
 Périphériques technologiques
IA
Plein d'informations utiles ! Première version texte du cours d'IA de deux heures de Master Karpathy, un nouveau flux de travail convertit automatiquement les vidéos en articles
Périphériques technologiques
IA
Plein d'informations utiles ! Première version texte du cours d'IA de deux heures de Master Karpathy, un nouveau flux de travail convertit automatiquement les vidéos en articles
Plein d'informations utiles ! Première version texte du cours d'IA de deux heures de Master Karpathy, un nouveau flux de travail convertit automatiquement les vidéos en articles

Il y a quelque temps, le cours d'IA en ligne du maître de l'IA Karpathy a reçu 150 000 vues sur l'ensemble du réseau.
A cette époque, certains internautes disaient que la valeur de ce cours de 2 heures équivalait à 4 années d'université.
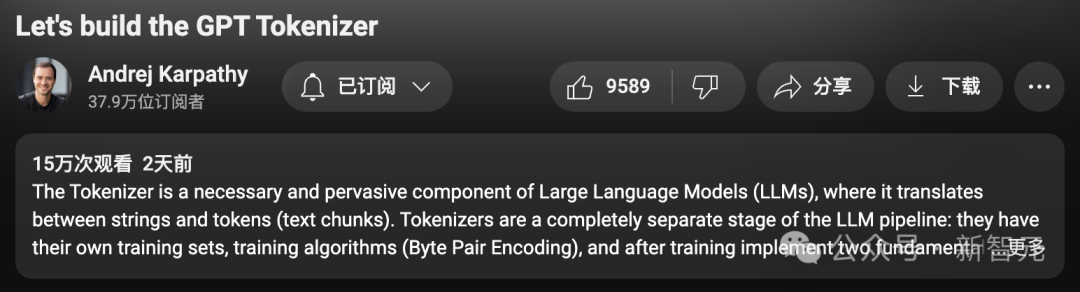
Ces derniers jours, Karpathy a eu une nouvelle idée :
Convertissez les 2 heures et 13 minutes du contenu vidéo "Construire un tokenizer GPT à partir de zéro" en un chapitre de livre ou un blog. La forme de l'article se concentre sur le thème de la « segmentation des mots ».
Les étapes spécifiques sont les suivantes :
- Ajouter des sous-titres ou un texte de narration à la vidéo.
- Coupez la vidéo en plusieurs paragraphes avec des images et du texte correspondants.
- Utilisez la technologie d'ingénierie rapide des grands modèles linguistiques pour traduire paragraphe par paragraphe.
- Affichez les résultats sous forme de page Web avec des liens vers des parties de la vidéo originale.
Plus largement, un tel flux de travail peut être appliqué à n'importe quelle entrée vidéo, générant automatiquement des « guides de support » pour divers didacticiels dans un format plus facile à lire, à parcourir et à rechercher.
Cela semble faisable, mais aussi assez difficile.
Il a écrit un exemple pour illustrer son imagination dans le cadre du projet GitHub minbpe.
Adresse : https://github.com/karpathy/minbpe/blob/master/lecture.md
Karpathy a déclaré qu'il s'agissait d'une tâche manuelle, c'est-à-dire regarder la vidéo et la traduire Articles au format démarque.
"Je n'ai regardé qu'environ 4 minutes de la vidéo (soit 3% de réalisation), et cela m'a pris environ 30 minutes à écrire, donc ce serait génial si quelque chose comme ça pouvait être fait automatiquement."
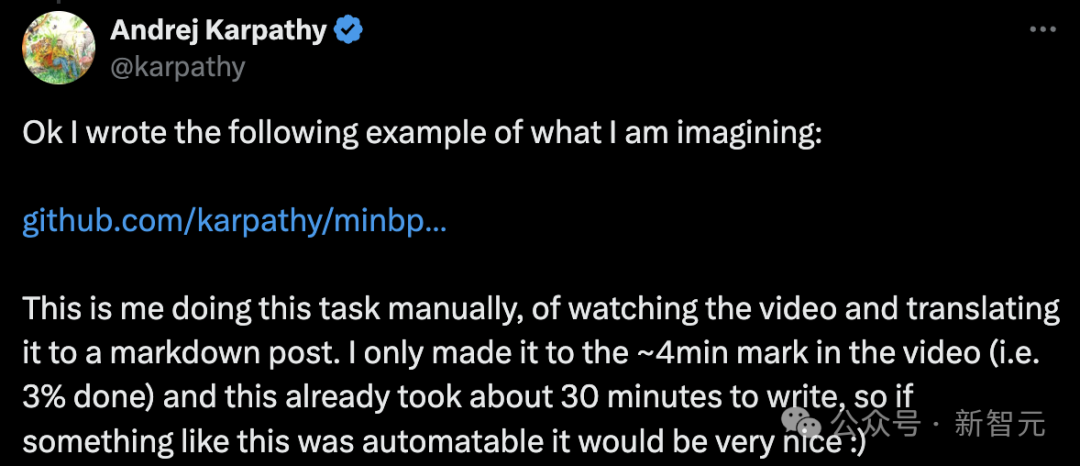
Ensuite, c'est l'heure des cours !
