

L'éditeur php Banana analyse de manière approfondie la logique d'implémentation sous-jacente des tableaux PHP. Le tableau en PHP est une structure de données flexible et puissante, mais la logique de mise en œuvre qui la sous-tend est assez complexe. Dans cet article, nous approfondirons les principes sous-jacents des tableaux PHP, y compris la structure interne du tableau, la relation entre les index et les tables de hachage, et comment implémenter les opérations d'ajout, de suppression, de modification et de requête du tableau. En comprenant la logique d'implémentation sous-jacente des tableaux PHP, les développeurs peuvent mieux comprendre et utiliser les tableaux, une structure de données importante.
À quoi ressemble un tableau dans le noyau PHP ? Nous pouvons voir la structure comme suit à partir du code source de PHP :
<code>// 定义结构体别名为 HashTable
typedef struct _zend_array HashTable;
struct _zend_array {
// <strong class="keylink">GC</strong> 保存引用计数,内存管理相关;本文不涉及
zend_refcounted_h gc;
// u 储存辅助信息;本文不涉及
u<strong class="keylink">NIO</strong>n {
struct {
ZEND_ENDIAN_LOHI_4(
zend_uchar flags,
zend_uchar nApplyCount,
zend_uchar nIteratorsCount,
zend_uchar consistency)
} v;
uint32_t flags;
} u;
// 用于散列函数
uint32_t nTableMask;
// arData 指向储存元素的数组第一个 Bucket,Bucket 为统一的数组元素类型
Bucket *arData;
// 已使用 Bucket 数
uint32_t nNumUsed;
// 数组内有效元素个数
uint32_t nNumOfElements;
// 数组总容量
uint32_t nTableSize;
// 内部指针,用于遍历
uint32_t nInternalPointer;
// 下一个可用数字<strong class="keylink">索引</strong>
zend_long nNextFreeElement;
// 析构函数
dtor_func_t pDestructor;
};</code> La différence entre nNumUsed et nNumOfElements : nNumUsed fait référence à C'est le numéro de Bucket qui a été utilisé dans le tableau arData, car après avoir supprimé l'élément, le tableau définit simplement le type de la valeur correspondante de l'élément Bucket à IS_UNDEF (car ce serait une perte de temps de déplacer et réindexer le tableau à chaque fois qu'un élément est supprimé), et nNumOfElements correspond au nombre réel d'éléments dans le tableau. nNumUsed 和 nNumOfElements 的区别:nNumUsed 指的是 arData 数组中已使用的 Bucket 数,因为数组在删除元素后只是将该元素 Bucket 对应值的类型设置为 IS_UNDEF(因为如果每次删除元素都要将数组移动并重新索引太浪费时间),而 nNumOfElements 对应的是数组中真正的元素个数。
