
 Périphériques technologiques
IA
Le débit est multiplié par 5. L'interface LLM pour concevoir conjointement le système back-end et le langage front-end est ici.
Périphériques technologiques
IA
Le débit est multiplié par 5. L'interface LLM pour concevoir conjointement le système back-end et le langage front-end est ici.
Le débit est multiplié par 5. L'interface LLM pour concevoir conjointement le système back-end et le langage front-end est ici.

Les grands modèles linguistiques (LLM) sont largement utilisés dans des tâches complexes qui nécessitent plusieurs appels de génération en chaîne, des techniques d'indication avancées, un flux de contrôle et une interaction avec l'environnement externe. Malgré cela, les systèmes efficaces actuels pour programmer et exécuter ces applications présentent des lacunes importantes.
Des chercheurs ont récemment proposé un nouveau langage de génération structuré appelé SGLang, qui vise à améliorer l'interactivité avec LLM. En intégrant la conception du système d'exécution back-end et le langage front-end, SGLang rend LLM plus performant et plus facile à contrôler. Cette recherche a également été relayée par Chen Tianqi, chercheur bien connu dans le domaine de l'apprentissage automatique et professeur assistant à la CMU.
De manière générale, les contributions de SGLang incluent principalement :
Sur le backend, l'équipe de recherche a proposé RadixAttention, une technologie de réutilisation du cache KV (cache KV) à travers plusieurs appels de génération LLM, automatique et efficace.
En développement front-end, l'équipe a développé un langage flexible spécifique à un domaine qui peut être intégré dans Python pour contrôler le processus de génération. Ce langage peut être exécuté en mode interpréteur ou en mode compilateur.
Les composants back-end et front-end fonctionnent ensemble pour améliorer l'exécution et l'efficacité de la programmation de programmes LLM complexes.
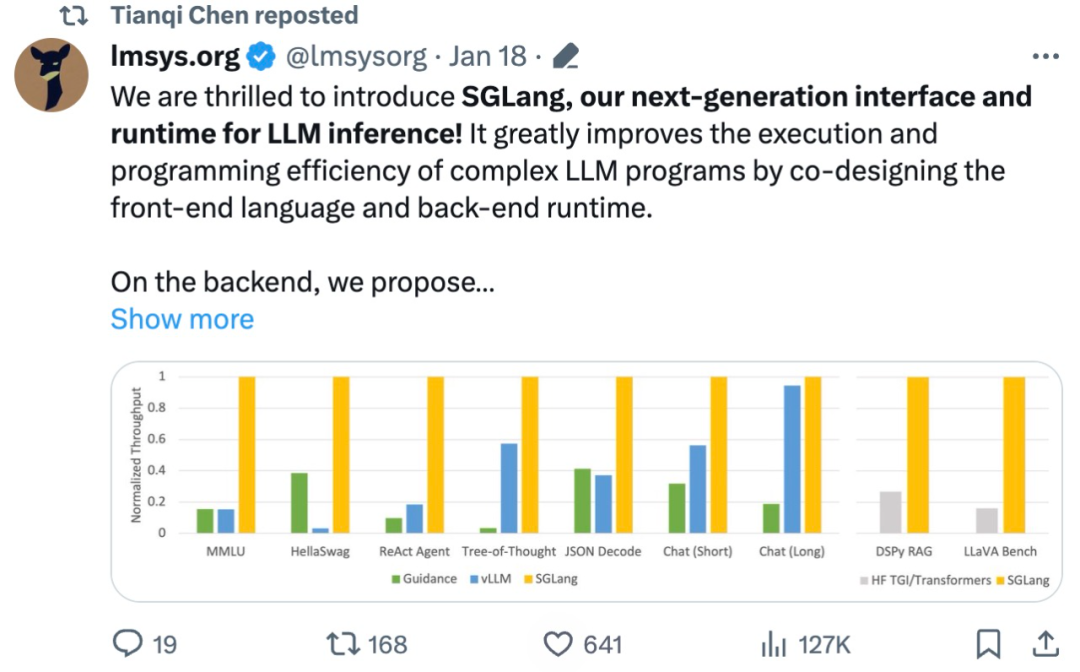
Cette étude utilise SGLang pour implémenter des charges de travail LLM courantes, notamment des tâches d'agent, d'inférence, d'extraction, de dialogue et d'apprentissage en quelques étapes, et adopte les modèles Llama-7B et Mixtral-8x7B sur le GPU NVIDIA A10G. Comme le montrent les figures 1 et 2 ci-dessous, le débit de SGLang est multiplié par 5 par rapport aux systèmes existants (c'est-à-dire Guidance et vLLM).

