
 Périphériques technologiques
IA
Combattez le problème de « l'élégance conceptuelle » ! Google publie un nouveau cadre de perception du temps : la précision de la reconnaissance d'image a augmenté de 15 %
Périphériques technologiques
IA
Combattez le problème de « l'élégance conceptuelle » ! Google publie un nouveau cadre de perception du temps : la précision de la reconnaissance d'image a augmenté de 15 %
Combattez le problème de « l'élégance conceptuelle » ! Google publie un nouveau cadre de perception du temps : la précision de la reconnaissance d'image a augmenté de 15 %

Dans la recherche sur l'apprentissage automatique, la dérive des concepts a toujours été un problème épineux. Il fait référence aux changements dans la distribution des données au fil du temps, ce qui affecte l'efficacité du modèle. Cette situation oblige les chercheurs à ajuster constamment leurs modèles pour s'adapter aux nouvelles distributions de données. La clé pour résoudre le problème de la dérive des concepts est de développer des algorithmes capables de détecter et de s'adapter aux changements de données en temps opportun.
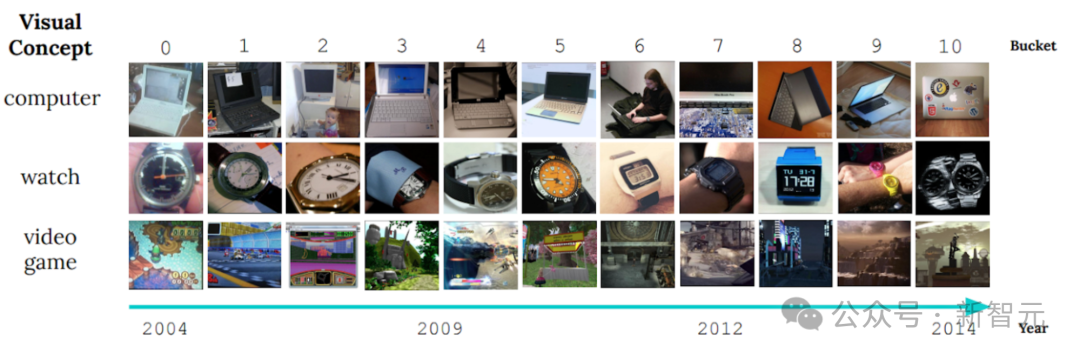
Un exemple évident est l'affichage d'images du benchmark d'apprentissage non stationnaire CLEAR, qui révèle le problème. changements importants dans les caractéristiques visuelles des objets au cours de la dernière décennie.
Ce phénomène est appelé « dérive lente des concepts » et pose un défi de taille aux modèles de classification d'objets. À mesure que l'apparence ou les attributs des objets changent au fil du temps, la recherche se concentre sur la façon de garantir que le modèle peut s'adapter à ce changement et continuer à classer avec précision.
Récemment, face à ce défi, l'équipe de recherche de Google AI a proposé une méthode basée sur l'optimisation appelée MUSCATEL (Multi-Scale Temporal Learning), qui a réussi à améliorer le modèle dans des performances axées sur des données énormes et changeantes. Ce résultat de recherche a été publié à AAAI2024.

Adresse papier : https://arxiv.org/abs/2212.05908
À l'heure actuelle, les méthodes principales de dérive des probabilités sont l'apprentissage en ligne et l'apprentissage continu (apprentissage en ligne et continu).
Le concept principal de ces méthodes est de mettre à jour en permanence le modèle pour s'adapter aux dernières données afin de garantir l'efficacité du modèle. Cependant, cette approche se heurte à deux défis principaux.
Ces méthodes se concentrent souvent uniquement sur les données les plus récentes, ignorant les informations précieuses contenues dans les données passées. De plus, ils supposent que la contribution de toutes les instances de données décroît uniformément avec le temps, ce qui n’est pas cohérent avec la réalité. La méthode
MUSCATEL peut résoudre efficacement ces problèmes. Elle attribue des scores d'importance aux instances de formation et optimise les performances du modèle dans les instances futures.
À cette fin, les chercheurs ont introduit un modèle auxiliaire qui combine les instances et leurs âges pour générer des scores. Le modèle auxiliaire et le modèle principal apprennent en collaboration pour résoudre deux problèmes fondamentaux.
Cette méthode présente d'excellentes performances dans les applications pratiques. Dans une expérience sur un ensemble de données réelles à grande échelle couvrant 39 millions de photos et d'une durée de 9 ans, par rapport à d'autres méthodes de base d'apprentissage en régime permanent, la précision a augmenté de 15 %. .
