
 Périphériques technologiques
IA
La fenêtre contextuelle de 10 millions de Google tue RAG ? Les Gémeaux sont-ils sous-estimés après avoir été volés par Sora ?
Périphériques technologiques
IA
La fenêtre contextuelle de 10 millions de Google tue RAG ? Les Gémeaux sont-ils sous-estimés après avoir été volés par Sora ?
La fenêtre contextuelle de 10 millions de Google tue RAG ? Les Gémeaux sont-ils sous-estimés après avoir été volés par Sora ?

Pour être considérée comme l'entreprise la plus déprimante ces derniers temps, Google en fait certainement partie : la sienne Gemini 1.5 vient de sortir, et elle a été volée par Sora d'OpenAI, qui peut être appelé le « Wang Feng » dans l'industrie de l'IA.
Plus précisément, ce que Google a lancé cette fois est la première version de Gemini 1.5 pour les premiers tests - Gemini 1.5 Pro. Il s'agit d'un modèle multimodal de taille moyenne (texte, vidéo, audio) avec des niveaux de performances similaires au plus grand modèle de Google à ce jour, 1.0 Ultra, et introduit des fonctionnalités expérimentales révolutionnaires dans la compréhension du contexte long. Il peut gérer de manière stable jusqu'à 1 million de jetons (équivalent à 1 heure de vidéo, 11 heures d'audio, plus de 30 000 lignes de code ou 700 000 mots), avec une limite de 10 millions de jetons (équivalent au « Seigneur des Anneaux »). " trilogie), Établissez un record pour la fenêtre contextuelle la plus longue.
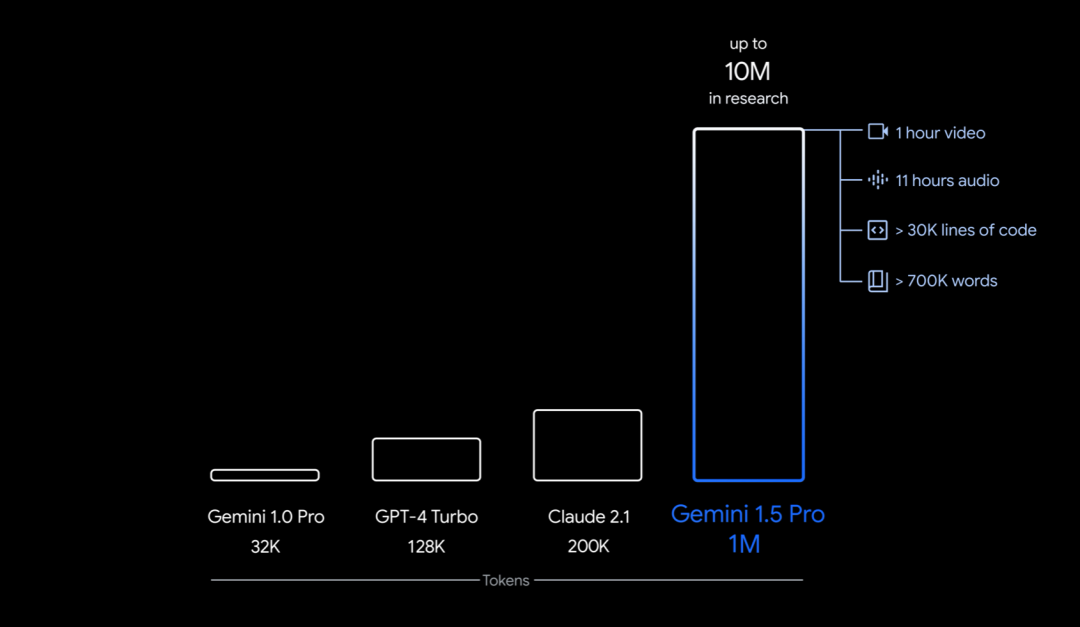
De plus, il peut également apprendre la traduction d'une petite langue avec seulement un livre de grammaire de 500 pages, 2000 entrées bilingues et 400 phrases parallèles supplémentaires (il n'y a pas d'informations pertinentes sur Internet), Réaliser un niveau proche de celui des apprenants humains en traduction.