nTableSize 数组的容量,该值为 2 的幂次方。PHP 的数组是不定长度但 C 语言的数组定长的,为了实现 PHP 的不定长数组的功能,采用了「扩容」的机制,就是在每次插入元素的时候判断 nTableSize 是否足以储存。如果不足则重新申请 2 倍 nTableSize 大小的新数组,并将原数组复制过来(此时正是清除原数组中类型为 IS_UNDEF 元素的时机)并且重新索引。
nNextFreeElement 保存下一个可用数字索引,例如在 PHP 中 $a[] = 1; 这种用法将插入一个索引为 nNextFreeElement 的元素,然后 nNextFreeElement 自增 1。
_zend_array 这个结构先讲到这里,有些结构体成员的作用在下文会解释,不用紧张O(∩_∩)O哈哈~。下面来看看作为数组成员的 Bucket 结构:
<code>typedef struct _Bucket {
// 数组元素的值
zval val;
// key 通过 Time 33 <strong class="keylink">算法</strong>计算得到的哈希值或数字索引
zend_ulong h;
// 字符键名,数字索引则为 NULL
zend_string *key;
} Bucket;</code>我们知道 PHP 数组是基于哈希表实现的,而与一般哈希表不同的是 PHP 的数组还实现了元素的有序性,就是插入的元素从内存上来看是连续的而不是乱序的,为了实现这个有序性 PHP 采用了「映射表」技术。下面就通过图例说明我们是如何访问 PHP 数组的元素 :-D。
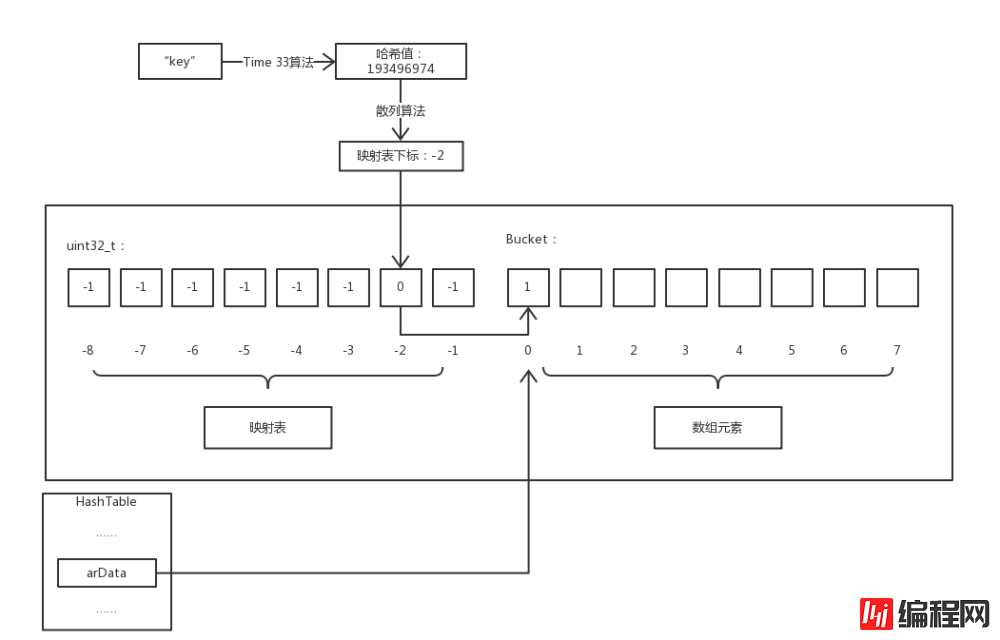
注意:因为键名到映射表下标经过了两次散列运算,为了区分本文用哈希特指第一次散列,散列即为第二次散列。
由图可知,映射表和数组元素在同一片连续的内存中,映射表是一个长度与存储元素相同的整型数组,它默认值为 -1 ,有效值为 Bucket 数组的下标。而 HashTable->arData 指向的是这片内存中 Bucket 数组的第一个元素。
举个例子 $a['key'] 访问数组 $a 中键名为 key 的成员,流程介绍:首先通过 Time 33 算法计算出 key 的哈希值,然后通过散列算法计算出该哈希值对应的映射表下标,因为映射表中保存的值就是 Bucket 数组中的下标值,所以就能获取到 Bucket 数组中对应的元素。
现在我们来聊一下散列算法,就是通过键名的哈希值映射到「映射表」的下标的算法。其实很简单就一行代码:
<code>nIndex = h | ht->nTableMask;</code>
将哈希值和 nTableMask 进行或运算即可得出映射表的下标,其中 nTableMask 数值为 nTableSize 的负数。并且由于 nTableSize 的值为 2 的幂次方,所以 h | ht->nTableMask 的取值范围在 [-nTableSize, -1]nTableSize La capacité du tableau, cette valeur est une puissance de 2. Les tableaux de PHP sont de longueur variable, mais les tableaux du langage C sont de longueur fixe Afin de réaliser la fonction des tableaux de longueur variable de PHP, un mécanisme « d'expansion » est adopté, qui consiste à déterminer nTableSize chaque. le moment où un élément est inséré. Est-ce suffisant pour stocker. S'il est insuffisant, réappliquez un nouveau tableau 2 fois la taille de nTableSize et copiez le tableau d'origine (c'est le moment d'effacer les éléments de type IS_UNDEF dans le tableau d'origine) et réindexer.
nNextFreeElement enregistre le prochain index numérique disponible, par exemple en PHP $a[] = 1; Cette utilisation insérera un index sous la forme nNextFreeElement, alors nNextFreeElement est incrémenté de 1.
