

Créer un système ERP de distribution et de service

Au début, comme la quantité de données n'était pas importante, les performances du système étaient plutôt bonnes et diverses requêtes de liste, requêtes de rapport, fonctions d'exportation de données Excel, etc. étaient toutes utilisées sans problème. Cependant, à mesure que les activités de l'entreprise se développaient et que le volume des commandes s'accumulait de jour en jour, et que la demande de requêtes de rapports et d'exportations de données de divers départements commerciaux continuait d'augmenter au cours de la période ultérieure, nous avons progressivement senti que le système fonctionnait de plus en plus lentement. La première solution à laquelle nous pouvons penser est donc d’optimiser la base de données des goulots d’étranglement du système. L'une de nos tentatives possibles consiste à placer la base de données séparément sur un serveur pour séparer la base de données et l'application, ou à établir divers index de table de base de données, à optimiser le code du programme, etc. Après de telles recherches et optimisations, les performances de certaines fonctions du système peuvent en effet être grandement améliorées, mais nous avons quand même constaté que l'interrogation des données et l'exportation de certaines listes de fonctions sont encore très lentes, ou que la quantité de données continue de s'accumuler, le La fonction d'exportation de liste à l'origine plus rapide est également de plus en plus lente. Nous avons essayé différentes méthodes, mais nous n'avons finalement pas pu atteindre la vitesse de performance idéale du système.
Afin d'améliorer les performances du système, nous pouvons prendre l'initiative d'apprendre de l'expérience technique de certaines sociétés Internet, telles que la haute concurrence, les hautes performances, le big data, la séparation lecture-écriture et d'autres solutions, mais constater que nous n'avons aucun moyen commencer. On pourrait penser que les caractéristiques métiers du système sont différentes. La concurrence du système ERP n'est pas élevée, principalement en raison de la complexité de l'entreprise.Le degré de couplage des différentes entreprises est beaucoup plus élevé que celui des applications Internet, ce qui rend la logique de requête de données beaucoup plus compliquée que cela. du système Internet. Les données interrogées à partir d'une page de liste nécessitent souvent Le résultat peut être obtenu en corrélant 4 ou 5 tableaux. Certains rapports en contiennent même plus. En plus de la nature transactionnelle des diverses opérations commerciales et des exigences élevées en matière de cohérence des données, nous étions souvent pris au dépourvu et incapables d'optimiser davantage le système.
Il était une fois, j'étais frustré pour une raison ou une autre, pensant que le système ERP était très spécial et incurable, mais plus tard. . .
Je ne le pense plus, il semble y avoir une nouvelle solution O(∩_∩)O haha~
Avant de décrire le plan spécifique, permettez-moi d'abord de partager mes réflexions. Tout d’abord, je pense qu’avant de construire un système ERP, nous devons avoir la réflexion Internet d’aujourd’hui. Nous ne voulons plus construire un système unifié. Nous devons diviser un grand système en petits systèmes. Ces petits systèmes sont ensuite autorisés à communiquer entre eux via des interfaces système. Cela forme un vaste système, en particulier la pensée Internet « distribuée » et « orientée vers les services ». Laissez le système être un système qui prend intrinsèquement en charge une grande évolutivité en termes de conception architecturale.
Comment faire ? Plus précisément, il est nécessaire de diviser la gestion des commandes, la gestion des marchandises, la production et les achats, la gestion des entrepôts, la gestion logistique et la gestion financière en un sous-système. Ces sous-systèmes peuvent être conçus et développés indépendamment, et les interfaces de données requises par divers autres sous-systèmes peuvent être exposées au monde extérieur. Chaque sous-système possède une base de données distincte. Même ces sous-systèmes peuvent être développés et maintenus par différentes équipes, en utilisant différents systèmes techniques et différentes bases de données. Au lieu de les intégrer dans le même système vaste et complet, une base de données vaste et complète, comme auparavant.
