
 Périphériques technologiques
IA
Pénétrez dans la couche inférieure de l'IA ! L'équipe de NUS Youyang utilise un modèle de diffusion pour construire les paramètres du réseau neuronal, LeCun aime ça
Périphériques technologiques
IA
Pénétrez dans la couche inférieure de l'IA ! L'équipe de NUS Youyang utilise un modèle de diffusion pour construire les paramètres du réseau neuronal, LeCun aime ça
Pénétrez dans la couche inférieure de l'IA ! L'équipe de NUS Youyang utilise un modèle de diffusion pour construire les paramètres du réseau neuronal, LeCun aime ça

Le modèle de diffusion a inauguré une nouvelle application majeure :
Tout comme Sora générant des vidéos, il génère des paramètres pour les réseaux de neurones et pénètre directement dans la couche inférieure de l'IA !
Il s'agit du dernier résultat de recherche open source de l'équipe du professeur You Yang de l'Université nationale de Singapour, en collaboration avec UCB, Meta AI Laboratory et d'autres institutions.

Plus précisément, l'équipe de recherche a proposé un modèle de diffusion p(arameter)-diff pour générer des paramètres de réseau neuronal.
Utilisez-le pour générer des paramètres réseau, la vitesse est jusqu'à 44 fois plus rapide que la formation directe et les performances ne sont pas inférieures.
Après la sortie du modèle, il a rapidement suscité des discussions animées au sein de la communauté de l'IA. Les experts du cercle ont montré la même attitude étonnante que les gens ordinaires en voyant Sora.
Certaines personnes se sont même directement exclamées que cela équivaut fondamentalement à la création d'une nouvelle IA par l'IA.

Même le géant de l'IA, LeCun, a loué cette réalisation après l'avoir vue, affirmant que c'était vraiment une idée mignonne.
En fait, p-diff a la même signification que Sora, le Dr Fuzhao Xue (Xue Fuzhao) du même laboratoire a expliqué en détail :
Sora génère des données de grande dimension, c'est-à-dire des vidéos. fait de Sora un simulateur de monde (se rapprochant de l'AGI à partir d'une seule dimension).
Et ce travail, la diffusion du réseau neuronal, peut générer des paramètres dans le modèle, a le potentiel de devenir un apprenant/optimiseur de classe mondiale, évoluant vers l'AGI à partir d'une autre nouvelle dimension importante.

Pour en revenir au sujet, comment p-diff génère-t-il les paramètres du réseau neuronal ?
Combinaison de l'auto-encodeur avec le modèle de diffusion
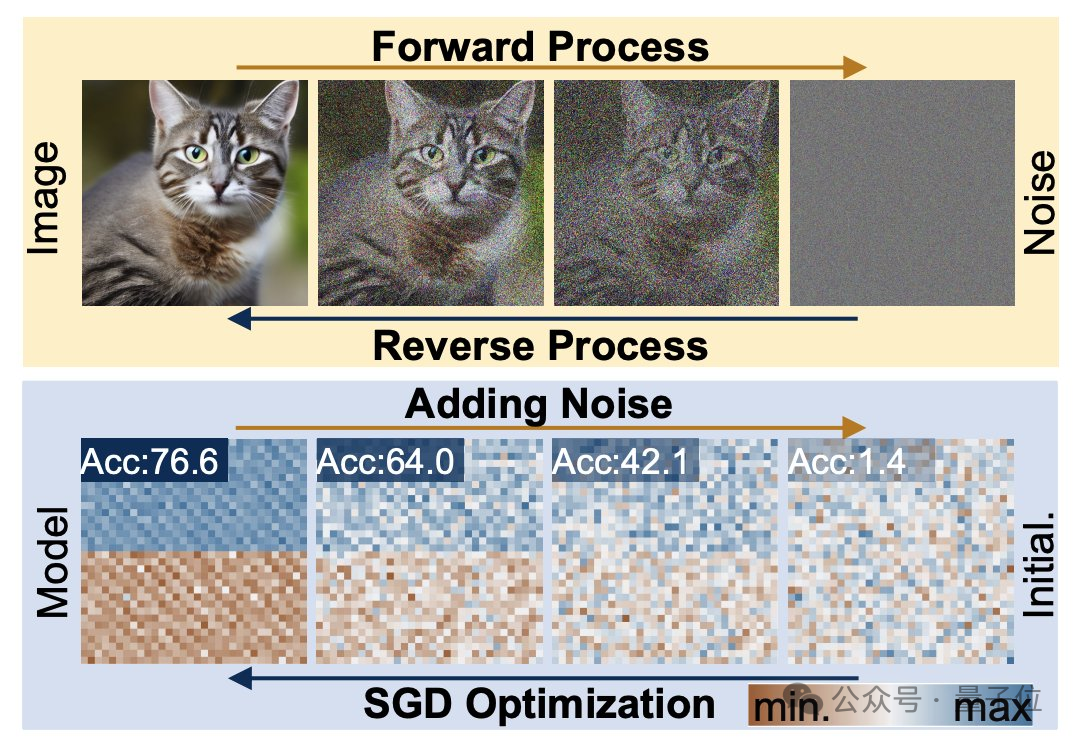
Pour comprendre ce problème, nous devons d'abord comprendre les caractéristiques de fonctionnement du modèle de diffusion et du réseau neuronal.
