner ces agents en douceur, LAVE utilise un modèle de langage visuel (VLM) pour générer automatiquement des descriptions linguistiques des effets visuels vidéo. Ces récits visuels permettent à LLM de comprendre le contenu vidéo et d'utiliser ses capacités linguistiques pour aider les utilisateurs dans le montage. De plus, LAVE propose deux modes de montage vidéo interactifs, à savoir l'assistance aux agents et le fonctionnement direct. Ce double mode offre aux utilisateurs une plus grande flexibilité pour améliorer le fonctionnement de l'agent selon les besoins.
Quant à l'effet d'édition de LAVE ? Les chercheurs ont mené une étude utilisateur auprès de 8 participants, dont des éditeurs novices et expérimentés, et les résultats ont montré que les participants pouvaient utiliser LAVE pour créer des vidéos collaboratives IA satisfaisantes.
Il est à noter que 5 des six auteurs de cette étude sont chinois, dont Yi Zuo, Bryan Wang, doctorant en informatique à l'Université de Toronto, les chercheurs Meta Yuliang Li, Zhaoyang Lv et Yan Xu. , Université de Californie, San Diego Professeur adjoint Haijun Xia.
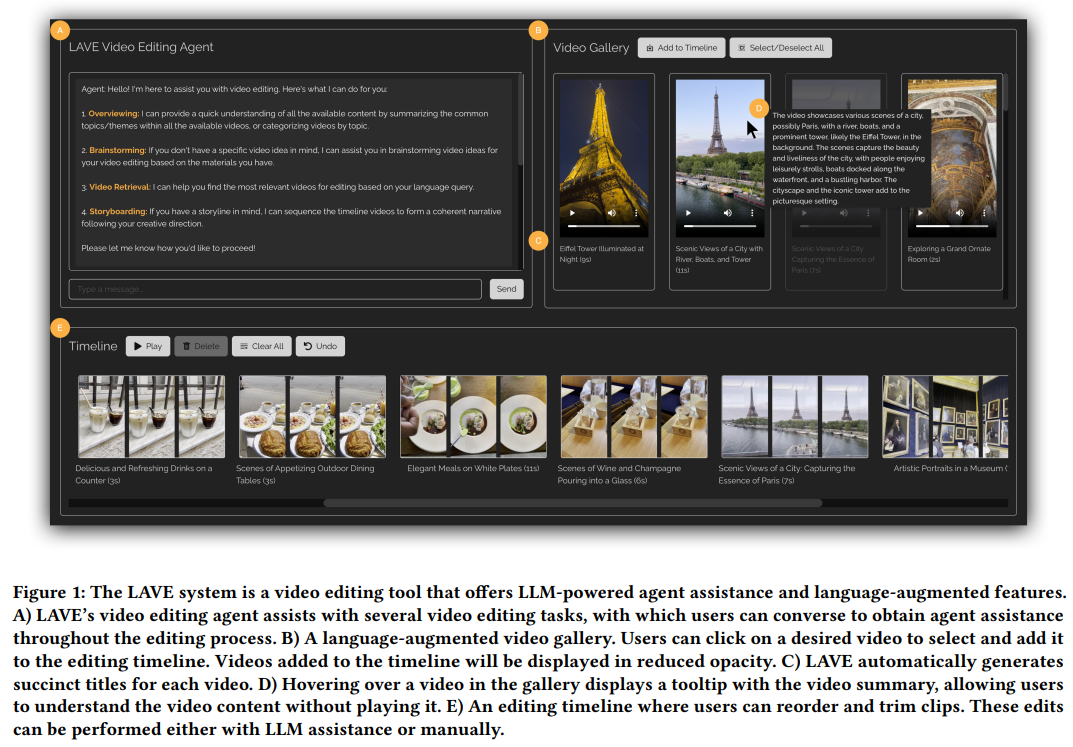
Interface utilisateur (UI) de LAVE
Examinons d'abord la conception du système de LAVE, comme le montre la figure 1 ci-dessous. L'interface utilisateur de
LAVE se compose de trois composants principaux, comme suit :
- Bibliothèque de vidéos linguistiquement améliorée, qui affiche des clips vidéo avec des descriptions de langue générées automatiquement
- Chronologie de clips vidéo, y compris basée sur la langue principale ; la chronologie du clip ; le
- Video Clip Agent permet à l'utilisateur d'interagir avec un agent conversationnel et d'obtenir de l'aide.