Beaucoup de personnes qui ont utilisé le Gemini 1.5 Pro pensent que ce modèle est sous-estimé. Quelqu'un a mené une expérience et a saisi la base de code complète téléchargée depuis Github et les problèmes associés dans Gemini 1.5 Pro. Les résultats ont été surprenants : non seulement il a compris l'intégralité de la base de code, mais il a également été capable d'identifier les problèmes les plus urgents et de les résoudre. .
Dans un autre test lié au code, Gemini 1.5 Pro a démontré d'excellentes capacités de recherche, étant capable de trouver rapidement les exemples les plus pertinents dans la base de code. De plus, il démontre une solide compréhension et est capable de trouver avec précision le code qui contrôle les animations et de fournir des suggestions de code personnalisées. De même, Gemini 1.5 Pro a également démontré d'excellentes capacités multimodes, étant capable d'identifier le contenu de démonstration via des captures d'écran et de fournir des conseils pour l'édition du code d'image.

Un tel modèle devrait attirer l’attention de tous. De plus, il convient de noter que la capacité de Gemini 1.5 Pro à gérer des contextes ultra-longs a également amené de nombreux chercheurs à se demander si la méthode RAG traditionnelle est toujours nécessaire ?
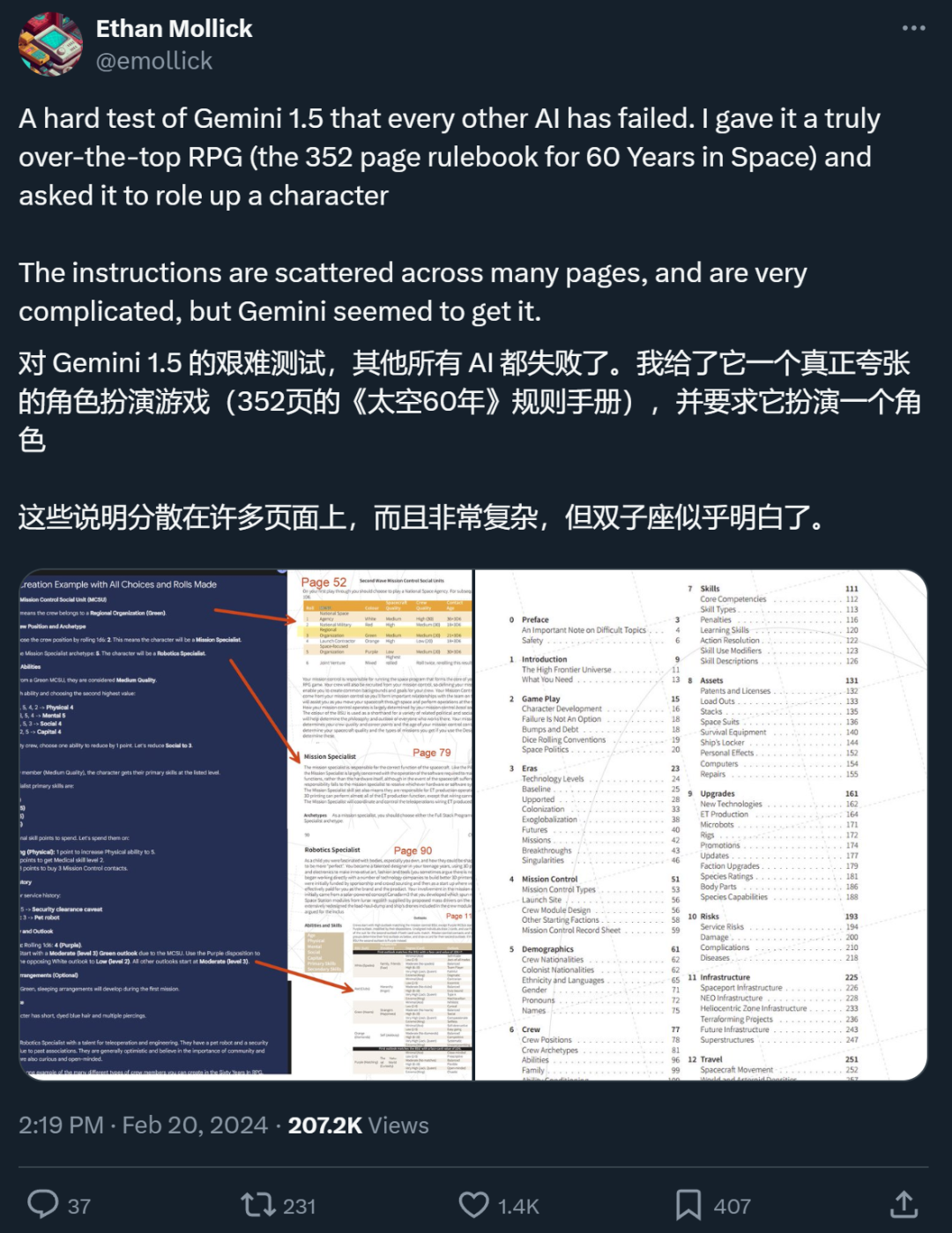
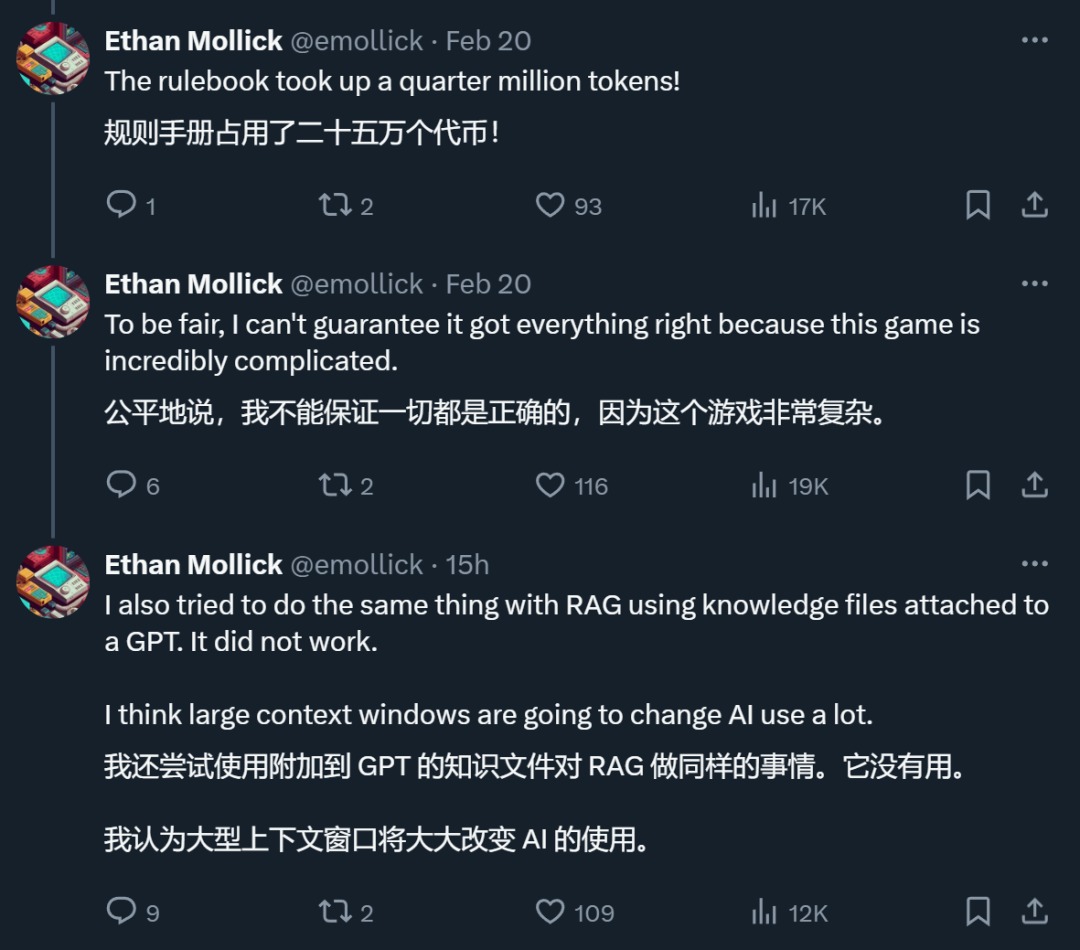
Un internaute X a déclaré que dans un test qu'il a effectué, Gemini 1.5 Pro, qui prend en charge un contexte ultra-long, a effectivement fait ce que RAG ne pouvait pas faire.