Le processus de génération de diffusion est la transformation d'une distribution aléatoire en une distribution très spécifique Grâce à l'ajout de bruit composé, l'information visuelle est réduite à une simple distribution de bruit.
L'entraînement des réseaux neuronaux suit également ce processus de transformation et peut également être dégradé par l'ajout de bruit. Inspirés par cette fonctionnalité, les chercheurs ont proposé la méthode p-diff.
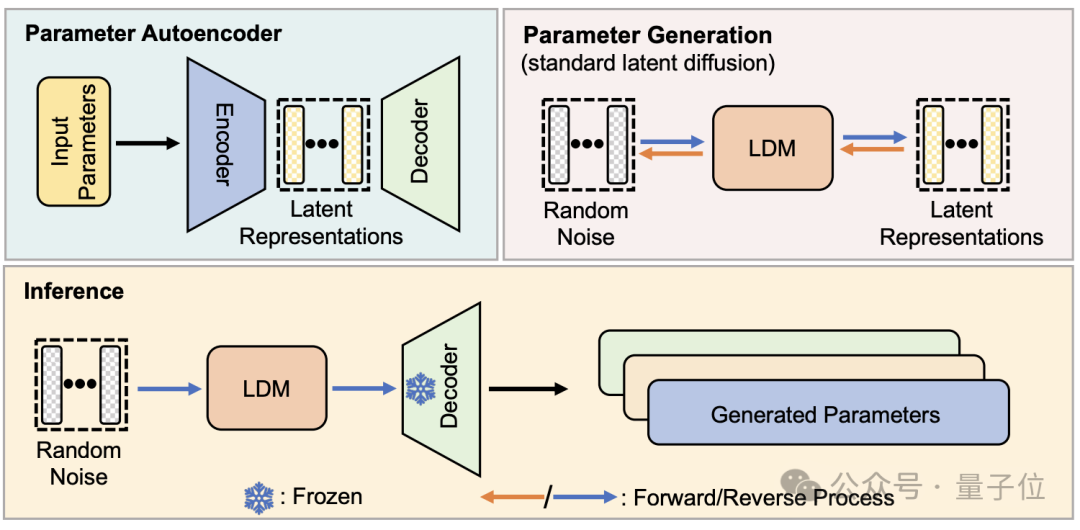
D'un point de vue structurel, p-diff est conçu par l'équipe de recherche sur la base du modèle standard de diffusion latente et combiné avec l'auto-encodeur.
Le chercheur sélectionne d'abord une partie des paramètres de réseau qui ont été entraînés et fonctionnent bien, et les développe sous une forme vectorielle unidimensionnelle.
Utilisez ensuite l'auto-encodeur pour extraire la représentation latente du vecteur unidimensionnel comme données d'entraînement pour le modèle de diffusion. Cela peut capturer les caractéristiques clés des paramètres d'origine.
Pendant le processus de formation, les chercheurs ont laissé p-diff apprendre la distribution des paramètres via des processus aller et retour. Une fois terminé, le modèle de diffusion synthétise ces représentations potentielles à partir de bruit aléatoire, comme le processus de génération d'informations visuelles.
Enfin, la représentation latente nouvellement générée est restituée aux paramètres réseau par le décodeur correspondant à l'encodeur et utilisée pour construire un nouveau modèle.
La figure suivante est la distribution des paramètres du modèle ResNet-18 formé à partir de zéro en utilisant 3 graines aléatoires via p-diff, montrant le modèle de distribution entre différentes couches et entre différents paramètres dans la même couche.