Quels sont les avantages du nouveau système d'architecture ?
La première et la plus importante chose est de résoudre le problème de performances du système. Dans le passé, il n'existait qu'une seule instance de base de données et il était impossible de l'étendre à plusieurs instances afin de pouvoir équilibrer la charge en ajoutant davantage d'instances de base de données lorsque les performances étaient limitées. Certains diront peut-être qu’une solution de séparation lecture-écriture peut être utilisée, mais en raison des caractéristiques du système ERP, cette solution est souvent irréaliste. Par exemple, lors de l'exploitation d'un inventaire, vous ne pouvez pas lire l'inventaire à partir de la bibliothèque de lecture, puis écrire l'inventaire dans la bibliothèque d'écriture. La réplication maître-esclave étant sensible au facteur temps, l'inventaire écrit ne peut pas être écrit immédiatement dans la base de données esclave. Il existe de nombreux scénarios de ce type dans un ERP. De plus, la bibliothèque d'écriture ne peut pas être étendue, il ne peut y en avoir qu'une. La nouvelle solution de conception consiste à séparer la bibliothèque d'écriture et chaque sous-système possède sa propre base de données.
Deuxièmement, la mise à jour est très pratique et chaque sous-système existe en tant que microservice d'arrière-plan. Il existe un projet Web distinct dans le front-end, et ce projet Web appelle les interfaces de service de ces sous-systèmes en arrière-plan. Avec cette conception, lorsqu'un certain sous-système métier doit être mis à jour, il peut être mis à jour indépendamment. Contrairement à l'architecture précédente à processus unique, une petite mise à jour nécessitait un redémarrage de l'ensemble du système, entraînant la perte de la session utilisateur et la reconnexion de l'utilisateur. La conception actuelle n’aura pas ce problème.
Vue du déploiement physique du système
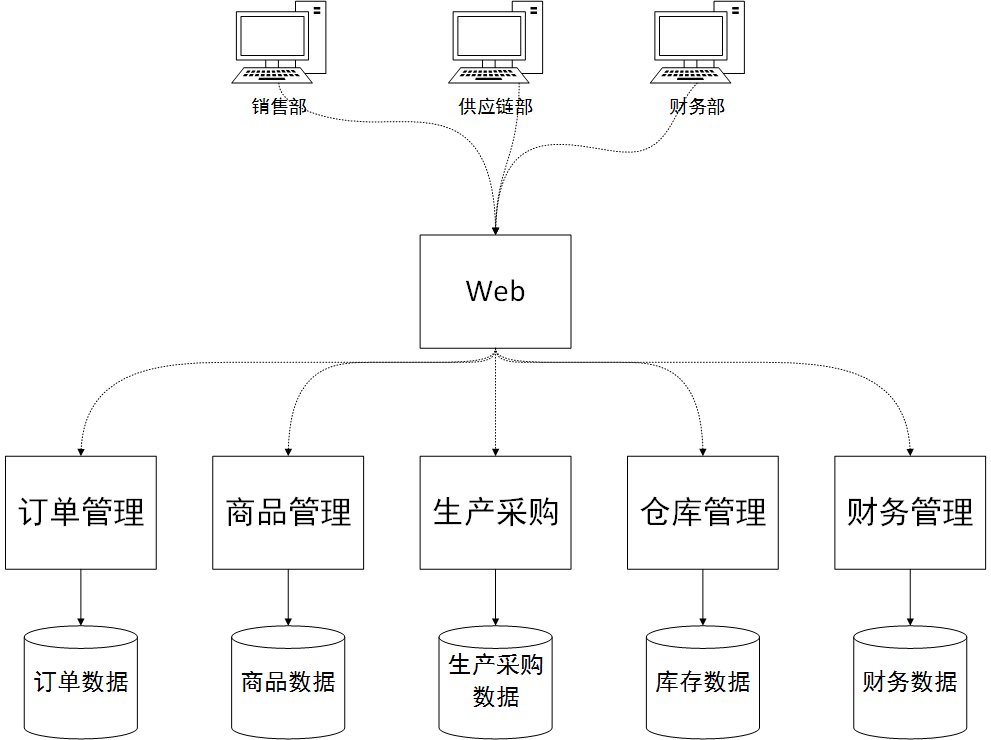
Le fractionnement de la couche application est la mise en œuvre du concept d'architecture « microservice ». Divisez l'architecture d'origine, vaste et complète, à processus unique en applications déployables indépendamment en fonction des modules métier pour obtenir des mises à jour et des mises à niveau fluides du système et faciliter l'expansion de la charge. Plus précisément, techniquement, vous pouvez utiliser une interface de style repos ou un framework comme Dubbo en Java pour simplifier la complexité du développement. Le client Web ERP ou autre client mobile est également une application distincte qui fait office de couche de présentation. Il est très fin, il accepte simplement les paramètres et appelle les interfaces de divers autres programmes de microservices en arrière-plan pour obtenir les données à afficher. Les microservices agissent comme une couche de logique métier. Chaque microservice est un programme qui peut être déployé indépendamment et fournit des interfaces d'accès aux données externes.