_zend_array Cette structure sera discutée ici en premier. Les fonctions de certains membres de la structure seront expliquées ci-dessous, alors ne soyez pas nerveux O(∩_∩)O. haha~. Jetons un coup d'œil à la structure Bucket en tant que membre du tableau :
<code>static zend_always_inline zval *_zend_hash_add_or_update_i(HashTable *ht, zend_string *key, zval *pData, uint32_t flag ZEND_FILE_LINE_DC)
{
zend_ulong h;
uint32_t nIndex;
uint32_t idx;
Bucket *p;
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) { // 数组未初始化
// 初始化数组
CHECK_INIT(ht, 0);
// 跳转至插入元素段
goto add_to_hash;
} else if (ht->u.flags & HASH_FLAG_PACKED) { // 数组为连续数字索引数组
// 转换为关联数组
zend_hash_packed_to_hash(ht);
} else if ((flag & HASH_ADD_NEW) == 0) { // 添加新元素
// 查找键名对应的元素
p = zend_hash_find_bucket(ht, key);
if (p) { // 若相同键名元素存在
zval *data;
if (flag & HASH_ADD) { // 指定 add 操作
if (!(flag & HASH_UPDATE_INDIRECT)) { // 若不允许更新间接类型变量则直接返回
return NULL;
}
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组成员值
data = &p->val;
if (Z_TYPE_P(data) == IS_INDIRECT) { // 原数组元素变量类型为间接类型
// 取间接变量对应的变量
data = Z_INDIRECT_P(data);
if (Z_TYPE_P(data) != IS_UNDEF) { // 该对应变量存在则直接返回
return NULL;
}
} else { // 非间接类型直接返回
return NULL;
}
} else { // 没有指定 add 操作
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组元素值
data = &p->val;
// 允许更新间接类型变量则 data 指向对应的变量
if ((flag & HASH_UPDATE_INDIRECT) && Z_TYPE_P(data) == IS_INDIRECT) {
data = Z_INDIRECT_P(data);
}
}
if (ht->pDestructor) { // 析构函数存在
// 执行析构函数
ht->pDestructor(data);
}
// 将 pData 的值复制给 data
ZVAL_COPY_VALUE(data, pData);
return data;
}
}
// 如果哈希表已满,则进行扩容
ZEND_HASH_IF_FULL_DO_RESIZE(ht);
add_to_hash:
// 数组已使用 Bucket 数 +1
idx = ht->nNumUsed++;
// 数组有效元素数目 +1
ht->nNumOfElements++;
// 若内部指针无效则指向当前下标
if (ht->nInternalPointer == HT_INVALID_IDX) {
ht->nInternalPointer = idx;
}
zend_hash_iterators_update(ht, HT_INVALID_IDX, idx);
// p 为新元素对应的 Bucket
p = ht->arData + idx;
// 设置键名
p->key = key;
if (!ZSTR_IS_INTERNED(key)) {
zend_string_addref(key);
ht->u.flags &= ~HASH_FLAG_STATIC_KEYS;
zend_string_hash_val(key);
}
// 计算键名的哈希值并赋值给 p
p->h = h = ZSTR_H(key);
// 将 pData 赋值该 Bucket 的 val
ZVAL_COPY_VALUE(&p->val, pData);
// 计算映射表下标
nIndex = h | ht->nTableMask;
// 解决冲突,将原映射表中的内容赋值给新元素变量值的 u2.next 成员
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
// 将映射表中的值设为 idx
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
return &p->val;
