
 Périphériques technologiques
IA
La technologie derrière l'explosion de Sora, un article résumant la dernière direction de développement des modèles de diffusion
Périphériques technologiques
IA
La technologie derrière l'explosion de Sora, un article résumant la dernière direction de développement des modèles de diffusion
La technologie derrière l'explosion de Sora, un article résumant la dernière direction de développement des modèles de diffusion

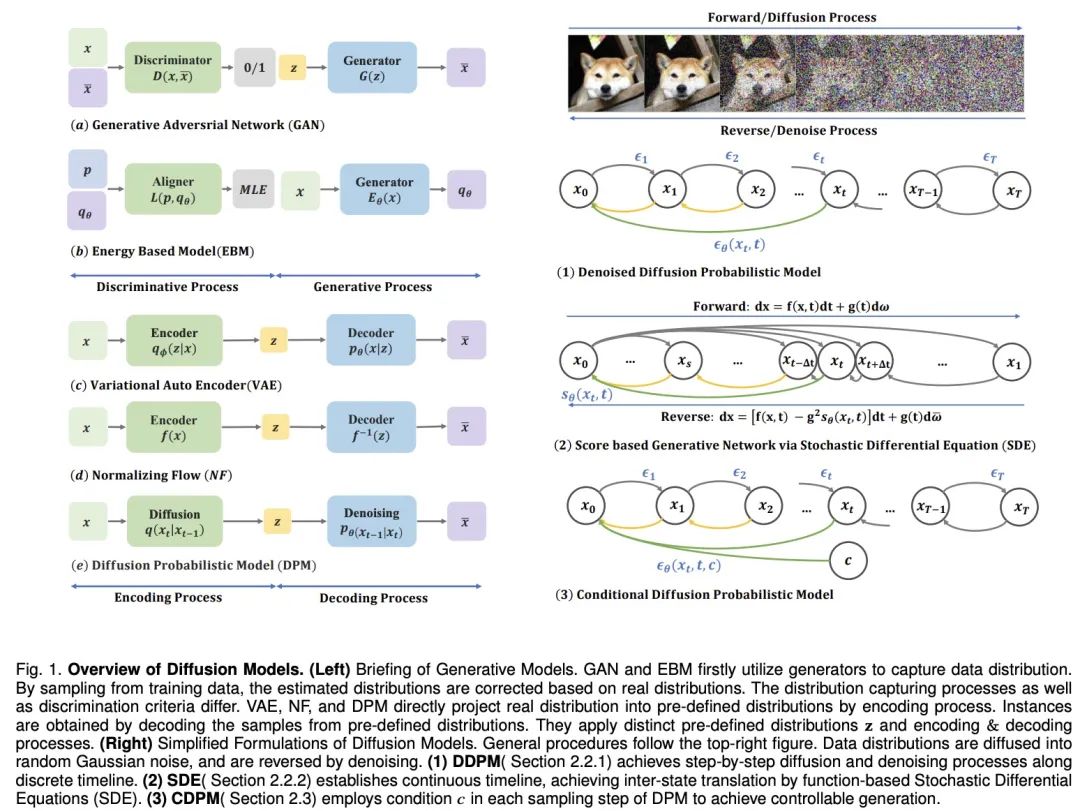

Adresse papier : https://arxiv.org/pdf/2209.02646.pdf Adresse du projet : https://github.com/chq1155/A-Survey-on-Generative-Diffusion-Model?tab= fichier readme-ov
