
 Périphériques technologiques
IA
PDG de DeepMind : LLM+tree search est la ligne technologique AGI. La recherche scientifique sur l'IA repose sur des capacités d'ingénierie qui sont plus sûres que les modèles open source.
Périphériques technologiques
IA
PDG de DeepMind : LLM+tree search est la ligne technologique AGI. La recherche scientifique sur l'IA repose sur des capacités d'ingénierie qui sont plus sûres que les modèles open source.
PDG de DeepMind : LLM+tree search est la ligne technologique AGI. La recherche scientifique sur l'IA repose sur des capacités d'ingénierie qui sont plus sûres que les modèles open source.

Google est soudainement passé en mode 996 après février, lançant 5 modèles en moins d'un mois.
Et le PDG de DeepMind, Hassabis lui-même, a également fait la promotion de sa propre plate-forme de produits, exposant de nombreuses informations privilégiées en coulisses sur le développement.
Selon lui, même si des avancées technologiques sont encore nécessaires, la voie vers l'AGI pour les humains est désormais ouverte.
La fusion de DeepMind et de Google Brain marque que le développement de la technologie de l'IA est entré dans une nouvelle ère.
Q : DeepMind a toujours été à la pointe de la technologie. Par exemple, dans un système comme AlphaZero, l’agent intelligent interne peut atteindre l’objectif final grâce à une série de pensées. Cela signifie-t-il que les grands modèles de langage (LLM) peuvent également rejoindre les rangs de ce type de recherche ?
Hassabis estime que les modèles à grande échelle ont un potentiel énorme et doivent être encore optimisés pour améliorer la précision de leurs prédictions et ainsi construire des modèles mondiaux plus fiables. Bien que cette étape soit cruciale, elle ne suffira peut-être pas à construire un système complet d’intelligence artificielle générale (AGI).
Sur cette base, nous développons un mécanisme de planification similaire à AlphaZero pour formuler des plans visant à atteindre des objectifs mondiaux spécifiques à travers le modèle mondial.
Cela implique d'enchaîner différentes chaînes de pensée ou de raisonnement, ou d'utiliser des recherches arborescentes pour explorer un vaste espace de possibilités.
Ce sont les chaînons manquants dans nos grands modèles actuels.
Q : En partant de méthodes d'apprentissage par renforcement pur (RL), est-il possible de passer directement à l'AGI ?
Il semble que de grands modèles de langage constitueront les connaissances préalables de base, et que des recherches plus approfondies pourront ensuite être menées sur cette base.
Théoriquement, il est possible d'adopter complètement la méthode de développement d'AlphaZero.
Certaines personnes de DeepMind et de la communauté RL travaillent dans cette direction. Elles partent de zéro et ne s'appuient sur aucune connaissance ou donnée préalable pour construire complètement un nouveau système de connaissances.
Je crois que tirer parti des connaissances mondiales existantes - telles que les informations sur le Web et les données que nous collectons déjà - sera le moyen le plus rapide d'atteindre l'AGI.
Nous disposons désormais d'algorithmes évolutifs - des transformateurs - capables d'absorber ces informations. Nous pouvons pleinement utiliser ces modèles existants comme connaissances préalables pour la prédiction et l'apprentissage.
Par conséquent, je crois que le système AGI final inclura certainement les grands modèles d'aujourd'hui dans le cadre de la solution.
Mais un grand modèle à lui seul ne suffit pas, nous devons également y ajouter davantage de capacités de planification et de recherche.
Q : Face aux énormes ressources informatiques requises par ces méthodes, comment faire une percée ?
Même un système comme AlphaGo est assez coûteux en raison de la nécessité d'effectuer des calculs sur chaque nœud de l'arbre de décision.
Nous nous engageons à développer des méthodes et des stratégies efficaces en matière d'échantillons pour réutiliser les données existantes, telles que la relecture d'expérience, ainsi qu'à explorer des méthodes plus efficaces.