Figure 1 : Débit des différents systèmes sur les tâches LLM (A10G, Llama-7B sur FP16, parallélisme tensoriel = 1)
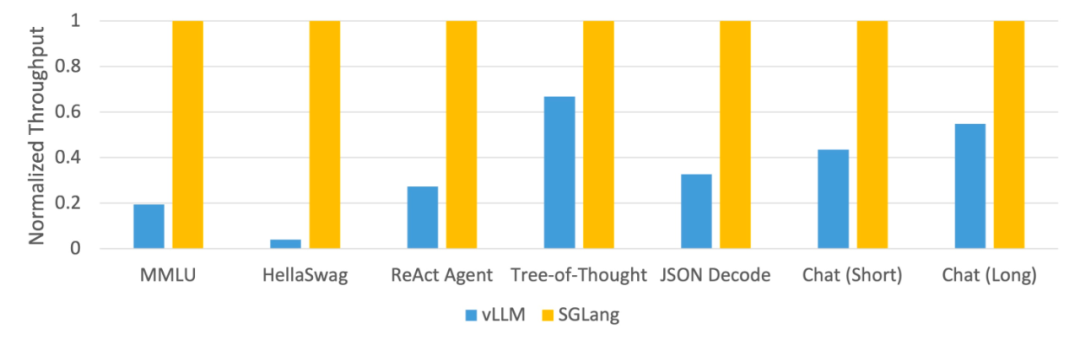
Figure 2 : Différents systèmes Débit sur les tâches LLM ( Mixtral-8x7B sur A10G, FP16, parallélisme tensoriel = 8)
Backend : réutilisation automatique du cache KV à l'aide de RadixAttention
Pendant le développement du runtime SGLang, cette étude a découvert la clé de l'optimisation des programmes LLM complexes : la réutilisation du cache KV , ce qui n'est pas bien géré par les systèmes actuels. La réutilisation du cache KV signifie que différentes invites avec le même préfixe peuvent partager le cache KV intermédiaire, évitant ainsi la mémoire et les calculs redondants. Dans les programmes complexes impliquant plusieurs appels LLM, différents modes de réutilisation du cache KV peuvent exister. La figure 3 ci-dessous illustre quatre de ces modèles que l'on retrouve couramment dans les charges de travail LLM. Bien que certains systèmes soient capables de gérer la réutilisation du cache KV dans certains scénarios, une configuration manuelle et des ajustements ad hoc sont souvent nécessaires. De plus, en raison de la diversité des modèles de réutilisation possibles, les systèmes existants ne peuvent pas s'adapter automatiquement à tous les scénarios, même via une configuration manuelle.
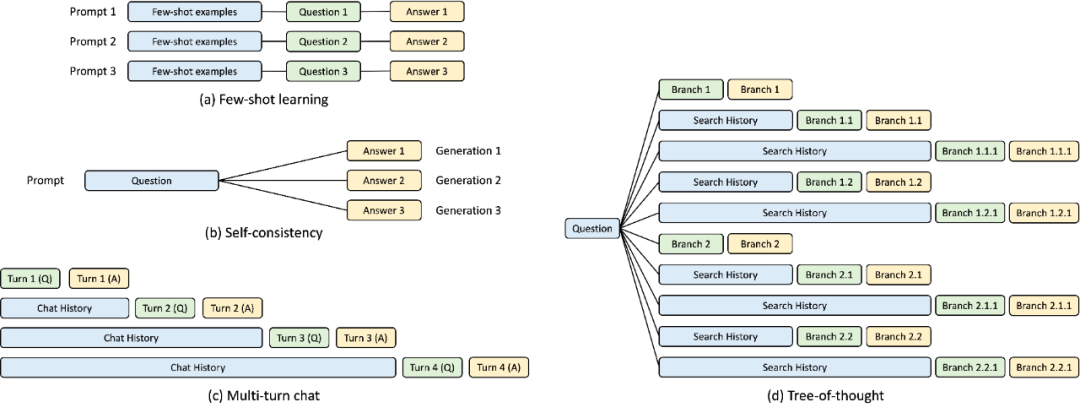
Figure 3 : Exemple de partage de cache KV. La boîte bleue est la partie d'invite partageable, la boîte verte est la partie non partageable et la boîte jaune est la sortie du modèle non partageable. Les parties partageables incluent de petits exemples d'apprentissage, des questions d'auto-cohérence, l'historique des conversations sur plusieurs cycles de dialogue et l'historique des recherches dans l'arbre de pensée.
