
 Périphériques technologiques
IA
Conception et mise en œuvre d'un cadre d'inférence LLM haute performance
Périphériques technologiques
IA
Conception et mise en œuvre d'un cadre d'inférence LLM haute performance
Conception et mise en œuvre d'un cadre d'inférence LLM haute performance


1. Présentation de l'inférence de grands modèles de langage
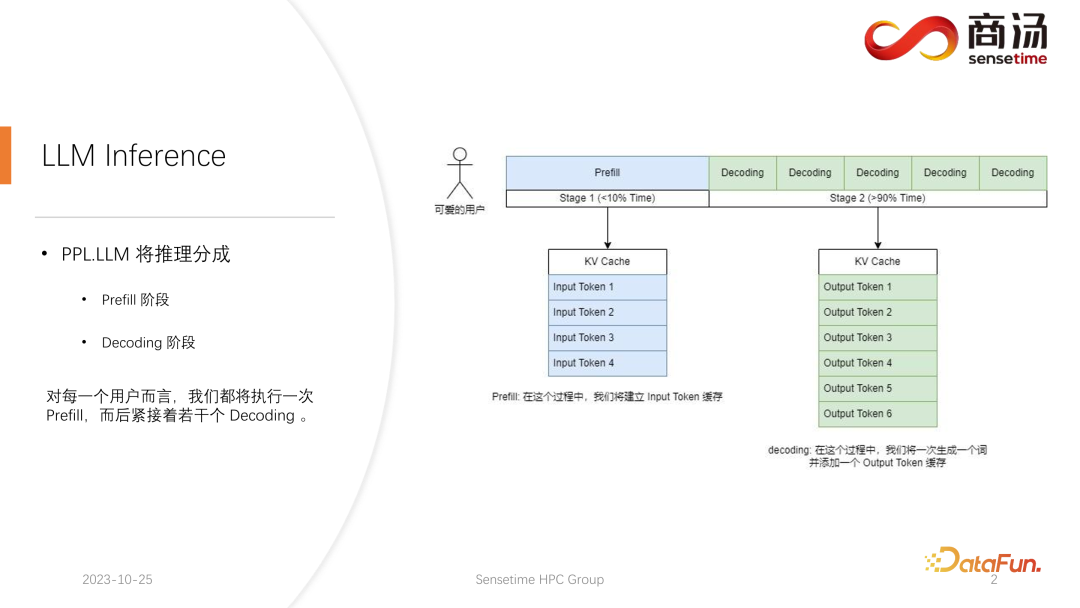
Différente de l'inférence de modèle CNN traditionnelle, l'inférence de grands modèles de langage est généralement divisée en deux étapes : le pré-remplissage et le décodage. Le processus de raisonnement généré après le lancement de chaque requête passera d'abord par un processus de pré-remplissage. Le processus de pré-remplissage calculera toutes les entrées de l'utilisateur et générera le cache KV correspondant. Il passera ensuite par plusieurs processus de décodage. Pour chaque processus de décodage, le serveur effectuera. générer un caractère et le mettre dans le cache KV, puis itérer en séquence.
Le processus de décodage étant généré caractère par caractère, la génération de chaque fragment de réponse prend beaucoup de temps et génère un grand nombre de caractères. Par conséquent, le nombre d’étapes de décodage est très important, représentant la majeure partie du processus de raisonnement, dépassant 90 %.
Dans le processus de pré-remplissage, bien que de nombreux calculs doivent être effectués car tous les mots saisis par l'utilisateur doivent être calculés en même temps, il ne s'agit que d'un processus unique. Par conséquent, le pré-remplissage ne représente que moins de 10 % du temps dans l’ensemble du processus d’inférence.
Dans l'inférence de modèle linguistique à grande échelle, il y a généralement quatre mesures clés sur lesquelles se concentrer : le débit, la latence du premier mot, la latence globale et les requêtes par seconde (QPS). Ces indicateurs de performance évaluent les capacités de service du système sous différents angles. Le débit mesure la rapidité et l'efficacité avec lesquelles un système traite les requêtes, tandis que la latence du premier mot fait référence au temps nécessaire au système pour générer son premier jeton. La latence globale est le temps nécessaire au système pour terminer l'intégralité de la tâche d'inférence. Enfin, QPS représente le nombre de requêtes traitées par le système par seconde. Ces métriques jouent un rôle clé dans l'évaluation des performances du modèle et de l'optimisation du système, contribuant ainsi à garantir que le système peut gérer efficacement diverses tâches d'inférence.
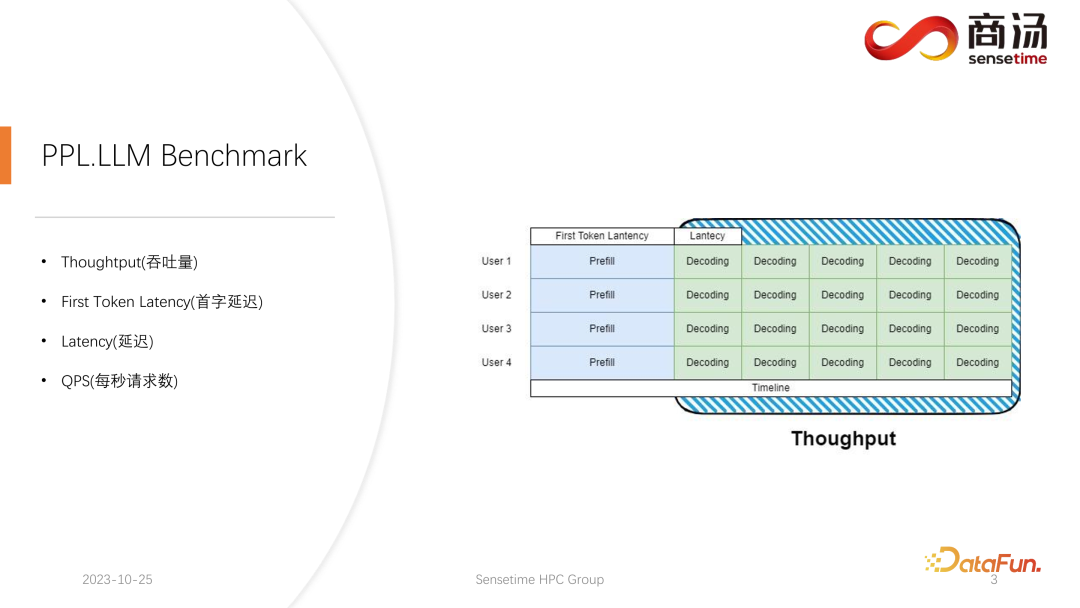
Tout d’abord, présentons le débit. Du point de vue de l'inférence du modèle, la première chose sur laquelle se concentrer est le débit. Le débit fait référence au nombre de décodages pouvant être effectués par unité de temps lorsque la charge du système atteint son maximum, c'est-à-dire au nombre de caractères générés. La façon de tester le débit est de supposer que tous les utilisateurs arriveront en même temps, et que ces utilisateurs poseront la même question, que ces utilisateurs peuvent commencer et terminer en même temps, et la longueur du texte qu'ils génèrent et la longueur de le texte saisi est le même. Un lot complet est formé en utilisant exactement la même entrée. Dans ce cas, le débit du système est maximisé. Mais cette situation est irréaliste, il s’agit donc d’un maximum théorique. Nous mesurons combien d’étapes de décodage indépendantes le système peut effectuer en une seconde.
Un autre indicateur clé est la latence du premier jeton, qui est le temps qu'il faut à un utilisateur pour terminer la phase de pré-remplissage après être entré dans le système d'inférence. Il s'agit du temps de réponse du système pour générer le premier caractère. De nombreux utilisateurs s'attendent à recevoir une réponse dans les 2 à 3 secondes après avoir saisi une question dans le système.
Une autre mesure importante est la latence. La latence représente le temps requis pour chaque opération de décodage, qui reflète l'intervalle de temps requis pour qu'un grand système de modèle de langage génère chaque caractère pendant le traitement en temps réel, ainsi que la fluidité du processus de génération. En règle générale, nous souhaitons que la latence reste inférieure à 50 millisecondes, ce qui signifie que nous pouvons générer 20 caractères par seconde. De cette façon, le processus de génération de grands modèles de langage sera plus fluide.
La dernière métrique est le QPS (requêtes par seconde). Il reflète le nombre de demandes d'utilisateurs qui peuvent être traitées en une seconde dans les services système en ligne. La méthode de mesure de cet indicateur est relativement complexe et sera présentée ultérieurement.
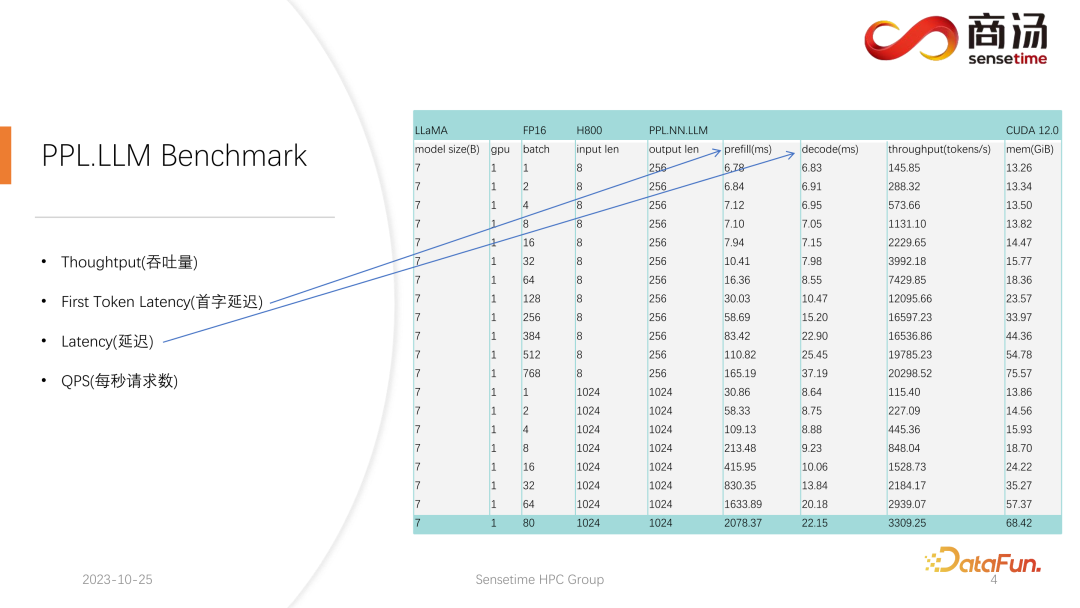
Nous avons effectué des tests relativement complets sur les indicateurs First Token Latency et Latency. Ces deux indicateurs changeront considérablement en raison des différentes longueurs de saisie des utilisateurs et des différentes tailles de lots.