RAG va être tué par le modèle à contexte long ?
"Un modèle avec une fenêtre de contexte de 10 millions de jetons rend inutiles la plupart des frameworks RAG existants, c'est-à-dire qu'un contexte de 10 millions de jetons tue RAG", a écrit Fu Yao, doctorant à l'Université d'Édimbourg dans un article examinant Gemini 1.5. Pro.

RAG est l'abréviation de « Retrieval-Augmented Generation », qui peut être traduit par « Retrieval-Augmented Generation » en chinois. RAG se compose généralement de deux étapes : récupérer des informations contextuelles et utiliser les connaissances récupérées pour guider le processus de génération. Par exemple, en tant qu'employé, vous pouvez demander directement au grand modèle : « Quelles sont les pénalités en cas de retard dans notre entreprise ? » Sans lire le « Manuel de l'employé », le grand modèle n'a aucun moyen de répondre. Cependant, avec l'aide de la méthode RAG, nous pouvons d'abord laisser un modèle de recherche rechercher les réponses les plus pertinentes dans le « Manuel de l'employé », puis envoyer votre question et les réponses pertinentes qu'il a trouvées au modèle de génération, permettant ainsi au grand modèle pour générer une réponse. Cela résout le problème selon lequel la fenêtre contextuelle de nombreux grands modèles précédents n'était pas assez grande (par exemple, elle ne pouvait pas accueillir le « Manuel de l'employé »), mais RAGfangfa manquait de capture des connexions subtiles entre les contextes.
Fu Yao estime que si un modèle peut traiter directement les informations contextuelles de 10 millions de jetons, il n'est pas nécessaire de passer par des étapes de récupération supplémentaires pour trouver et intégrer les informations pertinentes. Les utilisateurs peuvent placer toutes les données dont ils ont besoin directement dans le modèle en tant que contexte, puis interagir avec le modèle comme d'habitude. "Le grand modèle de langage lui-même est déjà un moteur de recherche très puissant, alors pourquoi s'embêter à créer un moteur de recherche faible et consacrer beaucoup d'énergie d'ingénierie au découpage, à l'intégration, à l'indexation, etc.?", a-t-il continué à écrire.

Cependant, les opinions de Fu Yao ont été réfutées par de nombreux chercheurs. Il a déclaré que bon nombre des objections étaient raisonnables, et il a également systématiquement trié ces opinions :
1. Problème de coût : les critiques ont souligné que RAG est moins cher que le modèle à contexte long. Fu Yao l'a reconnu, mais il a comparé l'histoire du développement de différentes technologies, soulignant que même si les modèles à faible coût (tels que BERT-small ou n-gram) sont effectivement bon marché, dans l'histoire du développement de l'IA, le coût des technologies avancées finira par diminuer. Son point de vue est de rechercher d'abord les performances des modèles intelligents, puis de réduire les coûts grâce au progrès technologique, car il est beaucoup plus facile de rendre les modèles intelligents bon marché que de rendre intelligents les modèles bon marché.
2. Intégration de la récupération et du raisonnement : Fu Yao a souligné que le modèle de contexte long est capable de mélanger la récupération et le raisonnement tout au long du processus de décodage, tandis que RAG n'effectue la récupération qu'au début. Le modèle de contexte long peut être récupéré au niveau de chaque couche et de chaque jeton, ce qui signifie que le modèle peut déterminer dynamiquement les informations à récupérer sur la base des résultats de l'inférence préliminaire, permettant ainsi une intégration plus étroite de la récupération et de l'inférence.