En fait, si le modèle mondial est suffisamment bon, votre recherche peut être plus efficace.
Prenons Alpha Zero comme exemple. Ses performances dans des jeux tels que le Go et les échecs dépassent le niveau du championnat du monde, mais sa plage de recherche est beaucoup plus petite que les méthodes de recherche traditionnelles par force brute.
Cela montre que l'amélioration du modèle peut rendre les recherches plus efficaces et ainsi atteindre des cibles plus larges.
Mais lors de la définition de la fonction et de l'objectif de récompense, comment garantir que le système se développe dans la bonne direction sera l'un des défis auxquels nous serons confrontés.
Pourquoi Google peut-il produire 5 modèles en un demi-mois ?
Q : Pouvez-vous nous expliquer pourquoi Google et DeepMind travaillent sur autant de modèles différents en même temps ?
Parce que nous menons des recherches fondamentales, nous avons un grand nombre de travaux de recherche fondamentale couvrant une variété d'innovations et de directions différentes.
Cela signifie que pendant que nous construisons la piste de modèle principale - le modèle de base Gemini, de nombreux autres projets exploratoires sont également en cours.
Lorsque ces projets d'exploration auront des résultats, nous les fusionnerons dans la branche principale de la prochaine version de Gemini, c'est pourquoi vous verrez la 1.5 publiée immédiatement après la 1.0, car nous travaillons déjà sur la prochaine version. Oui, parce que nous avons plusieurs équipes travaillant sur des échelles de temps différentes, alternant entre elles, c'est ainsi que nous pouvons continuer à progresser.
J'espère que cela deviendra notre nouvelle normalité, en sortant des produits à ce rythme élevé, mais bien sûr, tout en étant également très responsable, en gardant à l'esprit que la sortie de modèles sûrs est notre priorité numéro un.
Q : Je voulais vous poser des questions sur votre grande version la plus récente, Gemini 1.5 Pro, votre nouveau modèle Gemini Pro 1.5 peut gérer jusqu'à un million de jetons. Pouvez-vous expliquer ce que cela signifie et pourquoi la fenêtre contextuelle est un indicateur technique important ?
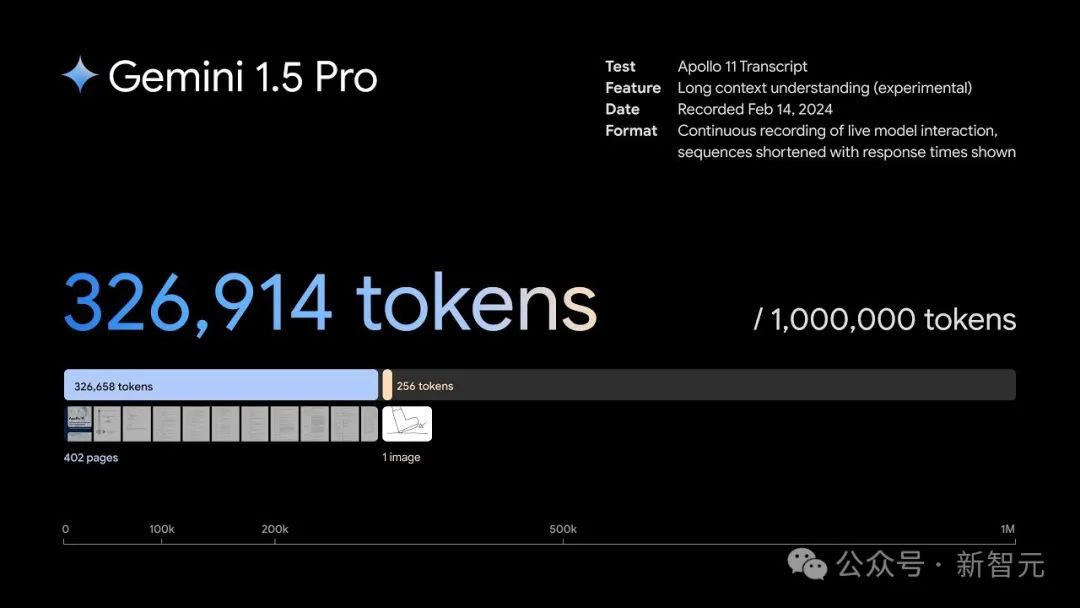
Oui, c'est très important. Le contexte long peut être considéré comme la mémoire de travail du modèle, c'est-à-dire la quantité de données qu'il peut mémoriser et traiter en même temps.