Les microservices peuvent utiliser divers frameworks RPC populaires, tels que dubbo, qui peuvent prendre en charge plusieurs protocoles d'appel Http, TCP, etc. Ces frameworks facilitent le codage. Le framework encapsule les détails de communication de données sous-jacents, permettant au client d'exécuter des méthodes à distance comme s'il s'agissait de lui. étaient des méthodes locales tout aussi simples.
L'architecture de microservices Dubbo prend également en charge la gouvernance des services, l'équilibrage de charge et d'autres fonctions. Cela peut non seulement améliorer la disponibilité du système, mais également améliorer dynamiquement les performances de la couche d'application du système. Par exemple, dans la gestion d'entrepôt, l'activité d'entreposage est très occupée et consomme beaucoup de ressources CPU et mémoire. Nous pouvons ajouter une autre machine et déployer un service de gestion d'entrepôt distinct. Cela permet à l’ensemble du système de disposer de deux services de gestion d’entrepôt travaillant en même temps pour équilibrer la charge. Et tout cela se fait automatiquement dans le centre d'enregistrement des services, tel que Zookeeper.
La structure du microservice prend naturellement en charge les opérations de mise à jour et de mise à niveau du système. Par exemple, si le module financier a une nouvelle exigence et doit être mis en ligne, il suffit de remplacer le service du module financier et de le redémarrer. Cela n'aura pas beaucoup d'impact sur les utilisateurs déjà connectés au système. Ils n'auront pas besoin de se reconnecter au système et l'utilisation des autres services du module ne sera pas affectée.
Le goulot d'étranglement de la base de données est une blessure permanente au système ERP. Une grande quantité de logique de connexion aux tables de requêtes de données complexes inonde l’ensemble du système. La clé du succès de la division verticale des bases de données réside dans la manière de repenser le couplage mutuel des différents modules de la couche de données du système. Si vous parvenez à résoudre ce problème, les dommages permanents pourront être résolus.
Examinons d'abord un problème typique de couplage de modules de couche de données. L'exigence est d'afficher l'inventaire du matériel, les champs de liste : numéro de matériau, nom du matériau, catégorie, entrepôt, quantité
Liste du matériel :
Tableau d'inventaire :
Les tableaux de catégories et d’entrepôts sont omis. . .
Évidemment, dans une base de données traditionnelle, nous n'avons besoin que d'une simple opération de jointure pour associer ces deux tables, et associer les tables de catégories et d'entrepôt pour interroger les données souhaitées. Mais maintenant, dans notre architecture, la table des matériaux et la table des produits ne se trouvent pas dans la même instance de base de données, et nous ne pouvons pas utiliser l'opération de jointure. Alors, comment réaliser les exigences ?