}</code>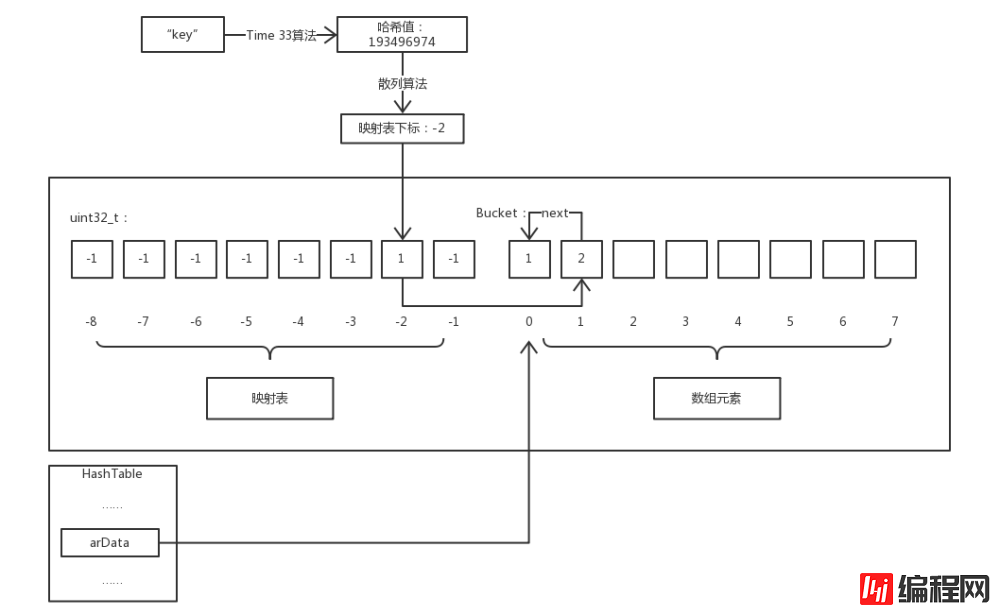 Accès au tableau🎜Nous savons que les tableaux PHP sont implémentés sur la base de tables de hachage, et ce qui est différent des tables de hachage générales est que PHP Les tableaux également L'ordre des éléments est obtenu, c'est-à-dire que les éléments insérés sont continus plutôt que désordonnés du point de vue de la mémoire. Afin d'obtenir cet ordre, PHP utilise la technologie des « tables de mappage ». Ci-dessous une illustration pour illustrer comment nous accédons aux éléments du tableau PHP :-D. 🎜🎜🎜🎜Remarque : étant donné que le nom de clé de l'indice de la table de mappage a été haché deux fois, afin de distinguer cet article, le hachage fait référence au premier hachage et le hachage est le deuxième hachage. 🎜🎜🎜Comme le montre la figure, la table de mappage et les éléments du tableau sont dans la même mémoire continue. La table de mappage est un tableau d'entiers de la même longueur que les éléments de stockage. Sa valeur par défaut est -1 et la valeur valide. est
Accès au tableau🎜Nous savons que les tableaux PHP sont implémentés sur la base de tables de hachage, et ce qui est différent des tables de hachage générales est que PHP Les tableaux également L'ordre des éléments est obtenu, c'est-à-dire que les éléments insérés sont continus plutôt que désordonnés du point de vue de la mémoire. Afin d'obtenir cet ordre, PHP utilise la technologie des « tables de mappage ». Ci-dessous une illustration pour illustrer comment nous accédons aux éléments du tableau PHP :-D. 🎜🎜🎜🎜Remarque : étant donné que le nom de clé de l'indice de la table de mappage a été haché deux fois, afin de distinguer cet article, le hachage fait référence au premier hachage et le hachage est le deuxième hachage. 🎜🎜🎜Comme le montre la figure, la table de mappage et les éléments du tableau sont dans la même mémoire continue. La table de mappage est un tableau d'entiers de la même longueur que les éléments de stockage. Sa valeur par défaut est -1 et la valeur valide. est Bucket code> L'indice du tableau. Et HashTable->arData pointe vers le premier élément du tableau Bucket dans cette mémoire. 🎜🎜Par exemple, $a['key'] accède au membre dont le nom de clé est key dans le tableau $a. introduit : premier passage L'algorithme Time 33 calcule la valeur de hachage de key, puis utilise l'algorithme de hachage pour calculer l'indice de la table de mappage correspondant à la valeur de hachage, car la valeur enregistrée dans la table de mappage est Bucket La valeur d'indice dans le tableau code>, afin que l'élément correspondant dans le tableau Bucket puisse être obtenu. 