Version texte du cours "Segmentation de mots LLM"
Bonjour à tous, aujourd'hui nous aborderons la problématique de la "segmentation de mots" en LLM.
Malheureusement, la « segmentation des mots » est une composante relativement complexe et délicate des grands modèles les plus avancés, mais il nous est nécessaire de la comprendre en détail.
Parce que de nombreux défauts du LLM peuvent être attribués à des réseaux de neurones ou à d'autres facteurs apparemment mystérieux, ces défauts peuvent en réalité être attribués à la « segmentation des mots ».
Segmentation de mots au niveau des caractères
Alors, qu'est-ce que la segmentation de mots ?
En fait, dans la vidéo précédente "Construisons GPT à partir de zéro", j'ai déjà introduit la tokenisation, mais ce n'était qu'une version très simple au niveau des personnages.
Si vous allez sur Google Colab et regardez cette vidéo, vous verrez que nous commençons par les données d'entraînement (Shakespeare), qui ne sont qu'une grosse chaîne en Python :
First Citizen: Before we proceed any further, hear me speak.All: Speak, speak.First Citizen: You are all resolved rather to die than to famish?All: Resolved. resolved.First Citizen: First, you know Caius Marcius is chief enemy to the people.All: We know't, we know't.
Mais comment est-ce qu'on alimente la chaîne dans What about LLM ?
Nous pouvons voir que nous devons d'abord construire un vocabulaire pour tous les caractères possibles dans l'ensemble de la formation :
# here are all the unique characters that occur in this textchars = sorted(list(set(text)))vocab_size = len(chars)print(''.join(chars))print(vocab_size)# !$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz# 65Ensuite, sur la base du vocabulaire ci-dessus, créez un vocabulaire entre les caractères simples et les nombres entiers. Table de recherche pour conversion. Cette table de recherche n'est qu'un dictionnaire Python :
stoi = { ch:i for i,ch in enumerate(chars) }itos = { i:ch for i,ch in enumerate(chars) }# encoder: take a string, output a list of integersencode = lambda s: [stoi[c] for c in s]# decoder: take a list of integers, output a stringdecode = lambda l: ''.join([itos[i] for i in l])print(encode("hii there"))print(decode(encode("hii there")))# [46, 47, 47, 1, 58, 46, 43, 56, 43]# hii thereUne fois que nous convertissons une chaîne en une séquence d'entiers, nous voyons que chaque entier est utilisé comme index dans l'intégration 2D des paramètres pouvant être entraînés.
Puisque la taille de notre vocabulaire est vocab_size=65 , cette table d'intégration aura également 65 lignes :
class BigramLanguageModel(nn.Module):def __init__(self, vocab_size):super().__init__()self.token_embedding_table = nn.Embedding(vocab_size, n_embd)def forward(self, idx, targets=None):tok_emb = self.token_embedding_table(idx) # (B,T,C)
Ici, l'entier "extrait" une ligne de la table d'intégration, et cette ligne est le vecteur représentant la segmentation des mots. Ce vecteur sera ensuite introduit dans le transformateur comme entrée pour le pas de temps correspondant.
Utilisation de l'algorithme BPE pour la segmentation des "morceaux de caractères"
C'est très bien pour une configuration naïve d'un modèle de langage "au niveau du caractère".
Mais en pratique, dans les modèles linguistiques de pointe, les gens utilisent des schémas plus complexes pour construire ces vocabulaires représentationnels.
Plus précisément, ces solutions ne fonctionnent pas au niveau du personnage, mais au niveau du "bloc de personnage". La façon dont ces vocabulaires de blocs sont construits consiste à utiliser des algorithmes tels que le Byte Pair Encoding (BPE), que nous décrivons en détail ci-dessous.
