Mona Lisa bâille, une poule apprend à soulever un fer... Le grand modèle de Google VideoPoet fonctionne très bien.
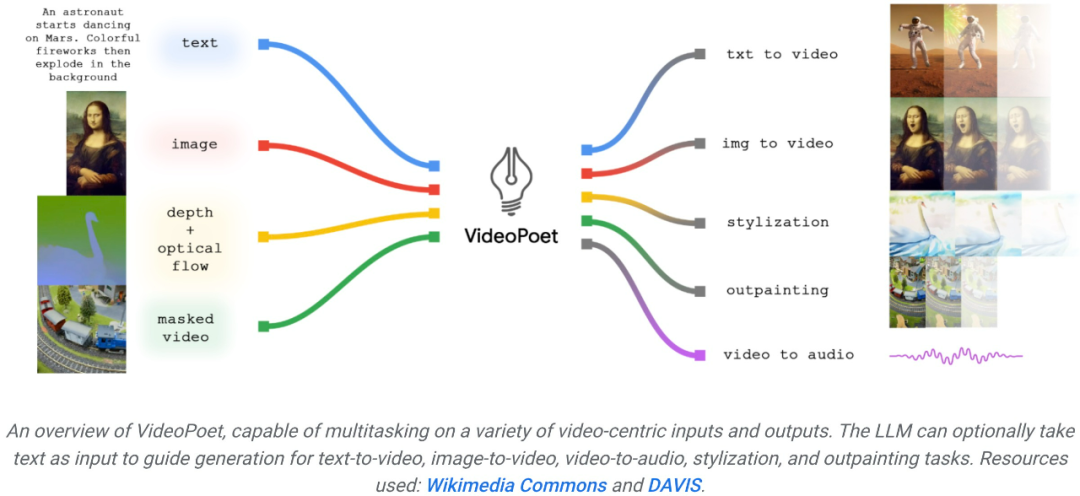
Fin 2023, les entreprises technologiques impactent le dernier niveau de l'IA générative : la génération vidéo. Ce mardi, le grand modèle de génération vidéo proposé par Google a été mis en ligne et a immédiatement attiré l'attention des gens. Ce grand modèle de langage appelé VideoPoet est considéré comme un outil révolutionnaire de génération vidéo sans plan. VideoPoet peut non seulement générer des vidéos à partir de texte et d'images, mais également transférer des styles et convertir des vidéos en parole. En effet, il permet de construire des mouvements diversifiés et fluides. 
Dès que la nouvelle est sortie, de nombreuses personnes l'ont saluée : regardez les quelques produits finis actuels avec de bons résultats, et le développement de la technologie des grands modèles est trop rapide.
Quelqu'un s'est dit surpris de la longueur de la vidéo générée par ce grand modèle :
Source : https://twitter.com/cybersphere_ai/status/1737257729167966353 Certaines personnes disent également qu'il s'agit d'un grand modèle de langage révolutionnaire.
Certains ont également fait appel à Google pour ouvrir rapidement VideoPoet. La tendance générale n'attend personne. Avec le développement de l'IA générative, il y a eu une vague récente de nouveaux modèles de génération vidéo qui démontrent une qualité d'image époustouflante. L’un des goulots d’étranglement actuels dans la génération vidéo est la génération de grands mouvements cohérents. Mais dans de nombreux cas, même les modèles les plus performants ne peuvent produire que des mouvements plus petits, ou présentent des artefacts visibles lors de la production de mouvements plus importants. Afin d'explorer l'application des modèles de langage dans la génération de vidéos, des chercheurs de Google ont introduit un grand modèle de langage (LLM) VideoPoet, qui peut effectuer diverses tâches de génération de vidéo, notamment du texte en vidéo, de l'image en vidéo et la stylisation de vidéos. , réparation et extension vidéo, et conversion vidéo en audio. VidéoAffichage de l'effet PoetVidéo de génération de texteConseils : Un chien écoute de la musique avec des écouteurs, des détails riches, 8k.
Conseils (de gauche à droite) : Un requin tirant des rayons laser depuis sa bouche ; des ours en peluche marchant main dans la main sur la Cinquième Avenue un jour de pluie ; un poulet soulevant un fer.
Conseils (de gauche à droite) : Un lion rugissant fait de pétales de pissenlit jaunes ; une explosion massive à la surface de la Terre ; un cheval galopant dans la Nuit étoilée de Van Gogh ; un écureuil en armure chevauchant une oie ; un selfie.