3. Nombre de jetons pris en charge : bien que le nombre de jetons pris en charge par RAG ait atteint le niveau du billion et que le modèle de contexte long prenne actuellement en charge le niveau du million, Fu Yao estime que dans les documents d'entrée naturellement distribués, la plupart d'entre eux nécessitent Les conditions de recherche sont toutes inférieures au niveau du million. Il a cité comme exemples l'analyse de documents juridiques et l'apprentissage automatique et a estimé que le volume d'entrée dans ces cas ne dépasserait pas des millions.

4. Mécanisme de mise en cache : Concernant le problème selon lequel le modèle de contexte long nécessite de ressaisir l'intégralité du document, Fu Yao a souligné qu'il existe un mécanisme de mise en cache dit KV (valeur clé), qui peut concevoir hiérarchies complexes de cache et de mémoire pour effectuer l'entrée. Il ne doit être lu qu'une seule fois et les requêtes ultérieures peuvent réutiliser le cache KV. Il a également mentionné que même si les caches KV peuvent être volumineux, il est optimiste quant à l'émergence d'algorithmes de compression de cache KV efficaces à l'avenir.
5. La nécessité d'appeler les moteurs de recherche : Il a admis qu'à court terme, appeler les moteurs de recherche pour la récupération est toujours nécessaire. Cependant, il a proposé une idée audacieuse, qui consiste à laisser le modèle de langage accéder directement à l'intégralité de l'index de recherche Google pour absorber toutes les informations, ce qui reflète la grande imagination du potentiel futur de la technologie de l'IA.
6. Problèmes de performances : Fu Yao a admis que le Gemini 1.5 actuel est lent lors du traitement du contexte 1M, mais il est optimiste quant à l'amélioration de la vitesse et pense que la vitesse du modèle de contexte long sera considérablement améliorée à l'avenir, et peut éventuellement atteindre le même niveau que la vitesse RAG.

En plus de Fu Yao, de nombreux autres chercheurs ont également exprimé leur point de vue sur les perspectives de RAG sur la plateforme X, comme le blogueur IA @elvis.
En général, il ne pense pas que le modèle de contexte long puisse remplacer RAG. Les raisons incluent :
1. Défis de types de données spécifiques : @elvis a proposé un scénario dans lequel les données ont une structure complexe et. change régulièrement et a une dimension temporelle importante (telle que les modifications/modifications de code et les journaux Web). Ce type de données peut être connecté à des points de données historiques, et éventuellement à d'autres points de données à l'avenir. @elvis estime que les modèles de langage à contexte long d'aujourd'hui ne peuvent pas gérer à eux seuls les cas d'utilisation qui reposent sur de telles données, car les données peuvent être trop complexes pour LLM et la fenêtre de contexte maximale actuelle n'est pas réalisable pour de telles données. Lorsque vous traitez ce type de données, vous pourriez avoir besoin d’un mécanisme de récupération intelligent.
2. Traitement des informations dynamiques : le LLM à contexte long actuel fonctionne bien dans le traitement des informations statiques (telles que les livres, les enregistrements vidéo, les PDF, etc.), mais n'a pas encore été testé en pratique lorsqu'il s'agit de traiter des informations hautement dynamiques. informations et connaissances. @elvis estime que même si nous progresserons vers la résolution de certains défis (tels que "perdu au milieu") et le traitement de données structurées et dynamiques plus complexes, il nous reste encore un long chemin à parcourir.

3. @elvis a proposé que, afin de résoudre ces types de problèmes, RAG et LLM à contexte long puissent être combinés pour construire un système puissant capable de récupérer et d'analyser de manière efficace et efficiente les informations historiques clés. Il a souligné que même cela pourrait ne pas suffire dans de nombreux cas. D’autant plus que de grandes quantités de données peuvent évoluer rapidement, les agents basés sur l’IA ajoutent encore plus de complexité. @elvis pense que pour les cas d'utilisation complexes, il s'agira probablement d'une combinaison de ces idées plutôt que d'un LLM à usage général ou à long contexte remplaçant tout.
4. Demande pour différents types de LLM : @elvis a souligné que toutes les données ne sont pas statiques et que de nombreuses données sont dynamiques. Lorsque vous envisagez ces applications, gardez à l’esprit les trois V du Big Data : vitesse, volume et variété. @elvis a appris cette leçon grâce à son expérience de travail dans une société de recherche. Il pense que différents types de LLM aideront à résoudre différents types de problèmes, et nous devons nous éloigner de l'idée qu'un seul LLM les gouvernera tous.