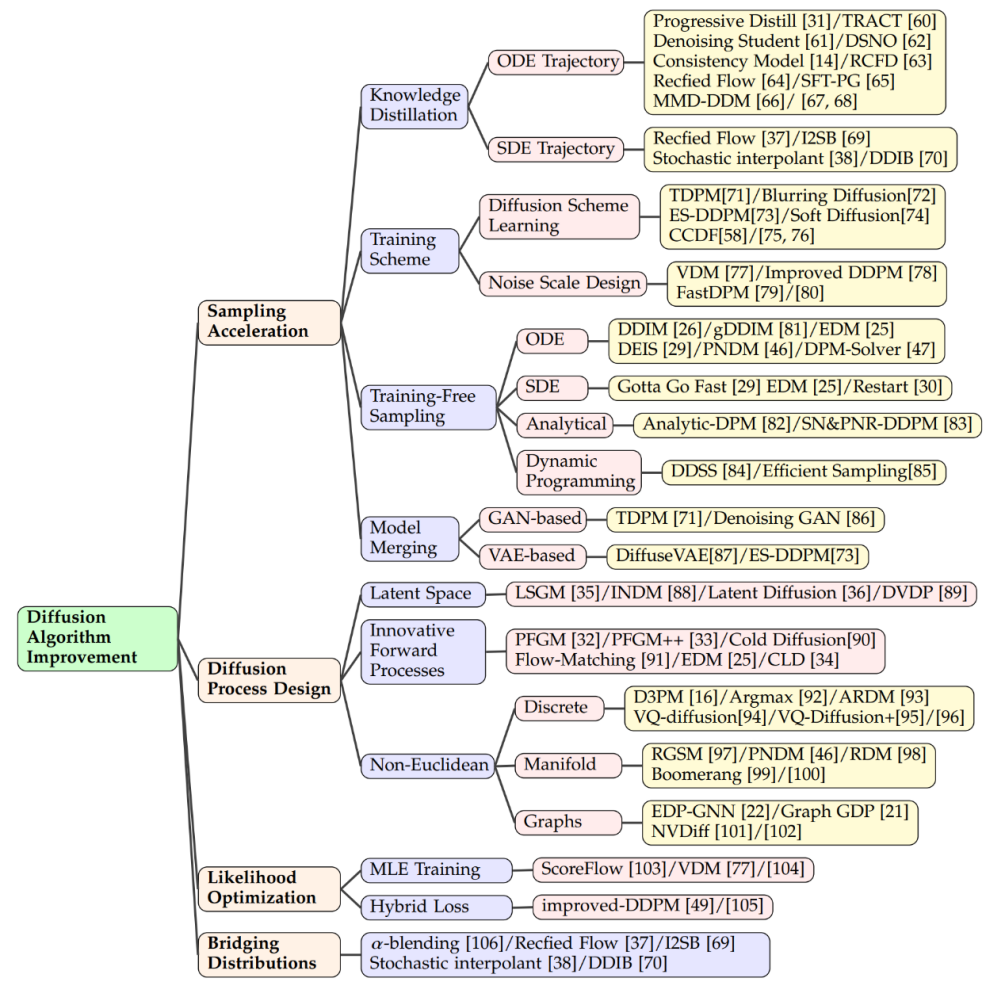
Distillation
Méthode de formation
Échantillonnage sans formation
Combinée avec d'autres modèles génératifs
Espace latent
Processus avancé innovant
Espace non euclidien
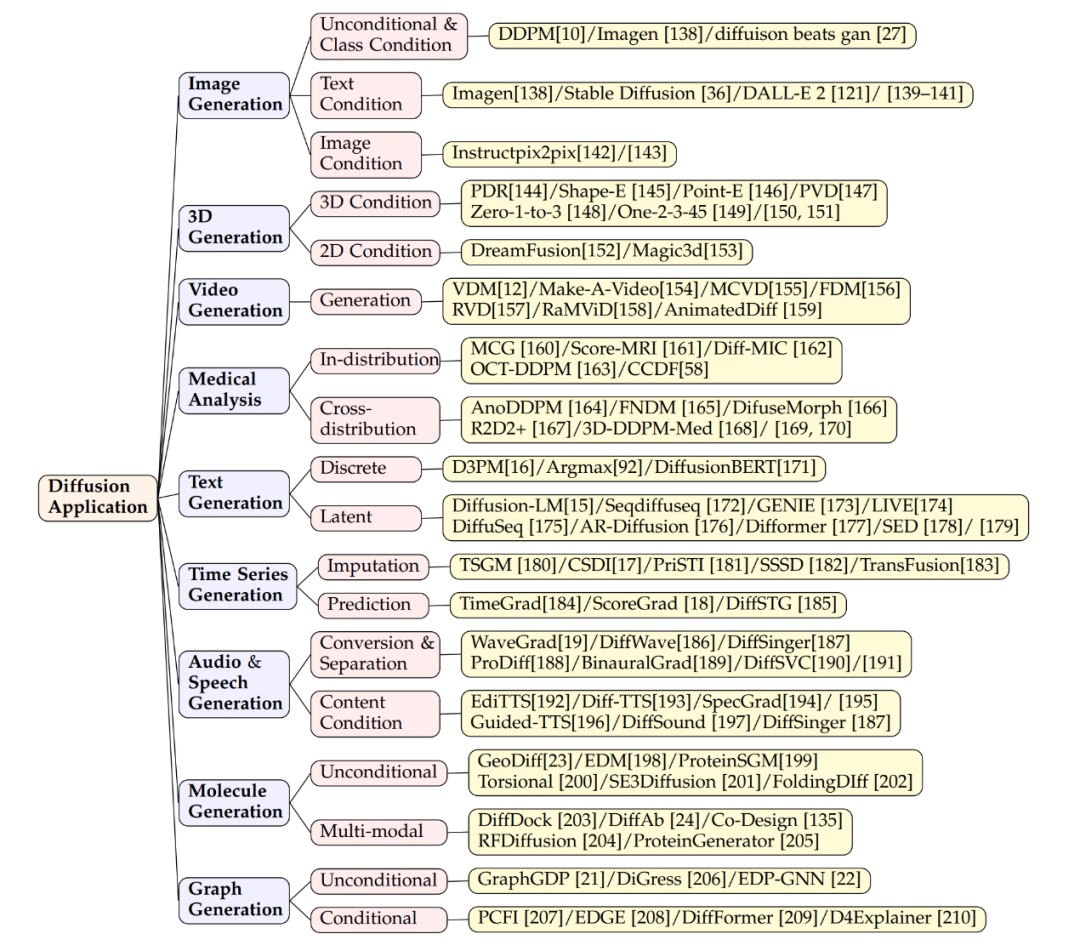
Kontrollierbare verteilungsbasierte Generierung
Erweiterte multimodale Generierung unter Verwendung großer Sprachmodelle
Integration mit dem Bereich des maschinellen Lernens
Feldanwendungsmethode (Anhang)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelles sont les dix principales plateformes de trading de devises virtuelles?
