
 Périphériques technologiques
IA
L'article de 6 pages de Microsoft explose : LLM ternaire, tellement délicieux !
Périphériques technologiques
IA
L'article de 6 pages de Microsoft explose : LLM ternaire, tellement délicieux !
L'article de 6 pages de Microsoft explose : LLM ternaire, tellement délicieux !

C'est la conclusion avancée par Microsoft et l'Université de l'Académie chinoise des sciences dans la dernière étude :
Tous les LLM seront en 1,58 bits.

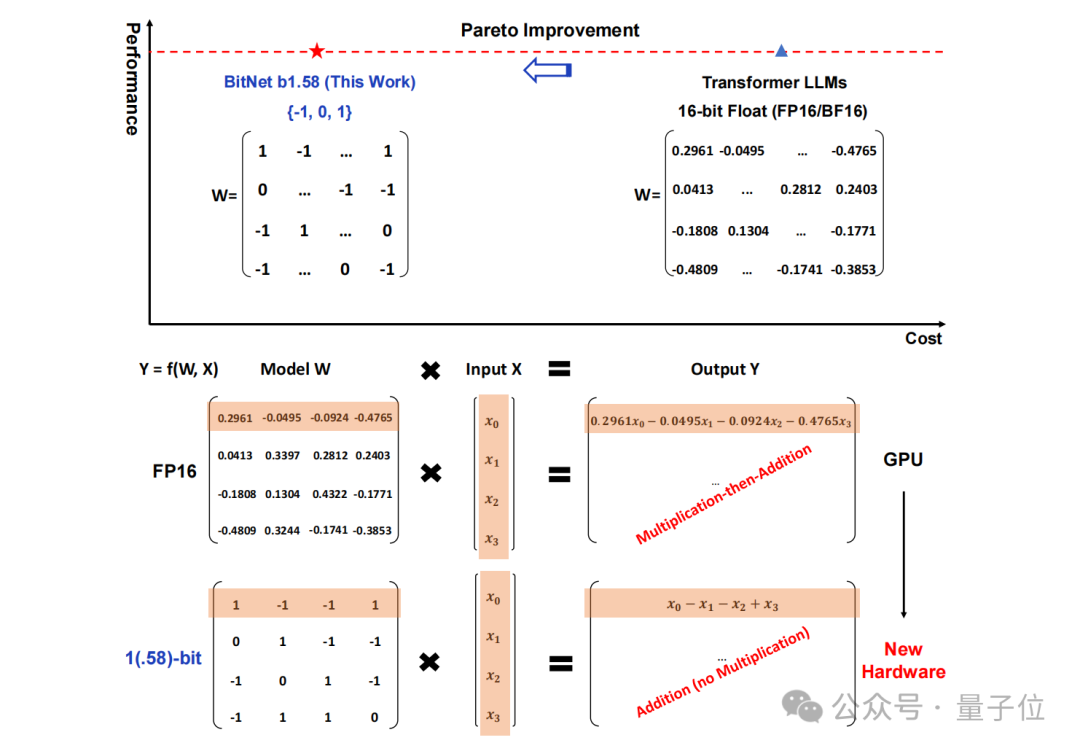
Plus précisément, la méthode proposée dans cette étude s'appelle BitNet b1.58, dont on peut dire qu'elle part des paramètres de la « racine » du grand modèle de langage.
Le stockage traditionnel sous forme de nombres à virgule flottante 16 bits (tels que FP16 ou BF16) a été transformé en ternaire , qui est {-1, 0, 1}.
Il est à noter que « 1,58 bit » ne signifie pas que chaque paramètre occupe 1,58 octets d'espace de stockage, mais que chaque paramètre peut être codé avec 1,58 bits d'information.
Après une telle conversion, le calcul dans la matrice impliquera seulement l'ajout d'entiers, permettant ainsi aux grands modèles de réduire considérablement l'espace de stockage et les ressources de calcul requis tout en conservant une certaine précision.
Par exemple, BitNet b1.58 est comparé à Llama lorsque la taille du modèle est de 3B. Alors que la vitesse est augmentée de 2,71 fois, l'utilisation de la mémoire GPU ne représente presque qu'un quart de l'original.
Et lorsque la taille du modèle est plus grande (par exemple, 70B) , l'amélioration de la vitesse et l'économie de mémoire seront plus significatives !