Pour exploiter systématiquement ces opportunités de réutilisation, cette étude propose une nouvelle méthode de réutilisation automatique du cache KV au moment de l'exécution - RadixAttention. Au lieu de supprimer le cache KV après avoir terminé la demande de construction, cette méthode conserve l'invite et le cache KV du résultat de la construction dans une arborescence de base. Cette structure de données permet des recherches, des insertions et des expulsions efficaces de préfixes. Cette étude met en œuvre une politique d'expulsion des moins récemment utilisés (LRU), complétée par une politique de planification prenant en compte le cache pour améliorer le taux de réussite du cache.
Les arbres Radix peuvent être utilisés comme une alternative peu encombrante aux essais (arbres à préfixes). Contrairement aux arbres typiques, les bords des arbres à base peuvent être marqués non seulement avec un seul élément, mais également avec des séquences d'éléments de différentes longueurs, ce qui améliore l'efficacité des arbres à base.
Cette recherche utilise un arbre de base pour gérer le mappage entre les séquences de jetons agissant comme des clés et les tenseurs de cache KV correspondants agissant comme des valeurs. Ces tenseurs de cache KV sont stockés sur le GPU dans une présentation paginée, où chaque page a la taille d'un jeton.
Étant donné que la capacité de mémoire du GPU est limitée et que les tenseurs de cache KV illimités ne peuvent pas être recyclés, une stratégie d'expulsion est nécessaire. Cette étude adopte la stratégie d’expulsion LRU pour expulser les nœuds feuilles de manière récursive. De plus, RadixAttention est compatible avec les technologies existantes telles que le traitement par lots continu et l'attention paginée. Pour les modèles multimodaux, RadixAttention peut être facilement étendu pour gérer les jetons d'image.