En même temps, elle montre également de meilleurs résultats que la méthode SOTA dans deux ensembles de données d'apprentissage non stationnaires et des environnements d'apprentissage continu.
Le défi de la dérive des concepts vers l'apprentissage supervisé
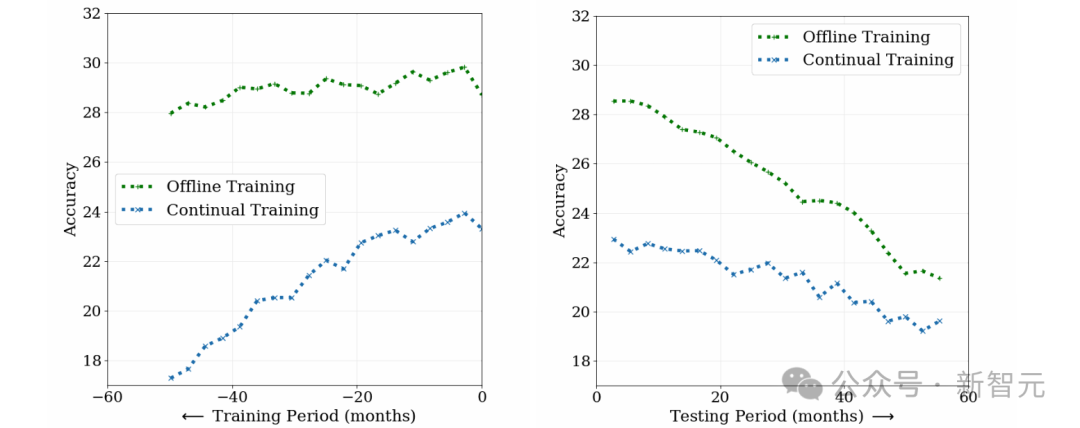
Afin d'étudier le défi de la dérive des concepts vers l'apprentissage supervisé, les chercheurs ont comparé la formation hors ligne (formation hors ligne) et la formation continue (formation continue) dans la tâche de classification de photos. méthode utilisant environ 39 millions de photos de réseaux sociaux sur une période de 10 ans.
Comme le montre la figure ci-dessous, bien que les performances initiales du modèle de formation hors ligne soient élevées, la précision diminue avec le temps et la compréhension des premières données est réduite en raison d'un oubli catastrophique.
Au contraire, bien que les performances initiales du modèle de formation continue soient moindres, il est moins dépendant des anciennes données et se dégrade plus rapidement lors des tests.
Cela montre que les données évoluent avec le temps et que l'applicabilité des deux modèles diminue. La dérive conceptuelle pose un défi à l'apprentissage supervisé, qui nécessite une mise à jour continue du modèle pour s'adapter aux changements de données.
MUSCATEL
MUSCATEL est une approche innovante conçue pour résoudre le problème de la lente dérive des concepts. Il vise à réduire la dégradation des performances du modèle à l'avenir en combinant intelligemment les avantages de l'apprentissage hors ligne et de l'apprentissage continu.
Face à d'énormes données d'entraînement, MUSCATEL montre son charme unique. Il s'appuie non seulement sur l'apprentissage hors ligne traditionnel, mais régule et optimise également soigneusement l'impact des données passées sur cette base, jetant ainsi une base solide pour les performances futures du modèle.
Afin d'améliorer encore les performances du modèle principal sur les nouvelles données, MUSCATEL introduit un modèle auxiliaire.
Sur la base des objectifs d'optimisation de la figure ci-dessous, le modèle auxiliaire de formation attribue des pondérations à chaque point de données en fonction de son contenu et de son âge. Cette conception permet au modèle de mieux s'adapter aux changements dans les données futures et de maintenir des capacités d'apprentissage continu.

Afin de co-évoluer le modèle auxiliaire et le modèle principal, MUSCATEL adopte également une stratégie de méta-apprentissage.
La clé de cette stratégie est de séparer efficacement la contribution des instances d'échantillon et de l'âge, et de définir les poids en combinant plusieurs échelles de temps de décroissance fixes, comme le montre la figure ci-dessous.