@elvis a terminé en citant Oriol Vinyals (vice-président de la recherche chez Google DeepMind), déclarant que même maintenant que nous sommes capables de gérer des contextes de 1 million de jetons ou plus, l'ère du RAG est loin d'être sur. RAG possède en fait des fonctionnalités très intéressantes. Non seulement ces propriétés peuvent être améliorées par des modèles de contexte longs, mais les modèles de contexte longs peuvent également être améliorés par RAG. RAG nous permet de trouver des informations pertinentes, mais la manière dont le modèle accède à ces informations peut devenir trop restreinte en raison de la compression des données. Le modèle à contexte long peut aider à combler cette lacune, de la même manière que la façon dont le cache L1/L2 et la mémoire principale fonctionnent ensemble dans les processeurs modernes. Dans ce modèle collaboratif, le cache et la mémoire principale jouent chacun des rôles différents mais se complètent, augmentant ainsi la vitesse et l'efficacité du traitement. De même, l'utilisation combinée de RAG et d'un contexte long peut permettre une récupération et une génération d'informations plus flexibles et plus efficaces, en exploitant pleinement leurs avantages respectifs pour gérer des données et des tâches complexes.

Il semble que "si l'ère RAG touche à sa fin" n'ait pas encore été décidé. Mais beaucoup de gens disent que le Gemini 1.5 Pro est vraiment sous-estimé en tant que modèle à fenêtre contextuelle extra-longue. @elvis a également donné les résultats de ses tests.
Rapport d'évaluation préliminaire de Gemini 1.5 Pro
Capacités d'analyse de documents longs
Pour démontrer la capacité de Gemini 1.5 Pro à traiter et analyser des documents, @elvis a commencé avec une tâche de réponse à des questions très basique. Il a téléchargé un fichier PDF et posé une question simple : de quoi parle cet article ?
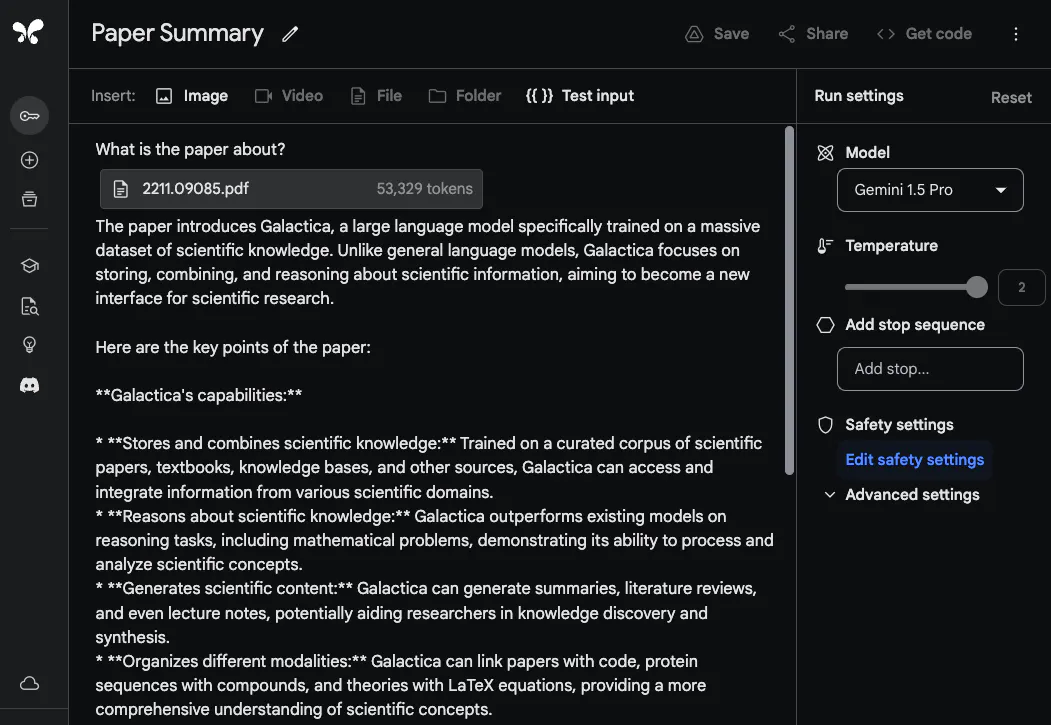
La réponse du modèle est précise et concise car elle fournit un résumé acceptable de l'article Galactica. L'exemple ci-dessus utilise des invites de forme libre dans Google AI Studio, mais vous pouvez également utiliser le format de chat pour interagir avec les PDF téléchargés. Il s'agit d'une fonctionnalité très utile si vous avez de nombreuses questions auxquelles vous aimeriez répondre à partir de la documentation fournie.