Image pour générer une vidéoPour l'image en vidéo, VideoPoet peut prendre l'image d'entrée et l'animer avec des invites. Pour lancer le bâillement de Mona Lisa, entrez simplement une image et une invite : Une femme bâille. Vous obtiendrez l’effet suivant.
Conseils (de gauche à droite) : Un navire naviguant sur une mer agitée avec des orages et des éclairs, style peinture à l'huile ; survolant une nébuleuse avec de nombreuses étoiles scintillantes ; un vagabond debout sur une falaise avec une canne par une journée venteuse, surplombant le mer de nuages flottant en dessous.
VideoPoet est également capable de styliser la vidéo d'entrée en fonction d'invites de texte. Conseils (de gauche à droite) : Un ours en peluche patine sur un lac de glace propre ; un lion métallique rugit à la lueur d'une fournaise.
VideoPoet peut également générer de l'audio. Demandez d’abord au modèle de générer un clip de 2 secondes, puis essayez de prédire l’audio de la scène sans aucune indication textuelle. De cette manière, VideoPoet est capable de générer de la vidéo et de l'audio à partir d'un seul modèle. VideoPoet peut également générer de longues vidéos, la valeur par défaut est de 2 secondes. Ce processus peut être répété à l'infini pour générer des vidéos de n'importe quelle durée en ajustant la dernière seconde de la vidéo et en prédisant la seconde suivante. Vous trouverez ci-dessous un exemple de démonstration de VideoPoet générant une longue vidéo à partir de la saisie de texte. Astuce : les images FPV montrent une ville Elfstone très nette dans la jungle, avec une rivière d'un bleu vif, des cascades et de grandes falaises verticales abruptes.
Les utilisateurs peuvent modifier l'invite, prolongeant ainsi la vidéo. Vidéo originale de deux ratons laveurs chevauchant une moto sur une route de montagne entourée de pins, 8k. La vidéo agrandie montre deux ratons laveurs conduisant une moto. Un météore tombe derrière les ratons laveurs, et le météore heurte la terre et explose.