Le diagramme ci-dessous illustre comment un arbre de base est conservé lors du traitement de plusieurs requêtes entrantes. Le frontal envoie toujours l'invite complète au runtime, et le runtime effectue automatiquement la correspondance, la réutilisation et la mise en cache des préfixes. La structure arborescente est stockée sur le processeur et nécessite une faible maintenance.
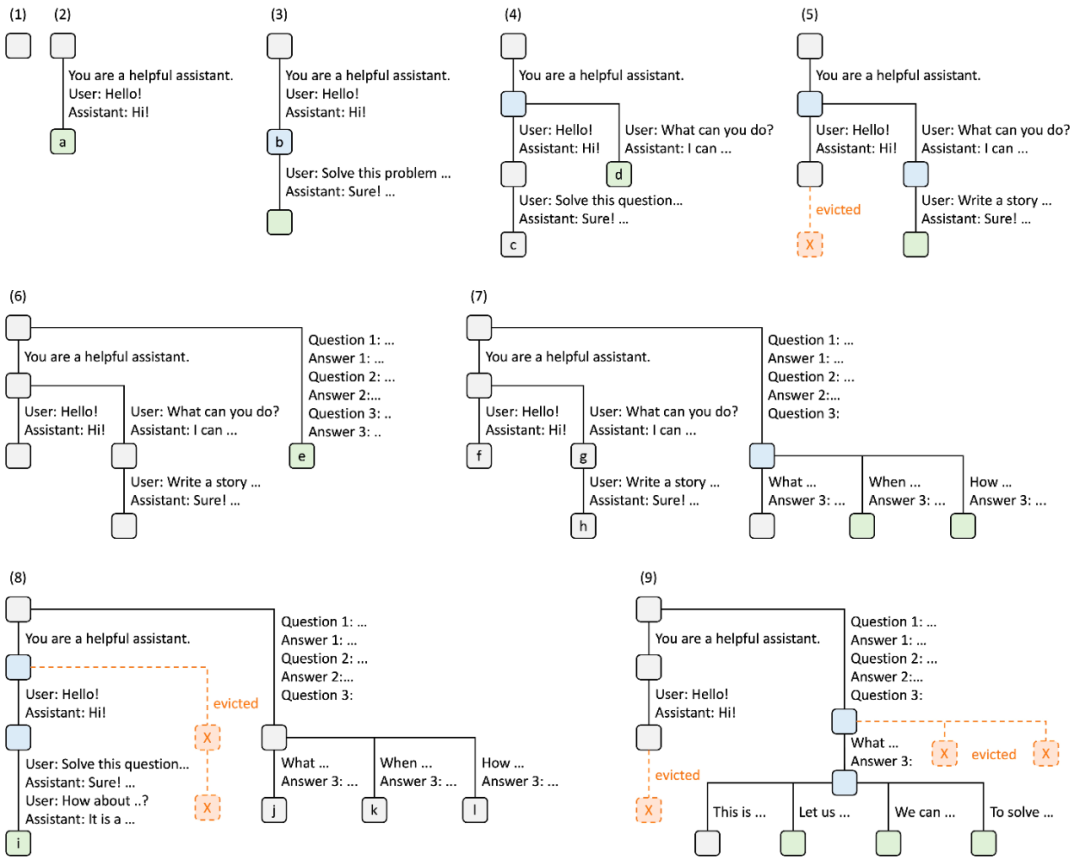
Figure 4. Exemple d'opération RadixAttention utilisant la politique d'expulsion LRU, expliquée en neuf étapes.
La figure 4 démontre l'évolution dynamique de l'arbre de base en réponse à diverses demandes. Ces requêtes incluent deux sessions de chat, un lot de requêtes d'apprentissage en quelques étapes et un échantillonnage auto-cohérent. Chaque bord d'arborescence est étiqueté avec une étiquette qui représente une sous-chaîne ou une séquence de jetons. Les nœuds sont codés par couleur pour refléter différents états : le vert indique les nœuds nouvellement ajoutés, le bleu indique les nœuds mis en cache auxquels on a accédé à ce moment-là et le rouge indique les nœuds qui ont été expulsés.
Front-end : la programmation LLM facilitée avec SGLang
Sur le front-end, la recherche propose SGLang, un langage spécifique à un domaine intégré dans Python qui permet l'expression de techniques d'invite avancées, de flux de contrôle et de multimodalité , décodage des contraintes et interactions externes. Les fonctions SGLang peuvent être exécutées via divers backends tels que OpenAI, Anthropic, Gemini et des modèles natifs.
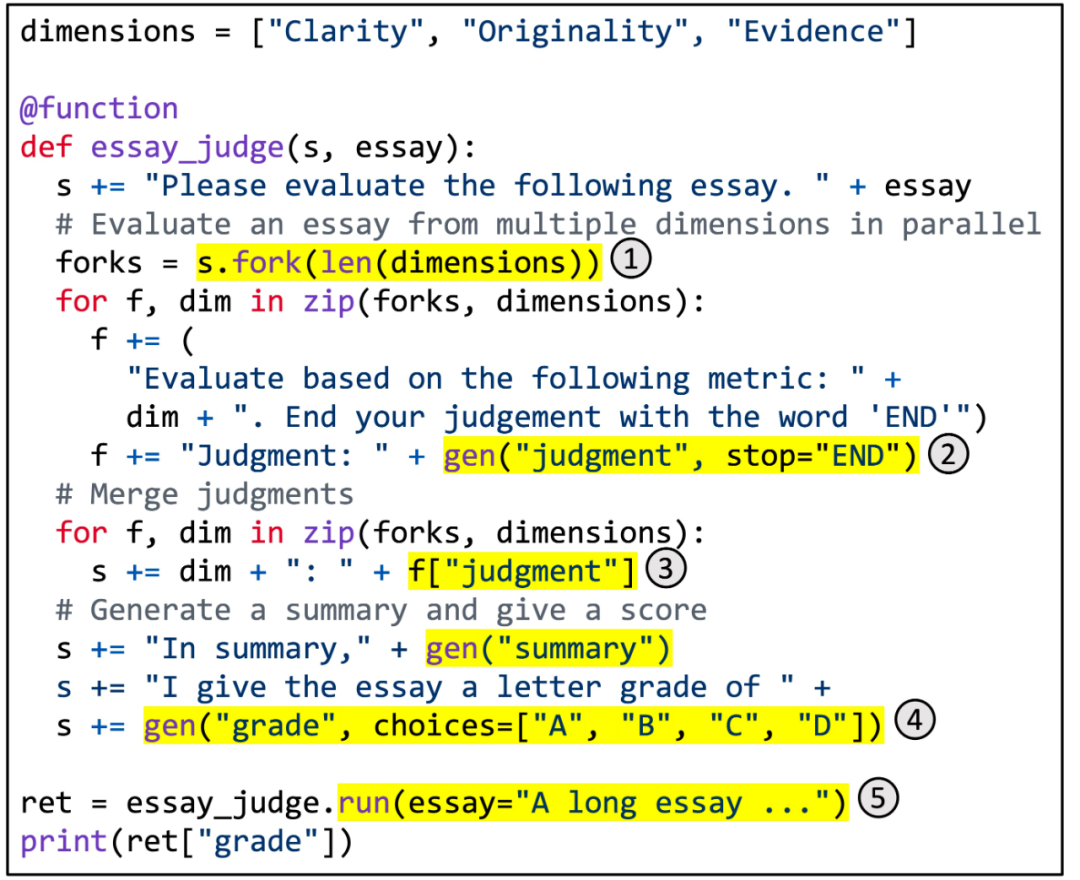
Figure 5. Utilisation de SGLang pour implémenter une notation d'articles multidimensionnelle.
La figure 5 montre un exemple spécifique. Il utilise la technologie d'invite de résolution de branche et de fusion pour obtenir une notation d'article multidimensionnelle. Cette fonction utilise LLM pour évaluer la qualité d'un article selon plusieurs dimensions, combiner les jugements, générer un résumé et attribuer une note finale. La zone en surbrillance illustre l'utilisation de l'API SGLang. (1) fork crée plusieurs copies parallèles de l'invite. (2) gen appelle la génération LLM et stocke les résultats dans des variables. Cet appel n'est pas bloquant, il permet donc à plusieurs appels de build de s'exécuter simultanément en arrière-plan. (3) [variable_name] récupère les résultats générés. (4) Choisir d'imposer des contraintes à la génération. (5) run exécute la fonction SGLang en utilisant ses paramètres.