Comme vous pouvez le voir dans le tableau ci-dessus, pour le même modèle 7B, si la longueur de saisie de l'utilisateur passe de 8 à 2048, le temps de pré-remplissage passera de 6,78 millisecondes jusqu'à ce qu'il devienne 2078 millisecondes, soit 2 secondes. S'il y a 80 utilisateurs et que chaque utilisateur saisit 1 024 mots, l'exécution du pré-remplissage sur le serveur prendra environ 2 secondes, ce qui est au-delà de la plage acceptable. Mais si la longueur de saisie de l'utilisateur est très courte, par exemple, seuls 8 mots sont saisis par visite, même si 768 utilisateurs arrivent en même temps, le délai du premier mot ne sera qu'environ 165 millisecondes.
La chose la plus pertinente pour le délai du premier mot est la longueur de saisie de l'utilisateur. Plus la longueur de saisie de l'utilisateur est longue, plus le délai du premier mot sera élevé. Si la longueur de saisie de l'utilisateur est courte, le retard du premier mot ne deviendra pas un goulot d'étranglement dans l'ensemble du processus d'inférence du grand modèle de langage.
Quant au délai de décodage ultérieur, généralement tant qu'il ne s'agit pas d'un modèle de niveau 100 milliards, le délai de décodage sera contrôlé dans les 50 millisecondes. Cela dépend principalement de la taille du lot. Plus la taille du lot est grande, plus le délai d'inférence sera grand, mais fondamentalement, l'augmentation ne sera pas très élevée.
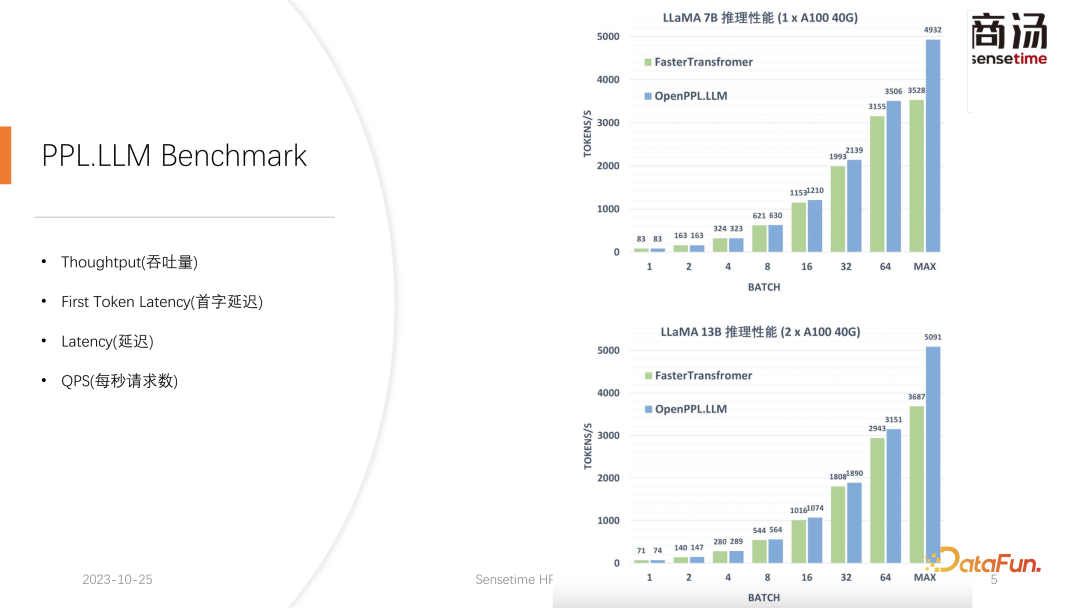
Le débit sera en réalité affecté par ces deux facteurs. Si la longueur de l’entrée utilisateur et la longueur générée sont très longues, le débit du système ne sera pas très élevé. Si la longueur saisie par l'utilisateur et la longueur générée ne sont pas très longues, le débit du système peut atteindre un niveau très ridicule.
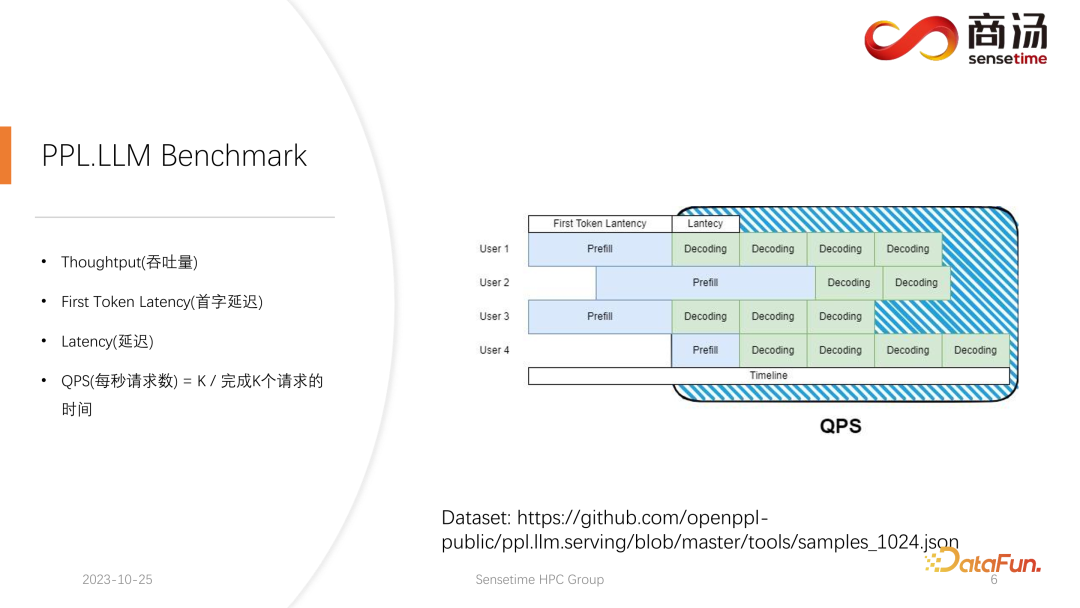
Regardons à nouveau QPS. QPS est une métrique très spécifique qui indique le nombre de requêtes par seconde que le système peut gérer. Lors de la réalisation de ce test, nous utiliserons des données réelles. (Nous avons déjà échantillonné ces données et les avons mises sur github.)
La mesure QPS est différente du débit, car lorsqu'un grand système de modèle de langage est réellement utilisé, chaque utilisateur vient Le moment est incertain. Certains utilisateurs peuvent arriver en avance, d'autres en retard, et la durée de la génération après que chaque utilisateur a terminé le pré-remplissage est également incertaine. Certains utilisateurs peuvent quitter après avoir généré 4 mots, tandis que d'autres devront peut-être générer plus de 20 mots.
Dans l'étape de pré-remplissage, dans l'inférence en ligne réelle, parce que les utilisateurs génèrent réellement des longueurs différentes, ils rencontreront un problème : certains utilisateurs le généreront à l'avance, tandis que d'autres ne termineront pas avant d'avoir généré beaucoup de longueur. Lors d’une construction comme celle-ci, il existe de nombreux endroits où le GPU sera inactif. Par conséquent, dans le processus d’inférence réel, notre QPS ne peut pas tirer pleinement parti du débit. Notre débit est peut-être élevé, mais la puissance de traitement réelle peut être faible car le traitement est plein de trous qui ne peuvent pas utiliser la carte graphique. Par conséquent, en termes d'indicateur QPS, nous aurons de nombreuses solutions d'optimisation spécifiques pour éviter les trous de calcul ou l'impossibilité d'utiliser efficacement la carte graphique, afin que le débit puisse pleinement servir les utilisateurs.
2. Optimisation des performances d'inférence du grand modèle de langage
Ensuite, entrez dans le processus d'inférence du grand modèle de langage pour voir quelles optimisations nous avons effectuées pour que le système obtienne des résultats comparables en termes de QPS et de débit et autres indicateurs. Excellente situation.
