
 Périphériques technologiques
IA
L'industrie de l'annotation de la conduite autonome sera-t-elle bouleversée par le modèle mondial en 2024 ?
Périphériques technologiques
IA
L'industrie de l'annotation de la conduite autonome sera-t-elle bouleversée par le modèle mondial en 2024 ?
L'industrie de l'annotation de la conduite autonome sera-t-elle bouleversée par le modèle mondial en 2024 ?

1. Problèmes rencontrés par l'annotation de données (en particulier basées sur les tâches BEV)
Avec l'essor des tâches basées sur les transformateurs BEV, la dépendance à l'égard des données est devenue de plus en plus lourde. L'annotation devient également de plus en plus importante. . À l'heure actuelle, qu'il s'agisse d'annotation d'obstacles communs 2D-3D, de lignes de voie basées sur des clips de nuages de points reconstruits ou d'annotation de tâches d'occupation, cela reste encore trop cher (par rapport aux tâches d'annotation 2D, c'est beaucoup plus cher). Bien entendu, il existe également dans l’industrie de nombreuses études d’annotations semi-automatiques ou automatisées basées sur de grands modèles. D’un autre côté, le cycle de collecte de données pour la conduite autonome est trop long et implique une série de problèmes de conformité des données. Par exemple, si vous souhaitez collecter une scène où un camion à plateau traverse la caméra, ou une scène où le nombre de voies dans la ville change de plus en moins, ou de moins en plus, vous avez besoin d'un personnel de collecte pour construire spécialement une telle scène. une scène.
Le 2.24 sera-t-il le moment de singularité pour le mannequin mondial ?
Le concept de modèle mondial couvre un large éventail et peut être considéré comme une simulation de capteur. Lors du Tesla AI Day, j’ai été témoin pour la première fois de l’impact perturbateur de la technologie de simulation sur l’annotation des données.

Figure 1 : Effet d'annotation automatisé de Tesla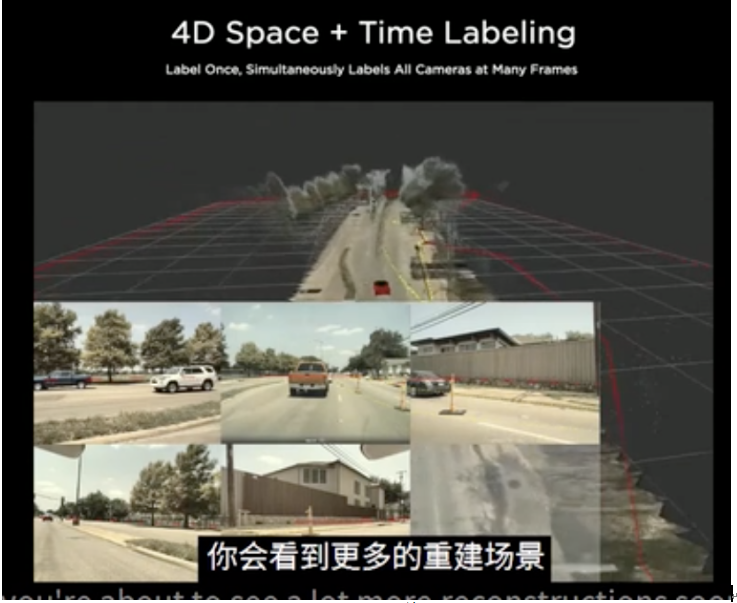 Figure 2 Effet de reconstruction 4D
Figure 2 Effet de reconstruction 4D
Quand j'ai vu la nouvelle pour la première fois, j'ai été très surpris, comme si j'avais découvert une fonctionnalité spéciale qui bouleversait la tradition comme les voitures électriques Tesla. Alors que de plus en plus de chercheurs investissent dans ce domaine, nous observons de nombreux excellents résultats de recherche. Le système de simulation de conduite autonome d'UniSim possède des fonctions telles que la relecture, le contrôle dynamique du comportement des objets et le rendu en vue libre. Ces fonctions sont très souhaitables pour tout chercheur de modèles en formation.

Vous pouvez également simuler le lidar.

Pour plus de détails, voir : https://zhuanlan.zhihu.com/p/636695025 Il existe d'autres études similaires dans cette direction.

NeuRAD : rendu neuronal pour la conduite autonome
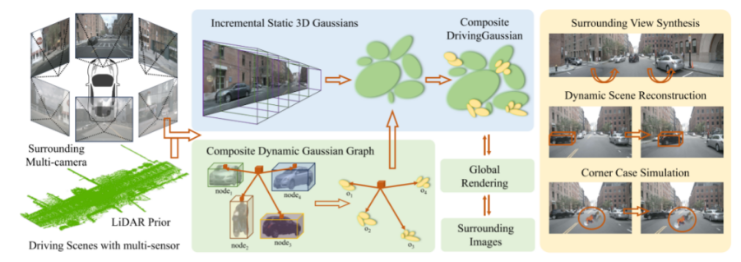
DrivingGaussian : éclaboussures gaussiennes composites pour les scènes de conduite autonomes dynamiques environnantes La plupart des méthodes ci-dessus sont liées à Nerf, et l'ensemble du pipeline est relativement lourd. Il existe une autre direction, une direction de recherche basée sur la diffusion. De bonnes recherches ont également été effectuées.
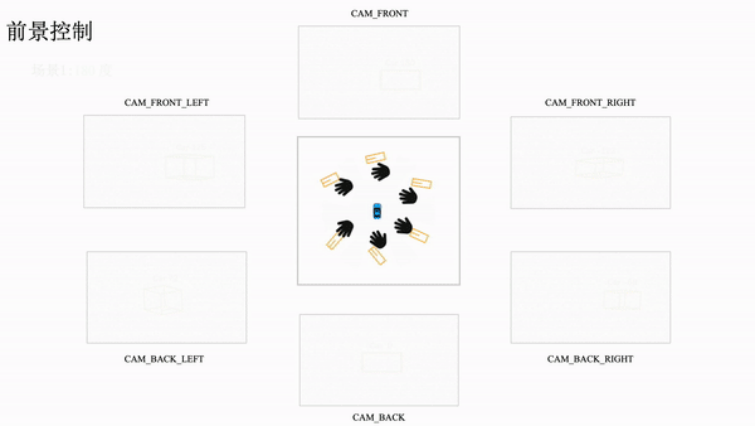
BEVControl : contrôle précis des éléments Street-View avec une cohérence multi-perspective via la mise en page d'esquisse BEV
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
