
 Périphériques technologiques
IA
Choisir le modèle d'intégration qui correspond le mieux à vos données : un test comparatif des intégrations multilingues OpenAI et open source
Périphériques technologiques
IA
Choisir le modèle d'intégration qui correspond le mieux à vos données : un test comparatif des intégrations multilingues OpenAI et open source
Choisir le modèle d'intégration qui correspond le mieux à vos données : un test comparatif des intégrations multilingues OpenAI et open source

OpenAI a récemment annoncé le lancement de son modèle d'intégration de dernière génération, l'intégration v3, qui, selon eux, est le modèle d'intégration le plus performant avec des performances multilingues plus élevées. Ce lot de modèles est divisé en deux types : les plus petits text-embeddings-3-small et les plus puissants et plus grands text-embeddings-3-large.

Très peu d'informations sont divulguées sur la façon dont ces modèles sont conçus et formés, et les modèles ne sont accessibles que via des API payantes. Il existe donc de nombreux modèles d'intégration open source. Mais comment ces modèles open source se comparent-ils au modèle open source OpenAI ?
Cet article comparera empiriquement les performances de ces nouveaux modèles avec des modèles open source. Nous prévoyons de créer un workflow de récupération de données dont la tâche clé est de trouver les documents les plus pertinents du corpus en fonction de la requête de l'utilisateur.
Notre corpus est la loi européenne sur l'intelligence artificielle, qui est actuellement en phase de validation. Ce corpus constitue le premier cadre juridique au monde impliquant l’intelligence artificielle et a la particularité d’être disponible en 24 langues. Cela nous permet de comparer l’exactitude de la récupération de données dans différents contextes linguistiques, fournissant ainsi un soutien important à l’application interculturelle de l’intelligence artificielle.
Nous prévoyons de créer un ensemble de données de questions/réponses synthétiques personnalisées à l'aide d'un corpus de texte multilingue et d'utiliser cet ensemble de données pour comparer la précision d'OpenAI et des modèles d'intégration open source de pointe. Nous partagerons le code complet car notre approche peut être facilement adaptée à d’autres corpus de données.
Générer un ensemble de données Q/A personnalisé
Tout d'abord, nous pouvons commencer par créer un ensemble de données de questions et réponses (Q/A) personnalisé. L'avantage de cette procédure est que cela garantit que l'ensemble de données le sera. ne fait pas partie de la formation du modèle Facteurs de biais pour éviter des situations similaires à celles qui peuvent se produire dans des références de référence telles que MTEB. De plus, en générant des ensembles de données personnalisés, nous pouvons adapter le processus d'évaluation à un corpus de données spécifique, ce qui peut être important pour des scénarios tels que les applications d'augmentation de récupération (RAG).
Nous suivrons le processus simple suggéré dans la documentation de Llama Index. Dans un premier temps, le corpus est divisé en morceaux. Ensuite, pour chaque bloc, un grand modèle de langage (LLM) est utilisé pour générer une série de questions synthétiques afin de garantir que la réponse se trouve dans le bloc correspondant.