La nouvelle architecture nous permet uniquement d'obtenir des données via l'interface du service de l'autre partie et ne peut pas s'associer directement à la base de données privée du service de l'autre partie. Au moins d'un point de vue architectural, d'un point de vue orienté service, vous ne pouvez pas accéder directement à la base de données du service de l'autre partie. Dans ce cas, en supposant que le sous-système du module Web appelle le sous-système de l'entrepôt pour obtenir des données, nous devons créer une méthode de service dans le module de l'entrepôt pour assembler les données. Ensuite, il est renvoyé au sous-système Web. Comme le montre la figure ci-dessous, la méthode de gestion d'entrepôt obtient d'abord le code article de la table d'inventaire local et les informations du champ de nom d'entrepôt de la table d'entrepôt, après la pagination, elle est enfin prête à renvoyer 20 éléments de données au module Web. L'ID de matériau dans ces 20 éléments de données est En tant que paramètre pour demander le sous-système de module de produits, le sous-système de produits renvoie les informations sur les produits liées à ces 20 ID de matériaux au module de gestion d'entrepôt, puis le module de gestion d'entrepôt réassemble les deux données de terrain. du nom du matériau et de la catégorie requis dans la liste supérieure pour répondre à l'exigence finale. Données renvoyées au sous-système Web.
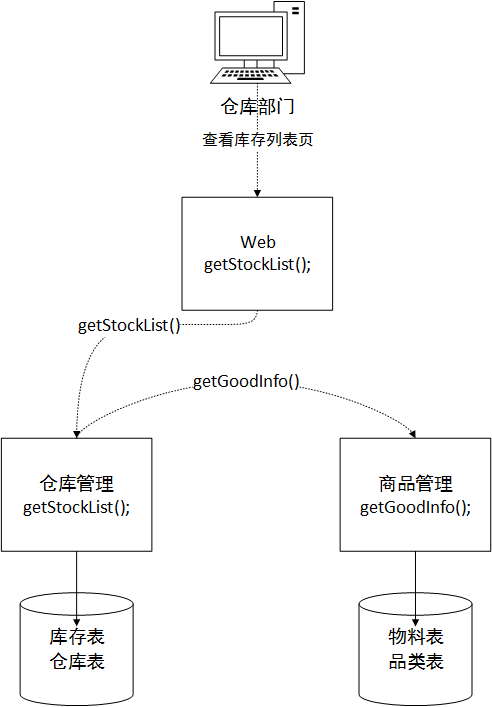
Peut-être direz-vous que c'est trop gênant. Les performances de cette méthode ne sont certainement pas aussi élevées que celles de la jointure directe et elle ne peut pas résoudre le problème de performances. Il semble que ce soit le cas, mais si vous y réfléchissez bien, dans un environnement où la concurrence du système est faible, le volume de données est faible et l'entreprise n'est pas occupée, les performances ne sont en effet pas aussi rapides que la jointure traditionnelle. méthode dans une donnée. Mais réfléchissons-y plus tard ! Notre conception architecturale actuelle consiste à diviser une base de données en plusieurs bases de données, et chaque base de données peut s'exécuter sur un serveur distinct, afin que la pression sur la base de données puisse être chargée à l'avenir. Dans l’ensemble, cela empêchera la base de données de devenir un goulot d’étranglement en termes de performances lorsque l’entreprise sera occupée à l’avenir. C’est excitant d’y penser, n’est-ce pas ?
À ce stade, certaines personnes se demanderont à nouveau : que se passera-t-il si le volume de données et l'activité du système devenaient plus importants à l'avenir, et que même les diviser en plusieurs bases de données ne suffisait pas ? Ma méthode est basée sur une base de données fractionnée, et chaque bibliothèque peut séparer la lecture et l'écriture, utiliser la mise en cache, etc. Vous pouvez même continuer à diviser le sous-système en plusieurs sous-systèmes. Cela dépend de l'occupation du module métier.
