

Dans le domaine de la détection de cibles, YOLOv9 continue de progresser dans le processus de mise en œuvre. En adoptant de nouvelles architectures et méthodes, il améliore efficacement l'utilisation des paramètres de la convolution traditionnelle, ce qui rend ses performances bien supérieures aux produits de la génération précédente.
Après la sortie officielle de YOLOv8 en janvier 2023, plus d'un an plus tard, YOLOv9 est enfin là !
Depuis que Joseph Redmon, Ali Farhadi et d'autres ont proposé le modèle YOLO de première génération en 2015, les chercheurs dans le domaine de la détection de cibles l'ont mis à jour et itéré à plusieurs reprises. YOLO est un système de prédiction basé sur des informations globales d'images et les performances de son modèle sont continuellement améliorées. En améliorant continuellement les algorithmes et les technologies, les chercheurs ont obtenu des résultats remarquables, rendant YOLO de plus en plus puissant dans les tâches de détection de cibles. Ces améliorations et optimisations continues ont apporté de nouvelles opportunités et de nouveaux défis au développement de la technologie de détection de cibles, tout en favorisant également le progrès et l'innovation dans ce domaine. Le succès de YOLO a également inspiré les chercheurs à poursuivre leurs efforts.
Cette fois, YOLOv9 a été développé conjointement par l'Academia Sinica de Taiwan, l'Université de technologie de Taipei et d'autres institutions. " est sorti.

Adresse papier : https://arxiv.org/pdf/2402.13616.pdf
Adresse GitHub : https://github.com/WongKinYiu/yolov9
Les méthodes d'apprentissage en profondeur d'aujourd'hui se concentrent sur la façon de concevoir le plus fonction objective appropriée, de sorte que les résultats de prédiction du modèle puissent être les plus proches de la situation réelle. Dans le même temps, une architecture appropriée doit être conçue pour permettre d’obtenir suffisamment d’informations pour la prédiction. Cependant, les méthodes existantes ignorent le fait qu’une grande quantité d’informations sera perdue lorsque les données d’entrée subiront une extraction de caractéristiques et une transformation spatiale couche par couche.
Par conséquent, YOLOv9 étudie en profondeur les problèmes importants de perte de données lorsque les données sont transmises via des réseaux profonds, à savoir les goulots d'étranglement de l'information et les fonctions réversibles.
Les chercheurs ont proposé le concept d'information de gradient programmable (PGI) pour faire face aux divers changements requis par les réseaux profonds pour atteindre plusieurs objectifs. PGI peut fournir des informations d'entrée complètes pour la tâche cible afin de calculer la fonction objectif, obtenant ainsi des informations de gradient fiables pour mettre à jour les pondérations du réseau.
De plus, les chercheurs ont conçu une nouvelle architecture de réseau légère basée sur la planification de chemins de gradient, à savoir le Réseau d'agrégation de couches efficace généralisé (GELAN). Cette architecture confirme que PGI peut obtenir d'excellents résultats sur des modèles légers.
Les chercheurs ont vérifié les GELAN et PGI proposés sur la tâche de détection de cible sur la base de l'ensemble de données MS COCO. Les résultats montrent que GELAN permet une meilleure utilisation des paramètres en utilisant uniquement des opérateurs de convolution traditionnels par rapport aux méthodes SOTA développées sur la base de convolutions profondes.
Pour le PGI, il est très adaptable et peut être utilisé sur différents modèles du léger au grand. Nous pouvons utiliser cela pour obtenir des informations complètes, permettant ainsi à un modèle formé à partir de zéro d'obtenir de meilleurs résultats qu'un modèle SOTA pré-entraîné à l'aide d'un grand ensemble de données. La figure 1 ci-dessous montre quelques résultats de comparaison.

Pour le nouveau YOLOv9, Alexey Bochkovskiy, qui a participé au développement de YOLOv7, YOLOv4, Scaled-YOLOv4 et DPT, en a fait l'éloge, affirmant que YOLOv9 est meilleur que n'importe quel détecteur d'objets à convolution ou à transformateur. . " semble être le nouveau détecteur d'objets en temps réel SOTA, avec son propre tutoriel de formation personnalisé. le chemin aussi.