1. Processus d'inférence LLM
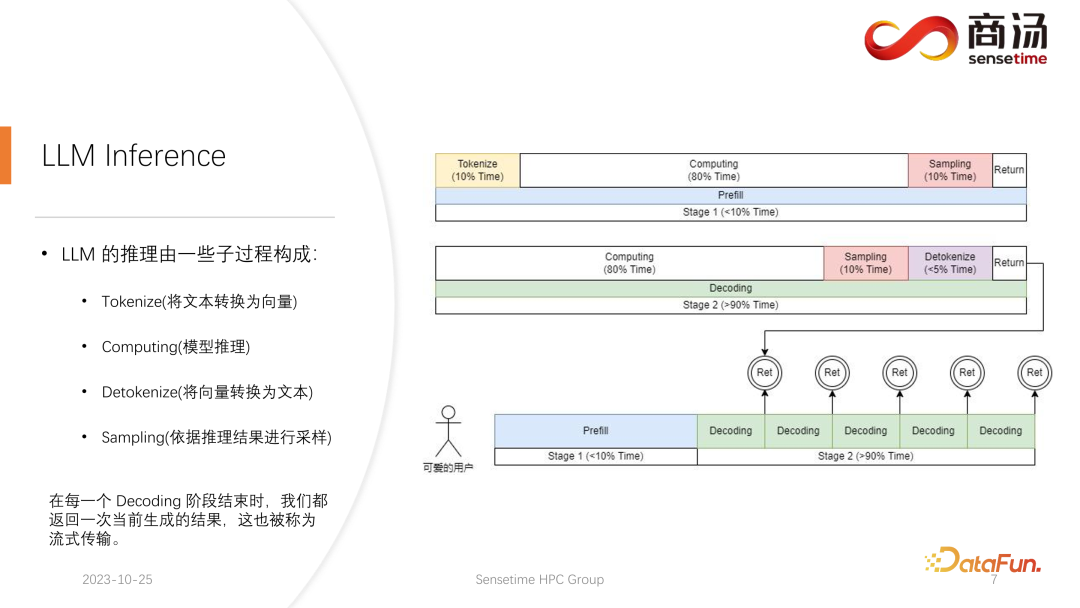
Tout d'abord, présentons en détail le processus d'inférence du grand modèle de langage Comme mentionné dans l'article précédent, chaque requête doit passer par les deux étapes de pré-remplissage et de décodage. . Lors de l'étape de pré-remplissage, au moins quatre choses doivent être faites :
La première chose est de vectoriser la saisie de l'utilisateur. Le processus de tokenisation fait référence à la conversion du texte saisi par l'utilisateur en un vecteur par rapport à l'ensemble du pré-remplissage. étape, cela prend probablement 10 % du temps, cela a un coût.
Le calcul de pré-remplissage proprement dit sera ensuite effectué, et ce processus prendra environ 80 % du temps.
Après le calcul, un échantillonnage sera effectué. Ce processus utilise généralement sample et top p dans Pytorch. Argmax est utilisé dans l'inférence de grands modèles de langage. Dans l’ensemble, il s’agit d’un processus permettant de générer le mot final basé sur les résultats du modèle. Ce processus prend 10 % du temps.
Enfin, le résultat de la recharge est renvoyé au client, ce qui prend un temps relativement court, environ 2% à 5% du temps.
L'étape de décodage ne nécessite pas de tokenisation. Chaque fois que vous effectuez un décodage, il démarre directement du calcul. L'ensemble du processus de décodage prendra 80 % du temps, ainsi que l'échantillonnage ultérieur, qui est le processus d'échantillonnage et de génération de mots. , prendra également 10% du temps. Mais cela prendra un temps de détokenisation. Detokenize signifie qu'une fois qu'un mot est généré, le mot généré est un vecteur et doit être décodé en texte. Cette opération prendra environ 5 % du temps. être Retour à l'utilisateur.
Lorsqu'une nouvelle demande arrive, après pré-remplissage, le décodage sera effectué de manière itérative. Après chaque étape de décodage, les résultats seront restitués sur place au client. Ce processus de génération est très courant dans les grands modèles de langage, et nous appelons cette méthode streaming.
2. Optimisation : pré- et post-traitement du pipeline et échantillonnage haute performance
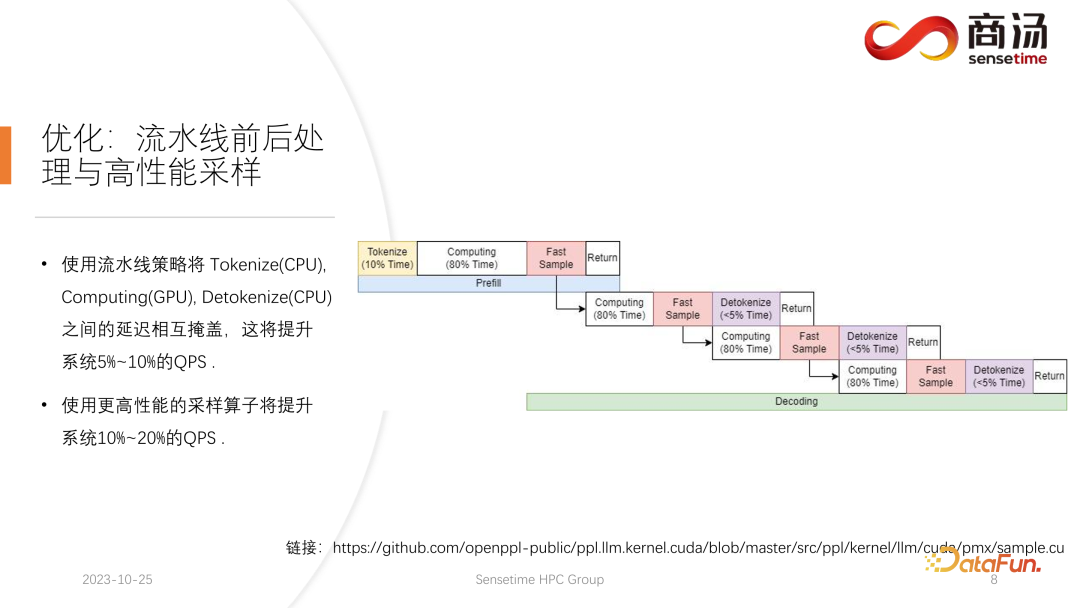
La première optimisation introduite ici est l'optimisation du pipeline, dont le but est de maximiser l'utilisation de la carte graphique.
Dans le processus d'inférence d'un grand modèle de langage, les processus de tokenisation, d'échantillonnage rapide et de détokenisation n'ont rien à voir avec le calcul du modèle. Nous pouvons imaginer le raisonnement de l'ensemble du grand modèle de langage comme un tel processus. Pendant le processus d'exécution du pré-remplissage, après avoir obtenu le vecteur de mots de l'échantillon rapide, je peux immédiatement commencer l'étape suivante du décodage sans attendre le résultat. renvoyé, car le résultat a déjà été sur le GPU. Lorsqu'un décodage est terminé, il n'est pas nécessaire d'attendre la fin de la détokenisation et le décodage suivant peut être démarré immédiatement. Étant donné que la détokenisation est un processus CPU, les deux derniers processus impliquent uniquement le retour des résultats à l'utilisateur et n'impliquent aucune opération GPU. Et après avoir exécuté le processus d'échantillonnage, nous savons déjà quel est le prochain mot généré. Nous avons obtenu toutes les données dont nous avons besoin et pouvons commencer immédiatement l'opération suivante sans attendre la fin des deux processus suivants.
Trois pools de threads sont utilisés dans l'implémentation de PPL.LLM :
Le premier pool de threads est responsable de l'exécution du processus de tokenisation
Le troisième pool de threads est responsable de l'exécution de l'échantillon rapide suivant ; renvoyer les résultats Le processus et détokenize;
Le pool de threads au milieu est utilisé pour exécuter le processus informatique.
Ces trois pools de threads isolent de manière asynchrone ces trois parties de retard les unes des autres, masquant ainsi autant que possible ces trois parties de retard. Cela apportera une amélioration de 10 à 20 % du QPS au système, ce qui est la première optimisation que nous effectuons.
3. Optimisation : Traitement par lots dynamique
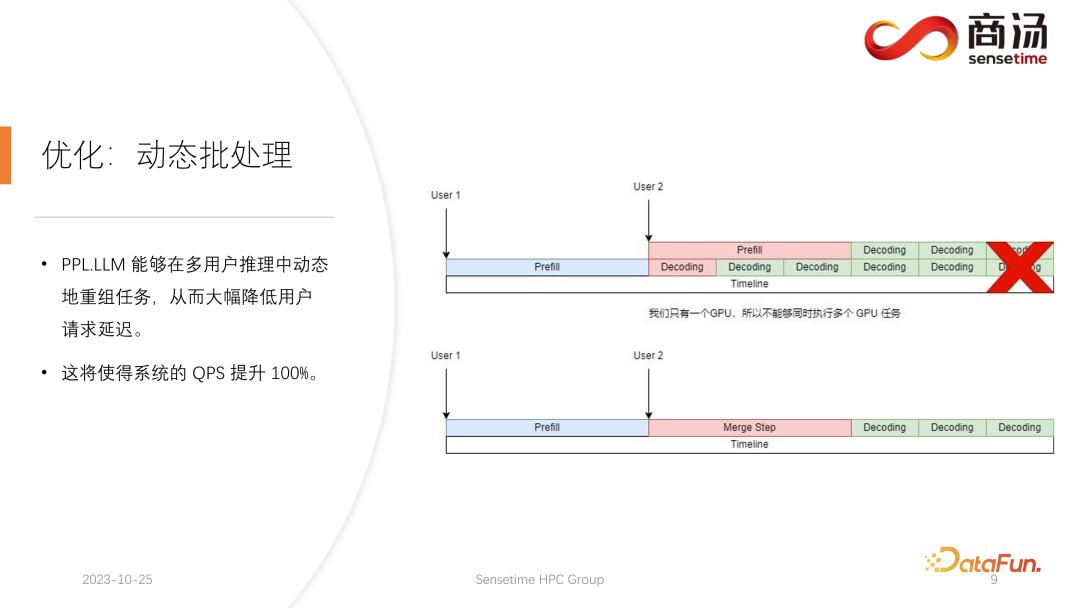
Après cela, PPL.LLM peut également effectuer une optimisation plus intéressante appelée traitement par lots dynamique.