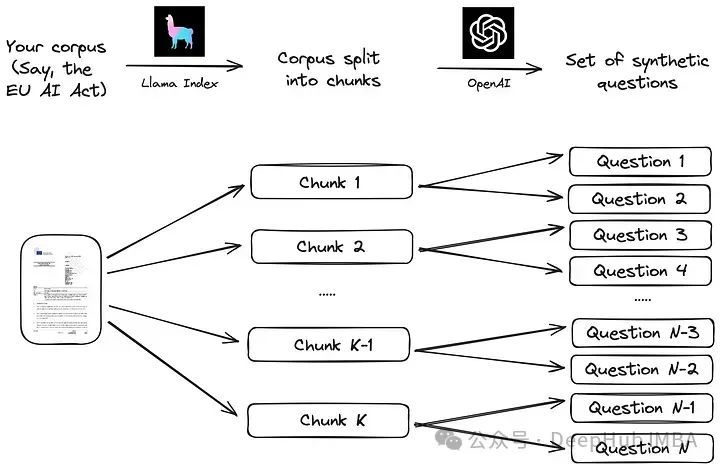
La mise en œuvre de cette stratégie à l'aide d'un bloc de données LLM comme Llama Index est très simple, comme le montre le code ci-dessous. Le corpus
from llama_index.readers.web import SimpleWebPageReader from llama_index.core.node_parser import SentenceSplitter language = "EN" url_doc = "https://eur-lex.europa.eu/legal-content/"+language+"/TXT/HTML/?uri=CELEX:52021PC0206" documents = SimpleWebPageReader(html_to_text=True).load_data([url_doc]) parser = SentenceSplitter(chunk_size=1000) nodes = parser.get_nodes_from_documents(documents, show_progress=True)
est la version anglaise de la loi européenne sur l'intelligence artificielle, obtenue directement du Web en utilisant cette URL officielle. Cet article utilise la version préliminaire d’avril 2021, car la version finale n’est pas encore disponible dans toutes les langues européennes. Ainsi, la version que nous avons choisie peut remplacer la langue de l'URL par l'une des 23 autres langues officielles de l'UE, en récupérant le texte dans différentes langues (BG pour le bulgare, ES pour l'espagnol, CS pour le tchèque, etc.).

Utilisez un objet SentenceSplitter pour diviser le document en morceaux de 1 000 jetons chacun. Pour l'anglais, cela génère environ 100 morceaux. Chaque morceau est ensuite donné comme contexte à l'invite suivante (l'invite par défaut suggérée dans la bibliothèque Llama Index) :
prompts={} prompts["EN"] = """\ Context information is below. --------------------- {context_str} --------------------- Given the context information and not prior knowledge, generate only questions based on the below query. You are a Teacher/ Professor. Your task is to setup {num_questions_per_chunk} questions for an upcoming quiz/examination. The questions should be diverse in nature across the document. Restrict the questions to the context information provided." """Cette invite peut générer des questions sur le morceau de document, avec le nombre de questions à générer pour chacun. data chunk as Le paramètre "num_questions_per_chunk" est passé et nous le définissons sur 2. Les questions peuvent ensuite être générées en appelant generate_qa_embedding_pairs dans la bibliothèque Llama Index :
from llama_index.llms import OpenAI from llama_index.legacy.finetuning import generate_qa_embedding_pairs qa_dataset = generate_qa_embedding_pairs(llm=OpenAI(model="gpt-3.5-turbo-0125",additional_kwargs={'seed':42}),nodes=nodes,qa_generate_prompt_tmpl = prompts[language],num_questions_per_chunk=2 )我们依靠OpenAI的GPT-3.5-turbo-0125来完成这项任务,结果对象' qa_dataset '包含问题和答案(块)对。作为生成问题的示例,以下是前两个问题的结果(其中“答案”是文本的第一部分):
- What are the main objectives of the proposal for a Regulation laying down harmonised rules on artificial intelligence (Artificial Intelligence Act) according to the explanatory memorandum?
- How does the proposal for a Regulation on artificial intelligence aim to address the risks associated with the use of AI while promoting the uptake of AI in the European Union, as outlined in the context information?