🎜🎜Parlons maintenant de l'algorithme de hachage, qui est l'algorithme qui mappe la valeur de hachage du nom de la clé à l'indice de la "table de mappage". En fait, c'est très simple, juste une ligne de code : 🎜rrreee🎜Ou la valeur de hachage et nTableMask pour obtenir l'indice de la table de mappage, où la valeur de nTableMask est Nombre négatif de nTableSize. Et puisque la valeur de nTableSize est une puissance de 2, la plage de valeurs de h | ht->nTableMask est comprise entre [-nTableSize, -1], exactement dans la plage d'indices de la table de mappage. Quant à savoir pourquoi ne pas utiliser une simple opération « reste » mais se donner la peine d'utiliser une opération « OU au niveau du bit » ? Parce que l'opération "OU au niveau du bit" est beaucoup plus rapide que l'opération "reste", je pense que pour cette opération fréquemment utilisée, l'optimisation du temps apportée par une implémentation plus complexe en vaut la peine. 🎜🎜Conflit de hachage🎜🎜Les indices de la « table de mappage » calculés par hachage des valeurs de hachage de différents noms de clés peuvent être les mêmes, et un conflit de hachage se produit. Pour cette situation, PHP utilise la "méthode d'adresse en chaîne" pour la résoudre. La figure suivante montre la situation d'accès aux éléments avec collision de hachage : 🎜🎜🎜🎜<p>这看似与第一张图差不多,但我们同样访问 <code>$a['key'] 的过程多了一些步骤。首先通过散列运算得出映射表下标为 -2 ,然后访问映射表发现其内容指向 arData 数组下标为 1 的元素。此时我们将该元素的 key 和要访问的键名相比较,发现两者并不相等,则该元素并非我们所想访问的元素,而元素的 val.u2.next 保存的值正是下一个具有相同散列值的元素对应 arData 数组的下标,所以我们可以不断通过 next 的值遍历直到找到键名相同的元素或查找失败。
插入元素
插入元素的函数 _zend_hash_add_or_update_i ,基于 PHP 7.2.9 的代码如下:
<code>static zend_always_inline zval *_zend_hash_add_or_update_i(HashTable *ht, zend_string *key, zval *pData, uint32_t flag ZEND_FILE_LINE_DC)
{
zend_ulong h;
uint32_t nIndex;
uint32_t idx;
Bucket *p;
IS_CONSISTENT(ht);
HT_ASSERT_RC1(ht);
if (UNEXPECTED(!(ht->u.flags & HASH_FLAG_INITIALIZED))) { // 数组未初始化
// 初始化数组
CHECK_INIT(ht, 0);
// 跳转至插入元素段
goto add_to_hash;
} else if (ht->u.flags & HASH_FLAG_PACKED) { // 数组为连续数字索引数组
// 转换为关联数组
zend_hash_packed_to_hash(ht);
} else if ((flag & HASH_ADD_NEW) == 0) { // 添加新元素
// 查找键名对应的元素