Comme mentionné dans l'article précédent, dans le processus de raisonnement réel, la durée de génération de l'utilisateur est différente et l'heure d'arrivée de l'utilisateur est également différente. Par conséquent, il y aura une situation où si le GPU actuel est dans le processus d'inférence, il y a déjà une demande d'inférence en ligne. À mi-chemin de l'inférence, une deuxième requête est insérée. À ce moment, le processus de génération de la deuxième requête sera inséré. Conflits avec le processus de génération de la première requête. Étant donné que nous n'avons qu'un seul GPU et que nous ne pouvons exécuter des tâches qu'en série sur ce GPU, nous ne pouvons pas simplement les paralléliser sur le GPU.
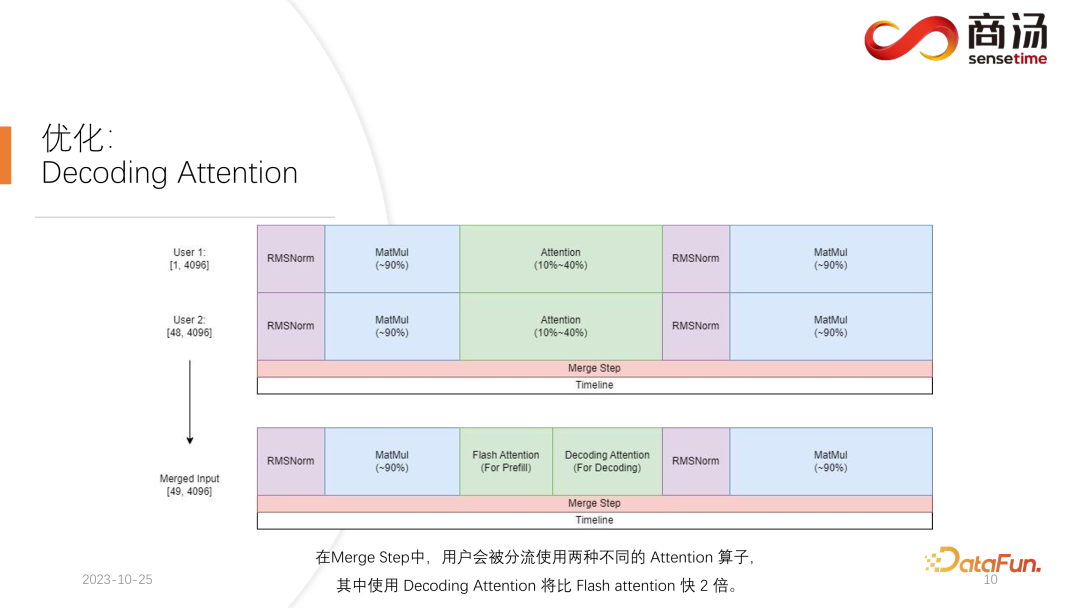
Ce que nous faisons, c'est, au moment où la deuxième requête arrive, mélanger sa phase de pré-remplissage avec la phase de décodage correspondant à la première requête, et générer une nouvelle phase appelée Merge Step. Dans cette étape de fusion, non seulement le décodage de la première requête sera effectué, mais le pré-remplissage de la deuxième requête sera également effectué. Cette fonctionnalité existe dans de nombreux systèmes d'inférence de grands modèles de langage et sa mise en œuvre a augmenté le QPS des grands modèles de langage de 100 %.
Le processus spécifique est que le processus de génération de la première requête est à mi-chemin, ce qui signifie qu'elle aura une entrée de longueur 1 lors du décodage, tandis que la deuxième requête est nouvellement saisie et est en cours de pré-remplissage. être une entrée de longueur 48. En épissant ces deux entrées l'une sur l'autre le long de la première dimension, la longueur de l'entrée épissée est de 49 et la dimension cachée est l'entrée de 4096. Dans cette entrée de longueur 49, le premier mot est demandé en premier et les 48 mots restants sont demandés en second.
Car dans le raisonnement sur grands modèles, les opérateurs qu'il faut expérimenter, comme RMSNorm, multiplication matricielle et attention, ont la même structure qu'ils soient utilisés pour le décodage ou le pré-remplissage. Par conséquent, l'entrée épissée peut être directement insérée dans l'ensemble du réseau et exécutée. Nous n’avons besoin de différencier qu’en un seul endroit, et c’est l’attention. Pendant le processus d'attention ou pendant l'exécution de l'opérateur d'auto-attention, nous effectuerons un shunt de données, shunterons toutes les requêtes de décodage en une seule vague, shunterons toutes les requêtes de pré-remplissage vers une autre vague et exécuterons deux opérations différentes. Toutes les requêtes de pré-remplissage exécuteront Flash Attention ; tous les utilisateurs de décodage exécuteront un opérateur très spécial appelé Decoding Attention. Une fois l'opérateur d'attention exécuté séparément, ces entrées utilisateur seront à nouveau regroupées pour compléter le calcul des autres opérateurs.
Pour l'étape de fusion, en fait, lorsque chaque demande arrive, nous fusionnerons cette demande avec l'entrée de toutes les demandes actuellement sur le système, terminerons ce calcul, puis continuerons à le décoder, ce qui est le cas. implémentation du traitement dynamique par lots dans de grands modèles de langage.
4. Optimisation : Décodage de l'attention
L'opérateur Decoding Attention n'est pas aussi connu que l'opérateur Flash Attention, mais il est en fait beaucoup plus rapide que Flash Attention dans le traitement des tâches de décodage.
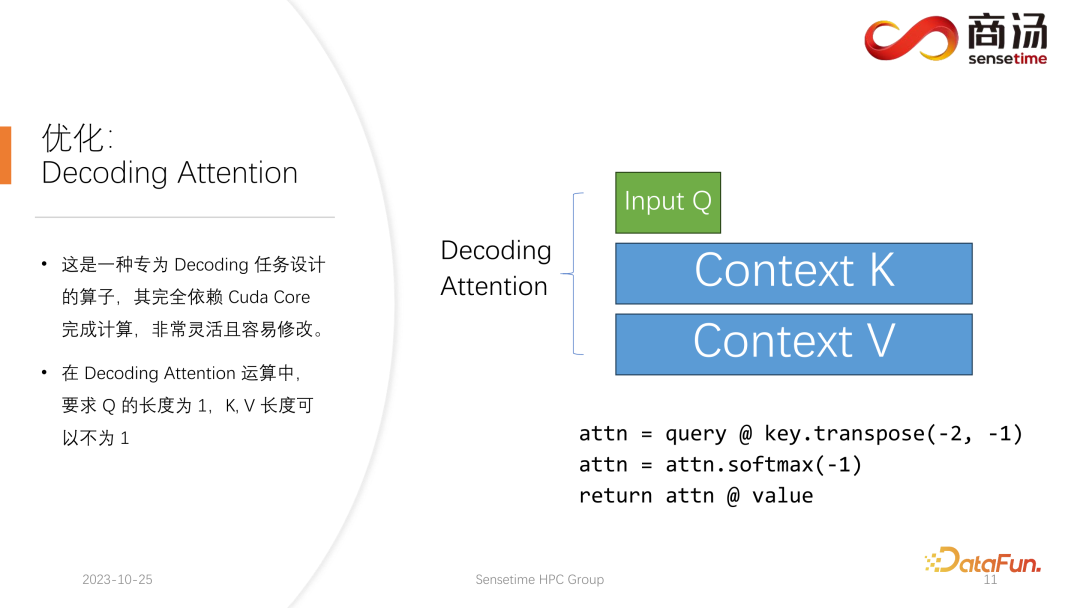
Il s'agit d'un opérateur spécialement conçu pour les tâches de décodage. Il s'appuie entièrement sur Cuda Core et ne s'appuie pas sur Tensor Core pour effectuer les calculs. Il est très flexible et facile à modifier, mais il a une limitation, car sa caractéristique réside dans l'opération de décodage du tenseur, il nécessite donc que la longueur de l'entrée q soit 1, mais les longueurs de k et v sont variables. Il s'agit d'une limitation de Decoding Attention. Sous cette limitation, nous pouvons effectuer certaines optimisations spécifiques.

Cette optimisation spécifique rend la mise en œuvre de l'opérateur attention dans l'étape de décodage plus rapide que Flash Attention. Cette implémentation est désormais open source et vous pouvez la visiter à l'URL dans l'image ci-dessus.
5. Optimisation : VM Allocator
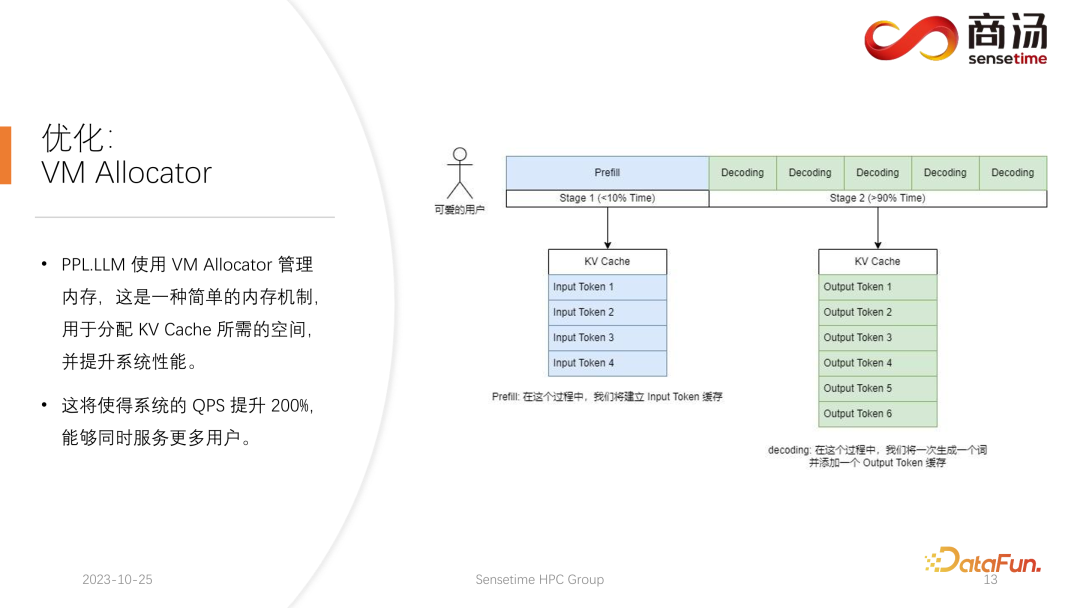
Une autre optimisation est Virtual Memory Allocator, correspondant à l'optimisation Page Attention. Lorsqu'une requête arrive, elle passe par la phase de pré-remplissage et la phase de décodage. Tous ses jetons d'entrée généreront un cache KV. Ce cache KV enregistre toutes les informations historiques de cette requête. Alors, quelle quantité d’espace de cache KV doit être allouée à une telle requête pour la satisfaire et terminer cette tâche de génération ? Si elle est trop divisée, la mémoire vidéo sera gaspillée. Si elle est trop peu divisée, elle atteindra la position de coupure du cache KV pendant la phase de décodage et il n'y aura aucun moyen de continuer à la générer.