OpenAI嵌入模型
评估函数也是遵循Llama Index文档:首先所有答案(文档块)的嵌入都存储在VectorStoreIndex中,以便有效检索。然后评估函数循环遍历所有查询,检索前k个最相似的文档,并根据MRR (Mean Reciprocal Rank)评估检索的准确性,代码如下:
def evaluate(dataset, embed_model, insert_batch_size=1000, top_k=5):# Get corpus, queries, and relevant documents from the qa_dataset objectcorpus = dataset.corpusqueries = dataset.queriesrelevant_docs = dataset.relevant_docs # Create TextNode objects for each document in the corpus and create a VectorStoreIndex to efficiently store and retrieve embeddingsnodes = [TextNode(id_=id_, text=text) for id_, text in corpus.items()]index = VectorStoreIndex(nodes, embed_model=embed_model, insert_batch_size=insert_batch_size)retriever = index.as_retriever(similarity_top_k=top_k) # Prepare to collect evaluation resultseval_results = [] # Iterate over each query in the dataset to evaluate retrieval performancefor query_id, query in tqdm(queries.items()):# Retrieve the top_k most similar documents for the current query and extract the IDs of the retrieved documentsretrieved_nodes = retriever.retrieve(query)retrieved_ids = [node.node.node_id for node in retrieved_nodes] # Check if the expected document was among the retrieved documentsexpected_id = relevant_docs[query_id][0]is_hit = expected_id in retrieved_ids # assume 1 relevant doc per query # Calculate the Mean Reciprocal Rank (MRR) and append to resultsif is_hit:rank = retrieved_ids.index(expected_id) + 1mrr = 1 / rankelse:mrr = 0eval_results.append(mrr) # Return the average MRR across all queries as the final evaluation metricreturn np.average(eval_results)
嵌入模型通过' embed_model '参数传递给评估函数,对于OpenAI模型,该参数是一个用模型名称和模型维度初始化的OpenAIEmbedding对象。
from llama_index.embeddings.openai import OpenAIEmbedding embed_model = OpenAIEmbedding(model=model_spec['model_name'],dimensinotallow=model_spec['dimensions'])
dimensions参数可以缩短嵌入(即从序列的末尾删除一些数字),而不会失去嵌入的概念表示属性。OpenAI在他们的公告中建议,在MTEB基准测试中,嵌入可以缩短到256大小,同时仍然优于未缩短的text-embedding-ada-002嵌入(大小为1536)。
我们在四种不同的嵌入模型上运行评估函数:
两个版本的text-embedding-3-large:一个具有最低可能维度(256),另一个具有最高可能维度(3072)。它们被称为“OAI-large-256”和“OAI-large-3072”。
OAI-small:text-embedding-3-small,维数为1536。
OAI-ada-002:传统的文本嵌入text-embedding-ada-002,维度为1536。
每个模型在四种不同的语言上进行评估:英语(EN),法语(FR),捷克语(CS)和匈牙利语(HU),分别涵盖日耳曼语,罗曼语,斯拉夫语和乌拉尔语的例子。