Certaines personnes peuvent se demander à nouveau, certaines logiques de requête de liste sont très complexes et impliquent plus de dix tables si les données sont divisées selon la méthode ci-dessus, ce sera un désastre ! Oui, tu as raison. Dans ce cas, mon plan est d'utiliser cette requête de données plus complexe au niveau du rapport pour afficher les exigences, et je peux créer un système de rapport distinct. La conception de la base de données de rapports adopte une approche d’entrepôt de données. Pour des performances de lecture plus élevées, nous pouvons concevoir la table de base de données dans de nombreux champs redondants, ce qui est une conception anti-paradigme, et créer de nombreux index combinés.
La clé du succès de ce système est la synchronisation des données et de la bibliothèque métier principale du système ERP. Généralement, vous pouvez écrire un programme de synchronisation planifiée pour générer directement les données finales ou intermédiaires requises pour les vues de rapport via la sélection, la transformation, etc. des données dans le système commercial principal de l'ERP afin de simplifier les requêtes associées. Le système de reporting peut également être conçu à l’aide d’une architecture de microservices. Comme le montre l'image ci-dessous :
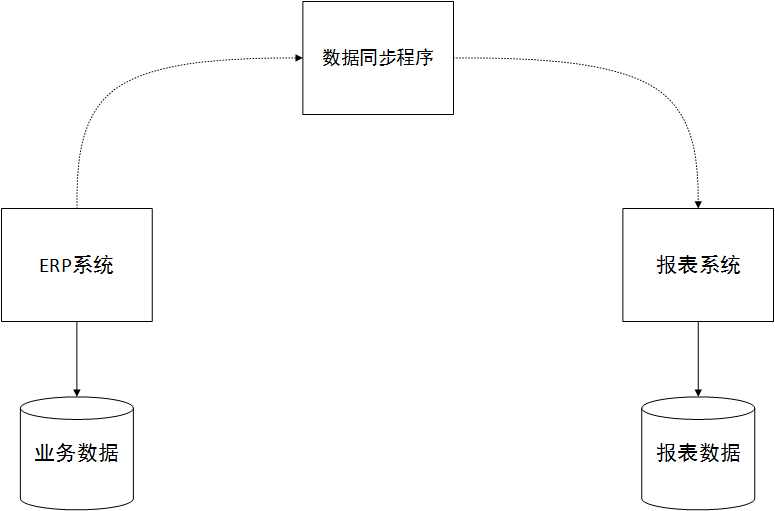
Si les données requises pour le rapport nécessitent du temps réel, nous pouvons permettre au système ERP de déclencher une demande de synchronisation des données pendant les opérations commerciales et de la synchroniser avec la bibliothèque de rapports en temps réel.
Quelqu'un se demandera peut-être encore : de nombreuses opérations dans le système ERP nécessitent une transactionnalité. Comment parvenir à la transactionnalité et garantir la cohérence des données après la division du système ?
C’est une bonne question, et c’est aussi la dernière question à laquelle j’ai réfléchi avant de décider d’écrire cet article. Dans une architecture de microservices, il n'est pas facile de mettre en œuvre des services offrant des services, du moins pas aussi pratiques que des applications locales utilisant des transactions de bases de données locales, avec des performances efficaces et une bonne cohérence des données.