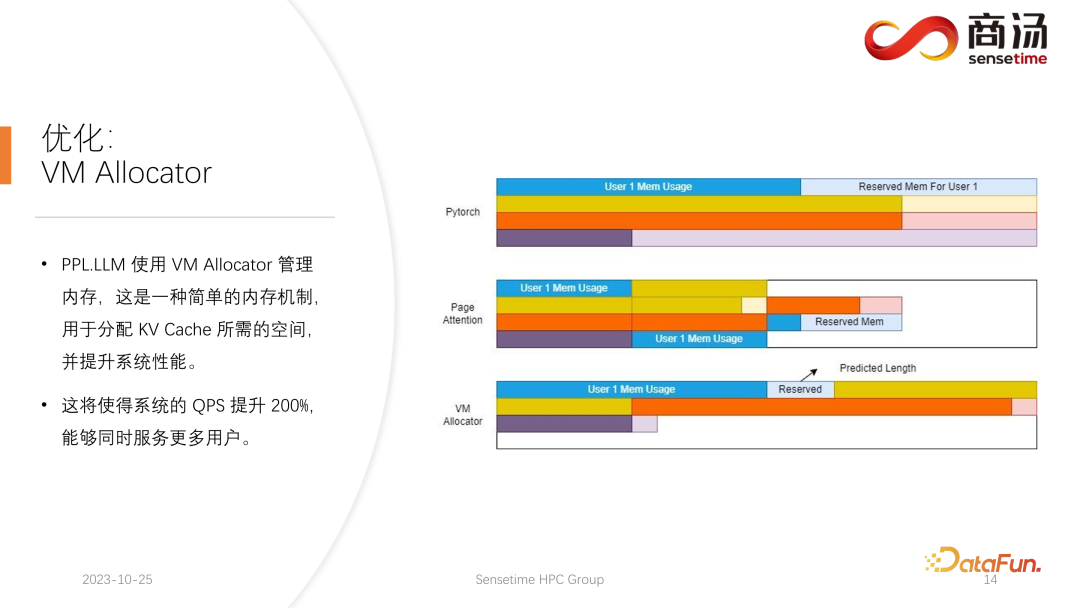
Pour résoudre ce problème, il existe 3 solutions.
La méthode de gestion de la mémoire de Pytorch consiste à réserver un espace suffisamment long pour chaque requête, généralement 2048 ou 4096, afin de garantir que 4096 mots sont générés. Mais la longueur réelle générée par la plupart des utilisateurs ne sera pas si longue, donc beaucoup d'espace mémoire sera gaspillé.
Page Attention utilise une autre méthode de gestion de la mémoire vidéo. Permet à l'utilisateur d'ajouter continuellement de la mémoire vidéo pendant le processus de génération. Semblable au stockage de pagination ou à la pagination de la mémoire dans le système d'exploitation. Lorsqu'une requête arrive, le système alloue un petit morceau de mémoire vidéo pour la requête. Ce petit morceau de mémoire vidéo est généralement suffisant pour générer 8 caractères. Lorsque la requête génère 8 caractères, le système ajoute un morceau de mémoire vidéo. , et le résultat peut être réutilisé lors de l'écriture dans cette mémoire vidéo, le système maintiendra une liste chaînée entre le bloc de mémoire vidéo et le bloc de mémoire vidéo, afin que l'opérateur puisse sortir normalement. Lorsque la longueur générée continue de croître, l'utilisateur continuera à se voir attribuer des blocs de mémoire vidéo supplémentaires, et la liste des allocations de blocs de mémoire vidéo peut être maintenue de manière dynamique, de sorte que le système n'ait pas une grande quantité de ressources gaspillées et n'ait pas besoin pour réserver trop de mémoire vidéo pour cette demande.
PPL.LLM utilise le mécanisme de gestion de la mémoire virtuelle pour prédire la longueur de génération requise pour chaque requête. Après l'arrivée de chaque requête, un espace continu lui sera directement alloué et la longueur de cet espace continu est prédite. Cependant, cela peut être difficile à réaliser en théorie, notamment lors de la phase de raisonnement en ligne. Il est impossible de savoir clairement combien de temps le contenu sera généré pour chaque requête. Nous recommandons donc de former un modèle pour ce faire. Car même si nous adoptons un modèle comme Page Attention, nous rencontrerons toujours des problèmes. Page Attention Pendant le processus en cours, à un moment donné par exemple, il y a déjà quatre requêtes sur le système actuel, et il reste encore 6 blocs de mémoire vidéo dans le système qui n'ont pas été alloués. À l'heure actuelle, nous n'avons aucun moyen de savoir si de nouvelles demandes arriveront et si nous pouvons continuer à leur fournir des services, car les quatre demandes actuelles ne sont pas encore terminées et de nouveaux blocs de mémoire vidéo pourraient continuer à y être ajoutés. l'avenir. Ainsi, même avec le mécanisme Page Attention, il est toujours nécessaire de prédire la durée réelle de génération de chaque utilisateur. Ce n'est qu'ainsi que nous pourrons savoir si nous pouvons accepter la contribution d'un nouvel utilisateur à un moment précis.
C'est quelque chose qu'aucun de nos systèmes de raisonnement actuels ne peut faire, y compris PPL. Cependant, le mécanisme de gestion de la mémoire virtuelle nous permet toujours d'éviter dans une large mesure le gaspillage de mémoire vidéo, augmentant ainsi le QPS global du système à environ 200 %.
6. Optimisation : quantification du cache KV
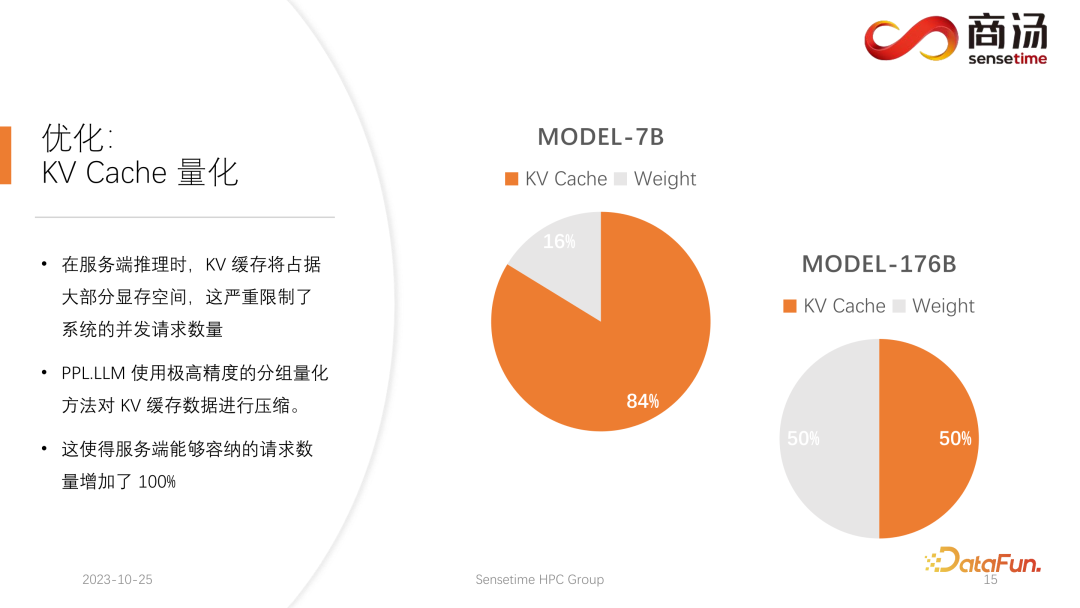
Une autre optimisation effectuée par PPL.LLM est la quantification du cache KV dans le processus d'inférence côté serveur, le cache KV occupera la grande majorité. espace mémoire vidéo, ce qui limitera considérablement le nombre de requêtes simultanées sur le système.
Vous pouvez constater que lors de l'exécution d'un grand modèle de langage tel que le modèle 7B sur le serveur, notamment sur les serveurs avec une grande mémoire comme A100 et H100, son cache KV occupera 84% de l'espace mémoire. , et pour les gros modèles comme le 176B, dont le cache KV occupera également plus de 50 % de l'espace cache. Cela limitera considérablement le nombre de concurrences du modèle. Après l'arrivée de chaque requête, une grande quantité de mémoire vidéo doit lui être allouée. De cette manière, le nombre de requêtes ne peut pas être augmenté, et donc le QPS et le débit ne peuvent pas être améliorés.