embeddings_model_spec = { } embeddings_model_spec['OAI-Large-256']={'model_name':'text-embedding-3-large','dimensions':256} embeddings_model_spec['OAI-Large-3072']={'model_name':'text-embedding-3-large','dimensions':3072} embeddings_model_spec['OAI-Small']={'model_name':'text-embedding-3-small','dimensions':1536} embeddings_model_spec['OAI-ada-002']={'model_name':'text-embedding-ada-002','dimensions':None} results = [] languages = ["EN", "FR", "CS", "HU"] # Loop through all languages for language in languages: # Load datasetfile_name=language+"_dataset.json"qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name) # Loop through all modelsfor model_name, model_spec in embeddings_model_spec.items(): # Get modelembed_model = OpenAIEmbedding(model=model_spec['model_name'],dimensinotallow=model_spec['dimensions']) # Assess embedding score (in terms of MRR)score = evaluate(qa_dataset, embed_model) results.append([language, model_name, score]) df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR"])MRR精度如下:
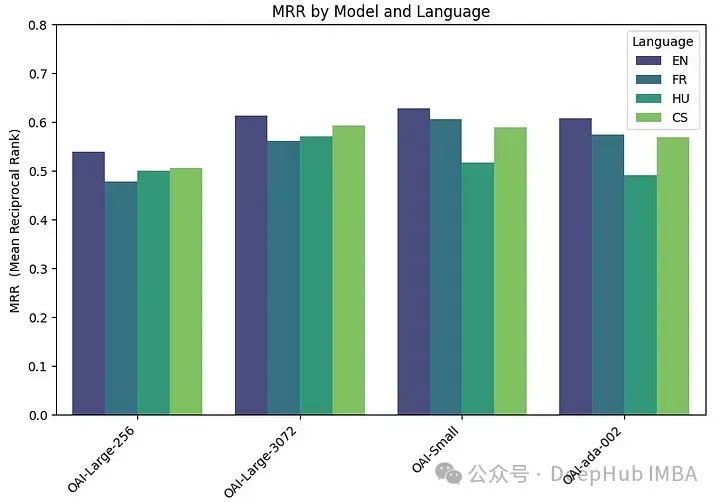
嵌入尺寸越大,性能越好。
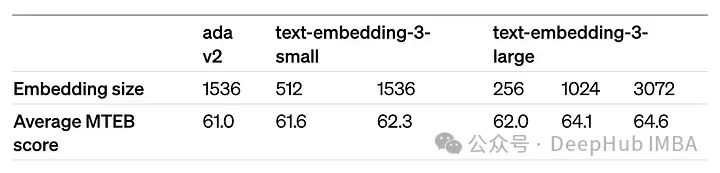
开源嵌入模型
围绕嵌入的开源研究也是非常活跃的,Hugging Face 的 MTEB leaderboard会经常发布最新的嵌入模型。
为了在本文中进行比较,我们选择了一组最近发表的四个嵌入模型(2024)。选择的标准是他们在MTEB排行榜上的平均得分和他们处理多语言数据的能力。所选模型的主要特性摘要如下。

e5-mistral-7b-instruct:微软的这个E5嵌入模型是从Mistral-7B-v0.1初始化的,并在多语言混合数据集上进行微调。模型在MTEB排行榜上表现最好,但也是迄今为止最大的(14GB)。
multilingual-e5-large-instruct(ML-E5-large):微软的另一个E5模型,可以更好地处理多语言数据。它从xlm-roberta-large初始化,并在多语言数据集的混合上进行训练。它比E5-Mistral小得多(10倍),上下文大小也小得多(514)。
BGE-M3:该模型由北京人工智能研究院设计,是他们最先进的多语言数据嵌入模型,支持100多种工作语言。截至2024年2月22日,它还没有进入MTEB排行榜。
nomic-embed-text-v1 (Nomic- embed):该模型由Nomic设计,其性能优于OpenAI Ada-002和text-embedding-3-small,而且大小仅为0.55GB。该模型是第一个完全可复制和可审计的(开放数据和开源训练代码)的模型。
用于评估这些开源模型的代码类似于用于OpenAI模型的代码。主要的变化在于模型参数:
embeddings_model_spec = { } embeddings_model_spec['E5-mistral-7b']={'model_name':'intfloat/e5-mistral-7b-instruct','max_length':32768, 'pooling_type':'last_token', 'normalize': True, 'batch_size':1, 'kwargs': {'load_in_4bit':True, 'bnb_4bit_compute_dtype':torch.float16}} embeddings_model_spec['ML-E5-large']={'model_name':'intfloat/multilingual-e5-large','max_length':512, 'pooling_type':'mean', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}} embeddings_model_spec['BGE-M3']={'model_name':'BAAI/bge-m3','max_length':8192, 