La logique de conception est la suivante : lorsque l'utilisateur interagit avec l'agent, l'échange de messages sera affiché dans l'interface utilisateur du chat. Ce faisant, l’agent apporte des modifications à la bibliothèque vidéo et à la chronologie du clip. De plus, les utilisateurs peuvent utiliser directement la vidéothèque et la chronologie à l'aide du curseur, à l'instar des interfaces d'édition traditionnelles.
Bibliothèque vidéo d'amélioration du langage
Les fonctions de la vidéothèque d'amélioration du langage sont illustrées dans la figure 3 ci-dessous.
Comme les outils traditionnels, cette fonctionnalité permet la lecture de clips mais fournit une narration visuelle, c'est-à-dire des descriptions textuelles générées automatiquement pour chaque vidéo, comprenant des titres sémantiques et des résumés. Les titres aident à comprendre et à indexer les clips, et les résumés fournissent un aperçu du contenu visuel de chaque clip, aidant ainsi les utilisateurs à former le scénario de leur projet de montage. Un titre et une durée apparaissent sous chaque vidéo.
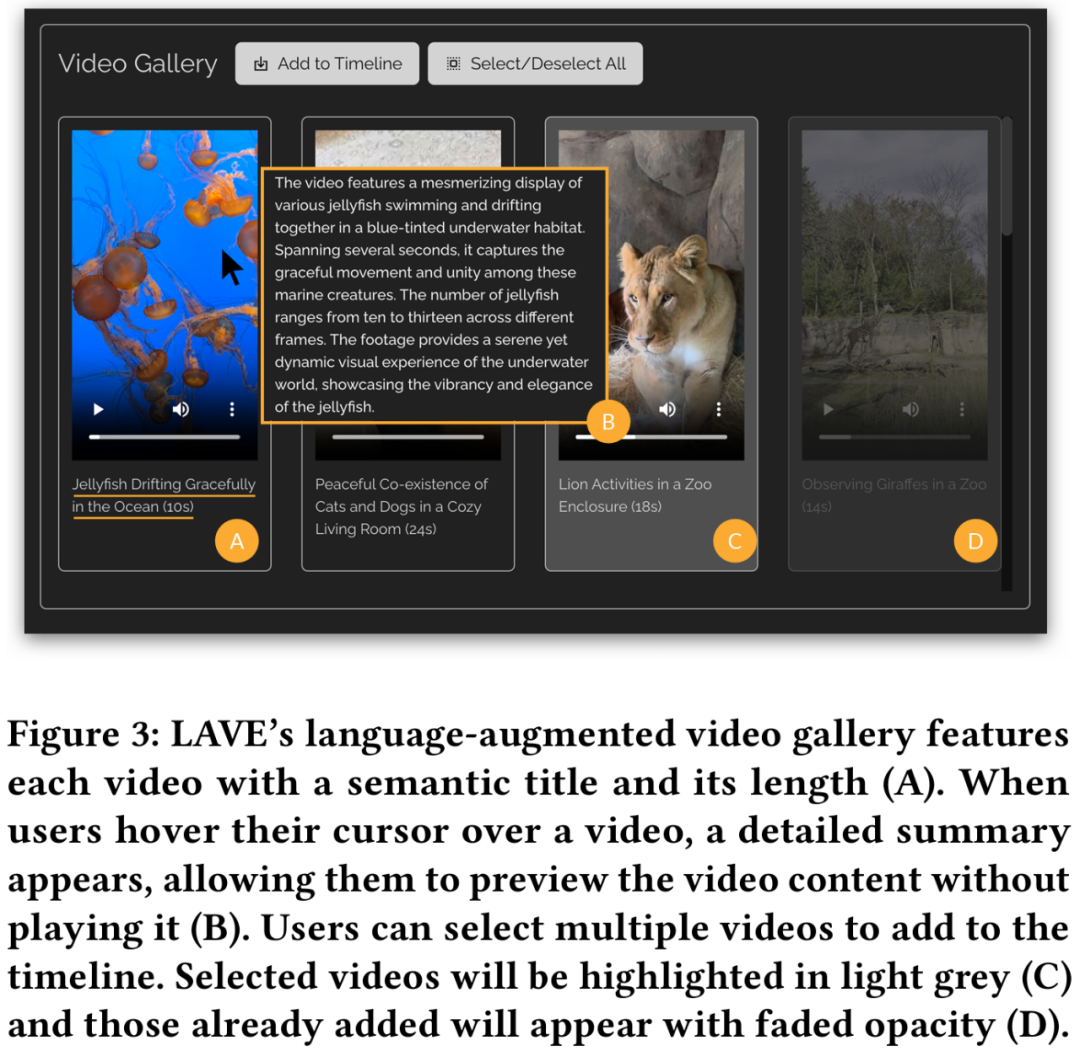
De plus, LAVE permet aux utilisateurs de rechercher des vidéos à l'aide de requêtes en langage sémantique, et les vidéos récupérées sont affichées dans la vidéothèque et triées par pertinence. Cette fonction doit être exécutée par le Clip Agent.