Pour la vidéo d'entrée fournie (à l'extrême gauche), l'utilisateur peut modifier le mouvement de l'objet pour effectuer différentes actions. Comme indiqué ci-dessous, les trois invites du milieu n'ont pas d'invite textuelle et la dernière invite textuelle est : Commencez avec un fond de fumée.
VideoPoet peut ajouter des détails aux parties masquées de la vidéo, ou vous pouvez choisir de la réparer via un guidage textuel.
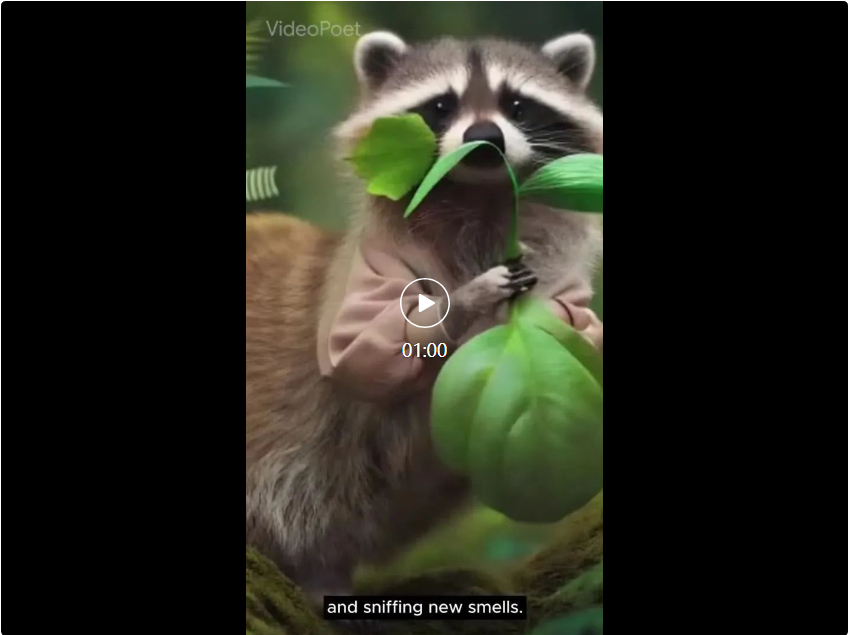
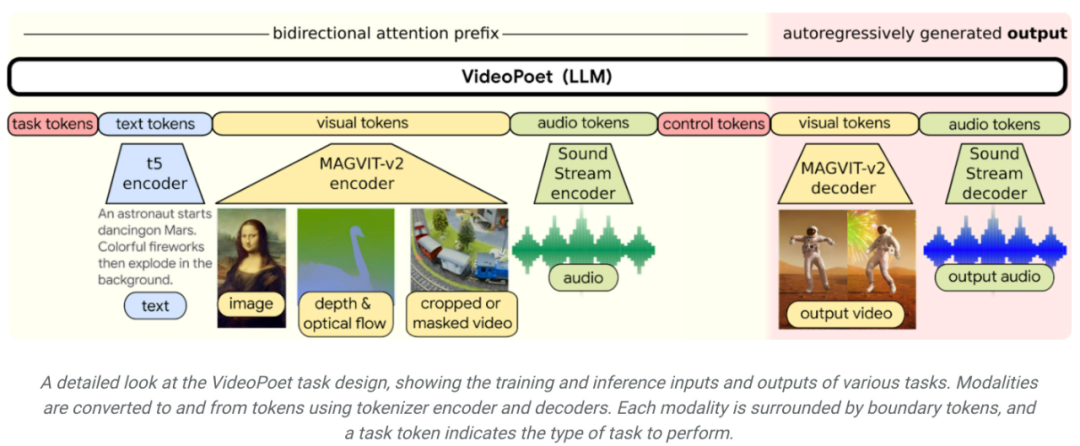
Pour démontrer les capacités de VideoPoet, Google a également produit un court métrage composé de plusieurs courtes vidéos générées par VideoPoet. Le scénario, écrit par Bard, est une courte histoire sur un raton laveur en voyage, accompagnée d'une description scène par scène et d'une liste d'invites qui l'accompagne. Google a ensuite généré des clips vidéo pour chaque invite et assemblé tous les clips générés ensemble pour produire la vidéo finale ci-dessous. Introduction à la méthodeComme le montre la figure ci-dessous, VideoPoet peut animer l'image d'entrée pour générer une vidéo, et peut éditer la vidéo ou étendre la vidéo.
En termes de stylisation, le modèle reçoit des vidéos caractérisant la profondeur et le flux optique pour dessiner le contenu dans un style guidé par le texte. Un avantage clé de l'utilisation du LLM pour la formation est que bon nombre des améliorations d'efficacité évolutives introduites dans l'infrastructure de formation LLM existante peuvent être réutilisées. Cependant, LLM fonctionne sur des jetons discrets, ce qui rend la génération vidéo difficile. Les tokeniseurs vidéo et audio peuvent être utilisés pour encoder des clips vidéo et audio en séquences de jetons discrètes, et peuvent également être reconvertis sous la forme de représentation originale. En utilisant plusieurs tokenizers (MAGVIT V2 pour les vidéos et les images et SoundStream pour l'audio), VideoPoet entraîne des modèles de langage autorégressifs pour apprendre plusieurs modalités à travers la vidéo, les images, l'audio et le texte. Une fois que le modèle génère des jetons conditionnés par un certain contexte, il peut utiliser un décodeur tokenizer pour les reconvertir en une représentation visuelle.
