
 Périphériques technologiques
IA
L'interprétation approfondie de Nanda Yu Yang : Qu'est-ce qu'un « modèle mondial » ?
Périphériques technologiques
IA
L'interprétation approfondie de Nanda Yu Yang : Qu'est-ce qu'un « modèle mondial » ?
L'interprétation approfondie de Nanda Yu Yang : Qu'est-ce qu'un « modèle mondial » ?

Avec le battage médiatique autour de Sora, le matériel d'introduction d'OpenAI qualifie Sora de « simulateur mondial ». Le terme modèle mondial est réapparu, mais il existe peu d'articles présentant les modèles mondiaux.
Ici, nous passons en revue ce qu'est un modèle mondial et discutons si Sora est un simulateur de monde.
Que sont les modèles du monde/modèles du monde
Quand les mots monde/monde et environnement/environnement sont évoqués dans le domaine de l'IA, c'est généralement pour les distinguer des agents/agents.
Les domaines faisant l'objet du plus grand nombre de recherches sur les agents sont l'apprentissage par renforcement et la robotique.
Vous pouvez donc constater que les modèles du monde et la modélisation du monde apparaissent le plus tôt et le plus souvent dans les articles dans le domaine de la robotique.
Le mot modèles du monde qui a le plus grand impact aujourd'hui est peut-être cet article intitulé « modèles du monde » que Jurgen a publié sur arxiv en 2018. L'article a finalement été publié dans NeurIPS'18.

L'article ne définit pas ce que sont les modèles mondiaux, mais fait une analogie avec le modèle mental du cerveau humain dans les sciences cognitives, citant la littérature de 1971.

le modèle mental est l'image miroir du cerveau humain du monde environnant
Le modèle mental présenté dans Wikipédia souligne clairement qu'il peut participer aux processus de cognition, de raisonnement et de prise de décision. Et lorsqu’il s’agit de modèle mental, il comprend principalement deux parties : les représentations mentales et la simulation mentale.
une représentation interne de la réalité externe, supposée jouer un rôle majeur dans la cognition, le raisonnement et la prise de décision. Le terme a été inventé par Kenneth Craik en 1943 qui a suggéré que l'esprit construit des « modèles à petite échelle » de la réalité. il utilise pour anticiper les événements.
C'est encore un peu déroutant à ce stade, mais le diagramme de structure dans le document explique clairement ce qu'est un modèle mondial.
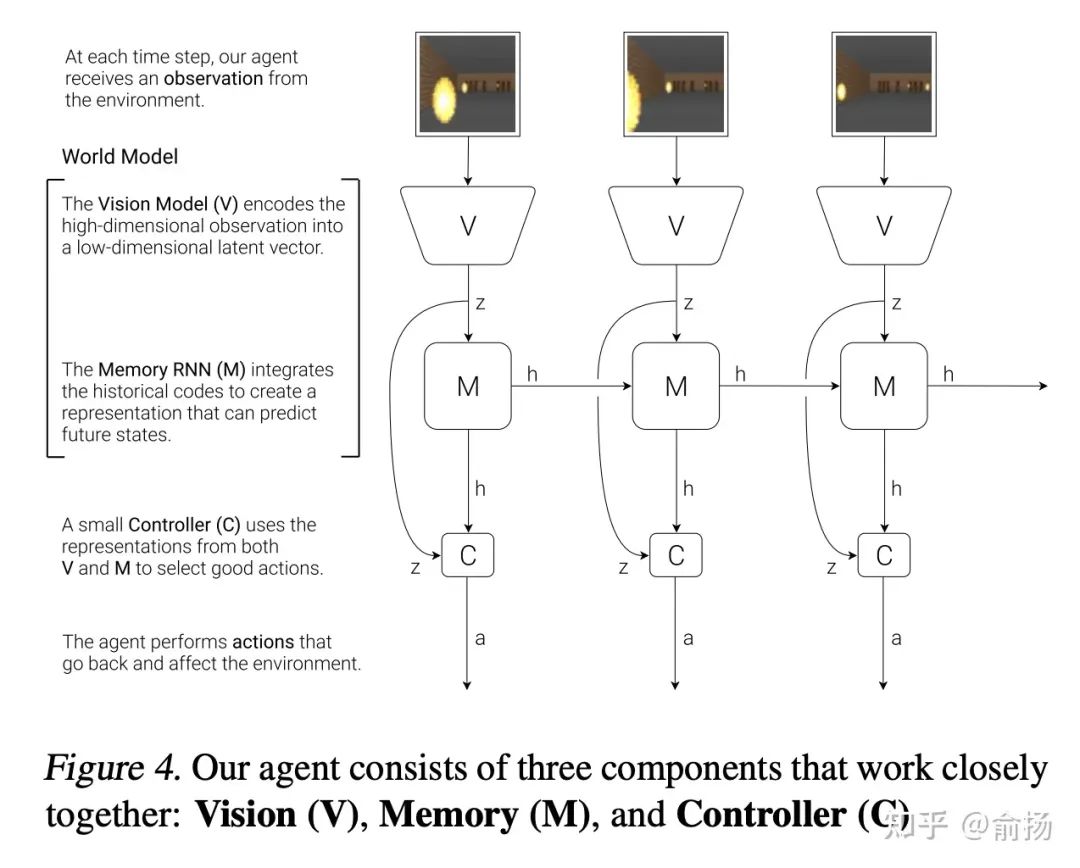
Dans la figure, le V->z vertical est la représentation de faible dimension de l'observation, qui est implémentée par VAE. Le M->h->M->h horizontal est. la représentation du prochain moment prédit de la séquence, implémentée avec RNN, les deux parties s'additionnent pour former le modèle mondial.