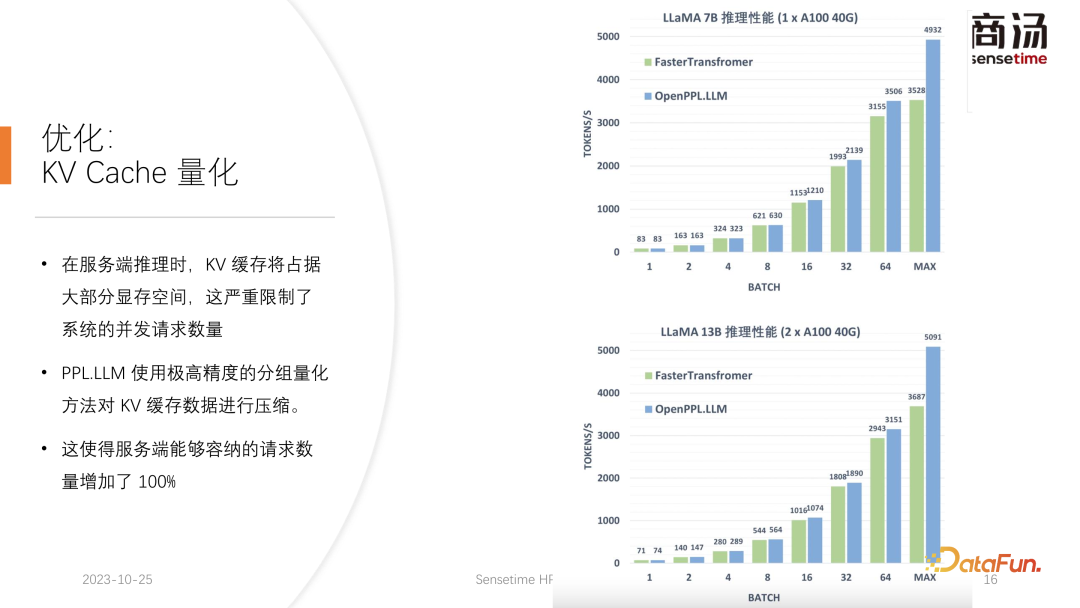
PPL.LLM utilise une méthode de quantification très spéciale, la quantification de groupe, pour compresser les données dans le cache KV. C'est-à-dire que pour les données originales du FP16, une tentative sera faite pour les quantifier en INT8. Cela réduira la taille du cache KV de 50 % et augmentera de 100 % le nombre de requêtes que le serveur peut traiter.
La raison pour laquelle il peut augmenter le débit d'environ 50 % par rapport à Faster Transformer est précisément due à l'augmentation de la taille des lots provoquée par la quantification du cache KV.
7. Optimisation : Quantification de la multiplication matricielle

Après la quantification du cache KV, nous avons effectué une quantification plus détaillée de la multiplication matricielle. Dans l'ensemble du processus d'inférence côté serveur, la multiplication matricielle représente plus de 70 % du temps d'inférence total. PPL.LLM utilise une méthode de quantification hybride alternée dynamique par canal/par jeton pour accélérer la multiplication matricielle. Ces quantifications sont également extrêmement précises et peuvent améliorer les performances de près de 100 %.
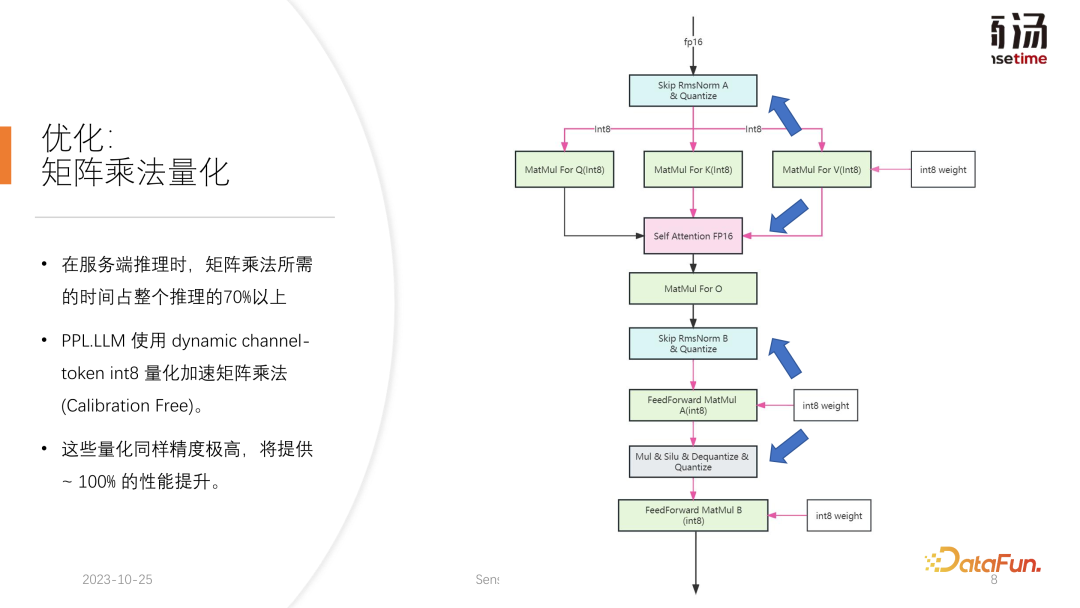
La méthode spécifique consiste à intégrer un opérateur de quantification sur la base de l'opérateur RMSNorm. Cet opérateur de quantification comptera les informations du jeton en fonction de la fonction de l'opérateur RMSNorm et comptera chaque valeur maximale et minimale. , et quantifiez ces données selon les dimensions du jeton. C'est-à-dire que les données après RMSNorm seront converties de FP16 en INT8, et cette fois la quantification est entièrement dynamique et ne nécessite pas d'étalonnage. Dans la multiplication matricielle QKV suivante, ces trois multiplications matricielles seront quantifiées par canal. Les données qu'ils reçoivent sont INT8, et leurs poids sont également INT8, donc ces multiplications matricielles peuvent effectuer des multiplications matricielles complètes INT8. Leur sortie sera acceptée par Soft Attention, mais un processus de déquantification sera effectué avant l'acceptation. Cette fois, le processus de déquantification sera fusionné avec l'opérateur soft attention.
La multiplication matricielle O ultérieure n'effectue pas de quantification, et le processus de calcul de Soft Attention lui-même n'effectue aucune quantification. Dans le processus FeedForward ultérieur, ces deux matrices sont également quantifiées de la même manière, fusionnées avec le RMSNorm ci-dessus, ou fusionnées avec des fonctions d'activation telles que Silu et Mul ci-dessus. Leurs opérateurs de quantification de solutions seront fusionnés avec leurs opérateurs en aval.
8. Optimisation : INT8 vs INT4
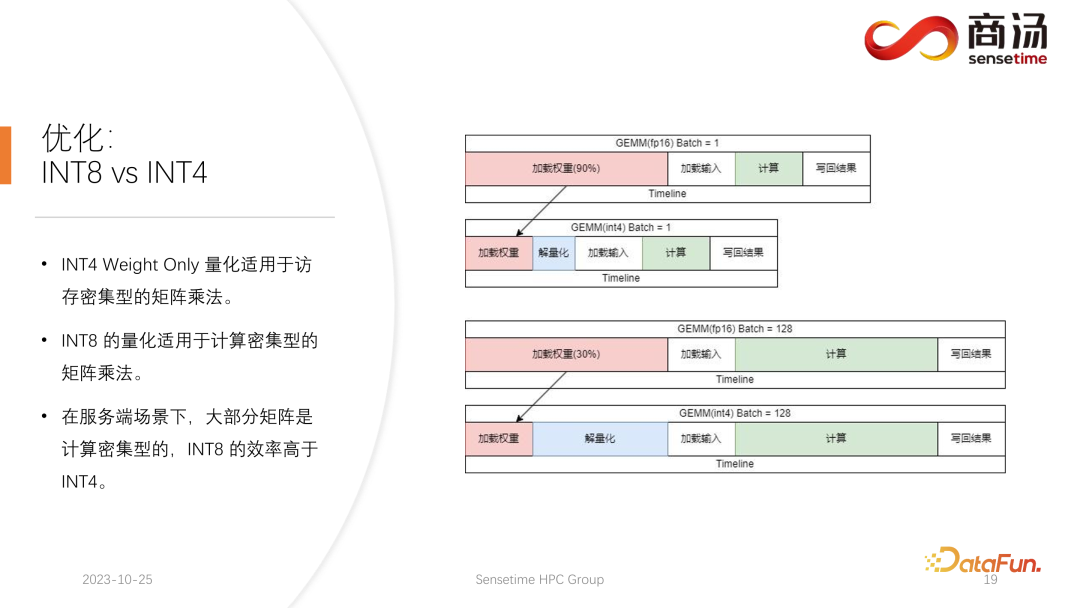
L'accent quantitatif actuel des cercles universitaires sur les grands modèles de langage peut se concentrer principalement sur INT4, mais dans le processus d'inférence côté serveur, INT8 est en fait plus approprié. .quantification.
La quantification INT4 est également appelée quantification par poids uniquement. L'importance de cette méthode de quantification est que lorsque le lot est relativement petit pendant le processus d'inférence du grand modèle de langage, 90 % du temps sera utilisé pour le chargement pendant le calcul de multiplication matricielle. processus. Étant donné que la taille des poids est très grande et que le temps de chargement de l'entrée est très court, leur entrée, c'est-à-dire leur activation, est également très courte, le temps de calcul n'est pas très long et le temps de réécriture des résultats est pas très long non plus, ce qui signifie que ce sous-calcul est un opérateur gourmand en accès mémoire. Dans ce cas, nous choisirons la quantification INT4, à condition que le lot soit suffisamment petit. Après le chargement de chaque poids à l'aide de la quantification INT4, un processus de déquantification suivra. Cette déquantification déquantifiera le poids de INT4 à FP16. Après avoir suivi le processus de déquantification, les calculs suivants sont exactement les mêmes que ceux de FP16, c'est-à-dire que la quantification de INT4 Weight Only convient à la multiplication matricielle nécessitant beaucoup d'accès à la mémoire. son calcul Le processus est toujours complété par le dispositif informatique FP16.