Pour profiter pleinement de la longue fenêtre contextuelle, @elvis a ensuite téléchargé deux PDF à des fins de test et a posé une question couvrant les deux PDF. La réponse donnée par
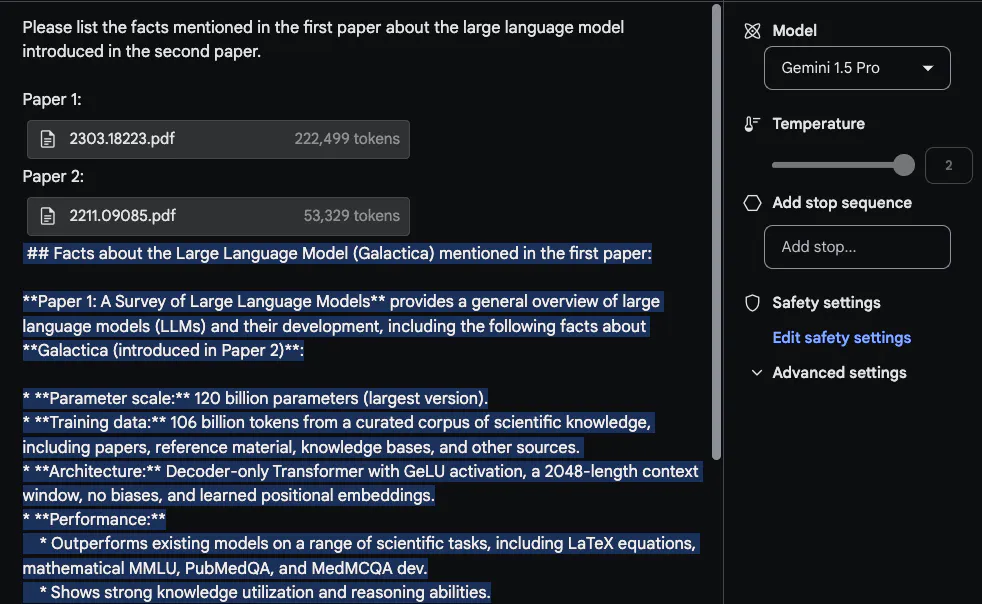
Gemini 1.5 Pro est raisonnable. Il est intéressant de noter que les informations extraites du premier article (un article de synthèse sur le LLM) proviennent d'un tableau. Les informations « architecture » semblent également correctes. Cependant, la partie « Performance » n’a pas sa place ici car elle n’était pas incluse dans le premier article. Dans cette tâche, il est important de placer l'invite « Veuillez lister les faits mentionnés dans le premier article concernant le grand modèle de langage introduit dans le deuxième article » en haut et d'étiqueter le document, par exemple « Papier 1 » et « Papier 2 ». ". Une autre tâche de suivi connexe à ce laboratoire consiste à rédiger un travail connexe en téléchargeant un ensemble d'articles et des instructions sur la façon de les résumer. Une autre tâche intéressante demandait au modèle d'inclure les articles LLM les plus récents dans une revue.