En d'autres termes, le modèle Monde comprend principalement la représentation d'état et le modèle de transition, qui correspond également aux représentations mentales et à la simulation mentale.
Quand vous voyez l’image ci-dessus, vous pensez peut-être : toutes les prédictions de séquences ne sont-elles pas des modèles mondiaux ?
En fait, les étudiants qui sont familiers avec l'apprentissage par renforcement peuvent voir en un coup d'œil que la structure de cette image est fausse (incomplète), et la vraie structure est l'image ci-dessous. L'entrée de RNN n'est pas seulement z, mais. aussi de l'action. Ce n'est pas la prédiction de séquence habituelle (l'ajout d'une action fera-t-il une grande différence ? Oui, l'ajout d'une action permet à la distribution des données de changer librement, ce qui pose d'énormes défis).
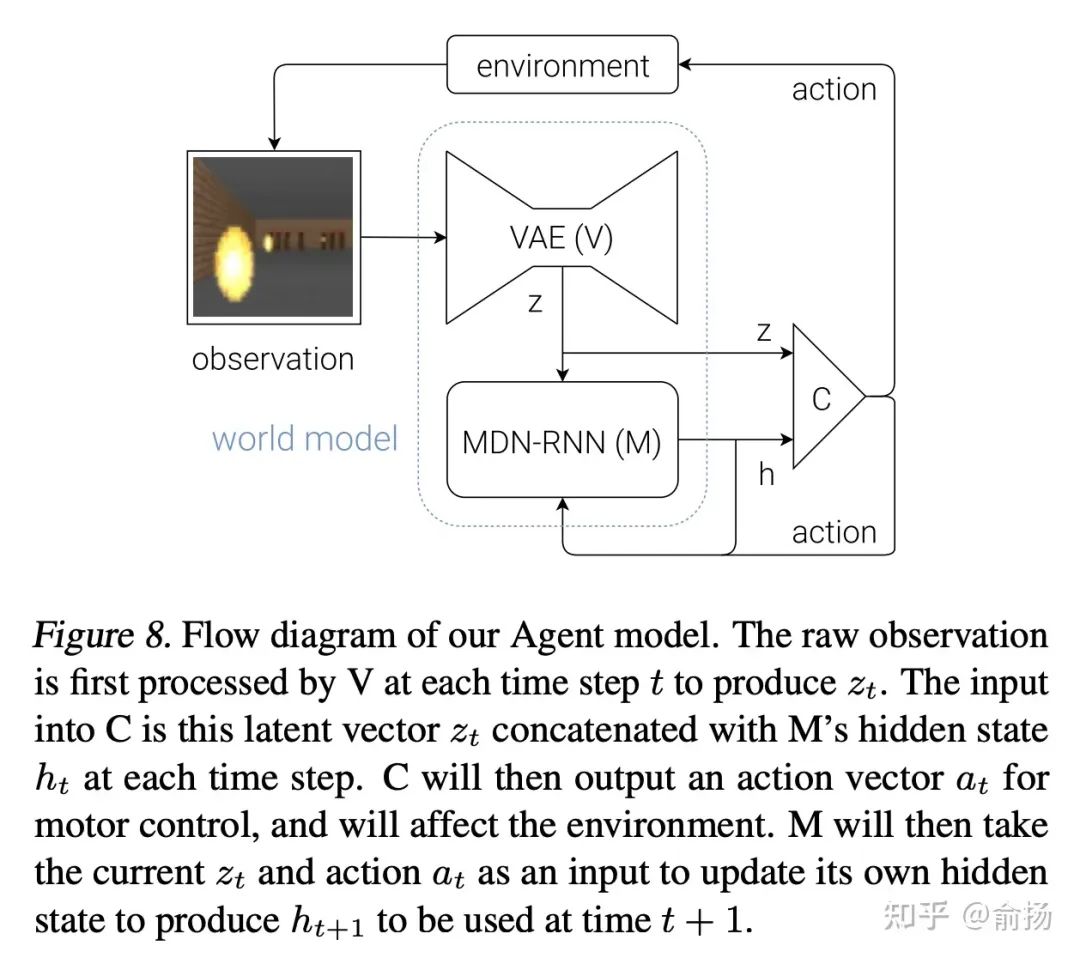
L'article de Jurgen appartient au domaine de l'apprentissage par renforcement.