Plus le contexte dont vous disposez est long, son exactitude est également importante, l'exactitude du rappel des éléments du contexte long est tout aussi importante, plus vous pouvez prendre en compte de données et de contexte.
Donc, un million signifie que vous pouvez gérer des livres énormes, des films complets, des tonnes de contenu audio, comme des bases de code complètes.
Si vous avez une fenêtre de contexte plus courte, disons seulement cent mille niveaux, alors vous ne pouvez en traiter que des fragments, et le modèle ne peut pas raisonner ou récupérer l'intégralité du corpus qui vous intéresse.
Cela ouvre donc des possibilités pour tous les types de nouveaux cas d'utilisation qui ne peuvent pas être réalisés avec de petits contextes.
Q : Des chercheurs en IA m'ont dit que le problème avec ces grandes fenêtres contextuelles est qu'elles nécessitent beaucoup de calculs. Par exemple, si vous téléchargez un film entier ou un manuel de biologie et posez des questions à ce sujet, il faudra plus de puissance de traitement pour traiter tout cela et y répondre. Si beaucoup de gens le font, les coûts peuvent rapidement s’accumuler. Google DeepMind a-t-il imaginé une innovation intelligente pour rendre ces énormes fenêtres contextuelles plus efficaces, ou Google a-t-il simplement supporté le coût de tous ces calculs supplémentaires ?
Oui, c'est une innovation complètement nouvelle car sans innovation on ne peut pas avoir un contexte aussi long.
Mais cela nécessite tout de même un coût de calcul élevé, nous travaillons donc dur pour l'optimiser.
Si vous remplissez toute la fenêtre contextuelle. Le traitement initial des données téléchargées peut prendre plusieurs minutes.
Mais ce n'est pas trop mal si vous considérez que c'est comme regarder un film entier ou lire l'intégralité de Guerre et Paix en une minute ou deux et vous pourrez ensuite répondre à toutes vos questions à ce sujet.
Ensuite, ce que nous voulons nous assurer, c'est qu'une fois que vous avez téléchargé et travaillé sur un document, une vidéo ou un audio, les questions et réponses suivantes devraient être plus rapides.
C'est ce sur quoi nous travaillons actuellement et nous sommes convaincus que nous pouvons le réduire à quelques secondes.
Q : Vous avez dit avoir testé le système avec jusqu'à 10 millions de jetons. Quel a été l'effet ?
A très bien fonctionné lors de nos tests. Le coût informatique étant encore relativement élevé, le service n'est pas disponible actuellement.
Mais en termes de précision et de rappel, il fonctionne très bien.
Q : Je veux vous poser des questions à propos de Gemini. Quelles choses spéciales Gemini peut-il faire que les modèles linguistiques précédents de Google ou d'autres modèles ne pouvaient pas faire ?
Eh bien, je pense que ce qui est passionnant avec Gemini, en particulier la version 1.5, c'est qu'il est intrinsèquement multimodal et que nous l'avons construit à partir de zéro pour pouvoir gérer tout type d'entrée : texte, images, code, vidéo. .
Si vous le combinez avec un contexte long, vous pouvez voir son potentiel. Par exemple, vous pouvez imaginer que vous écoutez une conférence entière ou qu’il y a un concept important que vous souhaitez comprendre et que vous souhaitez y accéder rapidement.