Cette idée subversive a vraiment impressionné les internautes, et le journal a également reçu une grande attention sur La vieille blague du journal :
 1 bit est tout ce dont VOUS avez besoin.
1 bit est tout ce dont VOUS avez besoin.
Alors, comment BitNet b1.58 est-il implémenté ? Continuons la lecture.
Convertir tous les paramètres en ternaire 
Dans l'ensemble, BitNet b1.58 est toujours basé sur l'architecture BitNet
(un Transformer), remplaçant nn.Linear par BitLinear. 
quantification du poids(quantification du poids)
.Les poids du modèle BitNet b1.58 sont quantifiés en valeurs ternaires {-1, 0, 1}, ce qui équivaut à utiliser 1,58 bits pour représenter chaque poids dans le système binaire. Cette méthode de quantification réduit l'empreinte mémoire du modèle et simplifie le processus de calcul.
Deuxièmement, en termes de
conception de la fonction de quantification, afin de limiter le poids à -1, 0 ou +1, les chercheurs ont utilisé une fonction de quantification appelée absmean. 
Cette fonction évolue d'abord en fonction de la valeur absolue moyenne de la matrice de poids, puis arrondit chaque valeur à l'entier le plus proche (-1, 0, +1).
La prochaine étape est la 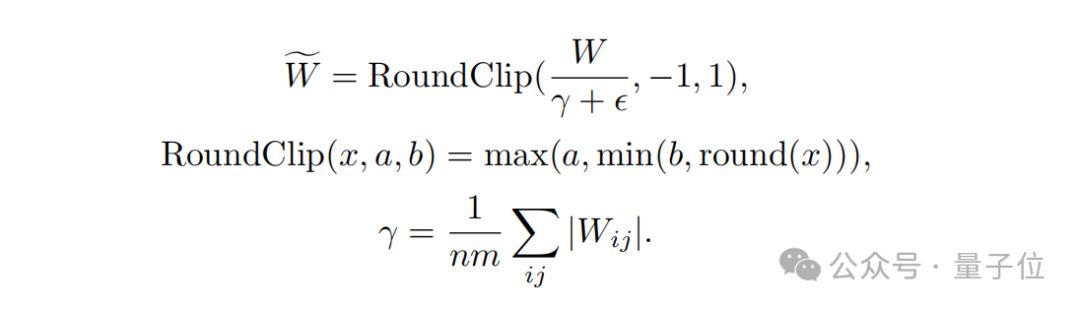 quantification d'activation
quantification d'activation
(quantification d'activation)
.La quantification des valeurs d'activation est la même que l'implémentation dans BitNet, mais les valeurs d'activation ne sont pas mises à l'échelle dans la plage [0, Qb] avant la fonction non linéaire. Au lieu de cela, les activations sont adaptées à la plage [−Qb, Qb] pour éliminer la quantification du point zéro.
Il convient de mentionner que afin de rendre BitNet b1.58 compatible avec la communauté open source, l'équipe de recherche a adopté des composants du modèle LLaMA, tels que RMSNorm, SwiGLU, etc., afin qu'il puisse être facilement intégré au grand public. logiciel source.
Enfin, en termes de comparaison des performances expérimentales, l'équipe a comparé BitNet b1.58 et FP16 LLaMA LLM sur des modèles de différentes tailles.