p = zend_hash_find_bucket(ht, key);
if (p) { // 若相同键名元素存在
zval *data;
if (flag & HASH_ADD) { // 指定 add 操作
if (!(flag & HASH_UPDATE_INDIRECT)) { // 若不允许更新间接类型变量则直接返回
return NULL;
}
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组成员值
data = &p->val;
if (Z_TYPE_P(data) == IS_INDIRECT) { // 原数组元素变量类型为间接类型
// 取间接变量对应的变量
data = Z_INDIRECT_P(data);
if (Z_TYPE_P(data) != IS_UNDEF) { // 该对应变量存在则直接返回
return NULL;
}
} else { // 非间接类型直接返回
return NULL;
}
} else { // 没有指定 add 操作
// 确定当前值和新值不同
ZEND_ASSERT(&p->val != pData);
// data 指向原数组元素值
data = &p->val;
// 允许更新间接类型变量则 data 指向对应的变量
if ((flag & HASH_UPDATE_INDIRECT) && Z_TYPE_P(data) == IS_INDIRECT) {
data = Z_INDIRECT_P(data);
}
}
if (ht->pDestructor) { // 析构函数存在
// 执行析构函数
ht->pDestructor(data);
}
// 将 pData 的值复制给 data
ZVAL_COPY_VALUE(data, pData);
return data;
}
}
// 如果哈希表已满,则进行扩容
ZEND_HASH_IF_FULL_DO_RESIZE(ht);
add_to_hash:
// 数组已使用 Bucket 数 +1
idx = ht->nNumUsed++;
// 数组有效元素数目 +1
ht->nNumOfElements++;
// 若内部指针无效则指向当前下标
if (ht->nInternalPointer == HT_INVALID_IDX) {
ht->nInternalPointer = idx;
}
zend_hash_iterators_update(ht, HT_INVALID_IDX, idx);
// p 为新元素对应的 Bucket
p = ht->arData + idx;
// 设置键名
p->key = key;
if (!ZSTR_IS_INTERNED(key)) {
zend_string_addref(key);
ht->u.flags &= ~HASH_FLAG_STATIC_KEYS;
zend_string_hash_val(key);
}
// 计算键名的哈希值并赋值给 p
p->h = h = ZSTR_H(key);
// 将 pData 赋值该 Bucket 的 val
ZVAL_COPY_VALUE(&p->val, pData);
// 计算映射表下标
nIndex = h | ht->nTableMask;
// 解决冲突,将原映射表中的内容赋值给新元素变量值的 u2.next 成员
Z_NEXT(p->val) = HT_HASH(ht, nIndex);
// 将映射表中的值设为 idx
HT_HASH(ht, nIndex) = HT_IDX_TO_HASH(idx);
return &p->val;
}</code>Copier après la connexionCopier après la connexion
扩容
前面将数组结构的时候我们有提到扩容,而在插入元素的代码里有这样一个宏 ZEND_HASH_IF_FULL_DO_RESIZE,这个宏其实就是调用了 zend_hash_do_resize 函数,对数组进行扩容并重新索引。注意:并非每次 Bucket 数组满了都需要扩容,如果 Bucket 数组中 IS_UNDEF 元素的数量占较大比例,就直接将 IS_UNDEF 元素删除并重新索引,以此节省内存。下面我们看看 zend_hash_do_resize 函数:
重新索引的逻辑在 zend_hash_rehash 函数中,代码如下:
总结
嗯哼,本文就到此结束了,因为自身水平原因不能解释的十分详尽清楚。这算是我写过最难写的内容了,写完之后似乎觉得这篇文章就我自己能看明白/(ㄒoㄒ)/~~因为文笔太辣鸡。想起一句话「如果你不能简单地解释一样东西,说明你没真正理解它。」PHP 的源码里有很多细节和实现我都不算熟悉,这篇文章只是一个我的 PHP 底层学习的开篇,希望以后能够写出真正深入浅出的好文章。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!










![Premiers pas avec le développement pratique PHP : création rapide de PHP [Small Business Forum]](https://img.php.cn/upload/course/000/000/035/5d27fb58823dc974.jpg)





![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