Video Understanding
Gemini 1.5 Pro est formé dès le départ sur les données multimodales. @elvis a testé quelques invites à l'aide de la récente vidéo de la conférence LLM d'Andrej Karpathy :
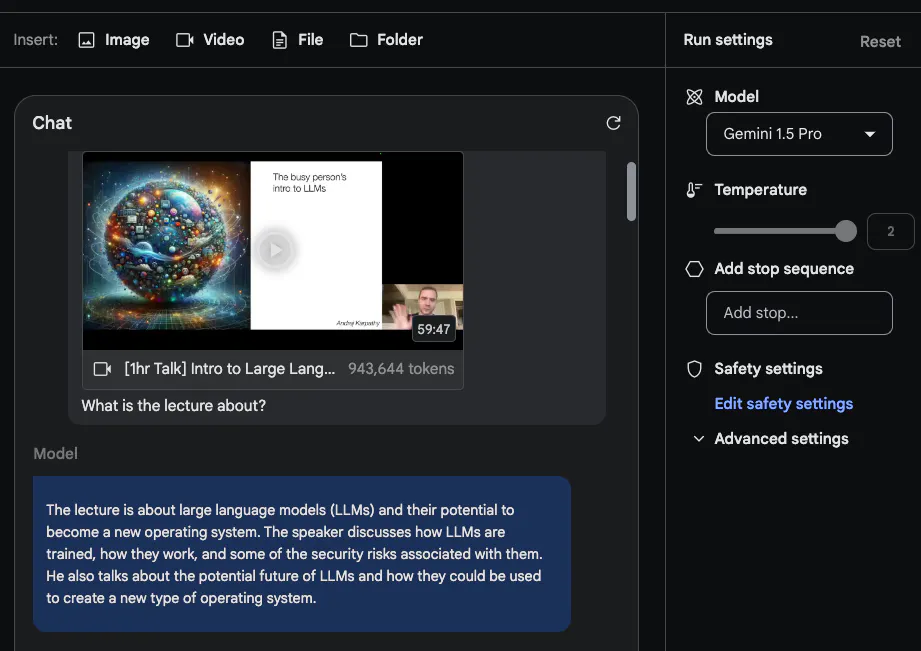
La deuxième tâche qu'il a demandé au modèle d'accomplir était de fournir un aperçu concis et concis de la conférence (une page). Les réponses sont les suivantes (éditées par souci de concision) :

Le résumé donné par Gemini 1.5 Pro est très concis et résume bien le contenu de la conférence et les points clés.
Lorsque des détails spécifiques sont importants, veuillez noter que les modèles peuvent parfois « halluciner » ou récupérer des informations incorrectes pour diverses raisons. Par exemple, lorsque l'on pose la question suivante au modèle : "Quels sont les FLOP signalés pour Llama 2 dans la conférence ?", sa réponse est "La conférence rapporte que la formation de Llama 2 70B nécessite environ 1 000 milliards de FLOP", ce qui est inexact. La bonne réponse devrait être "~1e24 FLOP". Le rapport technique contient de nombreux exemples de cas où ces modèles à contexte long trébuchent lorsqu'on leur pose des questions spécifiques sur les vidéos.
La tâche suivante consiste à extraire les informations du tableau de la vidéo. Les résultats des tests montrent que le modèle est capable de générer des tableaux avec certains détails corrects et d'autres incorrects. Par exemple, les colonnes du tableau sont correctes, mais l'étiquette de l'une des lignes est erronée (c'est-à-dire que la résolution du concept doit être la résolution Coref). Les testeurs ont testé certaines de ces tâches d'extraction avec d'autres tableaux et d'autres éléments différents (tels que des zones de texte) et ont trouvé des incohérences similaires.
Un exemple intéressant documenté dans le rapport technique est la capacité du modèle à récupérer les détails d'une vidéo en fonction d'une scène ou d'un horodatage spécifique. Dans le premier exemple, le testeur demande au modèle où commence une certaine partie. Le modèle a répondu correctement.
Dans l'exemple suivant, il a demandé au modèle d'expliquer un graphique dans la diapositive. Le modèle semble faire bon usage des informations fournies pour expliquer les résultats dans le graphique.

Voici des instantanés des diapositives correspondantes :
@elvis a déclaré qu'il avait commencé la deuxième série de tests et que les étudiants intéressés peuvent se rendre sur la plateforme X pour regarder.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