Chronologie du clip vidéo
Après avoir sélectionné les vidéos dans la vidéothèque et les avoir ajoutées à la chronologie du clip, elles seront affichées sur la chronologie du clip vidéo en bas de l'interface, comme le montre la figure 2 ci-dessous. . Chaque clip sur la timeline est représenté par une boîte et affiche trois images miniatures : l'image de début, l'image du milieu et l'image de fin.
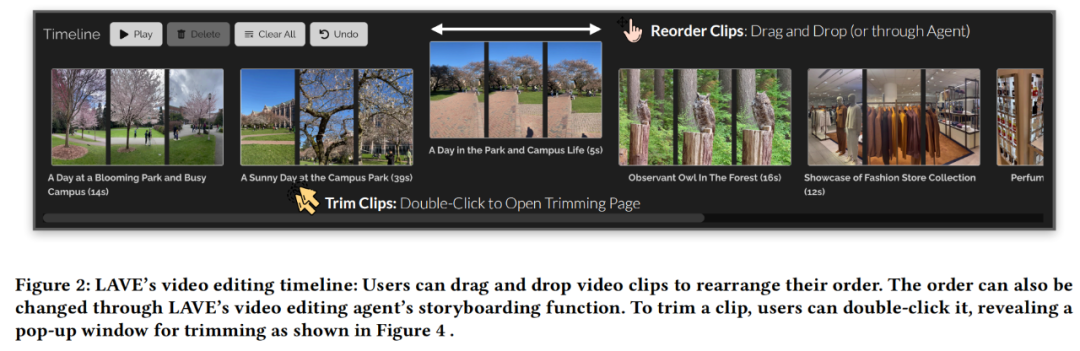
Dans le système LAVE, chaque image miniature représente une seconde de contenu dans le clip. Comme pour la galerie vidéo, un titre et une description sont fournis pour chaque clip. La chronologie des clips dans LAVE comporte deux fonctionnalités clés : le tri et le découpage des clips.
Le séquençage des clips sur la timeline est une tâche courante dans le montage vidéo et est important pour créer un récit cohérent. LAVE prend en charge deux méthodes de tri : l'une est le tri basé sur LLM, qui utilise la fonction de storyboard de l'agent de clip vidéo, l'autre est le tri manuel, qui est trié par opération directe de l'utilisateur. des clips apparaissent.
Le découpage est également important dans le montage vidéo pour mettre en évidence les segments clés et supprimer le contenu en excès. Lors du découpage, l'utilisateur double-clique sur le clip dans la timeline, ce qui ouvre une fenêtre contextuelle affichant des images d'une seconde, comme le montre la figure 4 ci-dessous.

Video Clip Agent
Video Clip Agent de LAVE est un composant basé sur le chat qui facilite l'interaction entre les utilisateurs et les agents basés sur LLM. Contrairement aux outils de ligne de commande, les utilisateurs peuvent interagir avec les agents en utilisant un langage libre. L'agent exploite l'intelligence linguistique de LLM pour fournir une assistance au montage vidéo et fournir des réponses spécifiques pour guider et assister l'utilisateur tout au long du processus de montage. Les capacités d'assistance aux agents de LAVE sont fournies par le biais d'opérations d'agent, dont chacune implique l'exécution d'une fonction d'édition prise en charge par le système.
En général, LAVE fournit des fonctionnalités qui couvrent l'ensemble du flux de travail, depuis l'idéation et la pré-planification jusqu'aux opérations d'édition réelles, mais le système n'impose pas un flux de travail strict. Les utilisateurs ont la possibilité d'exploiter des sous-ensembles de fonctionnalités qui correspondent à leurs objectifs d'édition. Par exemple, les utilisateurs ayant une vision éditoriale claire et un scénario clair peuvent contourner la phase d’idéation et passer directement à l’édition.
Système backend
Cette étude utilise GPT-4 d'OpenAI pour illustrer la conception du système backend LAVE, qui comprend principalement deux aspects : la conception d'agents et la mise en œuvre de fonctions d'édition pilotées par LLM.
Agent Design
Cette recherche exploite les multiples capacités linguistiques du LLM (c'est-à-dire GPT-4), y compris le raisonnement, la planification et la narration, pour créer l'agent LAVE.