Étant donné un tel programme SGLang, nous pouvons soit l'exécuter via l'interpréteur, soit le tracer sous forme de graphique de flux de données et l'exécuter à l'aide d'un exécuteur graphique. Cette dernière situation ouvre un espace pour certaines optimisations potentielles du compilateur, telles que le mouvement du code, la sélection d'instructions et le réglage automatique. La syntaxe de
SGLang est fortement inspirée de Guidance et introduit de nouvelles primitives, gérant également le parallélisme procédural et le traitement par lots. Toutes ces nouvelles fonctionnalités contribuent aux excellentes performances de SGLang.
Benchmarks
L'équipe de recherche a testé son système sur des charges de travail LLM courantes et a rapporté le débit atteint.
Plus précisément, l'étude a testé Llama-7B sur 1 GPU NVIDIA A10G (24 Go), Mixtral-8x7B sur 8 GPU NVIDIA A10G avec parallélisme tensoriel en utilisant la précision FP16 et en utilisant vllm v0 .2.5, Guidance v0.1.8 et Hugging Face TGI v1. .3.0 comme systèmes de référence.
Comme le montrent les figures 1 et 2, SGLang surpasse le système de base dans tous les benchmarks, atteignant une augmentation de 5 fois du débit. Il fonctionne également bien en termes de latence, en particulier pour la latence du premier jeton, où les accès au cache de préfixe peuvent apporter des avantages significatifs. Ces améliorations sont attribuées à la réutilisation automatique du cache KV de RadixAttention, au parallélisme dans le programme activé par l'interpréteur et à la co-conception des systèmes front-end et back-end. De plus, les études d'ablation montrent qu'il n'y a pas de surcharge significative qui entraîne l'activation permanente de RadixAttention au moment de l'exécution, même en l'absence d'accès au cache.