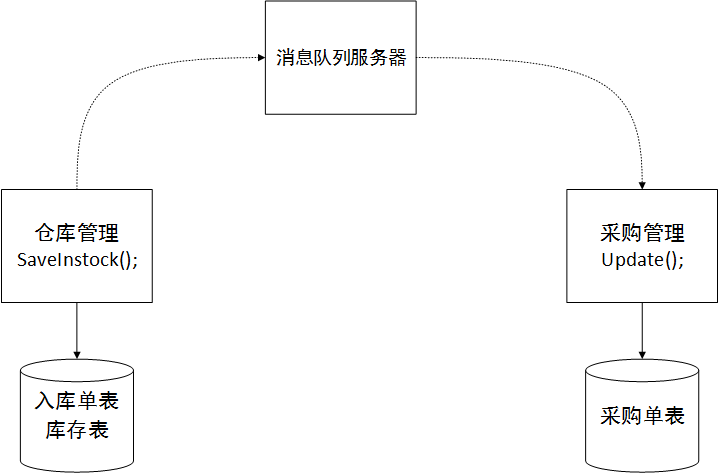
Peut-être avez-vous entendu parler du concept de transactions distribuées. Il existe deux scénarios. L'un consiste à utiliser plusieurs bases de données dans une seule application. Pour garantir la cohérence des données, des transactions distribuées doivent être utilisées. Il existe une autre situation spécifique à notre architecture. Les transactions distribuées dans un environnement de microservices, en particulier, utilisent une analogie. Le fonctionnement des achats et du stockage est conçu dans le service de gestion d’entrepôt. Après le stockage, la quantité stockée dans la commande d'achat dans le sous-système d'approvisionnement doit être mise à jour. Ce processus nécessite une cohérence des données, c'est-à-dire que la quantité dans la table d'inventaire est écrite dans la table d'inventaire une fois que la commande d'achat a été placée avec succès dans l'entrepôt, et la quantité dans la table de commande d'achat doit être mise à jour en même temps. Nous ne pouvons pas accéder directement à la base de données du service des achats dans le service d'entrepôt. Nous devons utiliser l'interface de service fournie par le service des achats. Si oui, comment pouvons-nous garantir la cohérence des données ? Car il est très possible que le tableau d'inventaire soit écrit avec succès, mais que l'appel au service des achats pour écrire les données du bon de commande échoue. Cela peut être dû à des problèmes de réseau et les données sont donc incohérentes.
Dans la technologie des transactions distribuées, il existe une possibilité d'atteindre une cohérence éventuelle, ce qui signifie que tant que je peux garantir que les données des deux côtés atteignent la cohérence, il n'est pas nécessaire d'utiliser des transactions. Il y a donc un plan. Par exemple, lorsque le sous-système d'entrepôt traite les achats et l'entreposage, il doit ajouter des données de commande d'entrepôt et mettre à jour les données d'inventaire et d'autres tables. Ces multiples tables se trouvent toutes dans le sous-système d'entrepôt et nous pouvons utiliser une transaction locale pour garantir la cohérence des données des tables dans le sous-système d'entrepôt. Appelez ensuite le sous-système d’approvisionnement pour mettre à jour la quantité en magasin dans le bon de commande. Afin d'éviter que ce processus ne soit soudainement interrompu et entraîne l'échec de l'appel, nous envisageons d'ajouter un middleware de file d'attente de messages tel qu'ActiveMQ. Si l'interface ne parvient pas à revenir, nous écrirons la demande de traitement à MQ. Une fois que le sous-système d'approvisionnement sera revenu à la normale, MQ informera le sous-système d'approvisionnement de traiter l'opération de mise à jour. Puisqu'il n'y aura plus de notifications une fois le message consommé, une exception s'est produite lors du traitement du sous-système d'approvisionnement, provoquant l'échec de la mise à jour. Le problème doit être écrit dans la bibliothèque de journaux locale afin d'informer l'administrateur d'une compensation ultérieure. traitement. De cette manière, diverses méthodes peuvent être utilisées pour atteindre la cohérence finale des données. Même si cela semble un peu déroutant, c’est la solution. Il n'y a rien de mieux. Ou après l'échec de la mise à jour, appelez à nouveau le sous-système de l'entrepôt pour annuler les données de réception d'entrepôt et d'inventaire afin d'obtenir une cohérence finale ! Comme le montre l'image :
Je suis très honorée de pouvoir partager mes connaissances et mes expériences avec tout le monde. C'est grâce au partage altruiste de chacun que nous pouvons grandir et progresser. J'ai rarement partagé des choses ces dernières années, parfois parce que je suis très occupé au travail et que je n'en ai pas. il est temps d’écrire quoi que ce soit, parfois c’est parce que je suis paresseux ou que je n’ai rien de nouveau à partager avec tout le monde. Enfin, j'espère que tout le monde critiquera et corrigera mes défauts de partage, afin que nous puissions progresser ensemble !