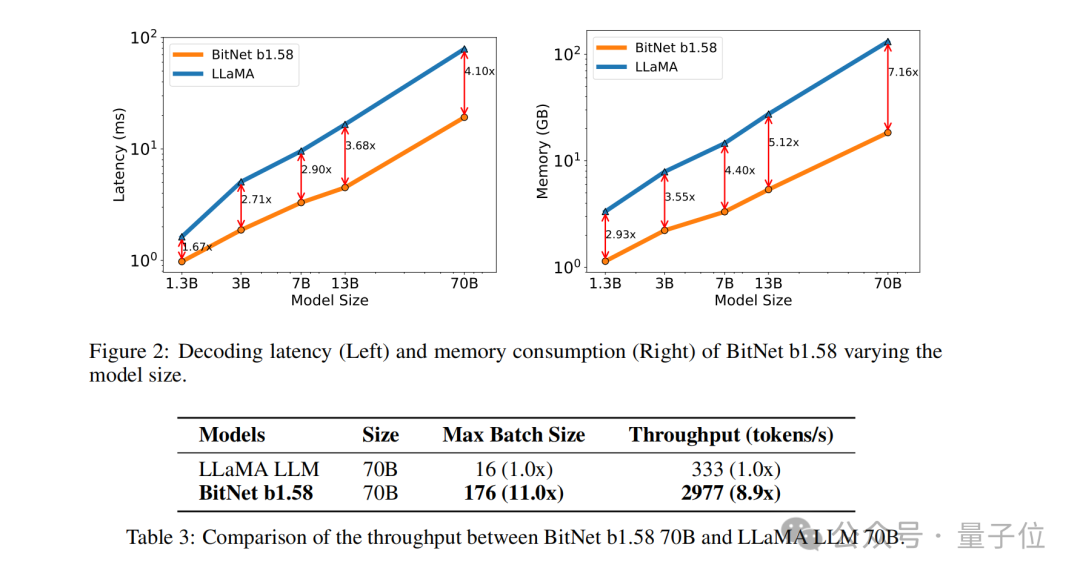
Les résultats montrent que BitNet b1.58 commence à correspondre au LLaMA LLM de pleine précision en perplexité à une taille de modèle 3B, tout en obtenant des améliorations significatives en termes de latence, d'utilisation de la mémoire et de débit.
Et lorsque la taille du modèle devient plus grande, cette amélioration des performances deviendra plus significative.
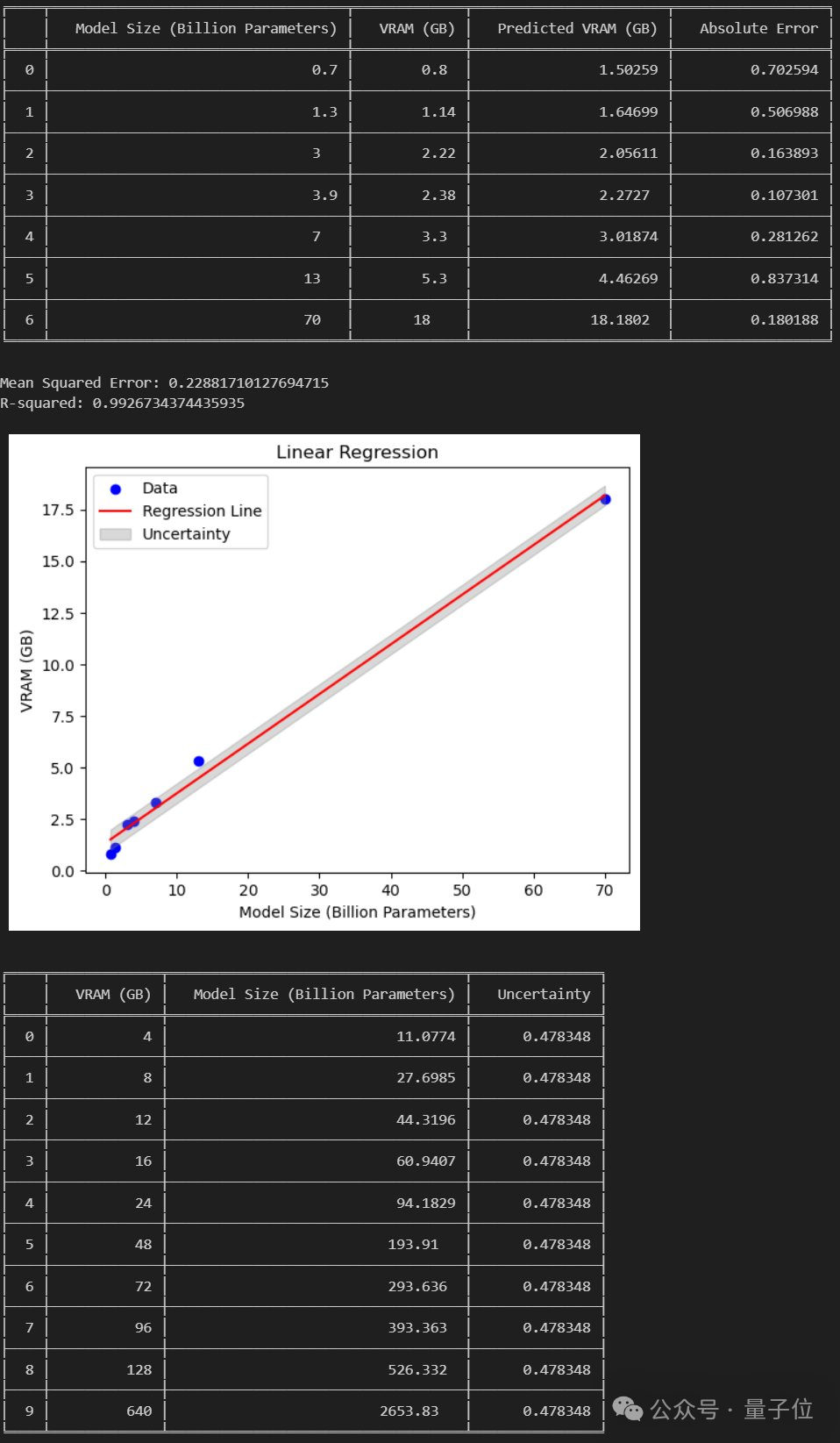
Internautes : Il est possible d'exécuter 120 milliards de grands modèles sur des GPU grand public
Comme mentionné ci-dessus, la méthode unique de cette étude a suscité de nombreuses discussions animées sur Internet.