Alors, n'y a-t-il pas beaucoup de RL basés sur des modèles en apprentissage par renforcement ? Quelle est la différence entre le modèle et le modèle mondial ? La réponse est qu’il n’y a pas de différence, c’est la même chose. Jurgen a dit quelque chose en premier

Le sens fondamental est que peu importe le nombre de travaux RL basés sur des modèles, je suis un pionnier du RNN pour créer des modèles, et je veux juste le faire.
Dans la première version de l'article de Jurgen, il a également mentionné beaucoup de RL basé sur un modèle. Bien qu'il ait appris le modèle, il n'a pas complètement formé RL au modèle.

Le fait que RL ne soit pas entièrement formé au modèle n'est pas en fait la différence entre RL basé sur un modèle et un modèle, mais la frustration de longue date de la direction RL basée sur un modèle : le modèle n'est pas assez précis et le RL formé entièrement au modèle est très efficace. Ce problème n'a été résolu que ces dernières années.
Smart Sutton a pris conscience du problème des modèles inexacts il y a longtemps. En 1990, l'article Integrated Architectures for Learning, Planning and Reacting based on Dynamic Programming qui proposait le cadre Dyna (publié sur ICML, qui était le premier atelier à être une conférence), a appelé ce modèle un modèle d'action, mettant l'accent sur la prévision des résultats de exécution des actions.
RL apprend à partir de données réelles (ligne 3) tout en apprenant à partir du modèle (ligne 5) pour éviter un apprentissage inexact du modèle à partir d'une mauvaise stratégie.

Vous pouvez voir que le modèle mondial est très important pour la prise de décision. Si vous pouvez obtenir un modèle mondial précis, vous pouvez trouver la décision optimale dans la réalité par essais et erreurs dans le modèle mondial.
C'est la fonction essentielle du modèle mondial : le raisonnement contrefactuel, c'est-à-dire que même pour des décisions qui n'ont pas été vues dans les données, les résultats de la décision peuvent être déduits dans le modèle mondial.
Les étudiants qui comprennent le raisonnement causal seront familiers avec le terme raisonnement contrefactuel. Dans le livre de vulgarisation scientifique de Judea Pearl, lauréat du prix Turing, Le livre du pourquoi, une échelle causale est dessinée. Ce que font principalement la plupart des modèles prédictifs ; la couche intermédiaire est « l'intervention », et l'exploration dans l'apprentissage par renforcement est une intervention typique ; la couche supérieure est contrefactuelle, répondant à la question « et si » par l'imagination ; Le diagramme schématique que Judea a dessiné pour un raisonnement contrefactuel est ce que les scientifiques imaginent dans leur cerveau, ce qui est similaire au diagramme schématique utilisé par Jurgen dans son article.