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Différence entre Centos et Ubuntu
Apr 14, 2025 pm 09:09 PM
Les principales différences entre Centos et Ubuntu sont: l'origine (Centos provient de Red Hat, pour les entreprises; Ubuntu provient de Debian, pour les particuliers), la gestion des packages (Centos utilise Yum, se concentrant sur la stabilité; Ubuntu utilise APT, pour une fréquence de mise à jour élevée), le cycle de support (CentOS fournit 10 ans de soutien, Ubuntu fournit un large soutien de LT tutoriels et documents), utilisations (Centos est biaisé vers les serveurs, Ubuntu convient aux serveurs et aux ordinateurs de bureau), d'autres différences incluent la simplicité de l'installation (Centos est mince)
 Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop
Apr 15, 2025 am 11:45 AM
Comment utiliser Docker Desktop? Docker Desktop est un outil pour exécuter des conteneurs Docker sur les machines locales. Les étapes à utiliser incluent: 1. Installer Docker Desktop; 2. Démarrer Docker Desktop; 3. Créer une image Docker (à l'aide de DockerFile); 4. Build Docker Image (en utilisant Docker Build); 5. Exécuter Docker Container (à l'aide de Docker Run).
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos arrête la maintenance 2024
Apr 14, 2025 pm 08:39 PM
Centos sera fermé en 2024 parce que sa distribution en amont, Rhel 8, a été fermée. Cette fermeture affectera le système CentOS 8, l'empêchant de continuer à recevoir des mises à jour. Les utilisateurs doivent planifier la migration et les options recommandées incluent CentOS Stream, Almalinux et Rocky Linux pour garder le système en sécurité et stable.
 Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Comment installer CentOS
Apr 14, 2025 pm 09:03 PM
Étapes d'installation de CentOS: Téléchargez l'image ISO et Burn Bootable Media; démarrer et sélectionner la source d'installation; sélectionnez la langue et la disposition du clavier; configurer le réseau; partitionner le disque dur; définir l'horloge système; créer l'utilisateur racine; sélectionnez le progiciel; démarrer l'installation; Redémarrez et démarrez à partir du disque dur une fois l'installation terminée.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 Comment monter un disque dur dans les centos
Apr 14, 2025 pm 08:15 PM
Comment monter un disque dur dans les centos
Apr 14, 2025 pm 08:15 PM
Le support de disque dur CentOS est divisé en étapes suivantes: Déterminez le nom du périphérique du disque dur (/ dev / sdx); créer un point de montage (il est recommandé d'utiliser / mnt / newdisk); Exécutez la commande Mount (mont / dev / sdx1 / mnt / newdisk); modifier le fichier / etc / fstab pour ajouter une configuration de montage permanent; Utilisez la commande umount pour désinstaller l'appareil pour vous assurer qu'aucun processus n'utilise l'appareil.
 Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Que faire après Centos arrête la maintenance
Apr 14, 2025 pm 08:48 PM
Une fois CentOS arrêté, les utilisateurs peuvent prendre les mesures suivantes pour y faire face: sélectionnez une distribution compatible: comme Almalinux, Rocky Linux et CentOS Stream. Migrez vers les distributions commerciales: telles que Red Hat Enterprise Linux, Oracle Linux. Passez à Centos 9 Stream: Rolling Distribution, fournissant les dernières technologies. Sélectionnez d'autres distributions Linux: comme Ubuntu, Debian. Évaluez d'autres options telles que les conteneurs, les machines virtuelles ou les plates-formes cloud.