Passons brièvement en revue le développement historique de cette méthode. L'article qui utilise l'algorithme BPE au niveau de l'octet pour la segmentation des mots du modèle de langage est l'article GPT-2 Les modèles de langage sont des apprenants multitâches non supervisés publié par OpenAI en 2019.

Adresse papier : https://d4mucfpksywv.cloudfront.net/better-lingual-models/lingual_models_are_unsupervised_multitask_learners.pdf
Faites défiler jusqu'à la section 2.2 « Représentation des entrées », où ils décrivent et motivent cet algorithme. . À la fin de cette section, vous verrez qu'ils disent :
Vocabulaire étendu à 50 257 mots. Nous avons également augmenté la taille du contexte de 512 à 1 024 jetons et utilisé une taille de lot plus grande de 512.
Rappelez que dans la couche d'attention du Transformer, chaque jeton est associé à une liste limitée de jetons précédents dans la séquence.
Cet article souligne que la longueur du contexte du modèle GPT-2 est passée de 512 jetons dans GPT-1 à 1024 jetons.
En d'autres termes, le token est "l'atome" de base à l'entrée de LLM.
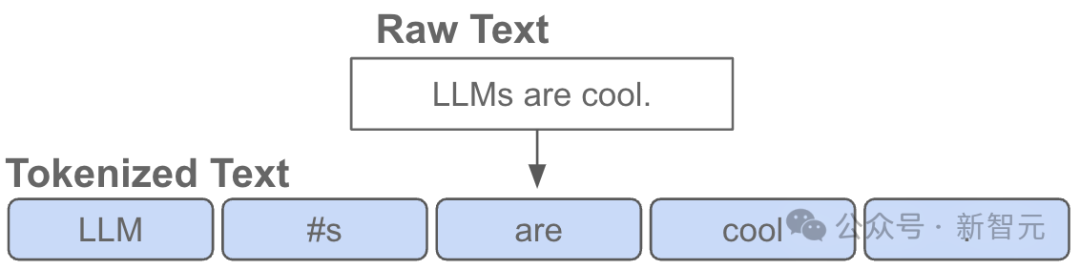
La « tokenisation » est le processus de conversion de chaînes originales en Python en listes de jetons, et vice versa.
Il existe un autre exemple populaire qui prouve l'universalité de cette abstraction. Si vous recherchez également "jeton" dans l'article de Llama 2, vous obtiendrez 63 résultats correspondants.
Par exemple, le journal affirme qu'ils se sont entraînés sur 2 000 milliards de jetons, etc.

Adresse papier : https://arxiv.org/pdf/2307.09288.pdf
Une brève discussion sur la complexité de la segmentation des mots
Avant d'entrer dans les détails de la mise en œuvre, expliquons brièvement qu'il est nécessaire de comprendre en détail le processus de « segmentation des mots ».
La tokenisation est au cœur de très nombreux problèmes étranges en LLM, et je vous recommande de ne pas l'ignorer.
De nombreux problèmes apparemment liés à l'architecture des réseaux neuronaux sont en réalité liés à la segmentation des mots. Voici quelques exemples :
- Pourquoi LLM ne parvient-il pas à épeler les mots ? ——Segmentation des mots
- Pourquoi LLM ne peut-il pas effectuer des tâches de traitement de chaînes très simples, telles que l'inversion des chaînes ? ——Segmentation des mots
- Pourquoi le LLM est-il pire dans les tâches en langue autre que l'anglais (comme le japonais) ? ——Participe
- Pourquoi LLM n'est-il pas bon en arithmétique simple ? ——Segmentation des mots
- Pourquoi GPT-2 rencontre-t-il plus de problèmes lors du codage en Python ? ——Segmentation de mots
- Pourquoi mon LLM s'arrête-t-il soudainement lorsqu'il voit la chaîne ? ——Participe
- Quel est cet étrange avertissement que j'ai reçu à propos des "espaces de fin" ? ——Participe
- Si je demande à LLM à propos de "SolidGoldMagikarp", pourquoi plante-t-il ? ——Segmentation de mots
- Pourquoi devrais-je utiliser YAML avec LLM au lieu de JSON ? ——Segmentation des mots
- Pourquoi LLM n'est-il pas une véritable modélisation linguistique de bout en bout ? ——Participe

Nous reviendrons sur ces questions à la fin de la vidéo.