Nous pouvons désormais placer l'intégralité de la base de code dans une fenêtre contextuelle, ce qui est très utile pour les nouveaux programmeurs qui débutent. Disons que vous êtes un nouvel ingénieur qui commence à travailler lundi. En règle générale, vous devez examiner des centaines de milliers de lignes de code. Comment accéder à une fonction ?
Vous devez demander aux experts de la base de code. Mais vous pouvez désormais utiliser Gemini comme assistant de codage, de manière amusante. Il renverra un résumé vous indiquant où se trouvent les parties importantes du code et vous pourrez commencer à travailler.
Je pense qu'avoir cette capacité est très utile et rend votre flux de travail quotidien plus efficace.
J'ai vraiment hâte de voir comment Gemini fonctionne lorsqu'il est intégré à des éléments comme Slack et à votre flux de travail général. À quoi ressemblera le workflow du futur ? Je pense que nous commençons tout juste à ressentir les changements.
La priorité absolue de Google en matière d'open source est la sécurité
Q : J'aimerais maintenant me tourner vers Gemma, une série de modèles open source légers que vous venez de publier. Aujourd’hui, la question de savoir s’il faut publier les modèles sous-jacents en open source ou les garder fermés semble être l’un des sujets les plus controversés. Jusqu’à présent, Google a gardé son modèle sous-jacent fermé. Pourquoi choisir l'open source maintenant ? Que pensez-vous des critiques selon lesquelles le fait de rendre les modèles sous-jacents disponibles via l'open source augmente le risque et la probabilité qu'ils soient utilisés par des acteurs malveillants ?
Oui, j'ai en fait discuté publiquement de cette question à plusieurs reprises.
L'une des principales préoccupations est que, de manière générale, l'open source et la recherche ouverte sont clairement bénéfiques. Mais il y a ici un problème spécifique, lié aux technologies AGI et IA, car elles sont universelles.
Une fois que vous les publiez, des acteurs malveillants peuvent les utiliser à des fins nuisibles.
Bien sûr, une fois que vous avez ouvert quelque chose, vous n'avez aucun moyen réel de le récupérer, contrairement à quelque chose comme l'accès à l'API, que vous pouvez simplement couper si vous constatez qu'il existe des cas d'utilisation nuisibles en aval que personne n'avait envisagé auparavant. . accéder.
Je pense que cela signifie que la barre en matière de sécurité, de robustesse et de responsabilité est encore plus haute. À mesure que nous nous rapprochons des AGI, elles auront des capacités plus puissantes, nous devons donc être plus prudents quant à l’utilisation qu’elles pourraient faire par des acteurs malveillants.
Je n'ai pas encore entendu un bon argument de la part de ceux qui soutiennent l'open source, tels que les extrémistes de l'open source, dont beaucoup sont mes collègues respectés du monde universitaire, comment ils répondent à cette question, - en ligne Empêcher les modèles open source de des problèmes qui permettraient à davantage d’acteurs malveillants d’accéder au modèle ?
Nous devons réfléchir davantage à ces questions à mesure que ces systèmes deviennent de plus en plus puissants.
Q : Alors, pourquoi Gemma ne vous a-t-elle pas inquiété à propos de ce problème ?

Oui, bien sûr, comme vous le remarquerez, Gemma ne propose que des versions légères, elles sont donc relativement petites.
En fait, la taille plus petite est plus utile pour les développeurs car généralement les développeurs individuels, les universitaires ou les petites équipes souhaitent travailler rapidement sur leurs ordinateurs portables, ils sont donc optimisés pour cela.
Parce que ce ne sont pas des modèles de pointe, ce sont des petits modèles et nous sommes rassurés que parce que les capacités de ces modèles ont été rigoureusement testées et que nous savons très bien de quoi ils sont capables, il n'y a pas de gros risques avec un modèle. de cette taille.