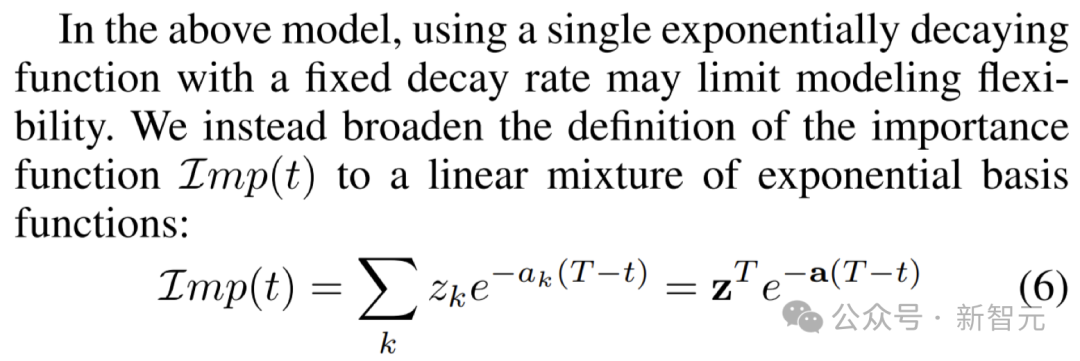
De plus, MUSCATEL apprend à « répartir » chaque instance à l'échelle de temps la plus appropriée pour un apprentissage plus précis.
Score de poids d'instance
Comme le montre la figure ci-dessous, dans le défi de reconnaissance d'objet CLEAR, le modèle auxiliaire appris a ajusté avec succès le poids des objets : le poids des objets avec une nouvelle apparence a augmenté et le poids des objets avec une apparence ancienne diminuée.

Grâce à l'évaluation de l'importance des caractéristiques basée sur le gradient, on peut constater que le modèle auxiliaire se concentre sur le sujet dans l'image, plutôt que sur l'arrière-plan ou les caractéristiques indépendantes de l'âge de l'instance, démontrant ainsi son efficacité.

Une avancée significative dans la tâche de classification de photos à grande échelle
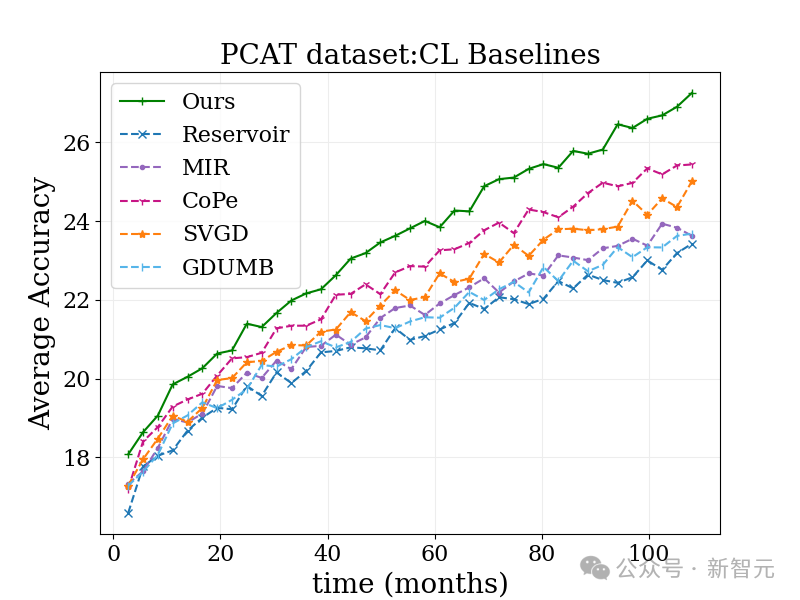
La tâche de classification de photos à grande échelle (PCAT) a été étudiée sur l'ensemble de données YFCC100M, en utilisant les données des cinq premières années comme base ensemble de formation et les données des cinq dernières années comme ensemble de test.
Par rapport aux bases de référence non pondérées et à d'autres techniques d'apprentissage robustes, la méthode MUSCATEL présente des avantages évidents.
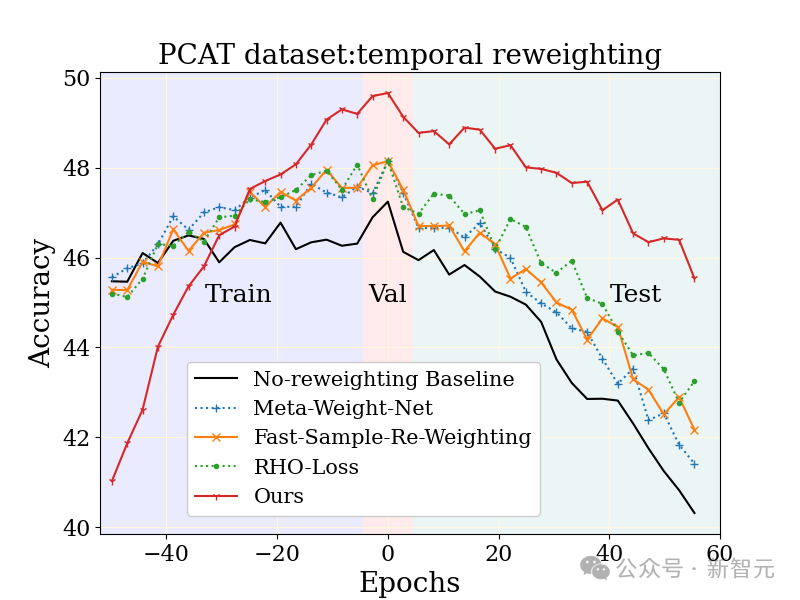
Il est à noter que la méthode MUSCATEL ajuste consciemment l'exactitude des données d'un passé lointain en échange d'une amélioration significative des performances lors des tests. Cette stratégie optimise non seulement la capacité du modèle à s'adapter aux données futures, mais montre également une moindre dégradation lors des tests.