Lorsque le lot est suffisamment grand, comme 64 ou 128, la quantification Weight Only d'INT4 n'apportera aucune amélioration des performances. Car si le lot est suffisamment important, le temps de calcul sera très long. Et la quantification INT4 Weight Only a un très mauvais point. La quantité de calcul requise pour son processus de déquantification augmentera avec l'augmentation du lot (GEMM Batch). À mesure que le lot d'entrée augmente, le temps de déquantification augmentera également. . Cela deviendra de plus en plus long. Lorsque la taille du lot atteint 128, la perte de temps causée par la déquantification et l'avantage de performances apporté par le chargement des poids s'annulent. C'est-à-dire que lorsque le lot atteint 128, la quantification matricielle INT4 ne sera pas plus rapide que la quantification matricielle FP16 et l'avantage en termes de performances est minime. Environ lorsque le lot est égal à 64, la quantification en poids uniquement de INT4 ne sera que 30 % plus rapide que celle du FP16. Lorsque le lot est de 128, elle ne sera qu'environ 20 % plus rapide, voire moins.
Mais pour INT8, la plus grande différence entre la quantification INT8 et la quantification INT4 est qu'elle ne nécessite aucun processus de déquantification et que son calcul peut être doublé dans le temps. Lorsque le lot est égal à 128, de la quantification FP16 à INT8, le temps de chargement des poids sera réduit de moitié, et le temps de calcul sera également réduit de moitié, ce qui entraînera une accélération d'environ 100 %.
Dans un scénario côté serveur, notamment en raison d'un afflux constant de requêtes, la plupart des multiplications matricielles nécessiteront beaucoup de calculs. Dans ce cas, si vous souhaitez atteindre le débit ultime, l'efficacité d'INT8 est en réalité supérieure à celle d'INT4. C'est également l'une des raisons pour lesquelles nous promouvons principalement INT8 côté serveur dans l'implémentation que nous avons réalisée jusqu'à présent.
9. Optimisation : FP8 vx INT8
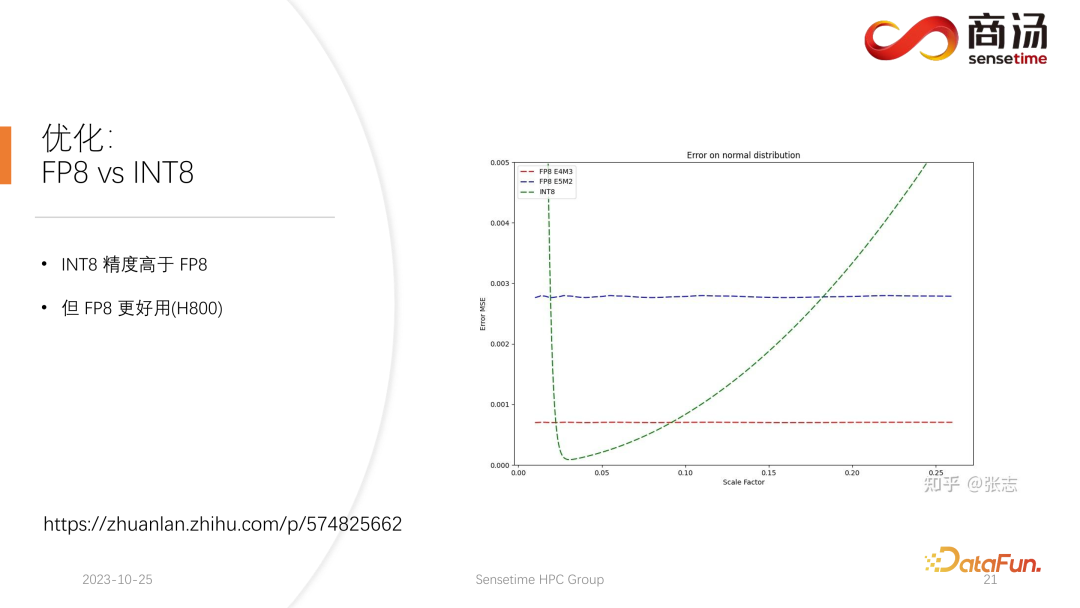
Sur H100, H800, 4090, nous pouvons effectuer une quantification FP8. Des formats de données tels que FP8 ont été introduits dans la dernière génération de cartes graphiques Nvidia. La précision de INT8 est théoriquement supérieure à celle de FP8, mais FP8 sera plus utile et plus performant. Nous favoriserons également la mise en œuvre de FP8 dans les mises à jour ultérieures du processus d'inférence côté serveur. Comme le montre la figure ci-dessus, l’erreur de FP8 est environ 10 fois supérieure à celle de INT8. INT8 aura un facteur de taille quantifié, et l'erreur de quantification de INT8 peut être réduite en ajustant le facteur de taille. L'erreur de quantification du FP8 est fondamentalement indépendante du facteur de taille, elle n'est pas affectée par le facteur de taille, ce qui signifie que nous n'avons pratiquement pas besoin de procéder à un calibrage. Mais son erreur est généralement supérieure à INT8.
10. Optimisation : INT4 vs quantification non linéaire

PPL.LLM wird in nachfolgenden Updates auch die Matrixquantisierung von INT4 aktualisieren. Diese Nur-Gewicht-Matrixquantisierung dient hauptsächlich der Terminalseite, für Geräte wie mobile Terminals, bei denen der Batch auf 1 festgelegt ist. In nachfolgenden Updates wird schrittweise von INT4 auf nichtlineare Quantisierung umgestellt. Denn im Berechnungsprozess von „Weight Only“ wird es einen Dequantisierungsprozess geben, der tatsächlich anpassbar ist und möglicherweise kein linearer Dequantisierungsprozess ist. Die Verwendung anderer Dequantisierungsprozesse und Quantisierungsprozesse führt zu einer höheren Berechnungsgenauigkeit.
Ein typisches Beispiel ist die in einem Artikel erwähnte Quantisierung von NF4. Diese Quantifizierung wird tatsächlich durch eine Tabellenmethode quantisiert. In nachfolgenden Updates von PPL.LLM werden wir versuchen, eine solche Quantisierung zu nutzen, um die geräteseitige Inferenz zu optimieren.
3. Hardware für die Inferenz großer Sprachmodelle
Abschließend stellen wir die Hardware für die Verarbeitung großer Sprachmodelle vor.
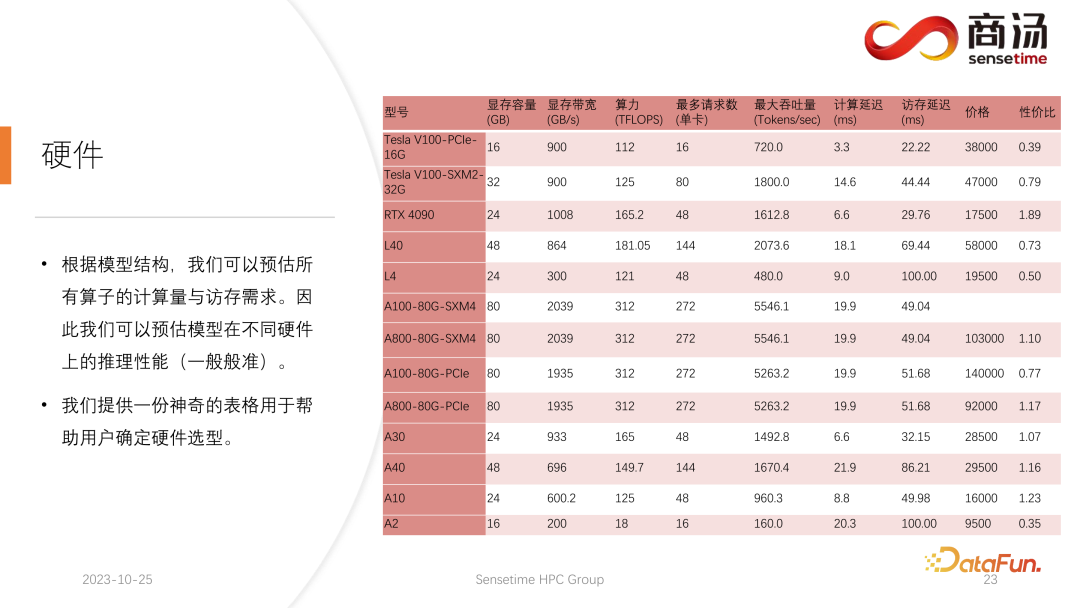
Sobald die Modellstruktur festgelegt ist, kennen wir den spezifischen Berechnungsumfang, wie viel Speicherzugriff erforderlich ist und wie viel Berechnungsumfang erforderlich ist. Gleichzeitig kennen Sie auch die Bandbreite, Rechenleistung, den Preis usw. jeder Grafikkarte. Nachdem wir die Struktur des Modells und die Hardwareindikatoren bestimmt haben, können wir anhand dieser Indikatoren den maximalen Durchsatz für die Ableitung eines großen Modells auf dieser Grafikkarte, die Berechnungsverzögerung und die erforderliche Speicherzugriffszeit berechnen spezifische Tabelle berechnet werden kann. Wir werden diese Tabelle in den folgenden Informationen veröffentlichen. Sie können auf diese Tabelle zugreifen, um zu sehen, welche Grafikkartenmodelle für die Inferenz großer Sprachmodelle am besten geeignet sind.