Lien de référence : https://lmsys.org/blog/2024-01-17-sglang/
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
L'auteur de ControlNet a encore un succès ! L'ensemble du processus de génération d'une peinture à partir d'une image, gagnant 1,4k étoiles en deux jours
Jul 17, 2024 am 01:56 AM
Il s'agit également d'une vidéo Tusheng, mais PaintsUndo a emprunté une voie différente. L'auteur de ControlNet, LvminZhang, a recommencé à vivre ! Cette fois, je vise le domaine de la peinture. Le nouveau projet PaintsUndo a reçu 1,4kstar (toujours en hausse folle) peu de temps après son lancement. Adresse du projet : https://github.com/lllyasviel/Paints-UNDO Grâce à ce projet, l'utilisateur saisit une image statique et PaintsUndo peut automatiquement vous aider à générer une vidéo de l'ensemble du processus de peinture, du brouillon de ligne au suivi du produit fini. . Pendant le processus de dessin, les changements de lignes sont étonnants. Le résultat vidéo final est très similaire à l’image originale : jetons un coup d’œil à un dessin complet.
 Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
Du RLHF au DPO en passant par TDPO, les algorithmes d'alignement des grands modèles sont déjà « au niveau des jetons »
Jun 24, 2024 pm 03:04 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Dans le processus de développement de l'intelligence artificielle, le contrôle et le guidage des grands modèles de langage (LLM) ont toujours été l'un des principaux défis, visant à garantir que ces modèles sont à la fois puissant et sûr au service de la société humaine. Les premiers efforts se sont concentrés sur les méthodes d’apprentissage par renforcement par feedback humain (RL
 En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
En tête de liste des ingénieurs logiciels d'IA open source, la solution sans agent de l'UIUC résout facilement les problèmes de programmation réels du banc SWE.
Jul 17, 2024 pm 10:02 PM
La colonne AIxiv est une colonne où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com Les auteurs de cet article font tous partie de l'équipe de l'enseignant Zhang Lingming de l'Université de l'Illinois à Urbana-Champaign (UIUC), notamment : Steven Code repair ; doctorant en quatrième année, chercheur
 Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Travail posthume de l'équipe OpenAI Super Alignment : deux grands modèles jouent à un jeu et le résultat devient plus compréhensible
Jul 19, 2024 am 01:29 AM
Si la réponse donnée par le modèle d’IA est incompréhensible du tout, oseriez-vous l’utiliser ? À mesure que les systèmes d’apprentissage automatique sont utilisés dans des domaines de plus en plus importants, il devient de plus en plus important de démontrer pourquoi nous pouvons faire confiance à leurs résultats, et quand ne pas leur faire confiance. Une façon possible de gagner confiance dans le résultat d'un système complexe est d'exiger que le système produise une interprétation de son résultat qui soit lisible par un humain ou un autre système de confiance, c'est-à-dire entièrement compréhensible au point que toute erreur possible puisse être trouvé. Par exemple, pour renforcer la confiance dans le système judiciaire, nous exigeons que les tribunaux fournissent des avis écrits clairs et lisibles qui expliquent et soutiennent leurs décisions. Pour les grands modèles de langage, nous pouvons également adopter une approche similaire. Cependant, lorsque vous adoptez cette approche, assurez-vous que le modèle de langage génère
 La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
La formation Axiom permet au LLM d'apprendre le raisonnement causal : le modèle à 67 millions de paramètres est comparable au niveau de mille milliards de paramètres GPT-4.
Jul 17, 2024 am 10:14 AM
Montrez la chaîne causale à LLM et il pourra apprendre les axiomes. L'IA aide déjà les mathématiciens et les scientifiques à mener des recherches. Par exemple, le célèbre mathématicien Terence Tao a partagé à plusieurs reprises son expérience de recherche et d'exploration à l'aide d'outils d'IA tels que GPT. Pour que l’IA soit compétitive dans ces domaines, des capacités de raisonnement causal solides et fiables sont essentielles. La recherche présentée dans cet article a révélé qu'un modèle Transformer formé sur la démonstration de l'axiome de transitivité causale sur de petits graphes peut se généraliser à l'axiome de transitivité sur de grands graphes. En d’autres termes, si le Transformateur apprend à effectuer un raisonnement causal simple, il peut être utilisé pour un raisonnement causal plus complexe. Le cadre de formation axiomatique proposé par l'équipe est un nouveau paradigme pour l'apprentissage du raisonnement causal basé sur des données passives, avec uniquement des démonstrations.
 Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
Les articles arXiv peuvent être publiés sous forme de 'barrage', la plateforme de discussion alphaXiv de Stanford est en ligne, LeCun l'aime
Aug 01, 2024 pm 05:18 PM
acclamations! Qu’est-ce que ça fait lorsqu’une discussion sur papier se résume à des mots ? Récemment, des étudiants de l'Université de Stanford ont créé alphaXiv, un forum de discussion ouvert pour les articles arXiv qui permet de publier des questions et des commentaires directement sur n'importe quel article arXiv. Lien du site Web : https://alphaxiv.org/ En fait, il n'est pas nécessaire de visiter spécifiquement ce site Web. Il suffit de remplacer arXiv dans n'importe quelle URL par alphaXiv pour ouvrir directement l'article correspondant sur le forum alphaXiv : vous pouvez localiser avec précision les paragraphes dans. l'article, Phrase : dans la zone de discussion sur la droite, les utilisateurs peuvent poser des questions à l'auteur sur les idées et les détails de l'article. Par exemple, ils peuvent également commenter le contenu de l'article, tels que : "Donné à".
 Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Une avancée significative dans l'hypothèse de Riemann ! Tao Zhexuan recommande fortement les nouveaux articles du MIT et d'Oxford, et le lauréat de la médaille Fields, âgé de 37 ans, a participé
Aug 05, 2024 pm 03:32 PM
Récemment, l’hypothèse de Riemann, connue comme l’un des sept problèmes majeurs du millénaire, a réalisé une nouvelle avancée. L'hypothèse de Riemann est un problème mathématique non résolu très important, lié aux propriétés précises de la distribution des nombres premiers (les nombres premiers sont les nombres qui ne sont divisibles que par 1 et par eux-mêmes, et jouent un rôle fondamental dans la théorie des nombres). Dans la littérature mathématique actuelle, il existe plus d'un millier de propositions mathématiques basées sur l'établissement de l'hypothèse de Riemann (ou sa forme généralisée). En d’autres termes, une fois que l’hypothèse de Riemann et sa forme généralisée seront prouvées, ces plus d’un millier de propositions seront établies sous forme de théorèmes, qui auront un impact profond sur le domaine des mathématiques et si l’hypothèse de Riemann s’avère fausse, alors parmi eux ; ces propositions qui en font partie perdront également de leur efficacité. Une nouvelle percée vient du professeur de mathématiques du MIT, Larry Guth, et de l'Université d'Oxford
 LLM n'est vraiment pas bon pour la prédiction de séries chronologiques. Il n'utilise même pas sa capacité de raisonnement.
Jul 15, 2024 pm 03:59 PM
LLM n'est vraiment pas bon pour la prédiction de séries chronologiques. Il n'utilise même pas sa capacité de raisonnement.
Jul 15, 2024 pm 03:59 PM
Les modèles linguistiques peuvent-ils vraiment être utilisés pour la prédiction de séries chronologiques ? Selon la loi des gros titres de Betteridge (tout titre d'actualité se terminant par un point d'interrogation peut recevoir une réponse « non »), la réponse devrait être non. Le fait semble être vrai : un LLM aussi puissant ne peut pas bien gérer les données de séries chronologiques. Les séries chronologiques, c'est-à-dire les séries chronologiques, comme leur nom l'indique, font référence à un ensemble de séquences de points de données disposées par ordre temporel. L'analyse des séries chronologiques est essentielle dans de nombreux domaines, notamment la prévision de la propagation des maladies, l'analyse du commerce de détail, la santé et la finance. Dans le domaine de l'analyse des séries chronologiques, de nombreux chercheurs ont récemment étudié comment utiliser les grands modèles linguistiques (LLM) pour classer, prédire et détecter les anomalies dans les séries chronologiques. Ces articles supposent que les modèles de langage capables de gérer les dépendances séquentielles dans le texte peuvent également se généraliser aux séries chronologiques.