Large utilisation vérifiée sur tous les ensembles de données
L'ensemble de données pour le défi d'apprentissage non stationnaire couvre une variété de sources et de modalités de données, notamment des photos, des images satellite, des textes sur les réseaux sociaux, des dossiers médicaux, des lectures de capteurs et des données tabulaires. , la taille des données varie également de 10 000 à 39 millions d'instances. Il convient de noter que la meilleure méthode précédente peut être différente pour chaque ensemble de données. Cependant, comme le montre la figure ci-dessous, dans le contexte de la diversité des données et des méthodes, la méthode MUSCATEL a montré des effets de gain significatifs. Ce résultat démontre pleinement la large applicabilité de MUSCATEL.
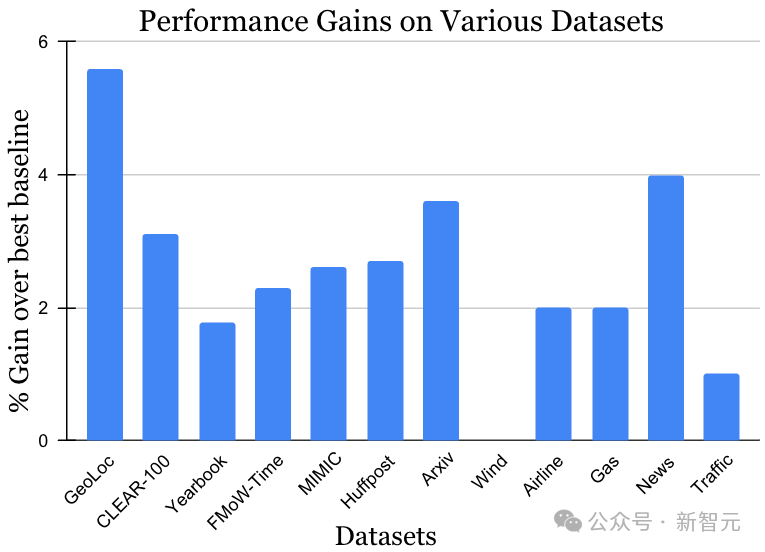
Développez les algorithmes d'apprentissage continu pour faire face aux défis de traitement de données à grande échelle
Face à des montagnes de données à grande échelle, les méthodes d'apprentissage hors ligne traditionnelles peuvent sembler inadéquates.
Avec cette problématique en tête, l’équipe de recherche a intelligemment adapté une méthode inspirée de l’apprentissage continu pour s’adapter facilement au traitement de données à grande échelle.
Cette méthode est très simple, c'est-à-dire ajouter un poids temporel à chaque lot de données, puis mettre à jour le modèle séquentiellement.
Bien qu'il existe encore quelques petites limitations, telles que le fait que les mises à jour du modèle ne peuvent être basées que sur les dernières données, l'effet est étonnamment bon !
Dans le test de classification de photos ci-dessous, cette méthode a mieux fonctionné que l'algorithme d'apprentissage continu traditionnel et divers autres algorithmes.
De plus, comme son idée s'accorde bien avec de nombreuses méthodes existantes, on s'attend à ce que lorsqu'elle est combinée avec d'autres méthodes, l'effet soit encore plus étonnant !
De manière générale, l'équipe de recherche a combiné avec succès l'apprentissage hors ligne et continu pour résoudre le problème de dérive des données qui tourmente depuis longtemps l'industrie.
Cette stratégie innovante atténue non seulement considérablement le phénomène « d'oubli de catastrophe » du modèle, mais ouvre également une nouvelle voie pour le développement futur de l'apprentissage continu de données à grande échelle, injectant une nouvelle vitalité dans l'ensemble du domaine de l'apprentissage automatique. .
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