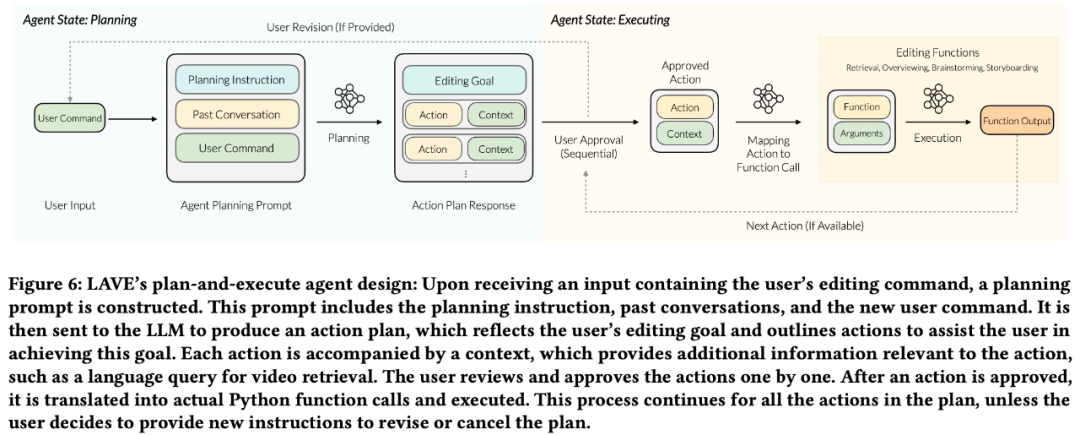
L'agent LAVE a deux états : planification et exécution. Cette configuration présente deux avantages principaux :
- permet aux utilisateurs de définir des objectifs de haut niveau contenant plusieurs actions, éliminant ainsi le besoin de détailler chaque action individuelle comme les outils de ligne de commande traditionnels.
- Avant l'exécution, l'agent présentera le plan à l'utilisateur, offrant des possibilités de modification et garantissant que l'utilisateur a un contrôle total sur le fonctionnement de l'agent. L'équipe de recherche a conçu un pipeline back-end pour compléter le processus de planification et d'exécution.
Comme le montre la figure 6 ci-dessous, le pipeline crée d'abord un plan d'action basé sur les entrées de l'utilisateur. Le plan est ensuite converti d'une description textuelle en appels de fonction, et les fonctions correspondantes sont ensuite exécutées.
Mise en œuvre des fonctions d'édition pilotées par LLM
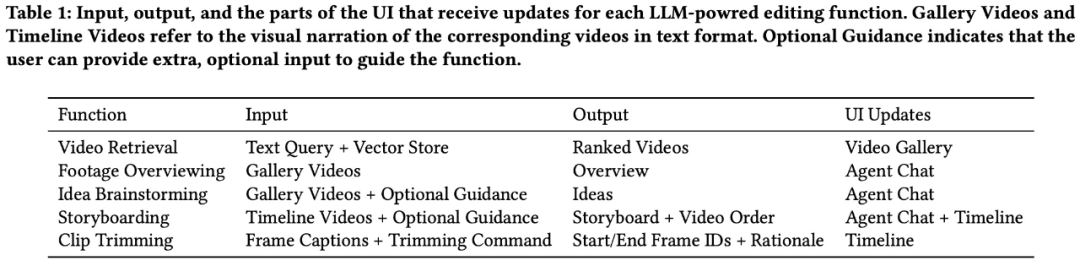
Pour aider les utilisateurs à effectuer les tâches de montage vidéo, LAVE prend principalement en charge cinq fonctions pilotées par LLM, notamment :
- Aperçu du matériel
- Brainstorming créatif
- Récupération vidéo
- Storyboard
- Découpage de clips
Les quatre premiers peuvent être accessible via l'agent (Figure 5), le La fonction de découpage de clip peut ouvrir une fenêtre contextuelle affichant des images d'une seconde en double-cliquant sur le clip dans la timeline (Figure 4).

Parmi eux, la récupération vidéo basée sur le langage est implémentée via une base de données de stockage vectoriel, et le reste est implémenté via l'ingénierie d'invite LLM. Toutes les fonctionnalités sont construites sur des descriptions verbales générées automatiquement des séquences originales, y compris des titres et des résumés pour chaque clip de la vidéothèque (Figure 3). L’équipe de recherche appelle les descriptions textuelles de ces vidéos narration visuelle.

Les lecteurs intéressés peuvent lire le texte original de l'article pour en savoir plus sur le contenu de la recherche.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