'pooling_type':'cls', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'torch_dtype':torch.float16}} embeddings_model_spec['Nomic-Embed']={'model_name':'nomic-ai/nomic-embed-text-v1','max_length':8192, 'pooling_type':'mean', 'normalize': True, 'batch_size':1, 'kwargs': {'device_map': 'cuda', 'trust_remote_code' : True}} results = [] languages = ["EN", "FR", "CS", "HU"] # Loop through all models for model_name, model_spec in embeddings_model_spec.items(): print("Processing model : "+str(model_spec)) # Get modeltokenizer = AutoTokenizer.from_pretrained(model_spec['model_name'])embed_model = AutoModel.from_pretrained(model_spec['model_name'], **model_spec['kwargs']) if model_name=="Nomic-Embed":embed_model.to('cuda') # Loop through all languagesfor language in languages: # Load datasetfile_name=language+"_dataset.json"qa_dataset = EmbeddingQAFinetuneDataset.from_json(file_name) start_time_assessment=time.time() # Assess embedding score (in terms of hit rate at k=5)score = evaluate(qa_dataset, tokenizer, embed_model, model_spec['normalize'], model_spec['max_length'], model_spec['pooling_type']) # Get duration of score assessmentduration_assessment = time.time()-start_time_assessment results.append([language, model_name, score, duration_assessment]) df_results = pd.DataFrame(results, columns = ["Language" ,"Embedding model", "MRR", "Duration"])Les résultats sont les suivants :
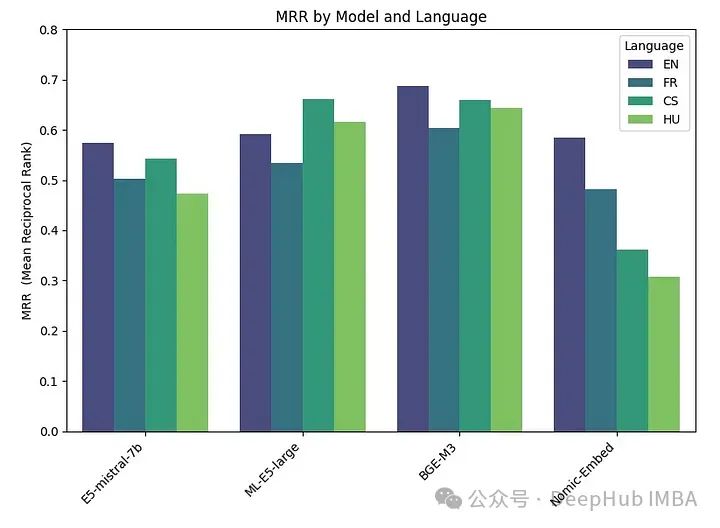
BGE-M3 a obtenu les meilleurs résultats, suivi de ML-E5-Large, E5-mistral-7b et Nomic-Embed. Le modèle BGE-M3 n'a pas encore été comparé au classement MTEB et nos résultats indiquent qu'il pourrait être mieux classé que les autres modèles. Bien que le BGE-M3 soit optimisé pour les données multilingues, il fonctionne également mieux en anglais que les autres modèles.
Parce que les modèles open source doivent généralement être exécutés localement, nous avons également délibérément enregistré le temps de traitement de chaque modèle embarqué.
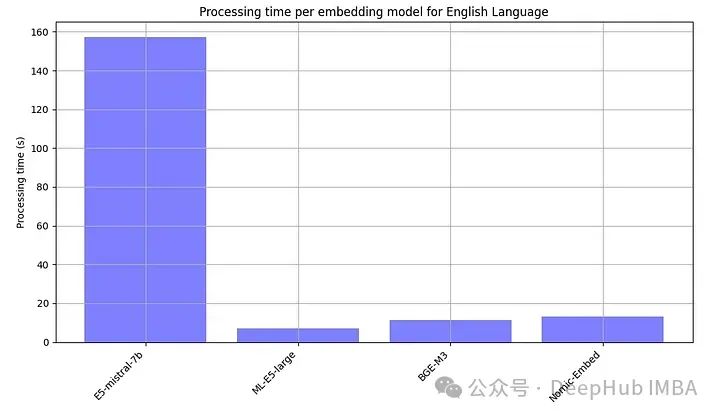
E5-mistral-7b est plus de 10 fois plus grand que les autres modèles, donc le plus lent est normal
Résumé
Nous résumons tous les résultats
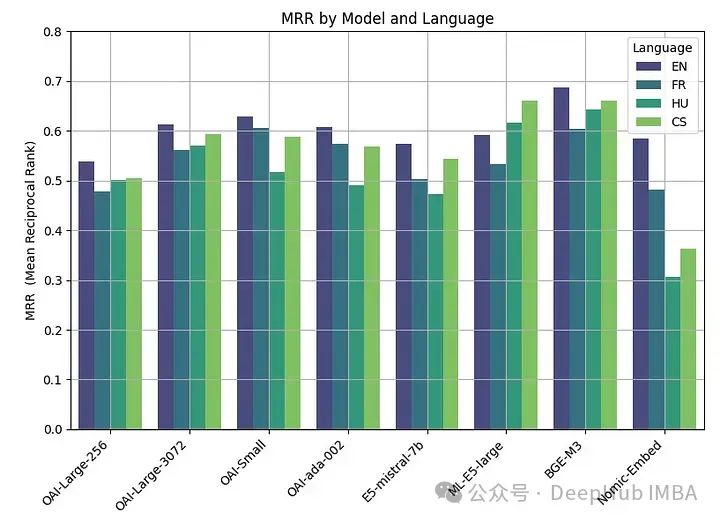
Le meilleur les performances ont été obtenues à l'aide de modèles open source, le modèle BGE-M3 étant le plus performant. Ce modèle a la même longueur de contexte (8 Ko) que le modèle OpenAI et sa taille est de 2,2 Go.