L'auteur de DeepLearning.scala, Yang Bo, a déclaré :
Par rapport au BitNet original, la plus grande caractéristique de BitNet b1.58 est qu'il autorise 0 paramètre. Je pense qu'en modifiant légèrement la fonction de quantification, nous pourrons peut-être contrôler la proportion de 0 paramètres. Lorsque la proportion de paramètres 0 est grande, les poids peuvent être stockés dans un format clairsemé, de sorte que la mémoire vidéo moyenne occupée par chaque paramètre soit même inférieure à 1 bit. Cela équivaut à un MoE au niveau du poids. Je pense que c'est plus élégant que le MoE classique.
Dans le même temps, il a également soulevé les lacunes de BitNet :
Le plus gros inconvénient de BitNet est que bien qu'il puisse réduire la surcharge de mémoire lors de l'inférence, l'état et le gradient de l'optimiseur utilisent toujours des nombres à virgule flottante, et la formation est toujours très gourmand en mémoire. Je pense que si BitNet peut être combiné avec une technologie qui économise la mémoire vidéo pendant l'entraînement, alors par rapport aux réseaux traditionnels de demi-précision, il peut prendre en charge plus de paramètres avec la même puissance de calcul et la même mémoire vidéo, ce qui présentera de grands avantages.
La façon actuelle d'économiser la surcharge de mémoire graphique de l'état de l'optimiseur est le déchargement. Un moyen d'économiser l'utilisation de la mémoire des dégradés peut être ReLoRA. Cependant, l’expérience papier ReLoRA n’a utilisé qu’un modèle comportant un milliard de paramètres, et rien ne prouve qu’elle puisse être généralisée à des modèles comportant des dizaines ou des centaines de milliards de paramètres.

△Source de l'image : Zhihu, cité avec autorisation
Cependant, certains internautes ont analysé que :
Si le document est établi, alors nous pouvons exécuter un grand modèle de 120 Go sur un GPU grand public de 24 Go.
Alors que pensez-vous de cette nouvelle méthode ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Solution d'erreur d'installation MySQL
Apr 08, 2025 am 10:48 AM
Solution d'erreur d'installation MySQL
Apr 08, 2025 am 10:48 AM
Raisons et solutions courantes pour l'échec de l'installation MySQL: 1. Nom d'utilisateur ou mot de passe incorrect, ou le service MySQL n'est pas démarré, vous devez vérifier le nom d'utilisateur et le mot de passe et démarrer le service; 2. Conflits portuaires, vous devez modifier le port d'écoute MySQL ou fermer le programme qui occupe le port 3306; 3. La bibliothèque de dépendances est manquante, vous devez utiliser le gestionnaire de package système pour installer la bibliothèque de dépendances nécessaires; 4. Autorisations insuffisantes, vous devez utiliser les droits de Sudo ou d'administrateur pour exécuter l'installateur; 5. Fichier de configuration incorrect, vous devez vérifier le fichier de configuration My.cnf pour vous assurer que la configuration est correcte. Ce n'est qu'en travaillant régulièrement et soigneusement que MySQL peut être installé en douceur.