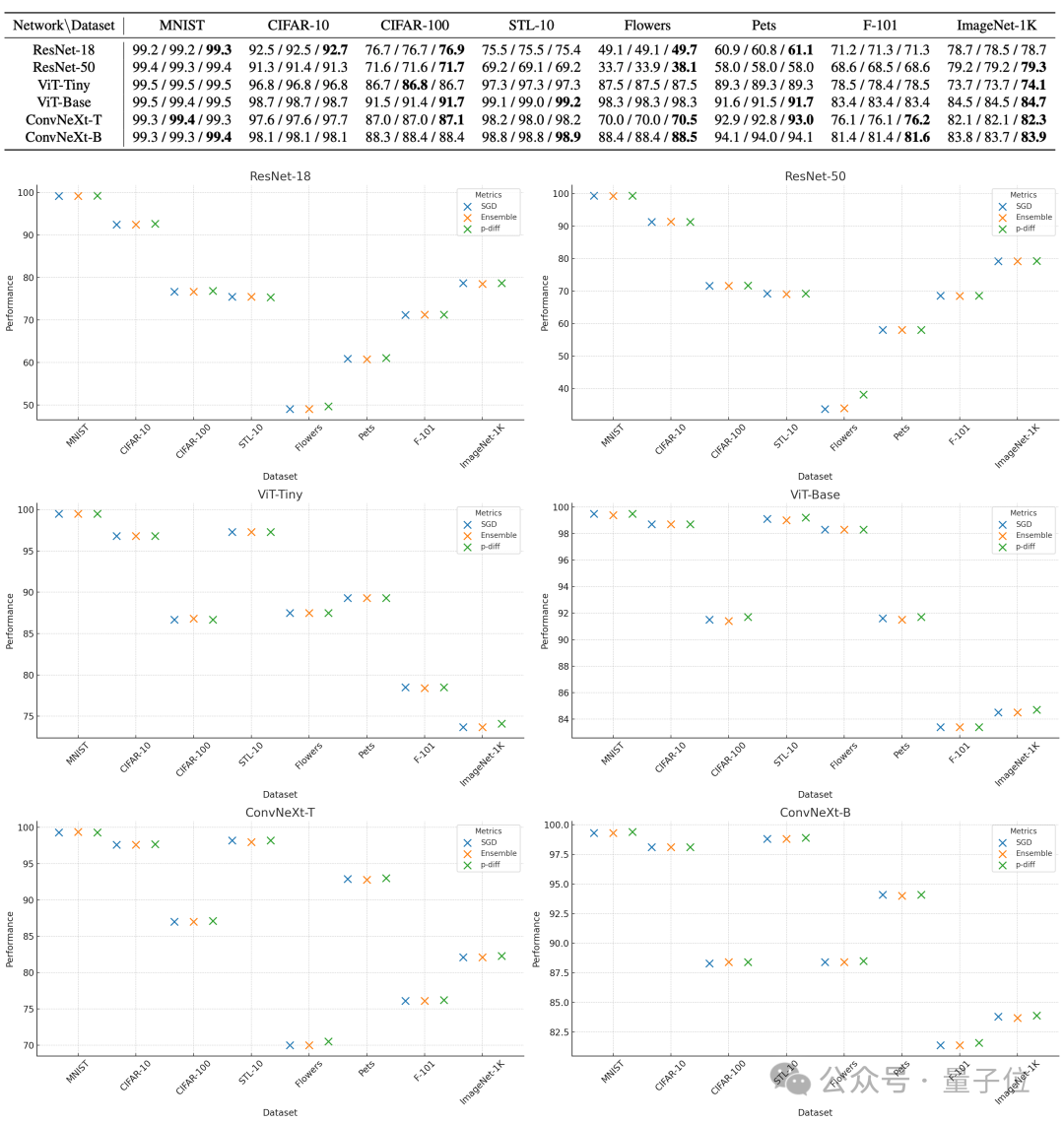
Pour évaluer la qualité des paramètres générés par p-diff, les chercheurs l'ont testé sur 8 ensembles de données utilisant 3 types de réseaux de neurones de deux tailles chacun.
Dans le tableau ci-dessous, les trois nombres de chaque groupe représentent les résultats d'évaluation du modèle original, du modèle intégré et du modèle généré avec p-diff.
Comme vous pouvez le voir sur les résultats, les performances du modèle généré avec p-diff sont fondamentalement proches, voire meilleures, que celles du modèle d'origine entraîné manuellement.
En termes d'efficacité, sans perdre en précision, p-diff génère le réseau ResNet-18 15 fois plus rapide que la formation traditionnelle, et génère Vit-Base 44 fois plus rapidement.