Da bei der Inferenz großer Sprachmodelle die meisten Operatoren speicherzugriffsintensiv sind, ist die Speicherzugriffslatenz immer höher als die Berechnungslatenz. Da die Parametermatrix des großen Sprachmodells tatsächlich zu groß ist, ist die Berechnungsverzögerung selbst beim A100 / 80G gering, wenn die Stapelgröße auf 272 geöffnet wird, die Verzögerung beim Speicherzugriff ist jedoch höher. Daher beginnen viele unserer Optimierungen mit dem Speicherzugriff. Bei der Auswahl der Hardware besteht unsere Hauptrichtung darin, Geräte mit relativ hoher Bandbreite und großem Videospeicher auszuwählen. Dadurch kann das große Sprachmodell mehr Anforderungen und einen schnelleren Speicherzugriff während der Inferenz unterstützen, und der entsprechende Durchsatz wird höher sein.

Das Obige ist der Inhalt, der dieses Mal geteilt wurde. Alle relevanten Informationen werden auf der Netzwerkfestplatte abgelegt, siehe Link oben. Unser gesamter Code wurde auch als Open Source auf Github bereitgestellt. Gerne können Sie jederzeit mit uns kommunizieren.
IV. Fragen und Antworten
F1: Gibt es ein Speicherzugriffsproblem wie Softmax in Flash Attention, das in PPL.LLM optimiert ist?
A1: Decoding Attention ist ein ganz besonderer Operator. Die Länge seines Q beträgt immer 1, daher ist in Softmax kein sehr großer Speicherzugriff wie bei Flash Attention erforderlich. Tatsächlich handelt es sich bei der Ausführung von Decoding Attention um die vollständige Ausführung von Softmax und muss nicht so schnell ausgeführt werden wie Flash Attention.
F2: Warum hängt die Nur-Gewicht-Quantisierung von INT4 linear mit der Charge zusammen? Ist das eine feste Zahl?
A2: Erstens ist diese Lösungsquantisierung nicht so, wie alle denken. Wenn Sie dies nur tun, ist die Lösung so groß Gewichte. Tatsächlich ist dies nicht der Fall, da es sich um eine in die Matrixmultiplikation integrierte Lösungsquantisierung handelt. Sie können nicht alle Gewichtslösungen quantisieren, bevor Sie die Matrixmultiplikation durchführen, sie dort ablegen und dann lesen. Auf diese Weise ist die Quantisierung von INT4, die wir vorgenommen haben, bedeutungslos. Da wir während des Ausführungsprozesses eine Blockmatrixmultiplikation durchführen, beträgt die Anzahl der Lese- und Schreibvorgänge nicht 1. Diese Zahl muss tatsächlich kontinuierlich berechnet werden. Das heißt, anders als bei den vorherigen Methoden zur Optimierung der Quantisierung wird es separate Quantisierungsoperatoren und Lösungsquantisierungsoperatoren geben. Bei der Einfügung zweier Operatoren wird die Lösungsquantisierung direkt in den Operator integriert. Wir führen eine Matrixmultiplikation durch, daher ist die Häufigkeit, mit der wir die Quantisierung lösen müssen, nicht einmal.
F3: Kann die inverse Quantisierungsberechnung im KV-Cache durch Nachahmung maskiert werden?
A3: Laut unseren Tests lässt es sich vertuschen, und tatsächlich ist noch viel mehr übrig. Die inverse Quantisierung und die Quantisierung in der KV-Berechnung werden in den Selbstaufmerksamkeitsoperator integriert, insbesondere in die Dekodierung der Aufmerksamkeit. Tests zufolge kann dieser Operator auch bei 10-fachem Rechenaufwand maskiert werden. Selbst die Verzögerung des Speicherzugriffs kann dies nicht verdecken. Sein Hauptengpass ist der Speicherzugriff, und sein Berechnungsumfang erreicht bei weitem nicht das Niveau, das den Speicherzugriff verdecken kann. Daher ist die inverse Quantisierungsberechnung im KV-Cache grundsätzlich eine gut abgedeckte Sache für diesen Operator.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1359
1359
 52
52

 Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Guide étape par étape pour utiliser Groq Llama 3 70B localement
Jun 10, 2024 am 09:16 AM
Traducteur | Bugatti Review | Chonglou Cet article décrit comment utiliser le moteur d'inférence GroqLPU pour générer des réponses ultra-rapides dans JanAI et VSCode. Tout le monde travaille à la création de meilleurs grands modèles de langage (LLM), tels que Groq, qui se concentre sur le côté infrastructure de l'IA. Une réponse rapide de ces grands modèles est essentielle pour garantir que ces grands modèles réagissent plus rapidement. Ce didacticiel présentera le moteur d'analyse GroqLPU et comment y accéder localement sur votre ordinateur portable à l'aide de l'API et de JanAI. Cet article l'intégrera également dans VSCode pour nous aider à générer du code, à refactoriser le code, à saisir la documentation et à générer des unités de test. Cet article créera gratuitement notre propre assistant de programmation d’intelligence artificielle. Introduction au moteur d'inférence GroqLPU Groq
 Les Chinois de Caltech utilisent l'IA pour renverser les preuves mathématiques ! Accélérer 5 fois a choqué Tao Zhexuan, 80% des étapes mathématiques sont entièrement automatisées
Apr 23, 2024 pm 03:01 PM
Les Chinois de Caltech utilisent l'IA pour renverser les preuves mathématiques ! Accélérer 5 fois a choqué Tao Zhexuan, 80% des étapes mathématiques sont entièrement automatisées
Apr 23, 2024 pm 03:01 PM
LeanCopilot, cet outil mathématique formel vanté par de nombreux mathématiciens comme Terence Tao, a encore évolué ? Tout à l'heure, Anima Anandkumar, professeur à Caltech, a annoncé que l'équipe avait publié une version étendue de l'article LeanCopilot et mis à jour la base de code. Adresse de l'article image : https://arxiv.org/pdf/2404.12534.pdf Les dernières expériences montrent que cet outil Copilot peut automatiser plus de 80 % des étapes de preuve mathématique ! Ce record est 2,3 fois meilleur que le précédent record d’Esope. Et, comme auparavant, il est open source sous licence MIT. Sur la photo, il s'agit de Song Peiyang, un garçon chinois.
 Plaud lance l'enregistreur portable NotePin AI pour 169 $
Aug 29, 2024 pm 02:37 PM
Plaud lance l'enregistreur portable NotePin AI pour 169 $
Aug 29, 2024 pm 02:37 PM
Plaud, la société derrière le Plaud Note AI Voice Recorder (disponible sur Amazon pour 159 $), a annoncé un nouveau produit. Surnommé NotePin, l’appareil est décrit comme une capsule mémoire AI, et comme le Humane AI Pin, il est portable. Le NotePin est
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
GraphRAG amélioré pour la récupération de graphes de connaissances (implémenté sur la base du code Neo4j)
Jun 12, 2024 am 10:32 AM
La génération améliorée de récupération de graphiques (GraphRAG) devient progressivement populaire et est devenue un complément puissant aux méthodes de recherche vectorielles traditionnelles. Cette méthode tire parti des caractéristiques structurelles des bases de données graphiques pour organiser les données sous forme de nœuds et de relations, améliorant ainsi la profondeur et la pertinence contextuelle des informations récupérées. Les graphiques présentent un avantage naturel dans la représentation et le stockage d’informations diverses et interdépendantes, et peuvent facilement capturer des relations et des propriétés complexes entre différents types de données. Les bases de données vectorielles sont incapables de gérer ce type d'informations structurées et se concentrent davantage sur le traitement de données non structurées représentées par des vecteurs de grande dimension. Dans les applications RAG, la combinaison de données graphiques structurées et de recherche de vecteurs de texte non structuré nous permet de profiter des avantages des deux en même temps, ce dont discutera cet article. structure
 Google AI annonce Gemini 1.5 Pro et Gemma 2 pour les développeurs
Jul 01, 2024 am 07:22 AM
Google AI annonce Gemini 1.5 Pro et Gemma 2 pour les développeurs
Jul 01, 2024 am 07:22 AM
Google AI a commencé à fournir aux développeurs un accès à des fenêtres contextuelles étendues et à des fonctionnalités économiques, à commencer par le modèle de langage large (LLM) Gemini 1.5 Pro. Auparavant disponible via une liste d'attente, la fenêtre contextuelle complète de 2 millions de jetons
 Comment créer une passerelle API évolutive utilisant la technologie NIO dans les fonctions Java ?
May 04, 2024 pm 01:12 PM
Comment créer une passerelle API évolutive utilisant la technologie NIO dans les fonctions Java ?
May 04, 2024 pm 01:12 PM
Réponse : Grâce à la technologie NIO, vous pouvez créer une passerelle API évolutive dans les fonctions Java pour gérer un grand nombre de requêtes simultanées. Étapes : Créer NIOChannel, enregistrer le gestionnaire d'événements, accepter la connexion, enregistrer les données, lire et écrire le gestionnaire, traiter la demande, envoyer la réponse.
 Déployer de grands modèles de langage localement dans OpenHarmony
Jun 07, 2024 am 10:02 AM
Déployer de grands modèles de langage localement dans OpenHarmony
Jun 07, 2024 am 10:02 AM
Cet article ouvrira en source les résultats du « Déploiement local de grands modèles de langage dans OpenHarmony » démontrés lors de la 2e conférence technologique OpenHarmony. Adresse : https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/hap_integrate.md. Les idées et les étapes de mise en œuvre consistent à transplanter le cadre d'inférence de modèle LLM léger InferLLM vers le système standard OpenHarmony et à compiler un produit binaire pouvant s'exécuter sur OpenHarmony. InferLLM est un L simple et efficace