Pourquoi DeepMind fusionne avec Google Brain
Q : L'année dernière, lorsque Google Brain et DeepMind ont fusionné, certaines personnes que je connais dans l'industrie de l'IA étaient inquiètes. Ils craignent que Google ait historiquement donné à DeepMind une latitude considérable pour travailler sur divers projets de recherche qu'il juge importants.
Avec la fusion, DeepMind devra peut-être être détourné vers des choses qui sont bénéfiques pour Google à court terme, plutôt que vers ces projets de recherche fondamentale à plus long terme. Cela fait un an depuis la fusion. Cette tension entre l'intérêt à court terme pour Google et les éventuelles avancées à long terme de l'IA a-t-elle changé ce sur quoi vous pouvez travailler ?
Oui, tout s'est bien passé cette première année comme vous l'avez mentionné. L'une des raisons est que nous pensons que c'est le bon moment, et je pense que c'est le bon moment du point de vue d'un chercheur.
Peut-être revenons cinq ou six ans en arrière, lorsque nous faisions des choses comme AlphaGo, dans le domaine de l'IA, nous avions étudié de manière exploratoire comment accéder à l'AGI, quelles avancées étaient nécessaires, sur quoi il fallait parier, et en ce sens, il y a un large éventail de choses que vous voulez faire, donc je pense que c'est une étape très exploratoire.
Je pense qu'au cours des deux ou trois dernières années, il est devenu clair quels seront les principaux composants de l'AGI, comme je l'ai déjà mentionné, même si nous avons encore besoin de nouvelles innovations.

Je pense que vous venez de voir le long contexte de Gemini1.5, et je pense qu'il y a beaucoup de nouvelles innovations comme celle-ci qui seront nécessaires, donc la recherche fondamentale est toujours aussi importante.
Mais maintenant, nous devons également travailler dur dans le sens de l'ingénierie, c'est-à-dire étendre et exploiter les technologies connues et les pousser dans leurs limites. Cela nécessite une ingénierie très créative à grande échelle, du matériel au niveau du prototype jusqu'à l'échelle du centre de données. et les problèmes d'efficacité impliqués.
Une autre raison est que si vous fabriquiez des produits basés sur l'IA il y a cinq ou six ans, vous auriez dû construire une IA complètement différente de la piste de recherche AGI.
Il ne peut effectuer des tâches que dans des scénarios spéciaux pour des produits spécifiques. Il s'agit d'une sorte d'IA personnalisée, « IA faite à la main ».
Mais les choses sont différentes aujourd'hui. Pour faire de l'IA pour les produits, la meilleure façon est désormais d'utiliser les technologies et les systèmes généraux d'IA car ils ont atteint un niveau suffisant de complexité et de capacité.
Il s'agit donc en fait d'un point de convergence, vous pouvez donc voir maintenant que la piste de recherche et la piste de produit ont été fusionnées.
Par exemple, nous allons maintenant créer un assistant vocal IA, et à l'opposé, un chatbot qui comprend vraiment le langage. Ils sont désormais intégrés, il n'est donc pas nécessaire de considérer cette dichotomie ou cette relation coordonnée et tendue.
La deuxième raison est qu'avoir une boucle de rétroaction étroite entre la recherche et les applications dans le monde réel est en fait très bénéfique pour la recherche.
En raison de la façon dont le produit vous permet de vraiment comprendre les performances de votre modèle, vous pouvez avoir des mesures académiques, mais le véritable test est lorsque des millions d'utilisateurs utilisent votre produit, le trouvent-ils utile, le trouvent-ils c'est utile Est-ce utile et est-ce bon pour le monde.
Vous allez évidemment recevoir beaucoup de retours et cela conduira ensuite à des améliorations très rapides du modèle sous-jacent, donc je pense que nous sommes actuellement dans cette étape très, très excitante.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