Source : https://twitter.com/skalskip92/status/1760717291593834648
 Certains Les internautes « travailleurs » ont ajouté le support pip au modèle YOLOv9.
Certains Les internautes « travailleurs » ont ajouté le support pip au modèle YOLOv9. 
Dans les détails de YOLOV9. Énoncé du problème
Habituellement, les gens attribuent le problème de difficulté de convergence des
réseaux de neuronesprofonds à des facteurs tels que la disparition du gradient ou la saturation du gradient, et ces phénomènes existent dans les réseaux de neurones profonds traditionnels. Cependant, les
réseaux de neuronesprofonds modernes ont fondamentalement résolu les problèmes ci-dessus en concevant diverses fonctions de normalisation et d'activation. Mais même ainsi, il existe toujours des problèmes de vitesse de convergence lente ou de mauvais effet de convergence dans les réseaux neuronaux profonds. Alors, quelle est l’essence de ce problème ? Grâce à une analyse approfondie du goulot d'étranglement de l'information, les chercheurs ont déduit la cause profonde du problème : peu de temps après que le gradient soit initialement diffusé depuis le réseau très profond, une grande partie des informations nécessaires pour atteindre l'objectif est perdue. Pour vérifier cette inférence, les chercheurs ont effectué un traitement anticipatif sur des réseaux profonds de différentes architectures avec des poids initiaux. La figure 2 illustre cela visuellement. De toute évidence, PlainNet perd beaucoup d’informations importantes nécessaires à la détection d’objets dans les couches profondes. Quant à la proportion d'informations importantes que ResNet, CSPNet et GELAN peuvent retenir, elle est en effet positivement liée à la précision pouvant être obtenue après la formation. Les chercheurs ont en outre conçu une méthode basée sur des réseaux réversibles pour résoudre les causes des problèmes ci-dessus. Introduction à la méthode
Informations de gradient programmables (PGI)Cette étude propose un nouveau cadre de supervision auxiliaire : les informations de gradient programmables (PGI), comme le montre la figure 3 (d).
PGI comprend principalement trois parties, à savoir (1) branche principale, (2) branche auxiliaire réversible, (3) informations auxiliaires à plusieurs niveaux.
Le processus d'inférence de PGI utilise uniquement la branche principale, il n'y a donc pas de coût de raisonnement supplémentaire ;
Résultats expérimentaux
 Pour évaluer les performances de YOLOv9, cette étude a d'abord comparé de manière exhaustive YOLOv9 avec d'autres détecteurs d'objets en temps réel formés à partir de zéro, et les résultats sont présentés dans le tableau 1 ci-dessous.
Pour évaluer les performances de YOLOv9, cette étude a d'abord comparé de manière exhaustive YOLOv9 avec d'autres détecteurs d'objets en temps réel formés à partir de zéro, et les résultats sont présentés dans le tableau 1 ci-dessous. L'étude a également inclus le modèle pré-entraîné ImageNet dans la comparaison, et les résultats sont présentés dans la figure 5 ci-dessous. Il convient de noter que YOLOv9 utilisant la convolution traditionnelle est encore meilleur que YOLO MS utilisant une convolution profonde dans l'utilisation des paramètres.

Expériences d'ablation
 Afin d'explorer le rôle de chaque composant dans YOLOv9, cette étude a mené une série d'expériences d'ablation.
Afin d'explorer le rôle de chaque composant dans YOLOv9, cette étude a mené une série d'expériences d'ablation. Cette étude a d’abord mené une expérience d’ablation sur le bloc de calcul de GELAN. Comme le montre le tableau 2 ci-dessous, l'étude a révélé qu'en remplaçant les couches convolutives d'ELAN par différents blocs de calcul, le système maintenait de bonnes performances.
Ensuite, l'étude a mené des expériences d'ablation sur des GELAN de différentes tailles pour la profondeur du bloc ELAN et la profondeur du bloc CSP, et les résultats sont présentés dans le tableau 3 ci-dessous.
En termes de PGI, les chercheurs ont mené des études d'ablation sur les branches auxiliaires réversibles et des informations auxiliaires à plusieurs niveaux sur le réseau fédérateur et le cou respectivement. Le tableau 4 répertorie les résultats de toutes les expériences. Comme le montre le tableau 4, le PFH n'est efficace que pour les modèles profonds, tandis que le PGI proposé dans cet article peut améliorer la précision dans différentes combinaisons.

Les chercheurs ont en outre mis en œuvre la surveillance PGI et en profondeur sur des modèles de différentes tailles et ont comparé les résultats. Les résultats sont présentés dans le tableau 5.

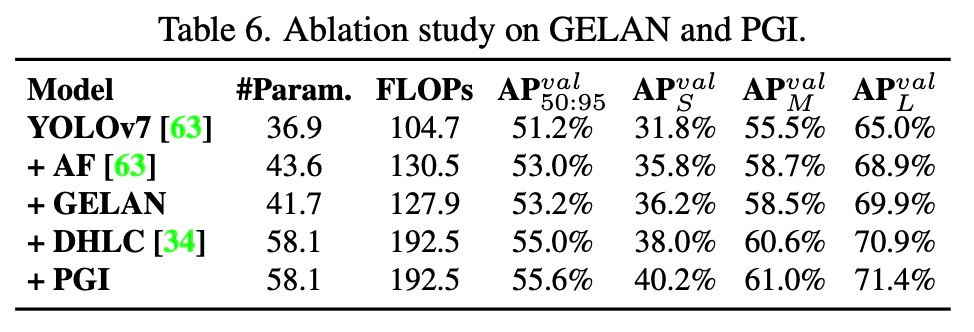
La figure 6 montre les résultats de l'ajout progressif de composants de la ligne de base YOLOv7 à YOLOv9-E.
Visualisation
Les chercheurs ont exploré le problème du goulot d'étranglement de l'information et l'ont visualisé. La figure 6 montre les résultats de visualisation des cartes de caractéristiques obtenues en utilisant des poids initiaux aléatoires comme rétroaction sous différentes architectures.

La figure 7 montre si PGI peut fournir des gradients plus fiables pendant l'entraînement, afin que les paramètres utilisés pour la mise à jour puissent capturer efficacement la relation entre les données d'entrée et la cible.

Pour plus de détails techniques, veuillez lire l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 utilisation de l'épissure
utilisation de l'épissure
 Comment supprimer des données dans MongoDB
Comment supprimer des données dans MongoDB
 Que diriez-vous de l'échange MEX
Que diriez-vous de l'échange MEX
 serveur Web
serveur Web
 La différence entre vscode et vs
La différence entre vscode et vs
 Quelles versions du système Linux existe-t-il ?
Quelles versions du système Linux existe-t-il ?
 Quelles sont les principales technologies de pare-feux ?
Quelles sont les principales technologies de pare-feux ?
 Que signifient les caractères pleine chasse ?
Que signifient les caractères pleine chasse ?
 La différence entre mysql et sql_server
La différence entre mysql et sql_server








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