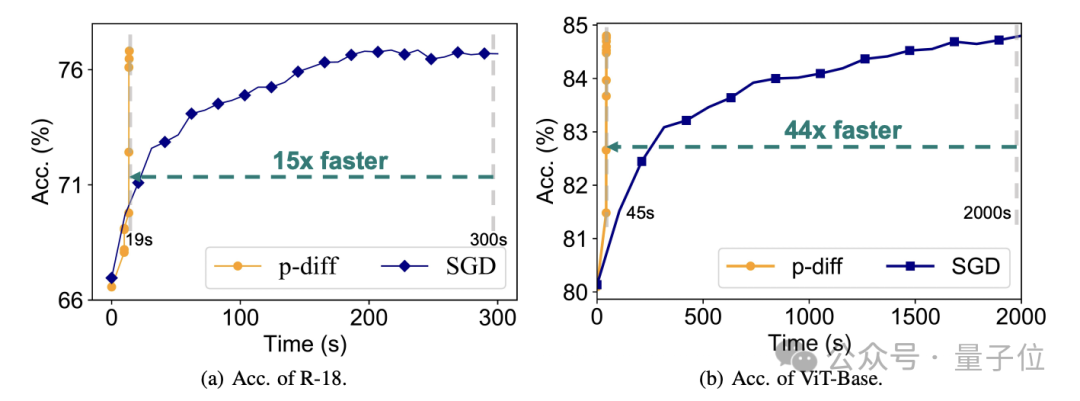
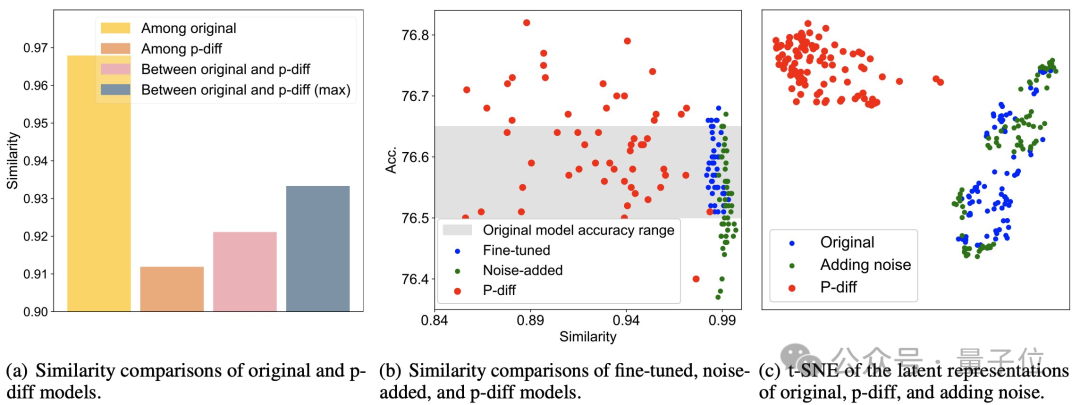
Des résultats de tests supplémentaires prouvent que le modèle généré par p-diff est significativement différent des données d'entraînement.
Comme vous pouvez le voir sur la figure (a) ci-dessous, la similarité entre les modèles générés par p-diff est inférieure à la similarité entre les modèles originaux, ainsi que la similarité entre p-diff et le modèle original.
Comme le montrent les points (b) et (c), par rapport aux méthodes de réglage fin et d'ajout de bruit, la similarité de p-diff est également plus faible.
Ces résultats montrent que p-diff génère en fait un nouveau modèle au lieu de simplement mémoriser des échantillons d'entraînement. Cela montre également qu'il a une bonne capacité de généralisation et peut générer de nouveaux modèles différents des données d'entraînement.
Actuellement, le code de p-diff est open source Si vous êtes intéressé, vous pouvez le consulter sur GitHub.
Adresse papier : https://arxiv.org/abs/2402.13144
GitHub : https://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravelelognent Model Retrieval: Faconttement l'obtention de données de base de données Eloquentorm fournit un moyen concis et facile à comprendre pour faire fonctionner la base de données. Cet article présentera en détail diverses techniques de recherche de modèles éloquentes pour vous aider à obtenir efficacement les données de la base de données. 1. Obtenez tous les enregistrements. Utilisez la méthode All () pour obtenir tous les enregistrements dans la table de base de données: usApp \ Modèles \ Post; $ poters = post :: all (); Cela rendra une collection. Vous pouvez accéder aux données à l'aide de Foreach Loop ou d'autres méthodes de collecte: ForEach ($ PostsAs $ POST) {echo $ post->