Feb 20, 2025 pm 02:15 PM
Quelles sont les dix principales plateformes de trading de devises virtuelles?
Feb 20, 2025 pm 02:15 PM
Avec la popularité des crypto-monnaies, des plateformes de trading de devises virtuelles ont émergé. Les dix principales plateformes de trading de devises virtuelles au monde sont classées comme suit selon le volume des transactions et la part de marché: Binance, Coinbase, FTX, Kucoin, Crypto.com, Kraken, Huobi, Gate.io, Bitfinex, Gemini. Ces plateformes offrent un large éventail de services, allant d'un large éventail de choix de crypto-monnaie à la négociation des dérivés, adapté aux commerçants de niveaux différents.
 Introduction aux types de devises PEPU
Dec 12, 2024 am 11:43 AM
Introduction aux types de devises PEPU
Dec 12, 2024 am 11:43 AM
PEPU Coin est un jeton ERC-20 basé sur la blockchain Ethereum, exploité par PEPU.io et utilisé comme jeton natif dans son application PEPU.
 Comment ajuster l'échange ouvert en sésame en chinois
Mar 04, 2025 pm 11:51 PM
Comment ajuster l'échange ouvert en sésame en chinois
Mar 04, 2025 pm 11:51 PM
Comment ajuster l'échange ouvert en sésame en chinois? Ce didacticiel couvre des étapes détaillées sur les ordinateurs et les téléphones mobiles Android, de la préparation préliminaire aux processus opérationnels, puis à la résolution de problèmes communs, vous aidant à changer facilement l'interface d'échange Open Sesame aux chinois et à démarrer rapidement avec la plate-forme de trading.
 Top 10 des plates-formes de trading de crypto-monnaie, les dix principales applications de plate-forme de trading de devises recommandées
Mar 17, 2025 pm 06:03 PM
Top 10 des plates-formes de trading de crypto-monnaie, les dix principales applications de plate-forme de trading de devises recommandées
Mar 17, 2025 pm 06:03 PM
Les dix principales plates-formes de trading de crypto-monnaie comprennent: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. BitFinex, 10. Gemini. La sécurité, la liquidité, les frais de traitement, la sélection des devises, l'interface utilisateur et le support client doivent être pris en compte lors du choix d'une plate-forme.
 Quelles sont les plates-formes de monnaie numérique sûres et fiables?
Mar 17, 2025 pm 05:42 PM
Quelles sont les plates-formes de monnaie numérique sûres et fiables?
Mar 17, 2025 pm 05:42 PM
Une plate-forme de monnaie numérique sûre et fiable: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. La sécurité, la liquidité, les frais de traitement, la sélection des devises, l'interface utilisateur et le support client doivent être pris en compte lors du choix d'une plate-forme.
 Top 10 des plates-formes de trading de devises virtuelles 2025 Applications de trading de crypto-monnaie classée top dix
Mar 17, 2025 pm 05:54 PM
Top 10 des plates-formes de trading de devises virtuelles 2025 Applications de trading de crypto-monnaie classée top dix
Mar 17, 2025 pm 05:54 PM
Top dix plates-formes de trading de devises virtuelles 2025: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. BitFinex, 10. Gemini. La sécurité, la liquidité, les frais de traitement, la sélection des devises, l'interface utilisateur et le support client doivent être pris en compte lors du choix d'une plate-forme.
 Laquelle des dix principales applications de trading de devises virtuelles est la meilleure?
Mar 19, 2025 pm 05:00 PM
Laquelle des dix principales applications de trading de devises virtuelles est la meilleure?
Mar 19, 2025 pm 05:00 PM
Top 10 des classements de trading de devises virtuels: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. BitFinex, 10. Gemini. La sécurité, la liquidité, les frais de traitement, la sélection des devises, l'interface utilisateur et le support client doivent être pris en compte lors du choix d'une plate-forme.
 Applications de logiciels de monnaie virtuels sûrs recommandés Top 10 des applications de trading de devises numériques classement 2025
Mar 17, 2025 pm 05:48 PM
Applications de logiciels de monnaie virtuels sûrs recommandés Top 10 des applications de trading de devises numériques classement 2025
Mar 17, 2025 pm 05:48 PM
Recommandés Applications logicielles de monnaie virtuelle recommandées: 1. Okx, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. La sécurité, la liquidité, les frais de traitement, la sélection des devises, l'interface utilisateur et le support client doivent être pris en compte lors du choix d'une plate-forme.