Les performances des modèles grand (3072), petit et ada d'OpenAI sont très similaires. Réduire la taille d'intégration de grande taille (256) entraîne une dégradation des performances et n'est pas aussi efficace que le dit OpenAI.
Presque tous les modèles (sauf ML-E5-large) fonctionnent mieux en anglais. Dans des langues comme le tchèque et le hongrois, il existe des différences de performances significatives, peut-être parce qu'il y a moins de données sur lesquelles s'entraîner.
Devrions-nous payer pour un abonnement OpenAI ou héberger un modèle embarqué open source
Le récent ajustement de prix d'OpenAI a rendu son API plus abordable, coûtant désormais 0,13 $ par million de jetons ? Si vous traitez un million de requêtes par mois (en supposant que chaque requête implique environ 1 000 jetons), le coût est d'environ 130 $. Par conséquent, vous pouvez choisir d'héberger ou non le modèle d'intégration open source en fonction des besoins réels.
Bien sûr, la rentabilité n’est pas la seule considération. D'autres facteurs tels que la latence, la confidentialité et le contrôle des flux de traitement des données peuvent également devoir être pris en compte. Le modèle open source offre les avantages d’un contrôle complet des données, d’une confidentialité et d’une personnalisation améliorées.
En parlant de latence, l'API d'OpenAI présente également des problèmes de latence, ce qui entraîne parfois des temps de réponse prolongés, donc parfois l'API d'OpenAI n'est pas nécessairement le choix le plus rapide.
En conclusion, choisir entre des modèles open source et des solutions propriétaires comme OpenAI n'est pas une réponse simple. L'intégration open source offre une excellente option qui combine performances et meilleur contrôle sur vos données. Et les produits d'OpenAI peuvent toujours plaire à ceux qui privilégient la commodité, surtout si les préoccupations en matière de confidentialité sont secondaires.
Code de cet article : https://github.com/Yannael/multilingual-embeddings
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
SK Hynix présentera de nouveaux produits liés à l'IA le 6 août : HBM3E à 12 couches, NAND à 321 hauteurs, etc.
Aug 01, 2024 pm 09:40 PM
Selon les informations de ce site le 1er août, SK Hynix a publié un article de blog aujourd'hui (1er août), annonçant sa participation au Global Semiconductor Memory Summit FMS2024 qui se tiendra à Santa Clara, Californie, États-Unis, du 6 au 8 août, présentant de nombreuses nouvelles technologies de produit. Introduction au Future Memory and Storage Summit (FutureMemoryandStorage), anciennement Flash Memory Summit (FlashMemorySummit) principalement destiné aux fournisseurs de NAND, dans le contexte de l'attention croissante portée à la technologie de l'intelligence artificielle, cette année a été rebaptisée Future Memory and Storage Summit (FutureMemoryandStorage) pour invitez les fournisseurs de DRAM et de stockage et bien d’autres joueurs. Nouveau produit SK hynix lancé l'année dernière
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