Aperçu visuel de la segmentation de mots
Ensuite, chargeons cette WebApp de segmentation de mots.
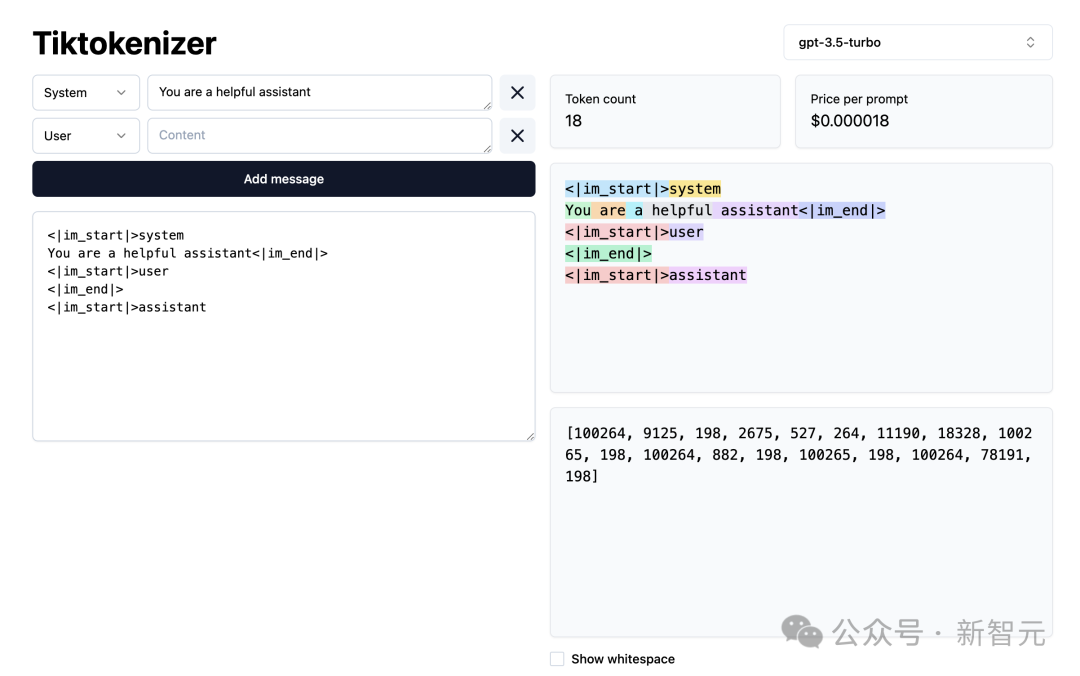
Adresse : https://tiktokenizer.vercel.app/
L'avantage de cette application web est que la tokenisation s'exécute en temps réel dans le navigateur web, vous permettant de saisir facilement du texte sur la chaîne du côté entrée et voyez les résultats de la segmentation des mots sur la droite.
En haut, vous pouvez voir que nous utilisons actuellement le tokenizer gpt2, et vous pouvez voir que la chaîne collée dans cet exemple est actuellement tokenisée en 300 tokens.
Ici, ils sont clairement affichés en couleur :
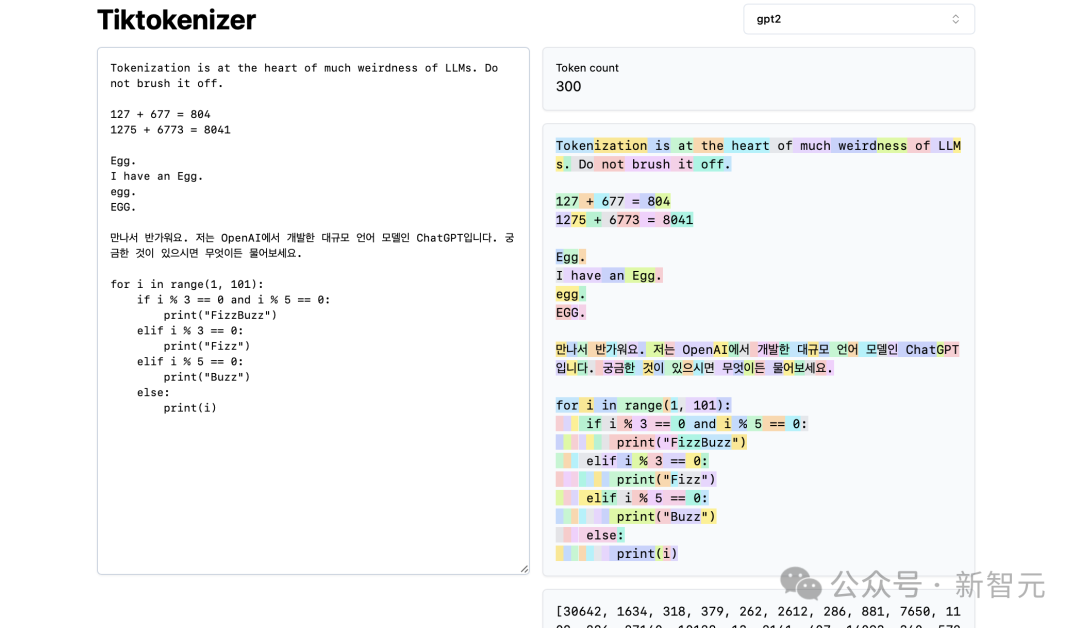
Par exemple, la chaîne "Tokenization" est codée en token30642, suivie du token 1634.