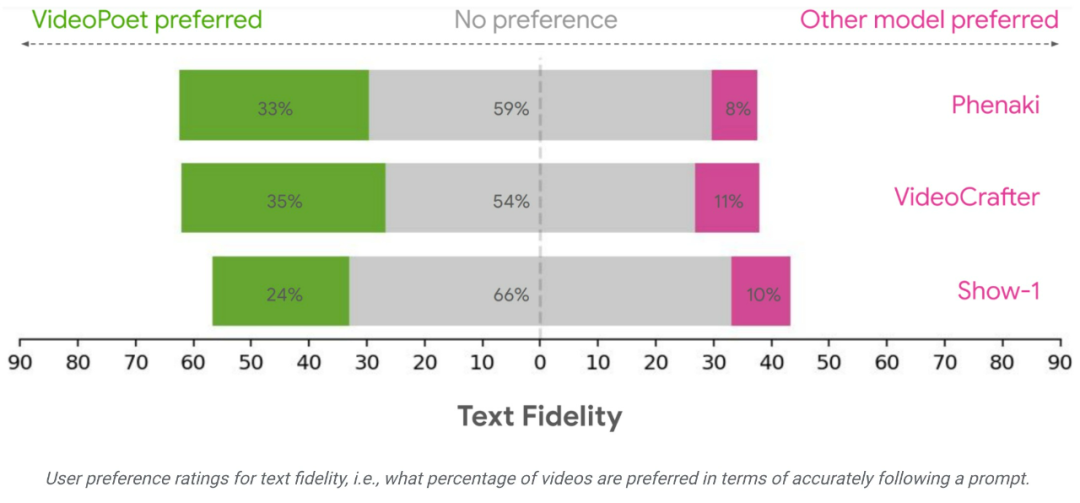
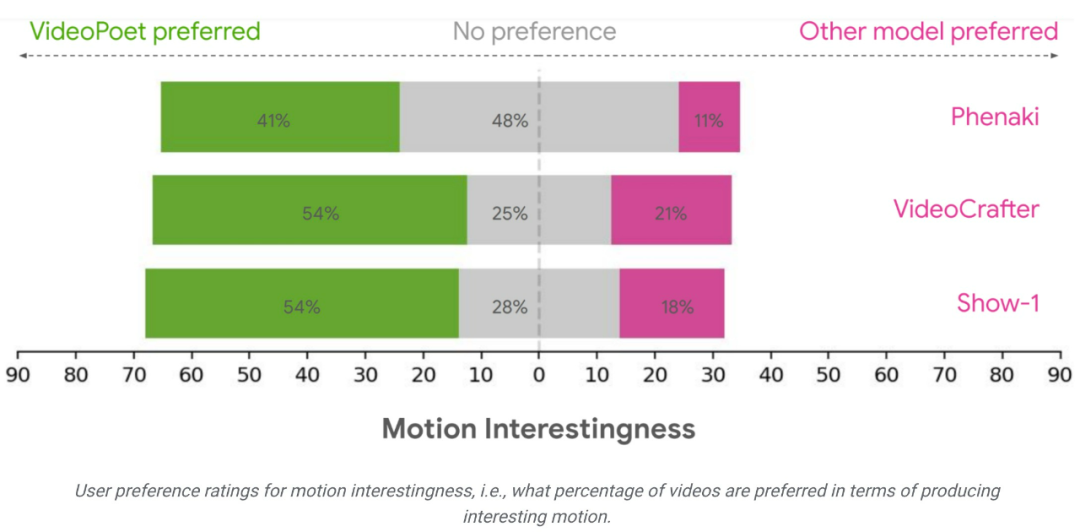
Résultats de l'évaluationL'équipe de recherche a évalué les performances de VideoPoet en matière de génération de texte en vidéo à l'aide de divers critères pour comparer les résultats avec d'autres méthodes. Pour garantir une évaluation neutre, l'étude a exécuté tous les modèles sous diverses invites, sans sélectionner d'exemples, et a demandé à des évaluateurs humains de fournir des évaluations de préférences.
En moyenne, 24 à 35 % des exemples dans VideoPoet ont été mieux notés que les modèles concurrents dans les invites suivantes, contre 8 à 11 % des modèles concurrents. Les évaluateurs ont également préféré 41 à 54 % des exemples de VideoPoet parce que les actions qui ont généré les vidéos étaient plus intéressantes, contre 11 à 21 % des autres modèles. https://blog.research.google/2023/12/videopoet-large-lingual-model-for-zero.htmlhttps ://sites.research.google/videopoet/stylisation/Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