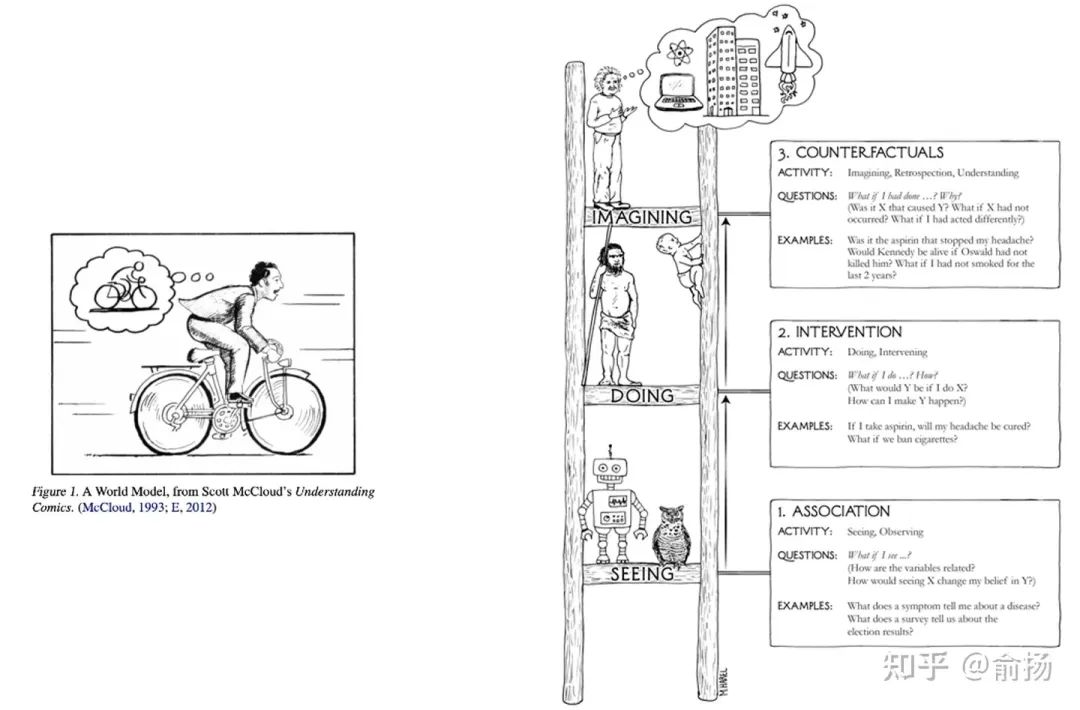
Gauche : Diagramme schématique du modèle du monde dans l'article de Jurgen. À droite : L’échelle de cause à effet dans le livre de Judée.
À ce stade, nous pouvons résumer que la recherche de modèles mondiaux par les chercheurs en IA consiste à essayer de transcender les données, de mener un raisonnement contrefactuel et de rechercher la capacité de répondre à des questions de simulation. Il s’agit d’une capacité que les humains possèdent naturellement, mais l’IA actuelle est encore très médiocre dans ce domaine. Une fois qu’une percée aura été réalisée, les capacités de prise de décision de l’IA seront considérablement améliorées, permettant des applications de scénarios telles que la conduite entièrement autonome.
Sora est-il un simulateur mondial
Le mot simulateur est plus couramment utilisé dans le domaine de l'ingénierie. Il fonctionne comme un modèle mondial et tente des essais et des erreurs coûteux et à haut risque, difficiles à mettre en œuvre dans le domaine. monde réel. OpenAI semble vouloir reformuler une phrase, mais le sens reste le même.
La vidéo générée par Sora ne peut être guidée que par de vagues mots d'invite, ce qui la rend difficile à contrôler avec précision. Par conséquent, il s’agit davantage d’un outil vidéo et il est difficile à utiliser comme outil de raisonnement contrefactuel pour répondre avec précision aux questions de simulation.
Il est même difficile d'évaluer la force de la capacité de génération de Sora, car on ne sait absolument pas à quel point la vidéo de démonstration est différente des données d'entraînement.
Ce qui est encore plus décevant, c'est que ces démos montrent que Sora n'a pas appris avec précision les lois de la physique. J'ai vu quelqu'un souligner l'incohérence avec les lois physiques dans les vidéos générées par Sora [OpenAI publie le modèle vidéo Vincent Sora, l'IA peut comprendre le monde physique en mouvement. Est-ce un modèle mondial ? Qu'est-ce que ça veut dire? ]
Je suppose que les démos publiées par OpenAI devraient être basées sur des données d'entraînement très suffisantes, incluant même les données générées par CG. Cependant, même ainsi, les lois physiques qui peuvent être décrites par des équations à quelques variables ne sont toujours pas comprises.
OpenAI estime que Sora constitue une voie vers des simulateurs du monde physique, mais il semble que le simple empilage de données ne soit pas la voie vers une technologie intelligente plus avancée.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