le jeton "is" (notez qu'il s'agit de trois caractères, y compris l'espace précédent, c'est important !) vaut 318.
Soyez prudent avec l'utilisation des espaces, car ils sont absolument présents dans la chaîne et doivent être rédigés avec tous les autres caractères. Cependant, il est généralement omis lors de la visualisation par souci de clarté.
Vous pouvez activer et désactiver sa fonction de visualisation en bas de l'application. De même, le jeton « à » vaut 379, « le » vaut 262, et ainsi de suite.
Ensuite, nous avons un exemple arithmétique simple.
Ici, nous voyons que le tokenizer peut être incohérent dans sa décomposition des nombres. Par exemple, le nombre 127 est un jeton à 3 caractères, mais le nombre 677 l'est car il y a 2 jetons : 6 (encore une fois, notez l'espace précédent) et 77.
Nous nous appuyons sur LLM pour expliquer cet arbitraire.
Il doit se renseigner sur ces deux jetons (6 et 77 se combinent en fait pour former le nombre 677) au sein de ses paramètres et lors de l'entraînement.
De même, on peut voir que si le LLM veut prédire que le résultat de cette somme est le nombre 804, il doit le sortir en deux pas de temps :
D'abord, il doit émettre le jeton "8" , puis c'est le jeton "04".
Veuillez noter que toutes ces répartitions semblent complètement arbitraires. Dans l'exemple ci-dessous, nous pouvons voir que 1275 est "12", puis "75", 6773 est en fait trois jetons "6", "77" et "3", et 8041 est "8" et "041" .
(À suivre...)
(À FAIRE : Si vous souhaitez continuer la version texte du contenu, à moins que nous trouvions comment la générer automatiquement à partir de la vidéo)

Les internautes sont en ligne pour donner des conseils
Les internautes ont dit : super, en fait, je préfère lire ces articles plutôt que de regarder des vidéos, c'est plus facile de contrôler mon propre rythme.

Certains internautes ont donné des conseils à Karpathy :
"Cela semble délicat, mais cela pourrait être possible en utilisant LangChain. Je me demandais si je pouvais utiliser la transcription chuchotée pour produire un plan de haut niveau avec des chapitres clairs, puis traiter ces morceaux de chapitre en parallèle, en me concentrant sur chacun dans le contexte. du plan général. Le contenu spécifique du bloc de chapitre (des images sont également générées pour chaque chapitre traité en parallèle. Ensuite, toutes les marques de référence générées sont compilées jusqu'à la fin de l'article via LLM. "

Quelqu'un a écrit un pipeline pour cela, et il sera bientôt open source.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravel Eloquent Orm dans Bangla Partial Model Search)
Apr 08, 2025 pm 02:06 PM
Laravelelognent Model Retrieval: Faconttement l'obtention de données de base de données Eloquentorm fournit un moyen concis et facile à comprendre pour faire fonctionner la base de données. Cet article présentera en détail diverses techniques de recherche de modèles éloquentes pour vous aider à obtenir efficacement les données de la base de données. 1. Obtenez tous les enregistrements. Utilisez la méthode All () pour obtenir tous les enregistrements dans la table de base de données: usApp \ Modèles \ Post; $ poters = post :: all (); Cela rendra une collection. Vous pouvez accéder aux données à l'aide de Foreach Loop ou d'autres méthodes de collecte: ForEach ($ PostsAs $ POST) {echo $ post->