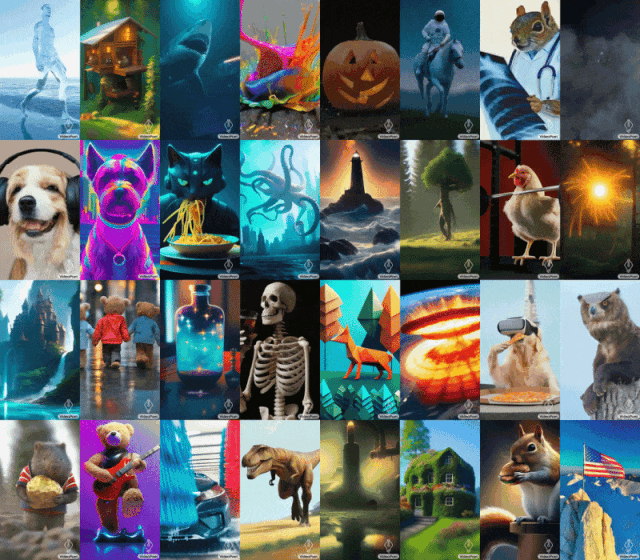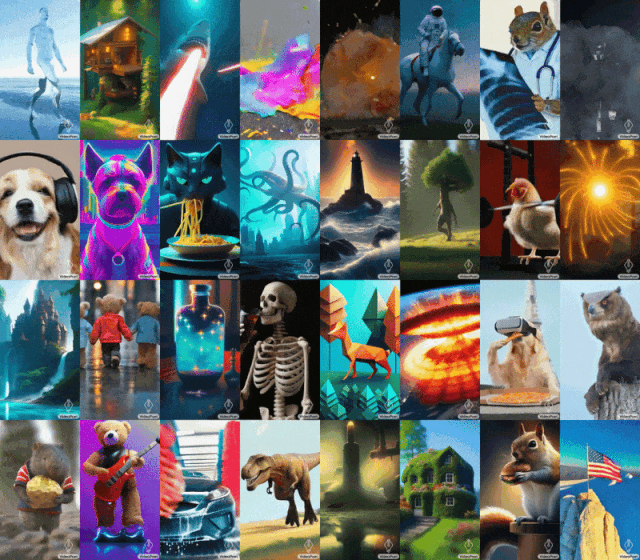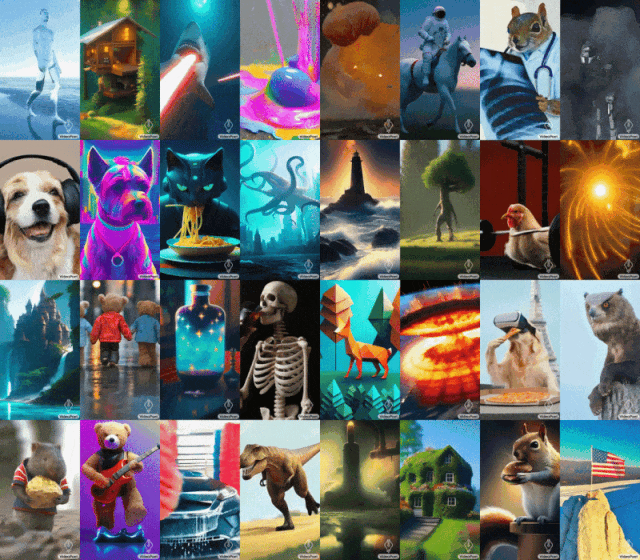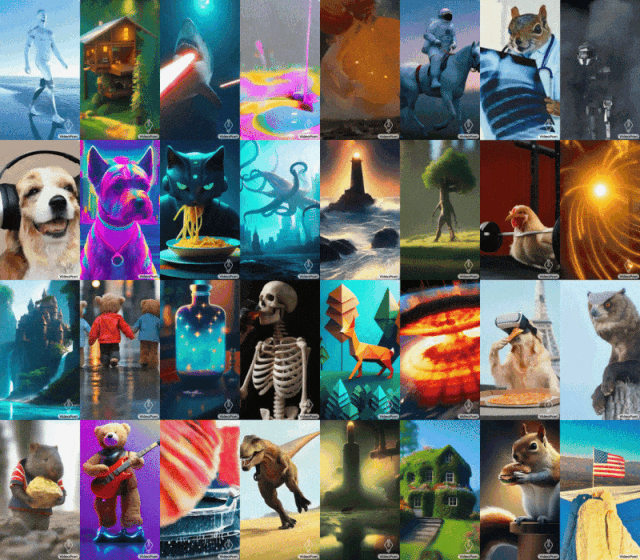













 La différence entre les threads et les processus
La différence entre les threads et les processus
 langbar.chm
langbar.chm
 Comment taper l'inscription sur le cercle de la pièce ?
Comment taper l'inscription sur le cercle de la pièce ?
 Comment résoudre la violation d'accès
Comment résoudre la violation d'accès
 La différence entre les fonctions fléchées et les fonctions ordinaires
La différence entre les fonctions fléchées et les fonctions ordinaires
 Comment mettre à niveau le système Hongmeng sur le téléphone mobile Honor
Comment mettre à niveau le système Hongmeng sur le téléphone mobile Honor
 Pourquoi vue.js signale-t-il une erreur ?
Pourquoi vue.js signale-t-il une erreur ?
 ERR_CONNECTION_REFUSED
ERR_CONNECTION_REFUSED








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



